作者:谭婧
(一)指令数据,了解一下
先聊一件圈内趣事:
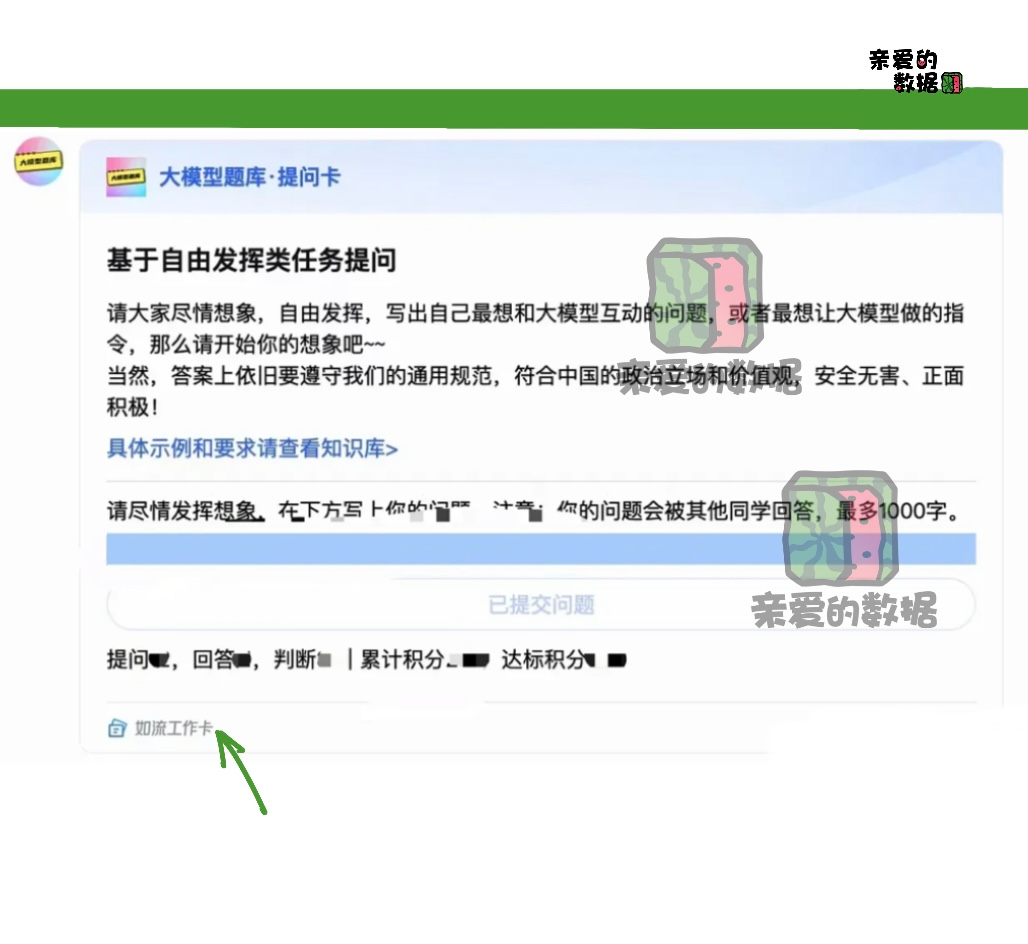
2023年初,大约在1月到2月份前后,
百度公司如流工作卡上有一个任务,
让百度员工打开脑洞,写“问答对”。
一问一答都让员工设计。
如流是百度员工内部通讯,相当于企业微信。
我推测此举很可能是在充实其“指令数据集”。
百度的做法是非常科学的指令数据集构造方法。
指令数据(Instruct data)是一种用于训练大模型的数据类型。
通常以有问有答的形式呈现。
在一问一答中传递信息,非常直观。
这种形式更接近人类的交流方式,
经过训练,能够更直接地引导大模型“行为”。
对比预训练环节的数据多来自于互联网数据爬取,需要经过清洗,抽取等冗长过程,指令数据的构造是另一种难度。
问题以一种人类真实需求来表达,不能瞎编。
答案则是尽量正确,且有针对性的回答,不能乱造。
例如,回答“今天天气怎么样?”时,
不能说“很好”,
