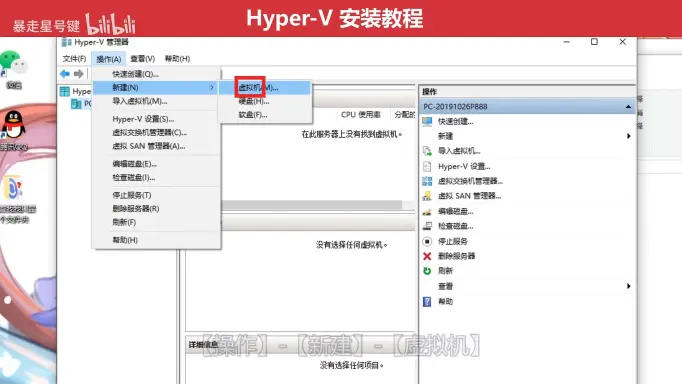
感谢
感谢艾兄(大佬带队)、rich师弟(师弟通过这次比赛机械转码成功、耐心学习)、张同学(也很有耐心的在学习),感谢开源方案(开源就是银牌),在此基础上一个月不到收获到了很多,运气很好。这个是我们比赛的总结:
我们队Kaggle CMI银牌方案,欢迎感兴趣的伙伴upvote:https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459610
计划 (系统>结果,稳健>取巧)
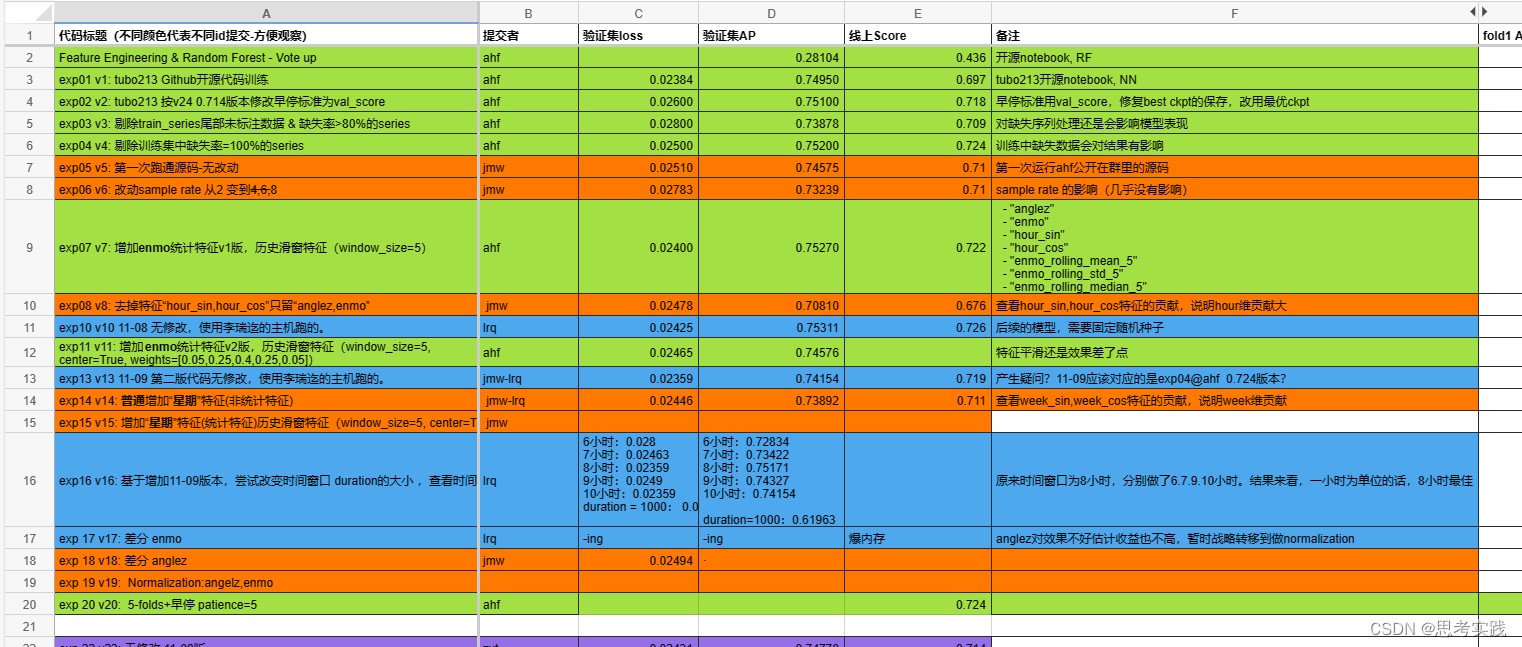
团队计划表,每个人做的那部分工作,避免重复,方便交流,提高效率,这个工作表起了很大的作用。
具体方案
75th Place Detailed Solution - Spec2DCNN + CenterNet + Transformer + NMS
First of all, I would like to thank @tubotubo for sharing your high-quality code, and also thank my teammates @liruiqi577 @brickcoder @xtzhou for their contributions in the competition. Here, I am going to share our team’s “snore like thunder” solution from the following aspects:
- Data preprocessing
- Feature Engineering
- Model
- Post Processing
- Model Ensemble
1. Data preprocessing
We made EDA and readed open discussions found that there are 4 types of data anomalies:
- Some series have a high missing rate and some of them do not even have any event labels;
- In some series , there are no event annotations in the middle and tail (possibly because the collection activity has stopped);
- The sleep record is incomplete (a period of sleep is only marked with onset or wakeup).
