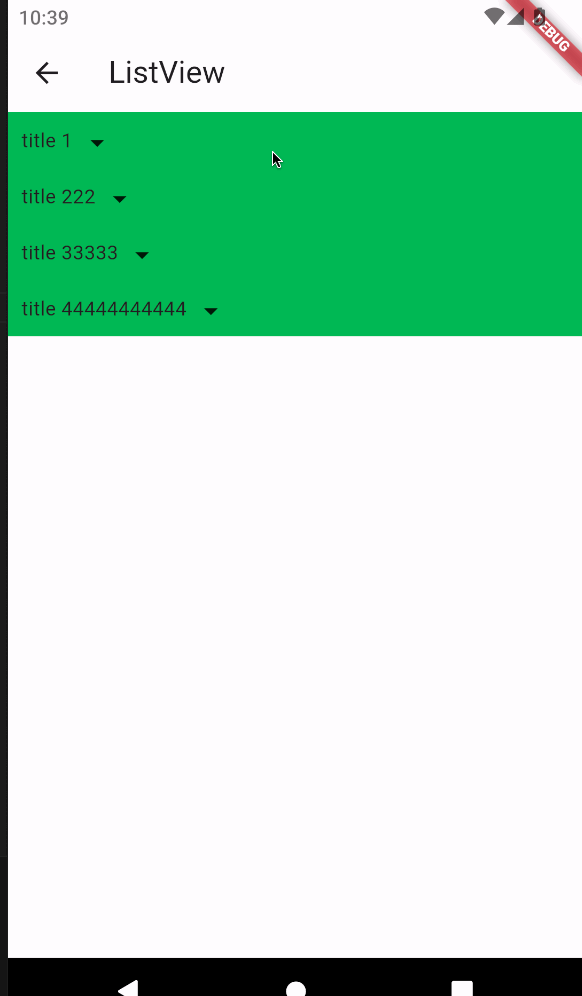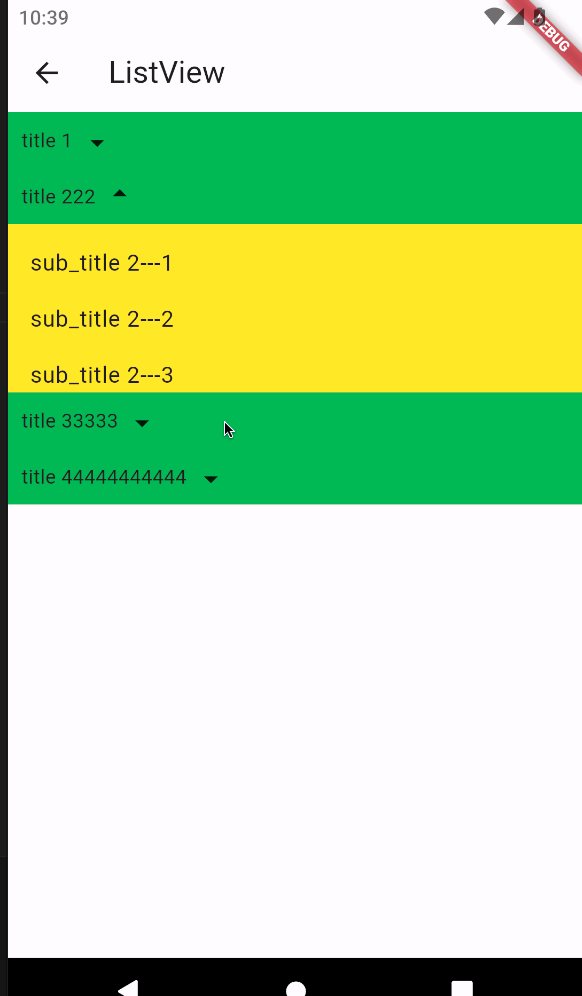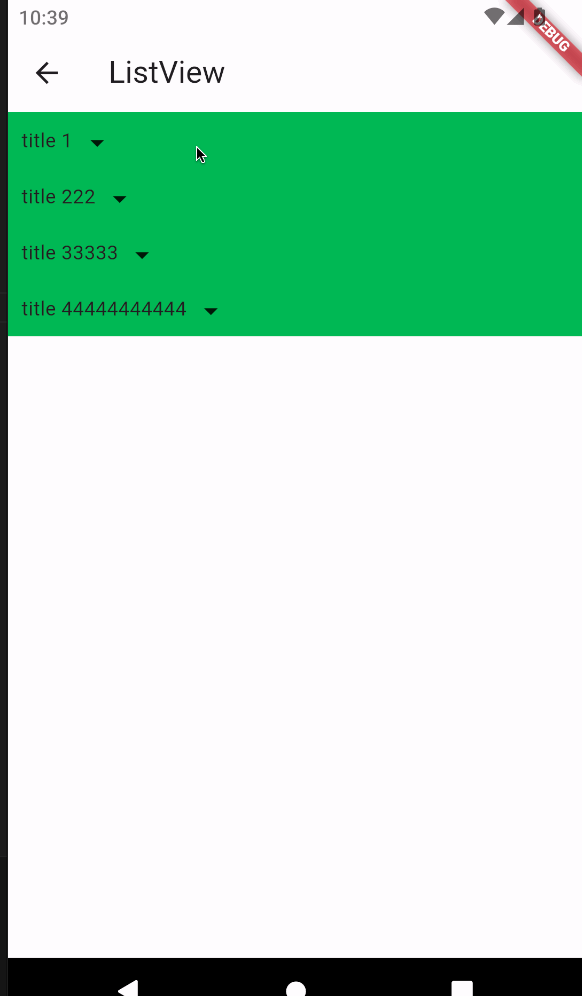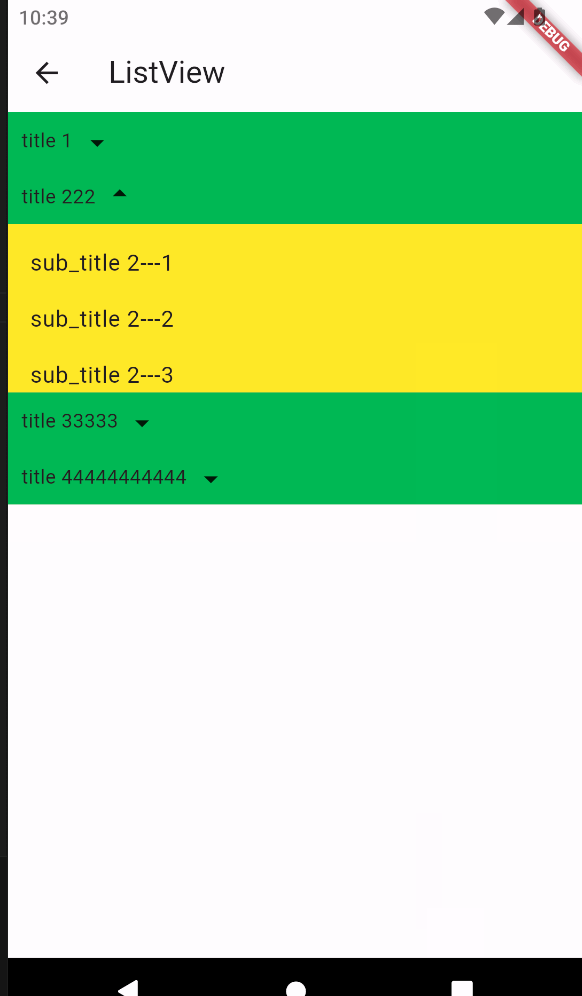
1.摘要
图像美学质量评估(AQA)旨在为图像指定数字美学等级,而图像美学字幕(IAC)旨在生成图像美学方面的文本描述。在本文中,我们研究了图像AQA和IAC,并提出了一种新的IAC方法,称为审美相关图像字幕(ARIC)。基于大多数图像的文本评论是关于物体及其交互而不是美学方面的观察,我们首先引入句子的美学相关性分数(ARS)的概念,并开发了一个自动标记句子及其美学相关性分数的模型。然后,我们使用ARS来设计ARIC模型,该模型包括ARS加权IAC损失函数和基于ARS的多样化美学字幕选择器(DAC)。我们展示了大量的实验结果,通过证明具有较高ARS的文本可以更准确地预测美学评级,以及新的ARIC模型可以生成更准确、美学上更相关和更多样化的图像标题,来显示ARS概念的可靠性和ARIC模型的有效性。此外,一个新的大型研究数据库,包含510,000张图片,超过500,000条评论和350,000个美学评分,以及用于实现ARIC的代码,可在https://github.com/PengZai/ARIC.获得。
本文聚焦于审美相关图像字幕ARIC:
- 引入句子的美学相关性分数(ARS)的概念,
- 开发自动标记句子及其美学相关性分数的模型。
- 我们使用ARS来设计ARIC模型,该模型包括ARS加权IAC损失函数和基于ARS的多样化美学字幕选择器(DAC)。
结论:
具有较高ARS的文本可以更准确地预测美学评级,以及新的ARIC模型可以生成更准确、美学上更相关和更多样化的图像标题,来显示ARS概念的可靠性和ARIC模型的有效性
新的数据集:
包含510,000张图片,超过500,000条评论和350,000个美学评分
核心关键:
ARS加权IAC损失函数和基于ARS的多样化美学字幕选择器(DAC)。是啥?
