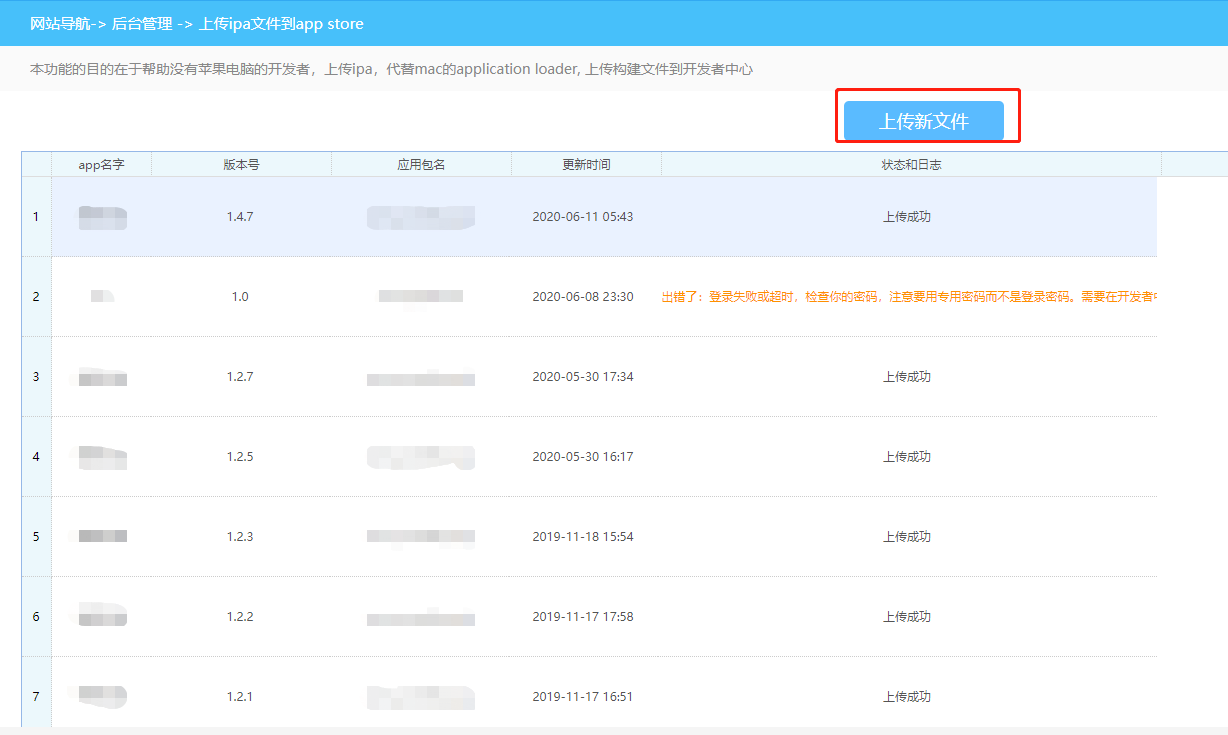
一. 简介
前面文章简单了解了哈希表 这种数据结构,文章如下:
什么是哈希表-CSDN博客
本文来学习一下哈希表,具体学习一下C语言实现对哈希表的简单实现。
二. C语言实现对哈希表的操作
1. 哈希表
哈希表(Hash Table,又称散列表)是一种高效的数据结构,用于实现键值对(Key-Value)的存储和快速查找。其核心思想是通过哈希函数将键(Key)映射到数组的特定位置(称为“桶”或“槽”),从而在平均情况下实现接近常数时间复杂度(O(1))的插入、删除和查找操作。
2. C语言实现哈希表操作
(1) 定义哈希表节点结构体与哈希表结构体
#define HASH_TABLE_LENGTH 20 //链表容量
#define LOAD_FACTOR 0.85 //负载因子
//哈希表节点结构
typedef struct hash_node {
char *key; //键
int value; //值
struct hash_node* next; //下一个节点指针(用于解决冲突)
} hash_node;
//哈希表结构
typedef struct hash_table {
hash_node** buckets; //桶数组
size_t size; //当前元素数量
size_t capacity; //哈希表长度
} hash_table;hash_node结构体表示每个键值对,hash_table表示每个桶,每个桶中存放一个链表。
LOAD_FACTOR宏为负载因子,负载因子是影响哈希表性能的关键指标:
负载因子 = 元素数量 / 容量。
当负载因子超过阈值(如 0.75)时,哈希表会扩容(Resize),以避免冲突过多导致性能下降。
(2) 创建哈希表,扩容哈希表容量
//创建哈希表
hash_table* create_hash_table(void) {
hash_table* hash_tables = (hash_table*)malloc(sizeof(hash_table));
if(!hash_tables) {
printf("hash_table malloc failed!\n");
return NULL;
}
hash_tables->size = 0;
hash_tables->capacity = HASH_TABLE_LENGTH;
hash_tables->buckets = (hash_node**)calloc(hash_tables->capacity, sizeof(hash_node*));
if(!hash_tables->buckets) {
printf("hash_tables->buckets calloc failed!\n");
return NULL;
}
return hash_tables;
}
//哈希函数的实现(djb2哈希算法)
unsigned long hash_func(const char* str) {
unsigned long hash = 5381;
int c;
while((c = *str++)) {
hash = ((hash << 5)+hash)+c;
}
return hash;
}
//调节哈希表长度(扩容)