而应该说“今天天气晴朗,气温为20℃,风力微弱。”
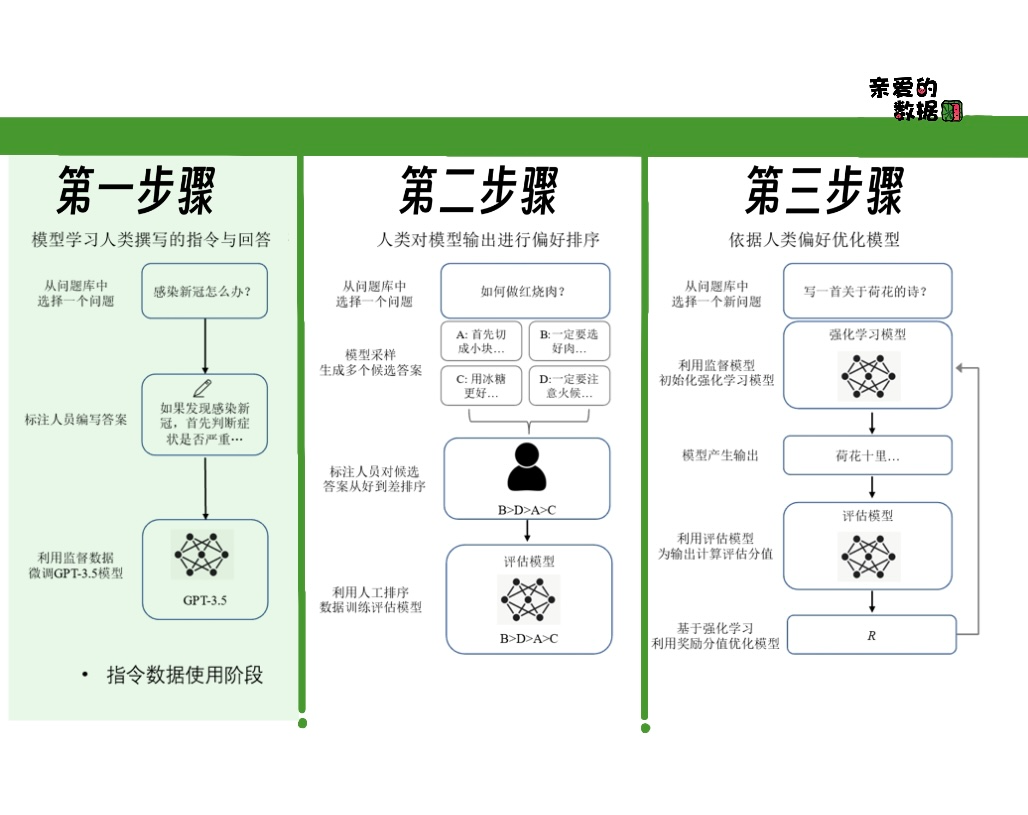
大语言模型的知识主要是在预训练期间学习的。
大语言模型“炼成后”,仍需“三大”步骤;
在第一个步骤中,通过指令数据进行有监督学习,至关重要。
指令(Instruct)可以简单理解为,
“命令”“指示”“指挥”,就是人类下达指令“让”大模型“干活”:
写封信,写首诗,写代码,等等。
比如,闲聊中也会有问有答的句子,但明显不同于指令数据,指令数据的内容针对问题来回答,所以针对性强。闲聊数据中找问答对,效率太低。
从学术人员的角度,
以前是小模型百花齐放的世界,一个模型干一件事(任务)。
现在是大模型一统天下,一个大模型能干得活可太多了,不能乱指挥,
得有一直方式让它知道你想干啥。
人类写好的一问一答的这种方式,
很适合大模型学习。
指令数据的微调让大模型多遵循指令,
少胡编事实。

指令(Instruct)和提示词(Prompt)的区别?
