目录
- 前言
- 引言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 模型构建
- 3. 模型训练及保存
- 4. 模型生成
- 系统测试
- 1. 训练准确率
- 2. 测试效果
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰写一篇关于方言分类的博客,以满足读者对这一主题的进一步了解和探索的需求。上篇博客可参考:
《基于Python+WaveNet+CTC+Tensorflow智能语音识别与方言分类—深度学习算法应用(含全部工程源码)》
引言
本项目以科大讯飞提供的数据集为基础,通过特征筛选和提取的过程,选用WaveNet模型进行训练。旨在通过语音的梅尔频率倒谱系数(MFCC)特征,建立方言和相应类别之间的映射关系,解决方言分类问题。
首先,项目从科大讯飞提供的数据集中进行了特征筛选和提取。包括对语音信号的分析,提取出最能代表语音特征的MFCC,为模型训练提供有力支持。
其次,选择了WaveNet模型进行训练。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。
在训练过程中,利用语音的MFCC特征,建立了方言和相应类别之间的映射关系。这样,模型能够识别和分类输入语音的方言,并将其划分到相应的类别中。
最终,通过这个项目,实现了方言分类问题的解决方案。这对于语音识别、语音助手等领域具有实际应用的潜力,也有助于保护和传承各地区的语言文化。
总体设计
本部分包括系统整体结构图和系统流程图。
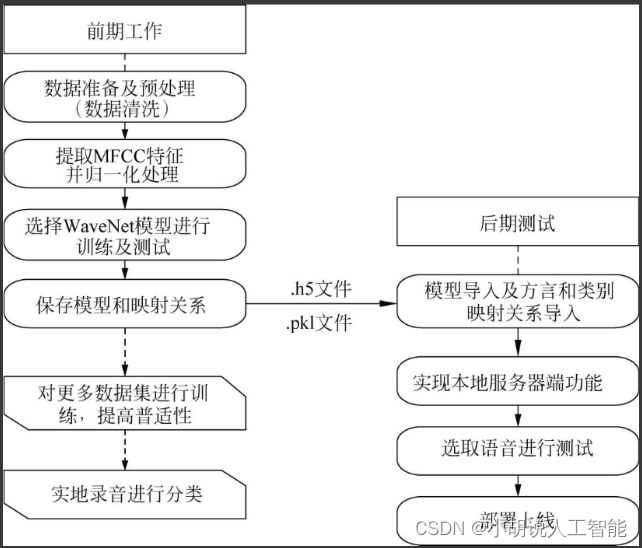
系统整体结构图
系统整体结构如图所示。
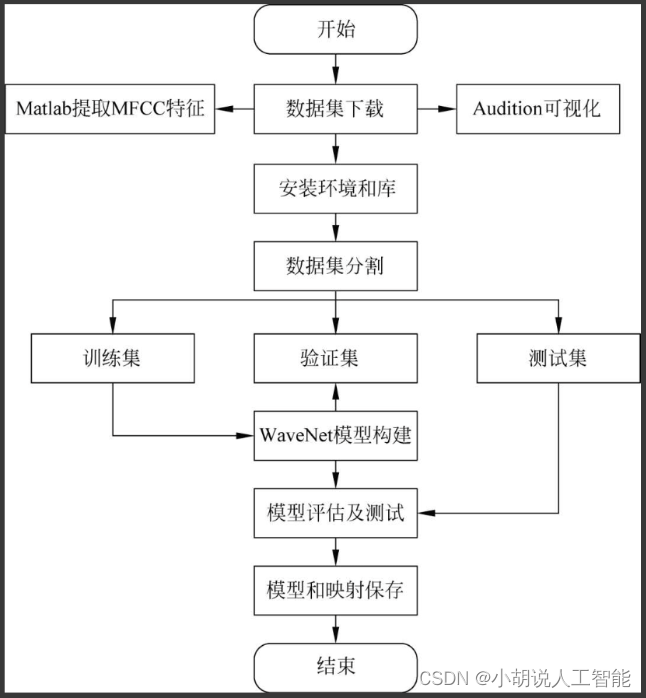
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据介绍、数据测试和数据处理。
详见博客。
2. 模型构建
数据加载进模型之后,需要定义模型结构并优化损失函数。
详见博客。
3. 模型训练及保存
本部分包括模型训练、模型保存和映射保存。
详见博客。
4. 模型生成
将训练好的.h5模型文件放入总目录下:信息系统设计方言种类识别/fangyan.h5。
相关代码如下:
#打开映射
with open('resources.pkl', 'rb') as fr:
[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
model = load_model('fangyan.h5')
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
将保存的方言和种类之间映射关系.pkl文件放到总文件目录下:信息系统设计/方言种类识别/resources.pkl。相关代码如下:
#打开保存的方言和种类之间的映射
with open('resources.pkl', 'rb') as fr:
[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
在单机上加载训练好的模型,随机选择一条语音进行分类。新建测试主运行文件main.py,加载库之后,调用生成的模型文件获得预测结果。
相关代码如下:
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
