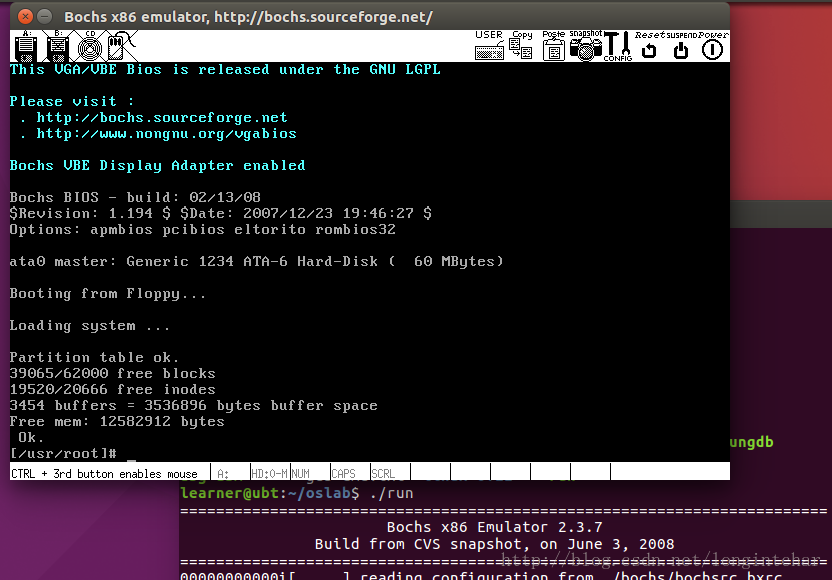
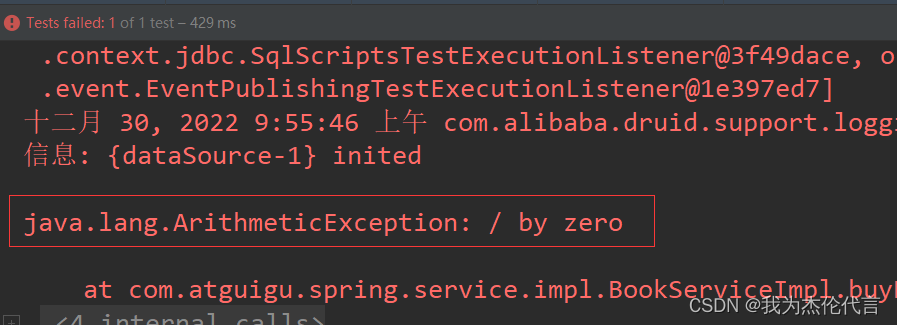
2022年某月,某运营商客户突然出现部分业务办理失败,数据无法入库的现象......

经过查询,应用进程insert提示:“ORA-14400”错误。由此诊断,故障出现是由于上月部分表分区未提前创建,导致本月前端业务在导入数据时,分区表中无匹配的分区导致业务数据无法写入,致使业务办理失败。
01
分区表有多重要?
对于应用系统的开发人员来讲,分区表应该是最简单、最常用的建表方式了,这也是海量数据规模下提升数据查询性能的重要手段。为了更加轻松的管理和查询数据,他们通常使用分区列值为时间的分区表来存储时间相关的数据,例如电商的订单信息、物联网采集的实时数据等等。这些时间相关的数据在导入分区表之前,需要保证分区表要有对应时间的分区才能顺利插入。
分区表拥有以下优点:
改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
增强数据可用性:数据分散到各个分区中,减少了数据全部损坏的风险,如果表的某个分区出现故障,表在其他分区的数据仍然可用。
维护更便利:如果表的某个分区出现故障,需要修复数据,只需要单独修复该分区即可。
均衡I/O:可以将分区映射到不同的物理磁盘上,来分散数据读写IO,提高整个系统的性能。
02
分区表的创建
分区表虽然好用,但仍然需要DBA花精力维护。在客户的生产环境中,很难保证所需的分区表都已经被提前创建好,分区表创建得过多过细,会影响数据库性能;同时也可能存在没有数据的历史分区,需要DBA及时地drop掉。一个已长久运行的应用系统可能会有成百上千的分区表,随着时间的推移,有些分区表的预留分区即将消耗殆尽,影响未来业务数据导入.....如此种种风险都隐藏在业务运行当中。
此时部分运维经验丰富的同仁可能就要说了,“早在 Oracle 11g就已经具备自动创建分区(Interval Partition)特性,通过此项功能可以在输入相应分区的数据时就自动创建相应分区,无需DBA去操作干预新分区的添加!”