两者的相同之处在于都可以引导模型。
通常来说,指令更强调对模型的具体要求,让其执行某个特定的任务,
而提示词更广泛,可能是一个问题、一个主题或一个启发性的语境。
大家观察GPT-3.5,喜欢参考Instruct-GPT的论文,看看论文里怎么说:
“我们收集了一个数据集,并使用此数据集做训练,让模型学习和参考,期望大模型的输出像人类已经编写好的例子这样。”

浪潮信息人工智能软件研发总监吴韶华的观点是,模型对于训练数据集学习能力是非常强的,高质量数据成为大模型决胜关键。
他谈到的例子让人印象深刻:
“在源1.0研发的时候,数据主要来自于互联网,我们从2017年到2021年之间互联网数据里边搜集出来了差不多800TB互联网数据。
我们清理出来大约5TB比较高质量数据,分析发现,哪怕应用很多的优化手段,数据质量依然不够高,依然会有噪声。
于是,在源2.0研发的时候,我们在数据方面做了大量的工作。
首先,大幅降低了来自互联网的数据占比,为了获得高质量数学数据,我们清洗了从2018到2023年之间互联网页,试图获取中文数学数据;我们开始处理的原始数据体量高达12PB,但最后获得的中文数学数据数据量不到10GB。
从12PB到小于10GB,大家可以想一下是什么概念。
高质量的数据非常难以获得。
为了弥补高质量数据的缺失,我们下了额外的功夫:
在预训练数据构建的时候,我们用大模型生成了一部分合成数据,比如部分代码数据,部分数学数据。
我们构建了一套基于大模型生成合成数据的工作流,通过这种形式可以保证生成数据的多样性,在每个类目里边保证数据的质量,通过这形式我们构建了一个比较完备的预训练数据集。
当然,类似的方式我们也用在了构建微调数据集上面。”

一般说来,有些数据既可以处理成预训练数据,
也可以处理成指令数据,取决于处理的方法。
(二)开源指令数据集
目前,大部分大模型团队都有自建指令数据集,很多不愿意公开。
开源的指令数据应该很多元。
按任务可以分为:数学能力,文本改编,知识问答,编程,标题生成,逻辑推理等。
程序算作计算机可执行的语言,和文字不做区分,都算做语言。
比如,“帮我用python语言实现排序算法。”
大模型回复的是代码,代码可以执行.
这对指令数据中,含有的内容以代码为主。