2.背景信息
- 美学是一个高度主观的概念
- 与相当抽象的视觉内容不同,文本更容易让人理解。
- 旨在自动生成图像文本描述的图像字幕已经得到了广泛的研究。但更抽象、更具挑战性的图像美学字幕问题(IAC)(Chang、Lu和Chen 2017)却很少受到关注,该问题旨在生成关于图像美学方面的评论。
- 在现有的文献中,图像AQA和IAC是相互独立研究的。
- 这些指标评估生成的句子和参考(基本事实)句子之间的相似性,而不是文本的美学相关性。如果我们能够直接测量IAC结果的美学相关性,例如,所生成的标题能够多准确地预测图像的美学分数,这将是非常有用的。
- ARIC模型是基于ARS加权损失函数构建的,该函数确保它学习美学相关信息。
- ARS的引入使得DAC的设计能够输出一组不同的美学上高度相关的句子。
创新点:
- 建立了一个大型图像数据库DPC2022,用于检索图像美学字幕和图像美学质量评价。DPC2022是包含美学评论和分数的最大数据集。
- 引入了一个新的概念——审美关联分数(ARS)来衡量句子的审美关联。用于构建ARS模型的关键词和其他统计信息的列表是可用的
- 在ARS的基础上,我们开发了新的美学相关图像字幕(ARIC)系统,该系统不仅能够制作美学相关的图像字幕,还能够制作多样化的图像字幕
创新点:
1.构建了一个大型数据集用来支持当前研究·
2.ARS衡量审美关联度:ARS构建关键词、统计信息列表,如何使用?
3.更多样化的图像字幕
重点:
- ARIC模型是基于ARS加权损失函数构建的,该函数确保它学习美学相关信息。
- ARS的引入使得DAC的设计能够输出一组不同的美学上高度相关的句子。
相关工作总结思路:
美学评估->美学字幕->图像字幕
3.数据集
当前数据集问题: 之前数据集要么小,要么就是根据AVA构建的,但是现在有条件创造更好的数据集。
构建数据集:——The DPC2022 Dataset
从网络抓取素材:总共获得了780,000张图片和它们的评论
文本数据清理:工业级自然语言处理工具spaCy (https://spacy.io/)
最后获得:510K的图像,质量好,注释干净
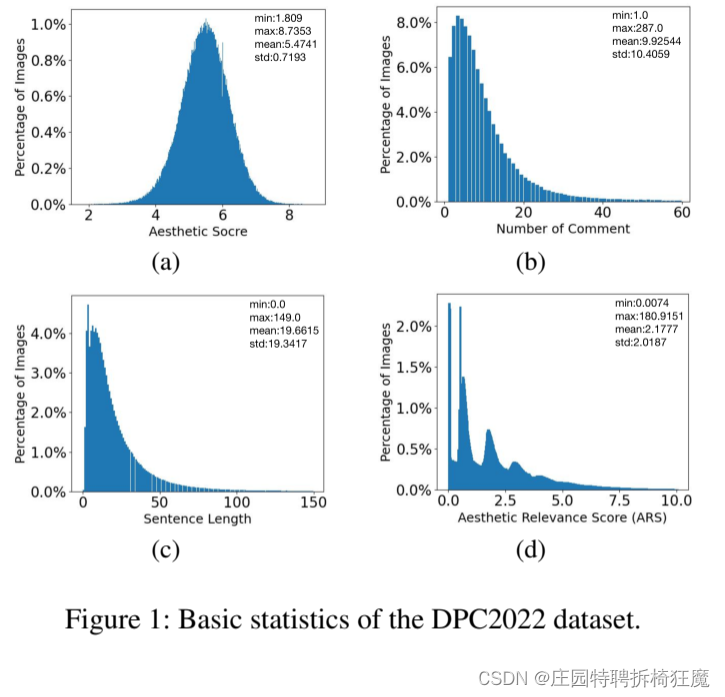
数据集特点:
- 510K张图片中,有350K张图片的评论和审美得分在1到10之间
- 每幅图像包含大约10条评论,
- 每条评论平均包含21个句子,平均句子长度为19个单词
4.模型
审美相关分数(ARS)
审美相关分数(ARS)概念:
- 据作者所知,当前还没有与图像美学相关的词和短语的定义。
- DPC2022数据集的评论有很明显许多评论与图像的美学品质无关。
- 为了区分涉及美学质量的词和不相关的词是适当的。——开发了审美相关分数(ARS),来量化评论的审美相关性。
- 基于主观判断和数据集统计数据的混合。
ARS标记句子:
- 为了计算A(t),我们手动选择了1022个最频繁出现的图像美学相关词,如镜头、颜色、构图、光线、焦点、背景、主题、细节、对比度等
- L(t)与t的长度有关
- 为了计算O(t ),我们通常选择2146个与物体相关的词,如眼睛、天空、脸、丝带、水、树、花、表情、手、鸟、玻璃、狗、头发、猫、微笑、太阳、窗户、汽车等
- 情感得分S(t)是基于BerTweet模型(Perez、Giudici和Luque 2021)计算的。
- Tf idf(t)与术语频率相关——逆文档频率。
总结:
审美相关分数(ARS):基于主观判断和数据集统计数据的混合,区分涉及美学质量的词和不相关的词是适当的。其量化了评论的审美相关性

A(t):美学相关词汇 L(t):文本长度 O(t):客观物体词汇
S(t):BerTweet情感得分 Tf-idf(t):逆文档频率

图摘自csdn
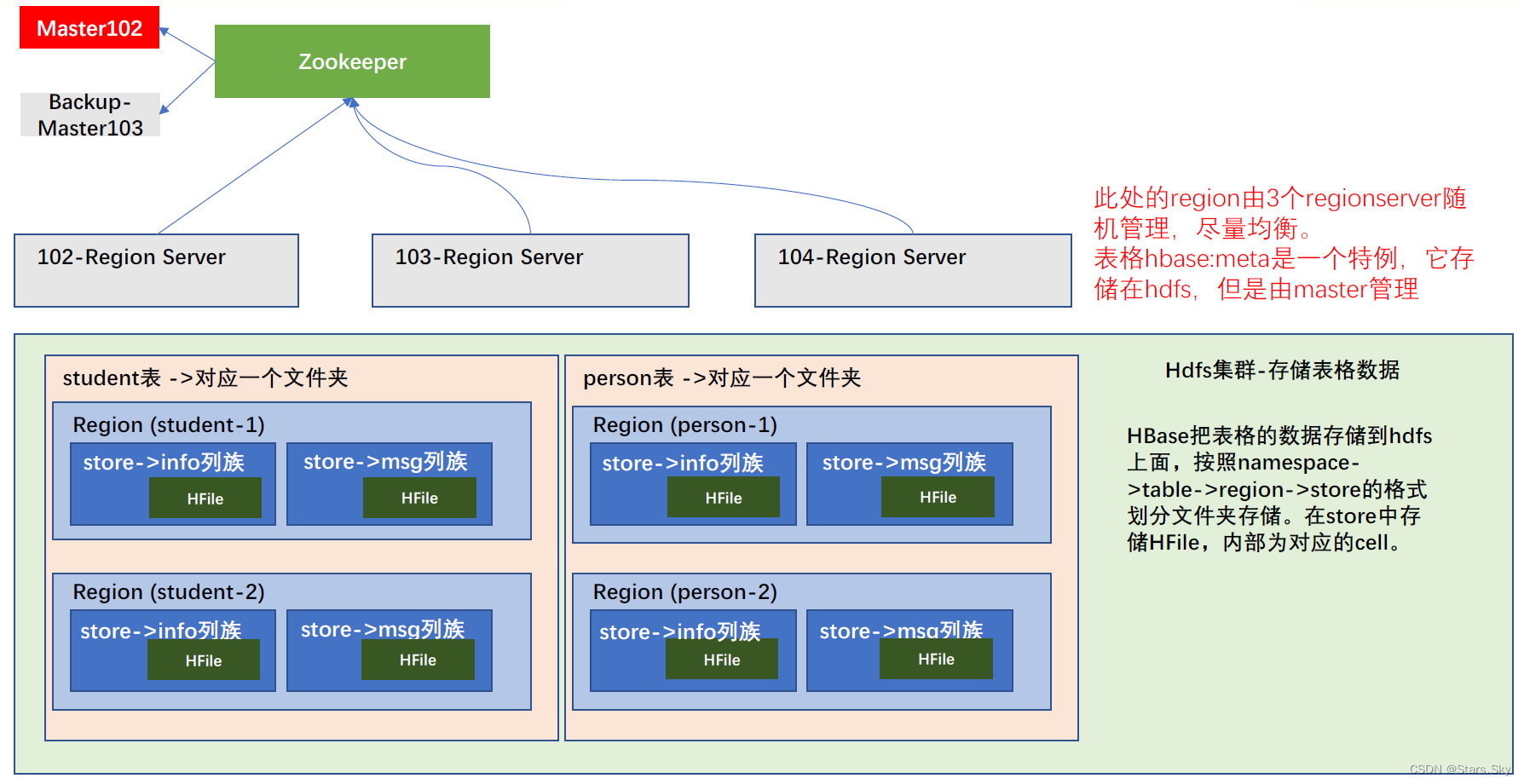
美学相关图像字幕图像字幕模型
图像编码器:
- 遵循自下而上-注意模型并使用ResNet-101 作为更快的R-CNN 的主干网络来提取图像特征。
- 对象检测保留了50个最感兴趣的区域,每个区域由一个2048维的特征向量表示。
解码器:
使用VisualGPT (基于GPT2)生成图像美学字幕。VisualGPT使用一个自我复活的激活单元将视觉信息编码到语言模型中,平衡了视觉编码器模块和语言解码器模块。
-------------------------------------------------------------------------------------------------------------------------
审美相关损失函数:
ARS(t)定量地测量一段文本t的美学相关性,较高的ARS(t)指示t包含高度美学相关的信息,而较低的ARS(t)指示相反的情况。因此,我们使用ARS(t)来定义审美相关损失函数


总结:
模型:编码器(50个区域特征+resnet101模型+自下而上的注意力模型)-解码器(VisualGPT-基于GPT2)