(某DBA的心理活动.....)

事实上,Oracle 的Interval特性并不适用于所有场景,支持范围有限,仅有NUMBER和TIME两种类型。而往往正是因为是通过系统自动创建分区名称,我们无法通过分区名称来判断数据存放位置,增加了后期的维护难度。例如,如果是DBA手动维护,假设表的分区”part_201901“存储的就是2019年1月的数据,假如我们想要删除1月份的数据,直接删除该分区即可,如果数据库里面有500个类似的表,直接写批量脚本”ALTER TABLE <table_name> DROP PARTITION part_201901“就将全部表的1月份的数据删除了。但是对于系统自动创建的分区,在不同的表里面,2019年1月的数据对应的分区名不同,自然无法使用脚本批量删除,即使有脚本,也非常麻烦。
因此每到年底,对于运营商、电力等大型客户而言,运维部门都要花费巨大的精力对应用系统开发商、驻场人员进行统筹安排,确保跨年后应用系统可以正常运行,此时如果可以周期性、自动化地检查预留分区的可用时间就显得尤为重要。
03
未雨绸缪:zCloud 分区表巡检
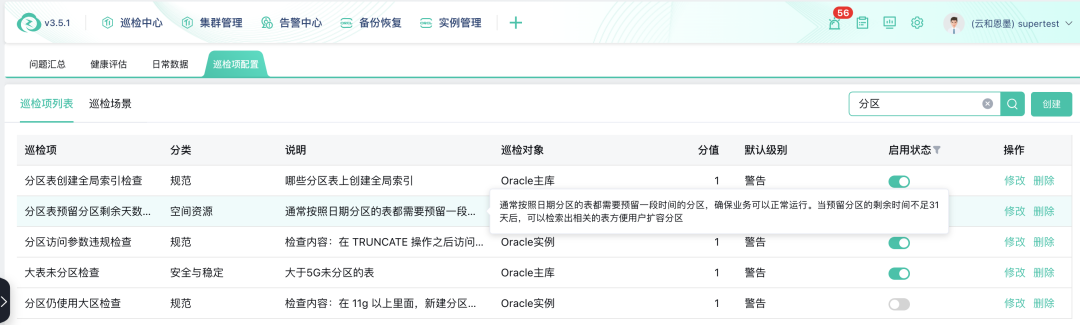
zCloud 数据库云管平台内置数百个基于最佳实践的巡检项,覆盖数据库空间资源、安全、性能、灾备等多个方面,包括“分区表未设置自动创建分区”“分区表创建全局索引检查”等多个与分区表相关的巡检项,其中“分区表预留分区剩余天数不足”这一巡检项在启用后,能够帮助用户发现 Oracle 数据库中所有存在预留分区不足风险的分区表,提醒用户及时操作下一步扩容分区,确保业务连续。同时通过 zCloud 自定义巡检场景,可将这一巡检项纳入日常巡检,帮助用户周期性、自动化的检查预留分区的可用时间。
年终已至,各位2023年的分区表创建好了吗?
快用 zCloud 巡检一下吧~
END
数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,以“数据驱动,成就未来”为使命,是智能的数据技术提供商。我们致力于将数据技术带给每个行业、每个组织、每个人,构建数据驱动的智能未来。
云和恩墨在数据承载(分布式存储、数据持续保护)、管理(数据库软件、数据库云管平台、数据技术服务)、加工(应用开发质量管控、数据模型管控、数字化转型咨询)和应用(数据服务化管理平台、数据智能、隐私计算数据联邦平台)等领域为各个组织提供可信赖的产品、服务和解决方案,围绕用户需求,持续为客户创造价值,激发数据潜能,为成就未来敏捷高效的数字世界而不懈努力。