解数学题的过程则属于逻辑推理。
指令数据也可以分为单模态和多模态;
多模态的数据集会在问答中含有图片,声音,视频等数据类型,比如,听歌识歌名,就需要音乐和文本的问答对进行训练。
这篇主要聊单模态。
“指令数据”全是人类手写也非常麻烦,所以,有一些是生成的。
生成的时候,因为问题和答案都是生的,所以要进行筛选。
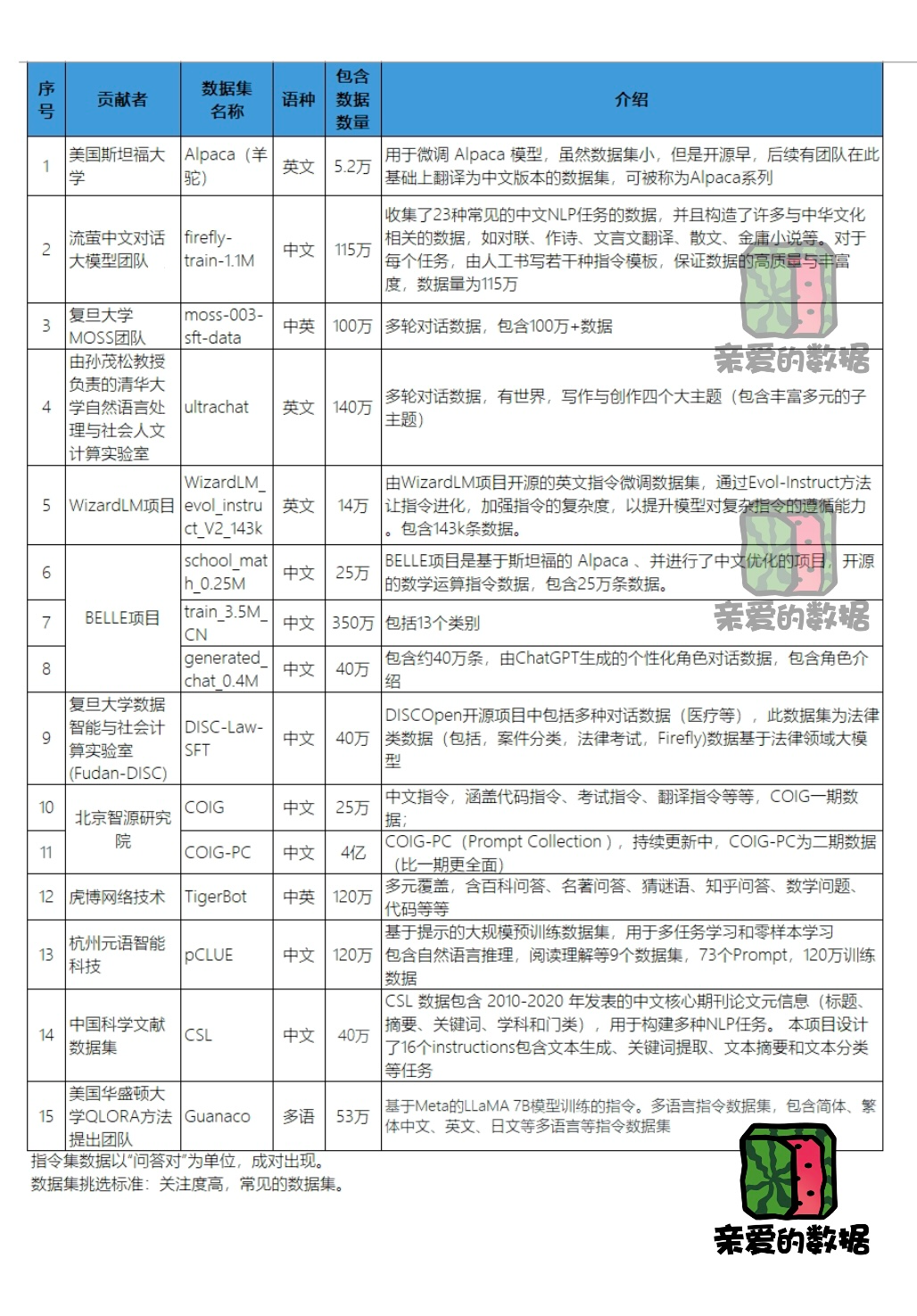
为了纵览中文视角下的全球开源指令数据集情况,
“亲爱的数据”做了一个盘点:
(三)提高质量的“魔法”
一位AI工程师告诉我:“敢开源,能开源的团队,都有点东西。”
我深以为意。
虽然不是每一次开源都让人兴奋,但是开源后,到底质量怎么样,有目共睹。
至少自信和敢作敢为这一波,力量是拉满了。
获得高质量数据这件事,是费时费力费人的工程活。
猛一看,技术含量不高,
细一看,大家都不愿意开源,可见技术含量藏的有点深。
我观察认为,有大模型训练实际经验的团队,比研究团队更有动力干这件事。
武汉人工智能研究院用一篇论文公开了他们构建指令数据集的方法。
实际上,武汉人工智能研究一直在研发迭代“紫东太初大模型”,他们对指令数据集的需求,来源于真实的复杂工程需求。
论文的方法,也是“紫东太初”大模型在用的方法。
省流版本是:
对于指令数据集来说,需要先定义什么是好问题好答案。
问题和答案的覆盖度足够全,有写代码,写作业,写信等形形色色的事情;1000个问题不能总在聊“吃”这个话题。
再定义什么是好答案。
武汉人工智能研究院的实践是训练了一个判断答案问答对质量的打分模型。
打分模型也是原创训练,基座还是语言模型,优化目标变成排序。给定一个任务,给出候选答案。标注好坏,训练结束,就具备了打分的功能。然后就能针对开源的指令数据打成绩单。
喂给模型,就会得到质量得分。
一千对问答,一千个分数。
高分留下,低分不要。
以分数来筛选。
更为详细的做法,可参见论文:
MoDS: Model-oriented Data Selection for Instruction Tuning
《MoDS:面向模型的指令数据选择》。

我认为论文题目可以叫,大模型指令数据高效选择方法MoDS。
论文回答了,如何为LLM选择合适的指令数据?