#通过random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label = path.split('/')[1]
print(label, path)
#本部分的相关代码
# -*- coding:utf-8 -*-
import numpy as np
from keras.models import load_model
from keras.preprocessing.sequence import pad_sequences
import librosa
from python_speech_features import mfcc
import pickle
import wave
import glob
#打开映射
with open('resources.pkl', 'rb') as fr:
[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
model = load_model('fangyan.h5')
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
#通过random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label = path.split('/')[1]
print(label, path)
#语音分片处理
mfcc_dim = 13
sr = 16000
min_length = 1 * sr
slice_length = 3 * sr
#提取语音信号的参数
def load_and_trim(path, sr=16000):
audio = np.memmap(path, dtype='h', mode='r')
audio = audio[2000:-2000]
audio = audio.astype(np.float32)
energy = librosa.feature.rmse(audio)
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
slices = []
for i in range(0, audio.shape[0], slice_length):
s = audio[i: i + slice_length]
slices.append(s)
return audio, slices
#提取MFCC特征进行测试
audio, slices = load_and_trim(path)
X_data = [mfcc(s, sr, numcep=mfcc_dim) for s in slices]
X_data = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_data]
maxlen = np.max([x.shape[0] for x in X_data])
X_data = pad_sequences(X_data, maxlen, 'float32', padding='post', value=0.0)
print(X_data.shape)
#预测方言种类并输出
prob = model.predict(X_data)
prob = np.mean(prob, axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
