第五章. 可视化数据分析图
5.7 Seaborn图表
Seaborn是一个基于Matplotlib的高级可视化效果库,偏向于统计图表,主要针对的是数据挖掘和机器学习中的变量特征选取,相比Matplotlib,他的语法相对简单,但是具有一定的局限性,本节主要介绍折线图,直方图,条形图,散点图。
1.Seaborn图表的基本设置
1).背景风格:
设置Seaborn的背景风格,主要使用axes_style函数和set_style函数,Seaborn有5个背景主题,适用与不同的场景和主题:
·darkgrid:灰色网格(默认值,主题中的白线能避免影响数据的表现)
·whitegrid:白色网格(更适合表达“重数据元素”)
·dark:灰色背景
·white:白色背景
·ticks:四周带刻度的白色背景
2).边框控制(despine函数):
·移除顶部和右边边框
seaborn.deapline()
·使用两个坐标轴离开一段距离
seaborn.deapline(offset=5,trim=True)
·移除左边边框,与set_style方法的白色网格搭配只用效果更佳
seaborn.set_style('whitegrid')
seaborn.deapline(left=True)
·移除指定边框,设置为True即可
seaborn.deapline(fig=None,ax=None,top=True,right=True,left=True,bottom=False,offset=None,trim=False)
2.折线图 (seaborn.relplot 和 seaborn.lineplot)
在Seaborn中实现折线图的两种方法:一是在relplot函数中通过设置kind参数为line,二是使用lineplot函数直接绘制折线图
1).语法:
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None,data=None, row=None,col=None, col_wrap=None,row_order=None,col_order=None, palette=None,hue_order=None, hue_norm=None, sizes=None,size_order=None, size_norm=None, markers=None,dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1,facet_kws=None, units=None, **kwargs)
参数说明:
x, y:x,y轴上的数据
hue: 将生成具有不同颜色的元素的分组变量。可以是按类别的(categorical),也可以是数字的,不过在后一种情况下,颜色映射的行为会有所不同。
data: 输入数据结构。要么是可以分配给命名变量的向量的长形式集合,要么是将进行内部整形的宽形式数据集
kind:需要绘制的图
2).示例:
Excel中的数据:
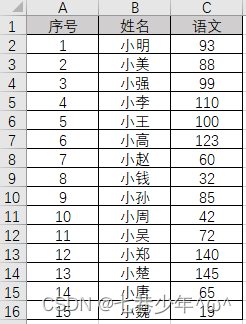
