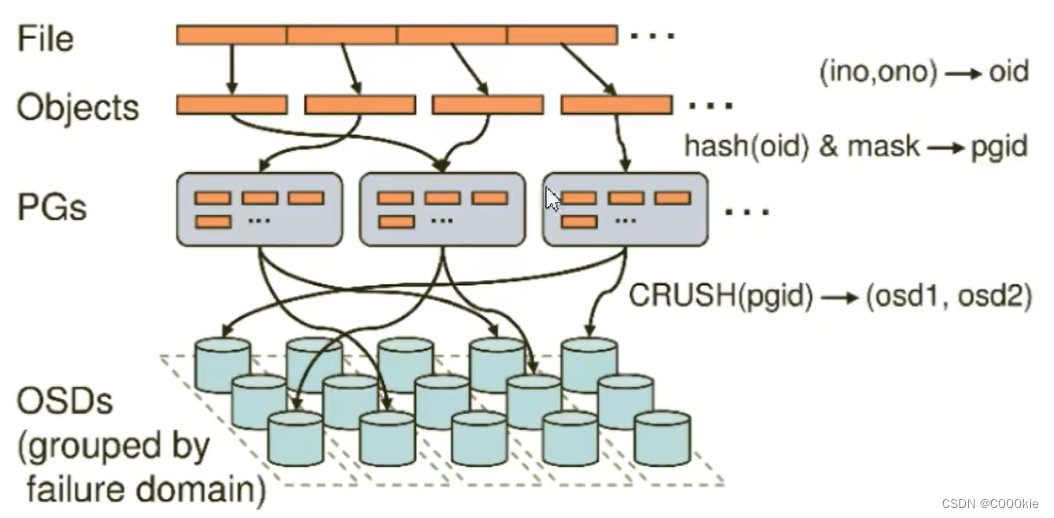
需求
对于应用系统而言,数据主要分为两大类,结构化数据和非结构化数据。
结构化数据通常是指可以明确定义其数据结构及属性的对象,如组织机构、用户、合同、订单等,通常都会使用关系型数据库来存储,通过SQL来读写。
非结构化数据,主要是文件类,如word、excel等office文档以及PDF、音频、视频、压缩包等二进制格式,无法明确定义数据结构,通常不会存放到关系型数据库的大字段中,而是另行存储,关系型数据库中只存放其引用,如磁盘路径或文件标识。
存储方案
非结构化数据的存储方案通常是以下三种:
- 存放到某些NoSQL数据库,如MongoDb
- 直接存储到服务器的磁盘
- 使用对象存储组件或系统,如minio、亚马逊S3云存储服务、阿里OSS等
方案1:NoSQL数据库
某些NoSQL数据库,具备了文件存储的能力,如MongoDB。
虽然比把文件放进传统的关系型数据库中的大字段的方式好一些,但不得不说,还是有其局限性,比如导致数据库的体积极速膨胀,进而对数据的读写性能、备份和恢复都产生一定的影响。中小系统或者系统中的一部分文档这么处理是可以考虑这么解决。
方案2:直接存储
直接存储到磁盘是中小型系统常见的处置方案,简单、实用。
方案3:对象存储组件
对象存储则是相当于在直接磁盘存储的基础上向前迈了一步,在使用方(应用系统)和服务方(底层存储,即磁盘)中间建了一座“桥”,附加了很多功能,如基于元数据的文档检索、数据逻辑隔离、读写权限控制等等。特别的是,一些对象存储系统通过冗余和算法,实现文件的高可用(在部分存储不可用的情况下仍能正常读写数据)。
因为做了抽象,所以使用方与服务方实现了解耦,从而具备了灵活更换文件存储组件的能力,当然前提是接口要一致,比如minio就兼容了亚马逊S3服务存储服务,如接口不一致,则仍需要一定的适配工作。
平台方案设计
文件的上传、下载、查看是平台的基础功能,需要综合考虑其处理和存储。
在本平台中,主要解决的是与业务实体关联的附件,不同场景下文件有大有小,小的有几十K到几十M的文档,大的有几百M到几G的音频视频文件。
前端
需要支持以下功能:
- 单文件上传
- 多文件上传
- 大文件上传
- 拖拽上传
- 切片
- 暂停
- 重试
- 分块
- 预估时间
- 进度展示
- 下载
不需要以下功能:
- 上传文件夹(上传文件夹通常做文档库、网盘场景中需要)
- 快传、秒传(快传、秒传往往只在互联网应用的网盘应用场景有需求,企业应用里都是些独立的,不重复的文件)
- 在线预览(文件格式多种多样,预览实现方案需另行考虑)
经过技术选型,前端集成vue-simple-uploader组件来实现。
后端
作为平台,需考虑支持多种文件存储方案,对于中小型系统,可以使用直接存储到磁盘这种简单实用的方式;对一中大型系统,能支持使用对象存储组件。
基于上述考虑,建立抽象层,通过接口定义对于文件的上传、下载、查看等功能,对于对象存储或文件服务器存储,本质上都是具体的存储实现方式。
通过功能类的具体实现,来支持多种存储模式,通过更改配置,可以灵活选择具体的存储方式,业务应用无感知。
平台内置磁盘存储和主流对象存储组件minio两种实现方案,如对接其他对象存储系统,如阿里OSS,通过系统集成的方式,实现预置的抽象接口,适配到阿里OSS的API即可。
关键问题及应对
前端大文件分块上传