ARS加权的损失函数:在原始交叉熵损失上使用ARS分数加权。(交叉熵*ARS分数)

多样化美学字幕选择器(DAC)
ARS概念:
- 来衡量一个句子的美学价值,
- 帮助从生成器中选择美学上更相关和更多样的词。
如何生成多样化的句子:
- 给定一幅图片,模型使用beam搜索生成N个最有把握的句子。
- 然后我们使用句子变换器1来提取句子的特征,然后计算N个句子之间的余弦相似度。
- 将余弦相似度高于0.7的句子分组到同一个组中,使得每个组包含许多相似的句子。
- ARS预测器来估计每组中句子的ARS。
- 如果一组句子的平均ARS低于训练数据的平均ARS(2:1787),则该组被丢弃,因为它们的美学价值低。
- 从剩下的组中,我们选择每组中ARS最高的句子作为输出。
目标:多样化美学标题选择器(DACS),生成了美学上高度相关和多样化的图像标题
总结:
如何生成美学相关的多样化句子:
- Beam search生成N个候选句子
- 计算N个句子的余弦相似度
- 余弦相似度高于0.7的,分组——相似的句子
- ARS预测器评估组种每句的ARS分数
- 一组假胡子ARS<训练集平均2.1787,则该组被弃——丢弃美学无关句子。
- 从剩余的句子选取得分高的输出。
多模态美学质量评估
一个合理的假设:一段文字越能准确预测一幅图像的审美等级,该文字与该图像在审美上就越相关
有3条独立的路径:
- 第一个将图像作为输入,输出图像的审美等级。骨干神经网络用于特征提取。这些特征随后被输入MLP,以回归审美等级。
- 第二条路径将图像的文本描述作为输入,并输出图像的美学分数。同样,神经网络主干用于文本特征提取。这些特征被输入MLP网络以输出审美分数。
- 第三条路径用于实现多模态AQA,其中视觉和文本特征被连接并被馈送到MLP以输出审美得分
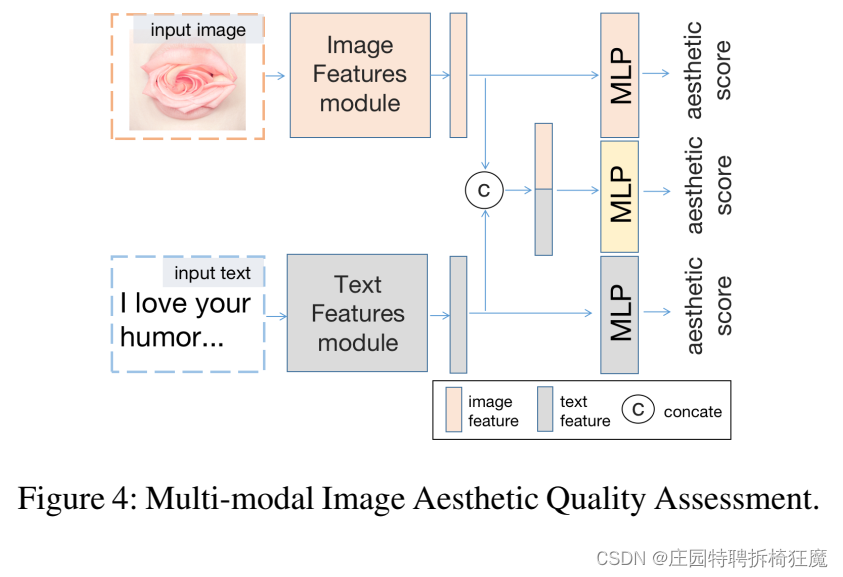
总结:
审美评估:文本越与美学相关,越有助于得到准确的美学评分。
三条路径:
图像——>审美评分
文本——>审美评分
图像+文本——>审美评分
5.实现细节
数据集:
SetA进行照片美学字幕实验,
SetA: 包含所有图像,510,000张照片中的350,000张也有审美评级
训练集:392331 验证集:10698 测试集:106971
使用SetB进行多模态美学质量评估
SetB: 包含带有评论和美学评级的图像的子集
训练集:232331 验证集:10698 测试集:106971