代码:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('F:\\Note\\清单.xlsx', sheet_name='Sheet4')
print(df)
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示的问题
# 绘制折线图
ax = sns.relplot(x='姓名', y='语文', kind='line', data=df)
# 设置文本标签
ax = ax.axes[0,0]
for x, y in zip(df['姓名'], df['语文']):
ax.text(x, y, '%.2f' % y, ha='center', va='center', fontsize=8, color='black')
# 设置标题
ax.title.set_text('成绩统计表')
# 显示图像
plt.show()
结果展示:
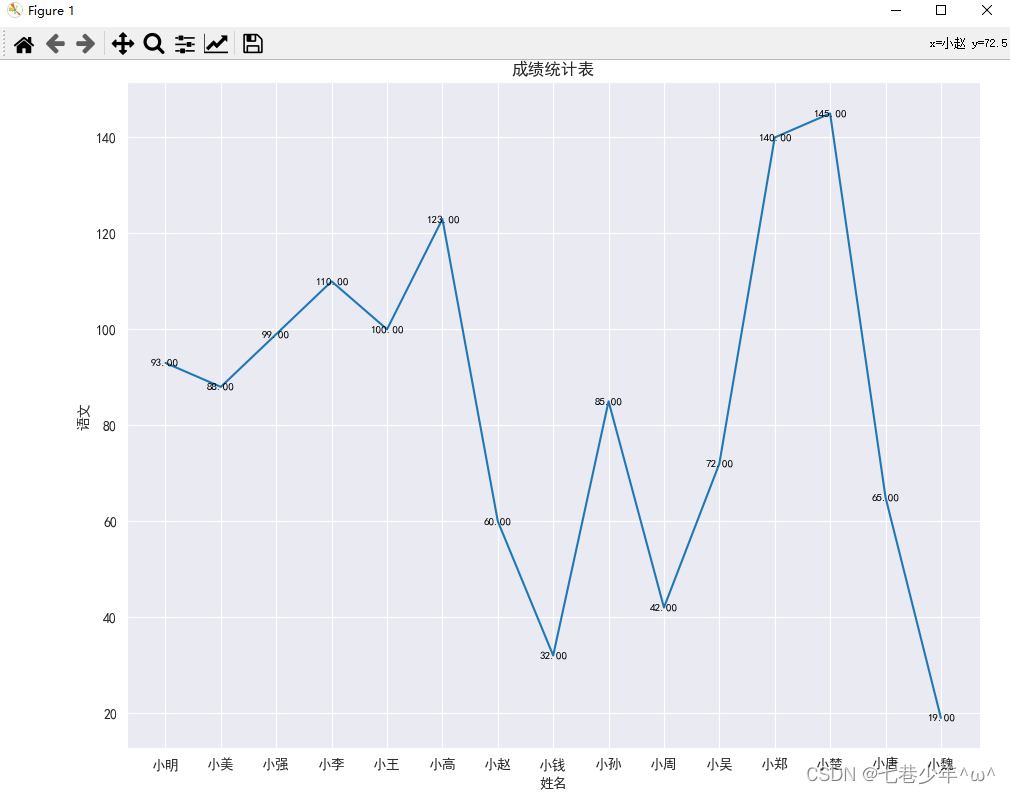
3).语法:
seaborn.lineplot(x=None, y=None, hue=None, size=None, style=None,data=None, row=None,col=None, col_wrap=None,row_order=None,col_order=None, palette=None,hue_order=None, hue_norm=None, sizes=None,size_order=None, size_norm=None, markers=None,dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1,facet_kws=None, units=None, **kwargs
参数说明:
x, y:x,y轴上的数据
hue: 将生成具有不同颜色的元素的分组变量。可以是按类别的(categorical),也可以是数字的,不过在后一种情况下,颜色映射的行为会有所不同。
data: 输入数据结构。要么是可以分配给命名变量的向量的长形式集合,要么是将进行内部整形的宽形式数据集
kind:需要绘制的图
4).示例:
Excel中的数据:
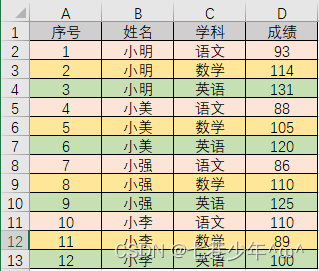
代码:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('F:\\Note\\清单.xlsx', sheet_name='Sheet8')
print(df)
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示的问题
# 设置画布大小
plt.figure(figsize=(8, 6), dpi=100)
# 绘制折线图
ax = sns.lineplot(x='姓名', y='成绩', hue='学科', data=df)