业务系统中的文件,一般是两类,一类是word 、excel、ppt、pdf等文档,一般在几百K到几兆,对于这类文件,直接上传即可,不需要分片;另外一类则以音频视频为主要代表的大文件,几十M起步,几百兆到几G都有可能,对于这类文件,为了加快处理速度,提升用户体验,则需要进行分块上传。
前端选用vue-simple-uploader组件,内置了大文件分块上传功能,参数配置如下:
defaultOptions: {
target: import.meta.env.VITE_BASE_URL + this.serverUrl,
testChunks: false,
maxChunkRetries: 3,
simultaneousUploads:3,
chunkSize: 10240000,
query: {
entityType: this.entityType,
entityId: this.entityId,
moduleCode: this.moduleCode
},
headers: { 'X-Token': token },
generateUniqueIdentifier: () => {
// 获取唯一性标识
const uniqueId = shortid.generate()
return uniqueId + '-'
},
parseTimeRemaining(timeRemaining, parsedTimeRemaining) {
return parsedTimeRemaining
.replace(/\syears?/, '年')
.replace(/\days?/, '天')
.replace(/\shours?/, '时')
.replace(/\sminutes?/, '分')
.replace(/\sseconds?/, '秒')
}
},
statusText: {
success: '100%',
error: '失败',
uploading: '上传中',
paused: '暂停中',
waiting: '等待中'
}
}
以下是几个与分片上传相关的关键参数:
chunkSize:分块大小,单位是B,这里设置10240000代表按10M进行切片。需要注意的是,若最后一块的大小在两倍该数值以内,则默认会作为一块处理,即前面切片后剩余18M,不会切分为10M和8M的两块,而是会把18M当成一块来处理。如果你想每个块都小于该值,需要附加指定一个参数forceChunkSize,将该值设置为true,则上面的例子会将剩余的18M切分为10M和8M的两块。
testChunks:是否测试每个块是否在服务端已经上传了,该参数默认开启,意味着前端会发送请求,跟后端核对每块是否上传过,后端确认上传过了则不再上传,从而达到“秒传”功能,这里我设置为false,关闭该功能,是从需求角度出发,企业应用场景下文件大都是独立、不重复的,秒传的意义有限。
simultaneousUploads:并发上传数量,默认为3,一般情况下保持默认即可,可根据实际业务场景合理化调整,调大该值并不一定更优。
generateUniqueIdentifier:文件的唯一性标识,在分块场景下,该标识非常重要,后端需要依据该标识来将各个文件块通过合并来还原为整个文件。该表示需要保证唯一,之前采用了实体标识+时间戳的方式,一方面只是最可能降低了重复的概率,但在高并发情况下并不能保证不重复;另一方面过长,有32位。引入了前端生成唯一性标识的组件shortid,由shortid内部算法来保证唯一性,且优化后长度10位。