----------------------------------------------------------------------------------------------------------------------
评价指标:
美学评估方面:
二进制准确度(ACC)、Spearman秩序相关系数(SRCC)、Pearson线性相关系数(PLCC)、均方根误差(RMSE)和平均绝对误差(MAE)
图像字幕方面:
CIDER 、METETOR 、ROUGE和SPICE 。SPICE是基于词的场景图语义相似度度量,其他都是基于n-gram
---------------------------------------------------------------------------------------------------------------------
实现细节设置:
图像模型:
VGG-16、RESNET18、DESNET121、RESNEXT50和ViT使用预训练模型,而不是从头开始训练。
图像编码大小:512
AQA文本模型:
TEXTCNN 、TEXTRNN 、BERT 和ROBERTA 。对于BERT和ROBERTA,使用预训练模型。
AQA模型被训练16个时期
IAC模型:
使用预训练的GPT2模型,并将token大小设置为64。
IAC模型被训练32个时期
实验设置:
具有4个NVIDIA A100 GPUs的机器。
使用的Adam优化器的学习速率为2e 5,没有重量衰减。
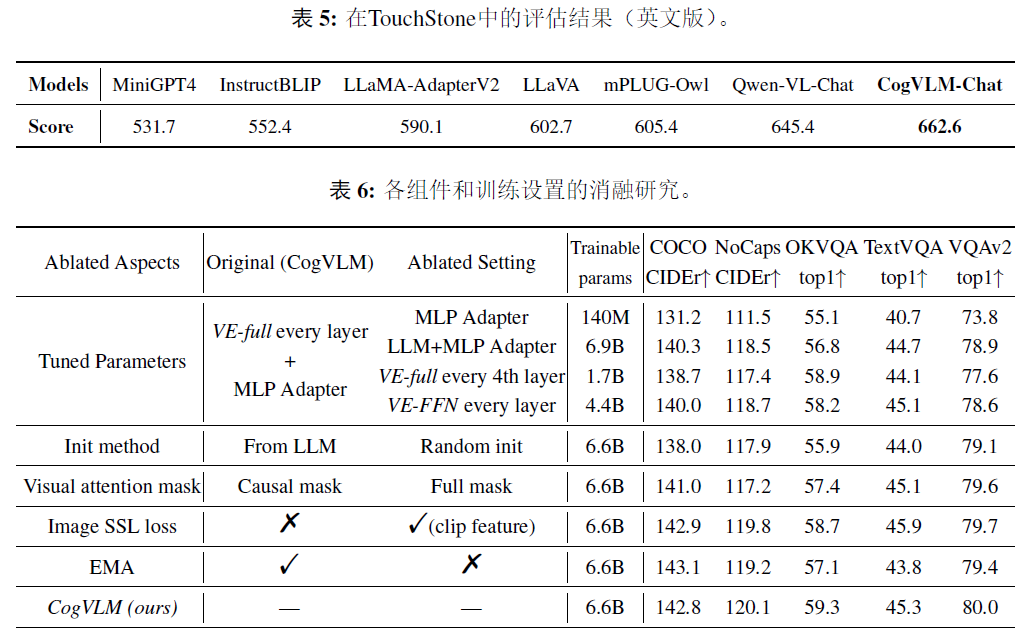
6.实验结果
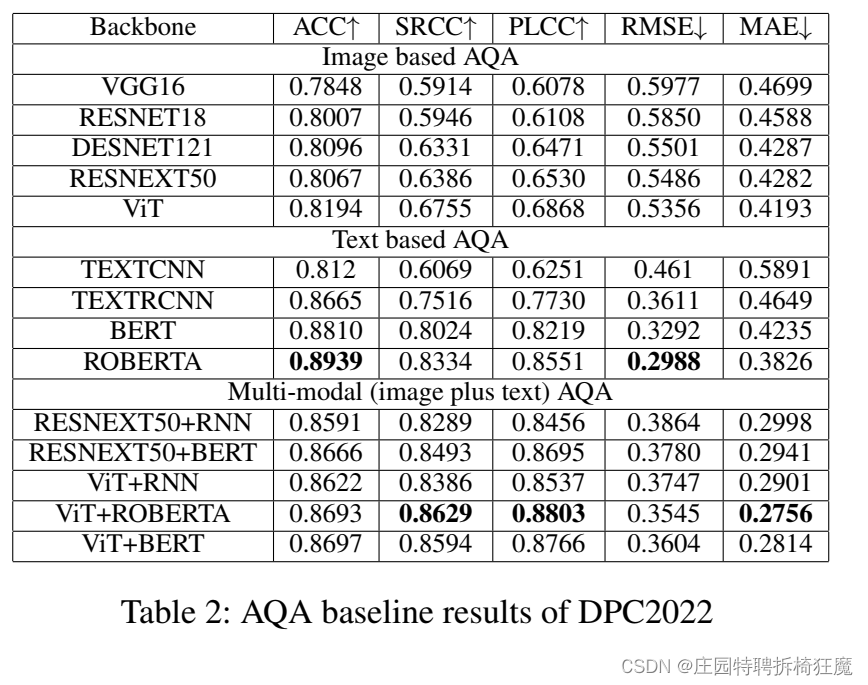
美学评估任务:图像AQA基线
试验了各种网络架构,基于图像、基于文本和多模式AQA结果的基线结果。
结果表明:图像的文本评论在美学上是高度相关的。
在五个指标中
- 2个指标中,使用评论文本能获得最佳绩效。
- 其他3个指标中,多模态AQA的性能最好。
总结:
与单模态相比,多模态AQA性能更好
-------------------------------------------------------------------------------------------------------------------------
ARS可靠性的验证:
如果ARS模型是合理的,那么我们期望具有较高ARS的评论文本应该能够更准确地预测图像的审美等级。相反,具有较低ARS的评论文本将产生对图像美学评级的较不准确的预测。