print('True:', label)
print('Pred:', pred, 'Confidence:', prob)
系统测试
本部分包括训练准确率及测试效果。
1. 训练准确率
绘制损失函数曲线和准确率曲线,经过10轮训练后,准确率将近100%,验证集准确率在89%左右。相关代码如下:
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
plt.plot(train_loss,label='训练集')
plt.plot(valid_loss,label='验证集')
plt.legend(loc='upperright')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.show()
#训练损失
#验证损失
#绘图
train acc = history.history['acc']
valid_acc = history.history['val_acc']
plt.plot(train_acc,label='训练集')
plt.plot(valid acc,label='验证集')
plt.legend(loc='upper right')
plt.xlabel('迭代次数')
plt.ylabel('准确率')
plt.show()
随着训练次数的增多,模型在训练数据、测试数据上的损失和准确率逐渐收敛,最终趋于稳定,如图3和图4所示。
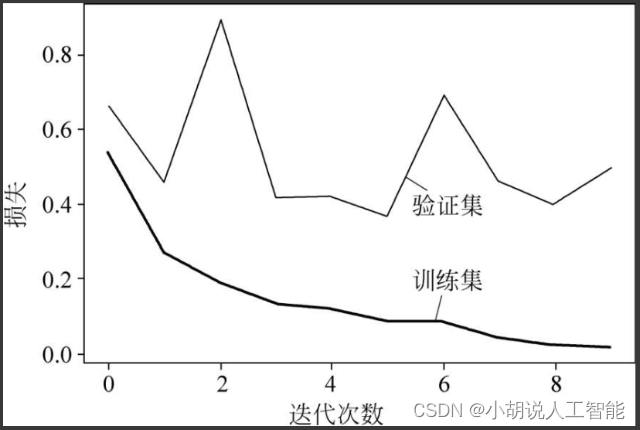
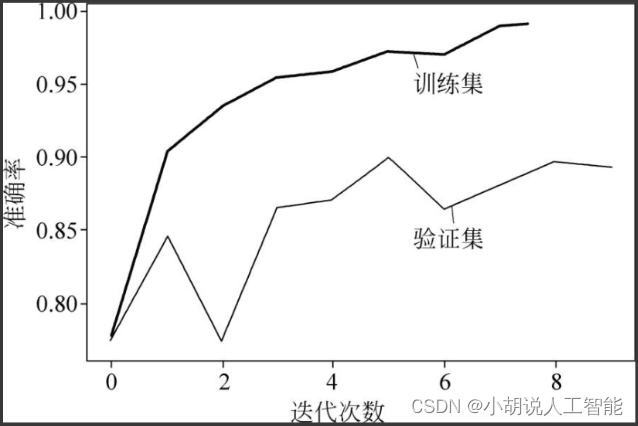
2. 测试效果
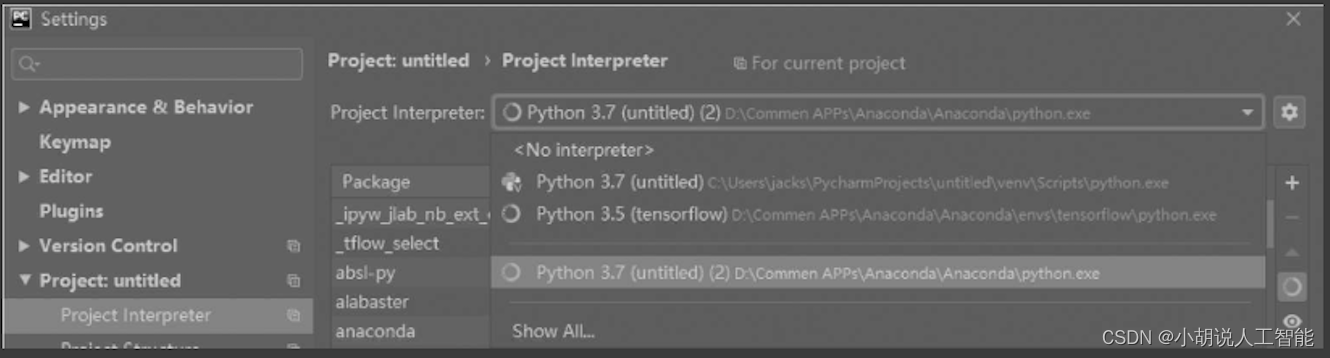
在本地服务器端进行测试,使用PyCharm调用保存的模型和映射。设置PyCharm运行环境,找到本地Python环境并导入,如图所示。
从本地随机抽取一段语音进行测试,相关代码如下:
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/* / .pcm')
#通过 random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label=path.split('/')[1]
print(label,path)
paths=glob.glob('D:/课堂导读/信息系统设计/方言种类分类/data/*/dev/*/*.pcm')
#预测方言种类并输出
prob=model.predict(X_data)
prob = np.mean(prob,axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
print('True:',label)
print('Pred:', pred, 'Confidence:', prob)
在PyCharm上编辑运行,得到的分类结果与语音片段一致,如图所示。

相关其它博客
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。








![[后端卷前端2]](https://img-blog.csdnimg.cn/direct/585ffffbef01482997a04a4c54e7760e.png)