后端文件块合并
后端收到文件块后,需要将各文件块通过合并来还原为整个文件,合并的依据是文件的唯一性标识。但这里还有个问题,即需要所有文件块都上传成功后再进行文件合并操作。
如何判断所有文件块都上传成功,这里有两种处理方案:
方案1:后端在每个文件块上传成功后,判断已上传文件块数量是否与文件分块数量一致。
方案2:前端监听文件上传完成事件,主动调用后端的文件合并操作。
经评估,采用方案1的方式,后端在每次文件块上传成功时判断,在高并发情况下可能存在问题。而前端文件上传组件的文件上传完成组件,是在每个文件块都上传完成(收到后端确认)的情况下才会触发,因此方案2更准确也更合理。
方案1实现方案核心判断逻辑如下:
@Override
public boolean checkIsLastChunk(FileChunk fileChunk) {
// TODO 此种处理方式不太踏实,是否会遇到并发问题???
// 获取临时文件路径
String tempPath = fileChunk.getPath() + FileConstant.TEMP_PATH;
String fullPath = getFullPath(tempPath);
// 获取该路径下以id开始的文件
File dir = FileUtils.getFile(fullPath);
FilenameFilter filenameFilter = new PrefixFileFilter(fileChunk.getIdentifier());
String[] fileList = dir.list(filenameFilter);
// 验证块数量是否匹配
if (fileList != null && fileList.length == fileChunk.getTotalChunks()) {
return true;
}
return false;
}
在高并发的情况下,有可能有两个文件块都判断自己并非是最后一块,从而无法触发文件块合并操作。
下面重点来说说方案2的实现。
vue-simple-uploader是基于simple-uploader.js的二次封装,前者文档资料很少,https://github.com/simple-uploader/Uploader/blob/develop/README_zh-CN.md,属性、方法、事件往往需要查阅后者https://github.com/simple-uploader/Uploader/blob/develop/README_zh-CN.md。
首先,通过查询simple-uploader的文档,文件上传成功会触发事件fileSuccess
.fileSuccess(rootFile, file, message, chunk) 一个文件上传成功事件,第一个参数 rootFile 就是成功上传的文件所属的根 Uploader.File 对象,它应该包含或者等于成功上传文件;第二个参数 file 就是当前成功的 Uploader.File 对象本身;第三个参数就是 message 就是服务端响应内容,永远都是字符串;第四个参数 chunk 就是 Uploader.Chunk 实例,它就是该文件的最后一个块实例,如果你想得到请求响应码的话,chunk.xhr.status 就是。