验证集根据ARS划分为两类:ARS高于平均值的、ARS低于平均值的
结果表明:
随着ARS的增加,AQA性能也增加。具有高ARS的评论可以始终如一地更准确地预测图像美学评级。
这意味着ARS及其组件确实可以测量文本评论的美学相关性。
总结:
随着ARS的增加,AQA性能也增加——>ARS及其组件确实可以测量文本评论的美学相关性
-------------------------------------------------------------------------------------------------------------------------
用于对文本相关性进行排名的ARS与CLIP
CLIP排名模式:
首先用DPC2022数据的训练集微调预训练的剪辑模型,以便图像和它们相应的注释匹配。
对图片评论中的句子进行排序。让Clip(I,ti)是图像I和句子t之间的匹配分数。
合理地假设,如果文本和图像具有更好的CLIP匹配分数,则文本可以更准确地描述图像。
ARS排名模式:
使用ARS根据句子的片段匹配分数对句子进行排序。
为了比较CLIP和ARS在图像自动问答中的文本选择:
对测试集中图像的句子进行排序,并对不同排序的句子执行基于文本的自动问答。按ARS和CLIP排序的SRCC和MAE性能如图5所示。
结果表明:
通过两种方法排序较高的句子可以更准确地预测审美等级,并且两者看起来非常相似。
适当微调的CLIP模型也可以用于为图像AQA选择美学上相关的文本。
值得注意的是,ARS是一个非常简单的方案,而CLIP是一个复杂得多但功能强大的模型。
-------------------------------------------------------------------------------------------------------------------------
美学字幕展示:
- 基线模型,其中使用了标准的交叉熵损失函数,设置ARS(tk)=1。
- 新模型(ARS加权训练),始终优于基线模型。
结果证明:
引入美学相关分数(ARS)用于美学图像字幕的有用性和有效性。新方法的更好的性能证明了新算法设计的合理性
多样性结果展示见图6
总结:
ARS加权损失训练出来的模型更具有美学价值。