- There are outliers in the enmo value.
To this end, we have some attempts, such as:
- Eliminate series with high missing rates;
- Cut the tail of the series without event labels;
- Upper clip enmo to 1.
But the above methods didn't completely work. In the end, our preprocessing method was:
We split the dataset group by series into 5 folds. For each fold, we eliminate series with a label missing rate of 100% in the training dataset while without performing any data preprocessing on the validation set. This is done to avoid introducing noise to the training set, and to ensure that the evaluation results of the validation set are more biased towards the real data distribution, which improve our LB score + 0.006.
Part of our experiments as below:
| Experiment | Fold0 | Public (single fold) | Private (5-fold) |
|---|---|---|---|
| No preprocess missing data | 0.751 | 0.718 | 0.744 |
| Eliminate unlabeled data at the end of train_series & series with missing rate >80% | 0.739 | 0.709 | 0.741 |
| Drop train series which don’t have any event labels | 0.752 | 0.724 | 0.749 |
2. Feature Engineering
- Sensor features: After smoothing the enmo and anglez features, a first-order difference is made to obtain the absolute value. Then replace the original enmo and anglez features with these features, which improve our LB score + 0.01.
train_series['enmo_abs_diff'] = train_series['enmo'].diff().abs()
train_series['enmo'] = train_series['enmo_abs_diff'].rolling(window=5, center=True, min_periods=1).mean()
train_series['anglez_abs_diff'] = train_series['anglez'].diff().abs()
train_series['anglez'] = train_series['anglez_abs_diff'].rolling(window=5, center=True, min_periods=1).mean()
- Time features: sin and cos hour.
In addition, we also made the following features based on open notebooks and our EDA, such as: differential features with different orders, rolling window statistical features, interactive features of enmo and anglez (such as anglez's differential abs * enmo, etc.), anglez_rad_sin/cos, dayofweek/is_weekend (I find that children have different sleeping habits on weekdays and weekends). But strangely enough, too much feature engineering didn’t bring us much benefit.
| Experiment | Fold0 | Public (5-fold) | Private (5-fold) |
|---|---|---|---|
| anglez + enmo + hour_sin + hour_cos | 0.763 | 0.731 | 0.768 |
| anglez_abs_diff + enmo_abs_diff + hour_sin + hour_cos | 0.771 | 0.741 | 0.781 |
3. Model
We used 4 models:
- CNNSpectrogram + Spec2DCNN + UNet1DDecoder;
- PANNsFeatureExtractor + Spec2DCNN + UNet1DDecoder.
- PANNsFeatureExtractor + CenterNet + UNet1DDecoder.
- TransformerAutoModel (xsmall, downsample_rate=8).
Parameter Tunning: Add more kernel_size 8 for CNNSpectrogram can gain +0.002 online.
Multi-Task Learning Objectives: sleep status, onset, wake.
Loss Function: For Spec2DCNN and TransformerAutoModel, we use BCE, but with multi-task target weighting, sleep:onset:wake = 0.5:1:1. The purpose of this is to allow the model to focus on learning the last two columns. We tried to train only for the onset and wake columns, but the score was not good. The reason is speculated that the positive samples in these two columns are sparse, and MTL needs to be used to transfer the information from positive samples in the sleep status to the prediction of sleep activity events. Also, I tried KL Loss but it didn't work that well.
self.loss_fn = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([0.5,1.,1.]))