原本想在这个事件里来触发文件合并操作,如下:
fileSuccess(rootFile) {
this.$api.support.attachment.mergeChunks(rootFile).then(() => {
this.$refs.uploader.uploader.removeFile(rootFile)
})
}
这时候坑点出现了,在浏览器控制台打印chunk参数,如下图所示:

这里的文件块对象,实际跟vue-simple-uploader上传文件块使用fileChunk,根本就不是一个对象,数据结构并不相同。
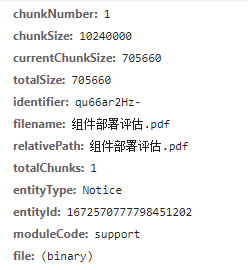
如何解决呢?其实我们合并文件并不需要文件块的所有信息,但必须拿到关键信息,尝试打印file参数
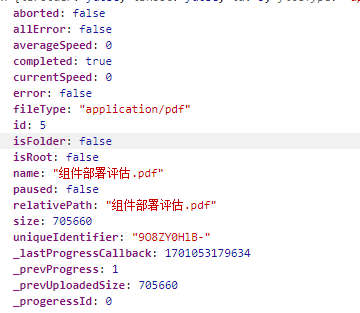
从里面可以拿到文件唯一性标识(uniqueIdentifier)和原始文件名(name),但还不够,我们还需要路径,而路径是通过自定义参数模块编码(moduleCode)和实体类型(entityType)来生成的,这两个参数vue-simple-uploader并没有传递到fileSuccess事件中,我们从外部输入。
fileSuccess(rootFile, file) {
const param = {
uniqueIdentifier: file.uniqueIdentifier,
fileName: file.name,
moduleCode: this.moduleCode,
entityType: this.entityType
}
this.$api.support.attachment.mergeChunks(param).then(() => {
this.$refs.uploader.uploader.removeFile(rootFile)
})
}
还有一个问题,对于体积低于分块大小配置2倍的文件,并不需要合并文件块,然后查看file对象,属性chunks是一个数组,元素个数即分块数量,如下图所示:
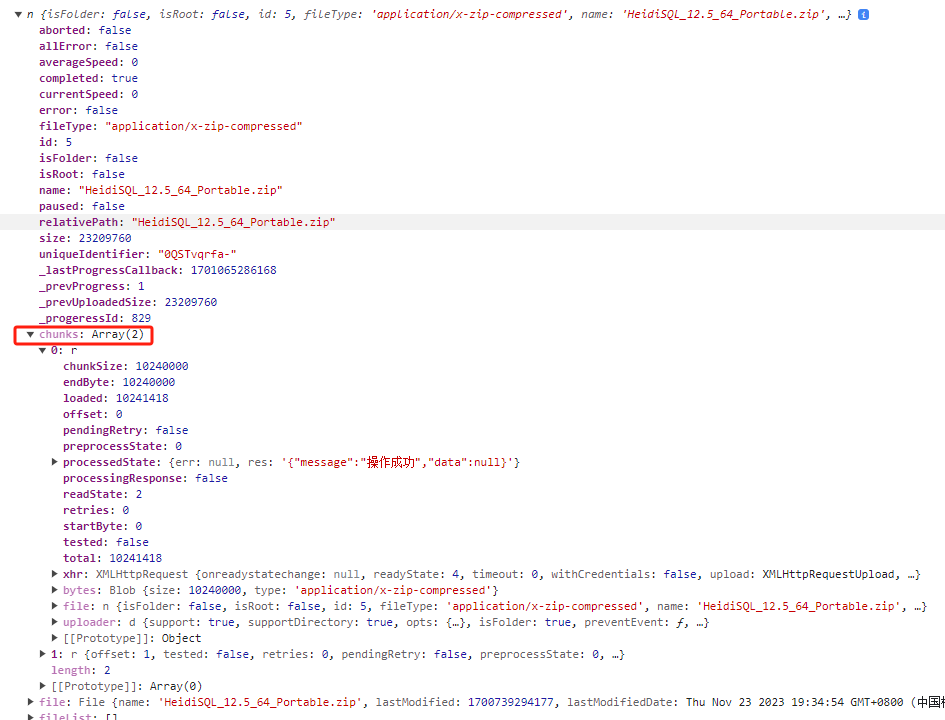
因此我们再加一层逻辑判断:
fileSuccess(rootFile, file) {
if (file.chunks.length > 1) {
//分块上传
const param = {
identifier: file.uniqueIdentifier,
filename: file.name,
moduleCode: this.moduleCode,
entityType: this.entityType
}
// 合并文件块
this.$api.support.attachment.mergeChunks(param).then(() => {
// 移除已上传成功的文件
this.$refs.uploader.uploader.removeFile(file)
})
} else {
// 不分块,移除已上传成功的文件
this.$refs.uploader.uploader.removeFile(file)
}
}
开源平台资料
平台名称:一二三开发平台
简介: 企业级通用开发平台
设计资料:csdn专栏
开源地址:Gitee
开源协议:MIT
欢迎收藏、点赞、评论,你的支持是我前行的动力。