文章目录
- 一、mysql数据库存在的问题
- 1.1 模糊查询索引失效
- 1.2 不能分词查询
- 二、倒排索引
一、mysql数据库存在的问题

1.1 模糊查询索引失效
假设要查询上图中title中包含"手机"的信息,那么sql语句是这样的
SELECT * FROM goods WHERE title LIKE '%手机%';
如果使用模糊查询,左边有通配符,不会走索引,会全表扫描,性能低
1.2 不能分词查询
假设上表查询title检索内容为"我要买一部华为手机",无论sql语句怎么模糊匹配都只会查询到包含这整条句子的title,显然数据库中是不存在的。
关系型数据库提供的查询,功能太弱
所以需要用到ES的倒排索引,以关键词为索引库,而关键词又是对原有数据内容拆分出来的,比如"我要买一部华为手机"中华为和手机关键词拆分出来作为索引查询就会灵活很多。
二、倒排索引
就像使用新华字典查找汉字,先找到汉字的偏旁部首,再根据偏旁部首对应的目录(索引)找到目标汉字。
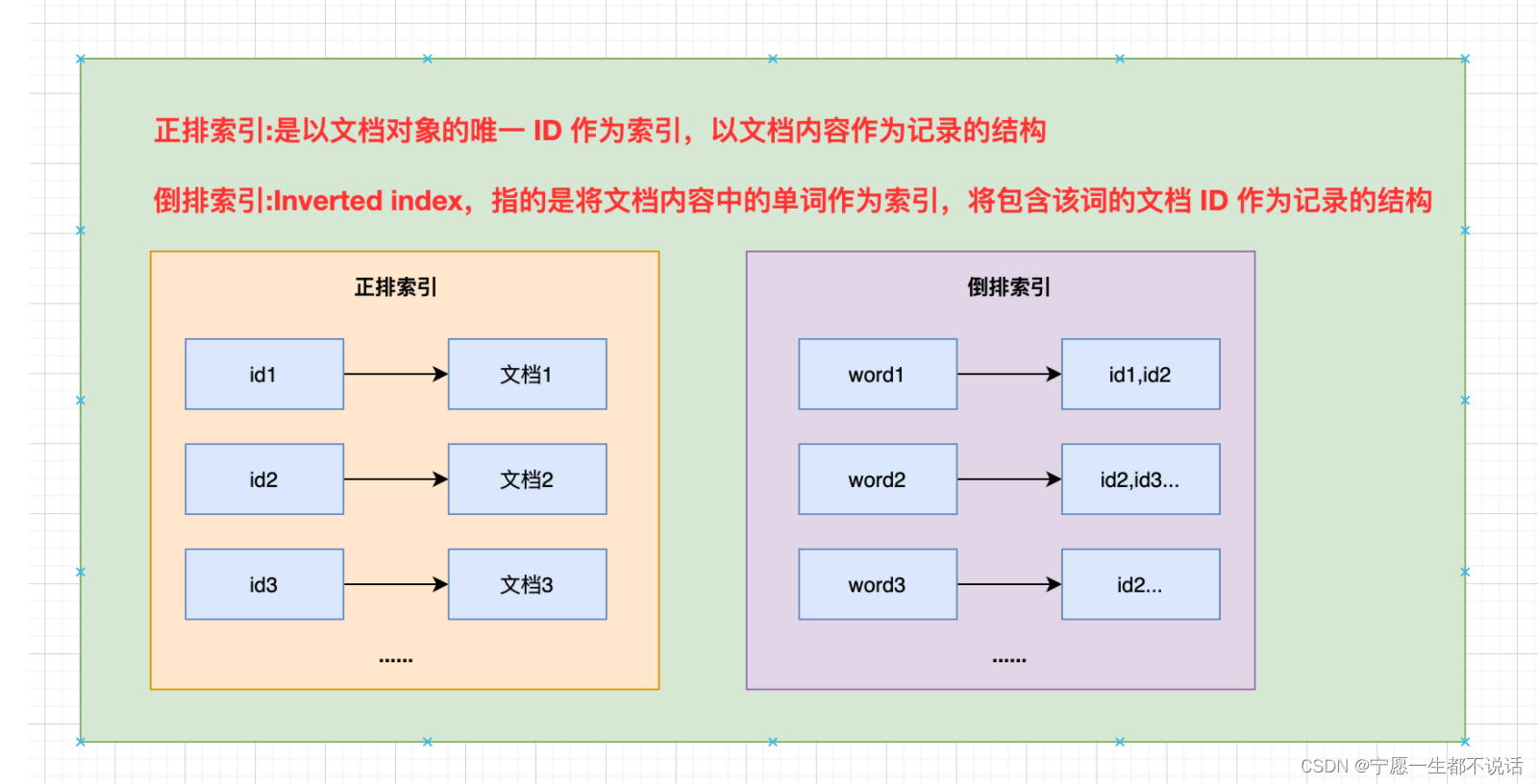
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
ES倒排索引样例:
- 假设文档0(编号0): we like java java java
- 假设文档1(编号1): we like lucene lucene lucene
建立倒排索引的流程
1.首先对所有数据的内容进行拆分(分词),拆分成唯一的一个个词语(词条Term)。
2.然后建立词条和每条数据的对应关系(词条在文档出现的位置下标,出现频率)
| (Term 词条) | (Doc ID,Freq 频率) | (Pos 位置) |
|---|---|---|
| we | (0,1) (1,1) | (0,0)(1,0) |
| like | (0,1) (1,1) | (0,1)(1,1) |
| java | (0,3) | (2,3,4) |
| lucene | (1,3) | (2,3,4) |
- 假设文档2(编号1):java java java we like
| (Term 词条) | (Doc ID,Freq 频率) | (Pos 位置) |
|---|---|---|
| we | (0,1) (1,1) | (0,0)(1,3) |
| like | (0,1) (1,1) | (0,1)(1,4) |
| java | (0,3) (1,3) | (0,2,3,4) (1,0,1,2) |
| lucene | (1,3) | (2,3,4) |
假设只有1个文档有,Pos位置第一位就不需要标识是几号文档,假设是有多个文档有,Pos位置的第一位默认就是文档编号
倒排索引:将每条数据中的内容进行分词,形成词条。然后记录词条和数据的唯一标识(id)的对应关系,形成的产物。