-------------------------------------------------------------------------------------------------------------------------
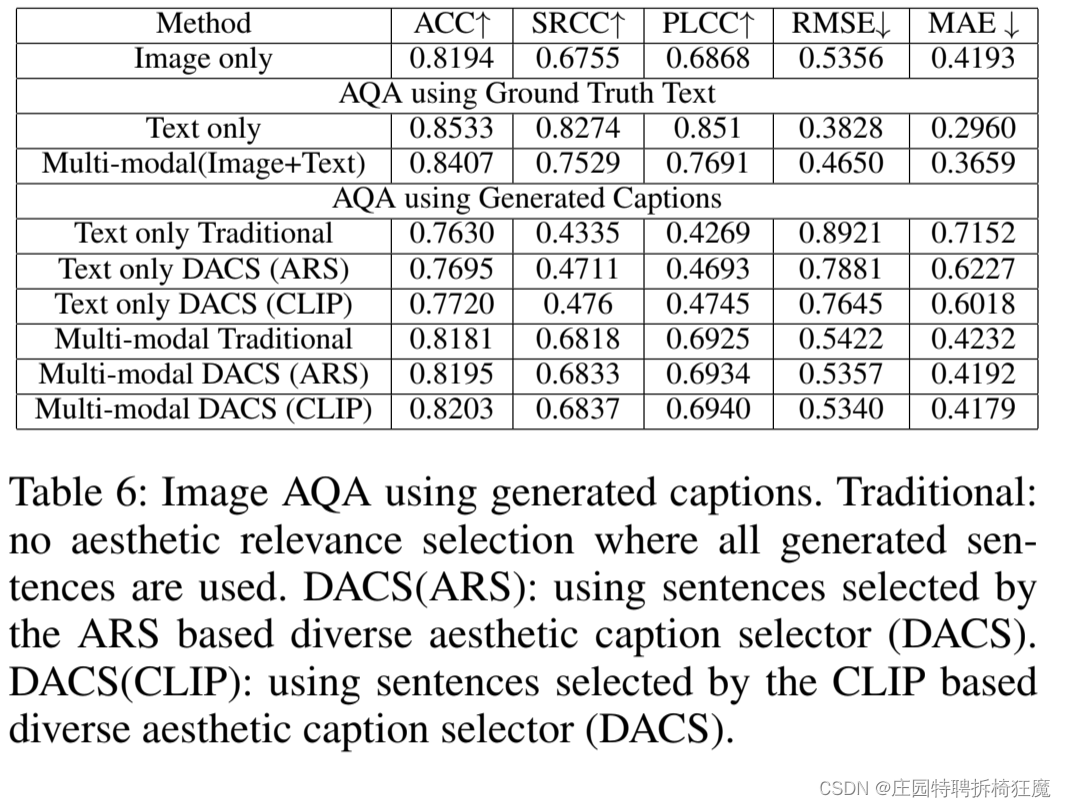
基于生成的字幕的图像AQA
- 在纯文本模态的AQA中,生成的文本表现得比真正的字幕差,也比纯图像模态的AQA差。
- 使用由新的多样化美学字幕选择器(DAC)选择的基于ARS或CLIP的字幕比使用没有选择的字幕执行得更好。
- 在多模态自动问答中,包含生成文本的自动问答已经开始略微超过仅包含图像的自动问答,但仍与使用ground truth的自动问答相差甚远。(多模态AQA的ACC是0.8407,而使用生成字幕的ACC是0.8203)
总结:
多模态文本+图片AQA性能比单模态更好
有DAC的模型比没有DAC的字幕模型性能更好
问答模型中准确率:多模态和生成字幕的差距在减小,说明生成的字幕更具丰富的价值。




7.总结:
两个密切相关的课题: 图像美学质量评价和图像美学字幕。
引入审美相关度(ARS)的概念:
- 通过ARS加权损失函数
- 基于ARS的多样性审美字幕选择器(DACS)来设计审美相关图像字幕(ARIC)模型。
实验结果: 证明了ARS概念的正确性和ARIC模型的有效性。
贡献: 一个大型研究数据库DPC2022,其中包含带有评论和美学评级的图像。
8.读后感
1.审美相关图像字幕(ARIC)是什么?把美学字幕和美学评估联系起来,这样得到的字幕不仅能够描述图片美学信息,还能很好的支持美学评估。
2.作者怎么做的?
关键概念引入美学相关性分数(ARS):
使用其对损失函数加权——与美学相关联
多样性审美字幕选择器(DACS)——筛选美学相关度高且多样化的文本
模型主体架构: 编码器(50个区域特征+resnet101模型+自下而上的注意力模型)-解码器(VisualGPT-基于GPT2)
3.当前的美学相关字幕怎么评价?
分两部分:
数据集划分:SetA:美学字幕 SetB:美学多模态评估
三个美学分数评估路径:仅图片、仅文本、多模态——>美学的分数
评价指标:
1.美学评估相关指标——美学评分|相关性
2.美学字幕相关指标——字幕相似性
4.如何评价本文模型?
自己创建数据集,自己创建基线,主要靠消融实验,优点在做了很多实验,验证逻辑详细。
模型中编解码器比较经典,能够引入一些更新的模型就更好了。
ARS概念的提出对于本文来说是关键。
ARS的实质是:情感信息+客体信息+美学信息+文本信息