int resize_hash_table(hash_table* hash_tables, size_t new_capacity) {
//分配新桶数组
hash_node** new_buckets = (hash_node**)calloc(new_capacity, sizeof(hash_node*));
if(!new_buckets) {
printf("new_buckets calloc failed!\n");
return -1;
}
int i = 0;
//遍历原有桶数组,并重新哈希
for(i = 0; i < hash_tables->capacity; i++) {
hash_node* node = hash_tables->buckets[i];
while(node != NULL) {
hash_node* tmp_node = node->next;
unsigned long new_index = hash_func(node->key)/ new_capacity;
//采用头插入法,插入到新桶中
node->next = new_buckets[new_index];
new_buckets[new_index] = node;
//遍历下一个元素
node = tmp_node;
}
}
hash_tables->buckets = new_buckets;
hash_tables->capacity = new_capacity;
free(hash_tables->buckets);
return 0;
}创建哈希表比较简单,这里不做说明。
调整哈希表容量接口这里进行一下说明:
首先,分配新哈希表的容量。
其次,遍历原来哈希表中所有元素(键值对),将旧的哈希表中元素插入到哈希表新桶中。由于哈希表的容量发生了改变,原有的键值对需要重新计算哈希值并插入到新的哈希表中。
node->next = new_buckets[new_index];
new_buckets[new_index] = node;这两行代码的作用是将当前处理的哈希表节点 node 插入到新哈希表的对应桶(bucket)中,采用的是头插法。
node->next = new_buckets[new_index];
- 含义:将当前节点
node的next指针指向新哈希表中对应桶的头节点。 - 作用:这一步是为了把当前节点插入到新桶的头部。若新桶原本为空,
new_buckets[new_index]会是NULL,那么node->next就会被设为NULL;若新桶已经有节点存在,new_buckets[new_index]就会指向桶中的头节点,此时node->next就会指向这个头节点。
new_buckets[new_index] = node;
- 含义:把新哈希表中对应桶的头节点更新为当前节点
node。 - 作用:经过这一步,当前节点
node就成为了新桶的头节点。原本新桶中的节点(如果有的话)就变成了node的后继节点。
(3) 向哈希表中插入新的键值对




![[C]基础13.深入理解指针(5)](https://i-blog.csdnimg.cn/img_convert/fdec36001df774bf9ccaa70641292453.png#pic_center)