论文作者为:杜倩龙、宗成庆、张家俊。

武汉人工智能研究院副院长的张家俊教授是论文作者之一,
他向我强调,
我们提出一种新颖的指令数据选择方法。
大家通常关注指令数据的两个方面:
一个是指令数据质量高不高,
另外一个方面指令数据的多样性覆盖度够不够。
但是很多时候会忽略一点,
每个大模型都有自身的特点,每个大模型训练数据不一样,模型架构不一样,训练参数又不一样,很显然不是每一个模型都应该用相同的指令数据。
为什么?
比如,有一些大模型这条指令给它的时候发现完成地非常好,或者有一些指令推理的时候,你发现这些指令完成地不够好,非常差。
本质上,非常差的指令才是需要去提升的能力。
因此,我们还提出来另外一个角度,数据必要性。
即从指令数据的质量、数据覆盖度和数据必要性三个角度衡量指令数据。

我理解,大模型所蕴含的知识是在预训练阶段内化到大语言模型里,而不是到指令微调阶段才开始“补课”,指令微调起到激发引导大模型的作用。
不同大模型的能力不同,我们引导的工具也应该不同。
就好比,一个大学生和一个小学生,你要教他们一人一个技能,是不是应该用不同的方法?
因此,论文中强调每个大语言模型都应该有一套与其相匹配的指令数据集;也就是我们常常看到的现象:训练GPT-4与LLaMA肯定不应该用一样的指令数据。
顺着这个逻辑,正是因为各种大模型所需的指令数据集不同,
我们就更需要“通用的指令数据筛选工具。
(完)


《我看见了风暴:人工智能基建革命》,作者:谭婧

更多阅读
AI大模型与ChatGPT系列:
1. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
2. ChatGPT:绝不欺负文科生
3. ChatGPT触类旁通的学习能力如何而来?
4. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
5. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
6. ChatGPT大模型用于刑侦破案只能是虚构故事吗?
7. 大模型“云上经济”之权力游戏
8. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
9. 深聊第四范式陈雨强丨如何用AI大模型打开万亿规模传统软件市场?
10. 深聊京东科技何晓冬丨一场九年前的“出发”:奠基多模态,逐鹿大模型
11. 老店迎新客:向量数据库选型与押注中,没人告诉你的那些事
12. 微调真香,漫画科技博主竟然在用国产大模型生成系列漫画女主角
13. 大模型“搅局”,数据湖,数据仓库,湖仓选型会先淘汰谁?
14. 大模型用于腾讯广告,难在哪?
15. 搞掂大模型,如何榨干每一滴算力?
16. 假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
长文
1. 深聊科大讯飞刘聪丨假如对大模型算法没把握,错一个东西,三个月就过去了
2. 深聊武汉人工智能研究院张家俊丨 “紫东太初”大模型背后有哪些值得细读的论文(一)
3. 深聊武汉人工智能研究院王金桥丨紫东太初:造一个国产大模型,需用多少篇高质量论文?(二)
4. 为何重视提示工程?
5. 跳槽去搞国产大模型,收入能涨多少?
6. AI咆哮后,一个赚大钱的AI+Data公司估值居然430亿美元?
7. 抢滩大模型,抢单公有云,Databricks和Snowflake用了哪些“阳谋”?
8. 大模型下一场战事,为什么是AI Agent?
漫画系列
1. 是喜,还是悲?AI竟帮我们把Office破活干完了
2. AI算法是兄弟,AI运维不是兄弟吗?
3. 大数据的社交牛气症是怎么得的?
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
6. 给王心凌打Call的,原来是神奇的智能湖仓
7. 原来,知识图谱是“找关系”的摇钱树?
8. 为什么图计算能正面硬刚黑色产业薅羊毛?
9. AutoML:攒钱买个“调参侠机器人”?
10. AutoML:你爱吃的火锅底料,是机器人自动进货
11. 强化学习:人工智能下象棋,走一步,能看几步?
12. 时序数据库:好险,差一点没挤进工业制造的高端局
13. 主动学习:人工智能居然被PUA了?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
16. 数据中心网络:迟到不可怕,可怕的是别人都没迟到
17. 漫画:大模型用于腾讯广告,难在哪?
AI框架系列:
1.搞深度学习框架的那帮人,不是疯子,就是骗子(一)
2.搞AI框架那帮人丨燎原火,贾扬清(二)
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)仅收录于《我看见了风暴》。