At the same time, we adjusted epoch to 70 and added early stopping with patience=15. The early stopping criterion is the AP of the validation dataset, not the loss of the validation set. batch_size=32.
| Experiment | Fold0 | Public (single fold) | Private (5-fold) |
|---|---|---|---|
| earlystop by val_loss | 0.750 | 0.697 | 0.742 |
| earlystop by val_score | 0.751 | 0.718 | 0.744 |
| loss_wgt = 1:1:1 | 0.752 | 0.724 | 0.749 |
| loss_wgt = 0.5:1:1 | 0.755 | 0.723 | 0.753 |
Note: we used the model_weight.pth with the best offline val_score to submit our LB instead of using the best_model.pth with the best offline val_loss。
4. Post Processing
Our post-processing mainly includes:
- find_peaks(): scipy.signal.find_peaks;
- NMS: This task can be treated as object detection. [onset, wakeup] is regarded as a bounding boxes, and score is the confident of the box. Therefore, I used a time-series NMS. Using NMS can eliminate redundant boxes with high IOU, which increase our AP.
def apply_nms(dets_arr, thresh):
x1 = dets_arr[:, 0]
x2 = dets_arr[:, 1]
scores = dets_arr[:, 2]
areas = x2 - x1
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
inter = np.maximum(0.0, xx2 - xx1 + 1)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
dets_nms_arr = dets_arr[keep,:]
onset_steps = dets_nms_arr[:, 0].tolist()
wakeup_steps = dets_nms_arr[:, 1].tolist()
nms_save_steps = np.unique(onset_steps + wakeup_steps).tolist()
return nms_save_steps
In addition, we set score_th=0.005 (If it is set too low, a large number of events will be detected and cause online scoring errors, so it is fixed at 0.005 here), and use optuna to simultaneously search the parameter distance in find_peaks and the parameter iou_threshold of NMS. Finally, when distance=72 and iou_threshold=0.995, the best performance is achieved.
import optuna
def objective(trial):
score_th = 0.005 # trial.suggest_float('score_th', 0.003, 0.006)
distance = trial.suggest_int('distance', 20, 80)
thresh = trial.suggest_float('thresh', 0.75, 1.)
# find peak
val_pred_df = post_process_for_seg(
keys=keys,
preds=preds[:, :, [1, 2]],
score_th=score_th,
distance=distance,
)
# nms
val_pred_df = val_pred_df.to_pandas()
nms_pred_dfs = NMS_prediction(val_pred_df, thresh, verbose=False)
score = event_detection_ap(valid_event_df.to_pandas(), nms_pred_dfs)
return -score
study = optuna.create_study()
study.optimize(objective, n_trials=100)
print('Best hyperparameters: ', study.best_params)
print('Best score: ', study.best_value)
| Experiment | Fold0 | Pubic (5-fold) | Private (5-fold) |
|---|---|---|---|
| find_peak | - | 0.745 | 0.787 |
| find_peak+NMS+optuna | - | 0.746 | 0.789 |
5. Model Ensemble
Finally, we average the output probabilities of the following models and then feed into the post processing methods to detect events. By the way, I tried post-processing the detection events for each model and then concating them, but this resulted in too many detections. Even with NMS, I didn't get a better score.
The number of ensemble models: 4 (types of models) * 5 (fold number) = 20.
| Experiment | Fold0 | Pubic (5-fold) | Private (5-fold) |
|---|---|---|---|
| model1: CNNSpectrogram + Spec2DCNN + UNet1DDecoder | 0.77209 | 0.743 | 0.784 |
| model2: PANNsFeatureExtractor + Spec2DCNN + UNet1DDecoder | 0.777 | 0.743 | 0.782 |
| model3: PANNsFeatureExtractor + CenterNet + UNet1DDecoder | 0.75968 | 0.634 | 0.68 |
| model4: TransformerAutoModel | 0.74680 | - | - |
| model1 + model2(1:1) | - | 0.746 | 0.789 |
| model1 + model2+model3(1:1:0.4) | - | 0.75 | 0.786 |
| model1 + model2+model3+model4(1:1:0.4:0.2) | 0.752 | 0.787 |
Unfortunately, we only considered CenterNet and Transformer to model ensemble with a tentative attitude on the last day, but surprisingly found that a low-CV-scoring model still has a probability of improving final performance as long as it is heterogeneous compared with your previous models. But we didn’t have more opportunities to submit more, which was a profound lesson for me.
Thoughts not done:
-
Data Augmentation: Shift the time within the batch to increase more time diversity and reduce dependence on hour features.
-
Model: Try more models. Although we try transformer and it didn’t work for us. I am veryyy looking forward to the solutions from top-ranking players.
Thanks again to Kaggle and all Kaggle players. This was a good competition and we learned a lot from it. If you think our solution is useful for you, welcome to upvote and discuss with us.
In addition, this is my first 🥈 silver medal. Thank you everyone for letting me learn a lot. I will continue to work hard. :)