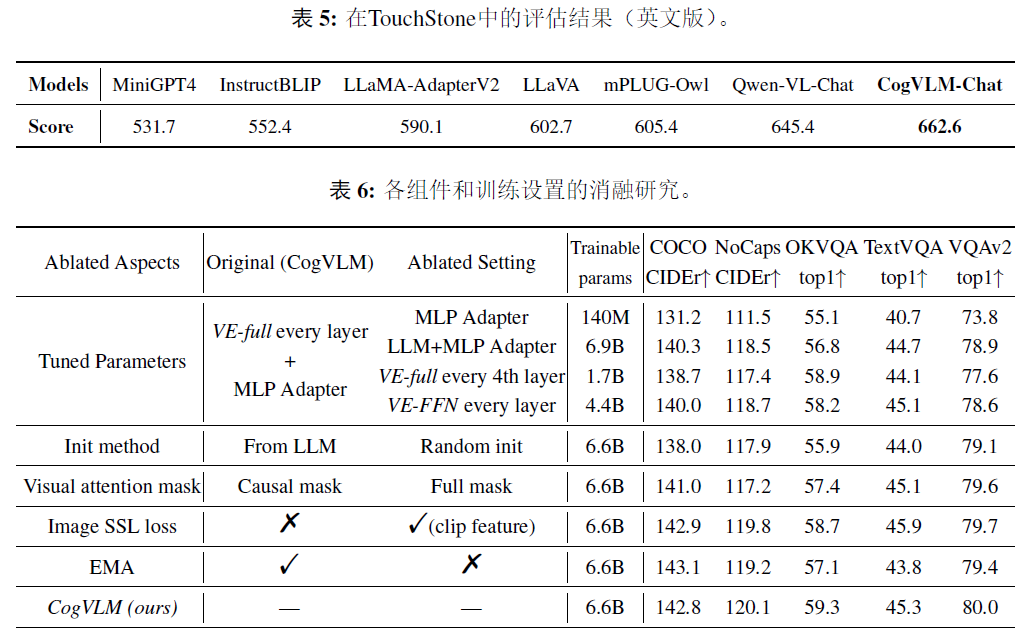
CogVLM: Visual Expert For Large Language Models论文笔记 - 知乎github: https://github.com/THUDM/CogVLM简介认为原先的shallow alignment效果不好(如blip-2,llava等),提出了visual expert module用于特征的deep fusion在10项任务上达到SOTA,效果堪比PaLI-X 55B分为专家模…![]() https://zhuanlan.zhihu.com/p/6627642351.introduction
https://zhuanlan.zhihu.com/p/6627642351.introduction
shallow alignment不好,blip2,minigpt4,llava,visualglm等通过可训练的Q-former或线性层将冻结的预训练视觉编码器和语言模型连接起来,将图像特征映射到语言模型的输入嵌入空间中,虽然收敛速度快,但是不如联合训练视觉和语言模块的方法,例如PaLi-X,容易产生幻觉。shallow alignment较差的原因是视觉和语言之间缺乏深度融合deep fusion。这一想法来自于高效微调中的p-tuning和lora的比较,其中p-tuning通过学习输入中的任务前缀嵌入,而lora通过地址矩阵调整每个层的模型权重,lora效果更好更稳定。在VLM中,shallow alignment中,图像特征起到了p-tuning中的前缀嵌入作用,导致p-tuning和shallow alignment性能下降的原因包括:1.语言模型的权重是用文本token训练的,视觉特征在输入文本空间中并不能很多的对齐,因此在多层转换之后,视觉特征可能不再与深层权重的输入分布相匹配。2.在预训练阶段,cation中的先验信息只能被编码到浅层对齐方法中的视觉特征中,这削弱了视觉特征和文本之间的一致性。当然这也不全然,QWen-VL采用的三阶段训练,语言模型也会训练应该会解决一些对齐和融合的问题。一种方法是将语言模型和图像-文本联合训练,包括PaLI和QWen-VL,但是这种方式会导致语言模型能力下降,PaLM-E语言模型在VLM预训练期间可能会灾难性遗忘,导致8B的语言模型NLG下降87.3%.
CogVLM相反,向语言模型中添加了一个可训练的visual expert,在每一层中,序列中的图像特征使用一个新的不同的QKV矩阵和MLP层与文本特征并行。visual expert保证FLOPS不变的同时使参数数量翻倍。语言模型使用的是Vicuna-7B.
2.method
2.1 architecture
cogvlm由四个基本组件组成:VIT,MLP adapter,预训练语言模型,visual expert。

VIT:CogVLM-17B,预训练的EVA2-CLIP-E,VIT最后一层被移除。大概有4.4B。
MLP adapter:2层MLP,用于将VIT的输出映射与词嵌入的文本特征相同的空间。
预训练语言模型:Vicuna-7B-V1.5.
visual expert模块:在语言模型的每一层上都加了visual expert,以实现深层次的视觉语言对齐,由一个QKV矩阵和一个MLP组成,和语言模型中的QKV矩阵,MLP的形状相同,并从语言模型中初始化,语言模型中的每个attention head捕捉语义信息,可训练的visual expert可以将图像特征转换为与不同的attention head对齐,从而实现深度融合。
2.2 pretraining
数据:
开源数据集:LAION-2B,COYO-700M,剔除有问题的,大概还有15亿张图像用于预训练。
构造一个40M的视觉grounding数据集,在LAION-115M中采样,GLIPv2预测,确保75%的图像都至少有2个边界框。
训练:第一阶段针对image captioning loss,即文本的下一个预测。将CogVLM-17B在15亿个图像文本对上进行了120k迭代训练,bs为8196,得到base模型;预训练第二阶段是Referring Expression Comprehension和image captioning混合训练,15亿图像-文本对,bs为1024,60k迭代,最后30k把图片尺寸从224提升到490,得到CogVLM Grounding model。REC通过给出对象的文本描述,预测图像中的边界框,以VQA的形式进行训练,即Question:对象在哪里?Answer:[[x0,y0,x1,y1]]。可训练参数为65亿,消耗4096个A100/天。
2.3 alignment
对CogVLM进行微调,使其能够与任何主题自由形式指令相对齐。微调之后的模型为CogVLM-chat。
数据:SFT从LLAVA-INstruct、LRV-INstruction、LLaVAR和内部数据集中收集,共计50w个VQA对。SFT至关重要,LLaVA-Instruct由GPT4生成,手动进行了纠错。
训练:8k迭代,bs为640,lr为10-5,warmup迭代次数为50,为了防止过度拟合数据中的文本答案,使用了较小的学习率来更新语言模型,SFT中除了VIT,所有参数都参与训练。
3.experiments