# 设置文本标签
x_label = df['姓名']
x_label = np.arange(len(x_label))
width = 0.25
dis1 = x_label
dis2 = x_label
dis3 = x_label
for x, y in zip(x_label, df['成绩']):
discuss = int(x / 3)
if x % 3 == 0:
ax.text(dis1[discuss], y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
elif x % 3 == 1:
ax.text(dis2[discuss], y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
else:
ax.text(dis3[discuss], y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
# 设置标题
ax.title.set_text('成绩统计表')
# 设置图例
ax.legend(loc='upper right')
# 显示图像
plt.show()
结果展示:
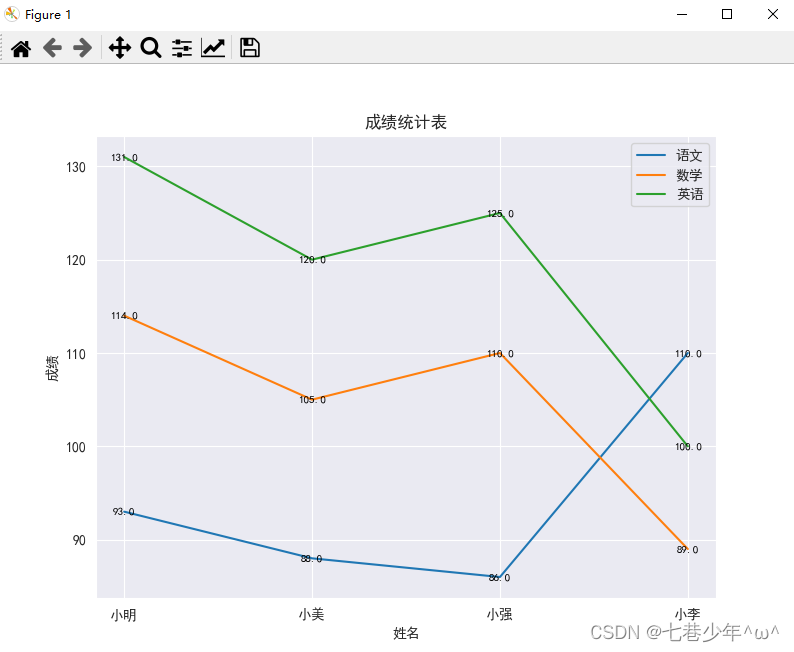
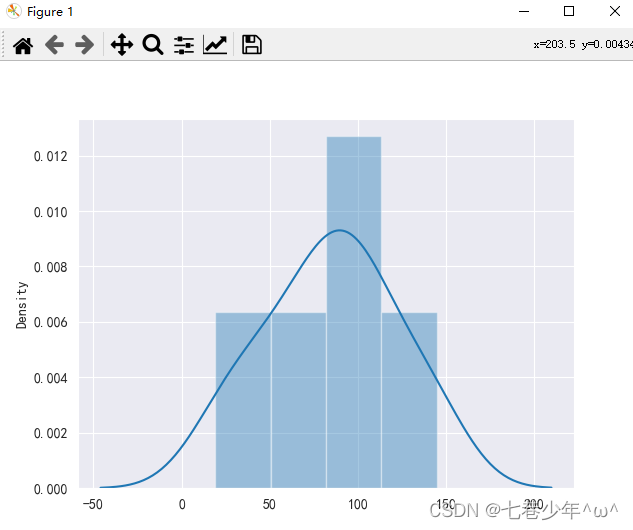
3.直方图 (seaborn.distplot)
1).语法:
seaborn.distplot(data=None, bins=None, hist=True, kde=True, rug=False, fit=None,hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,color=None, vertical=False, norm_hist=False, axlabel=None,label=None, ax=None, x=None)
参数说明:
data:数据
bins:设置矩形图数量
hist:是否显示条形图
kde:是否显示核密度估计图,默认值为True,显示核密度估计图
rug:是否在x轴上显示观测的小细条
fit:拟合的参数分布图形
2).示例:
Excel中的数据:
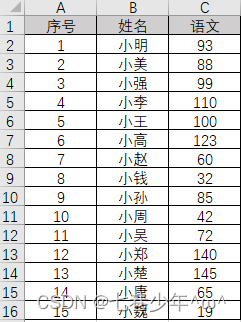
代码:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('F:\\Note\\清单.xlsx', sheet_name='Sheet4')
print(df)
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示的问题
data = df[['语文']]
sns.distplot(data, kde=True)
# 显示图像
plt.show()
结果展示:
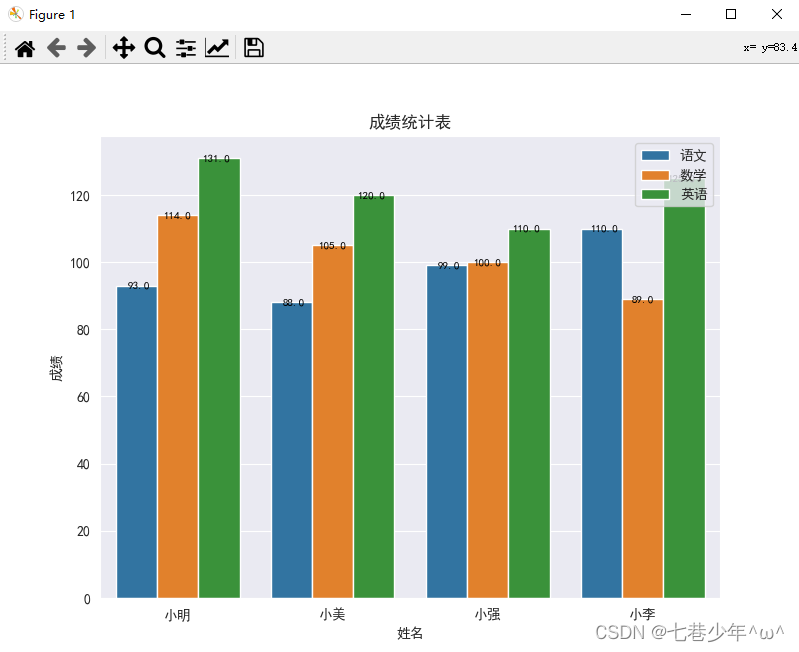
4.条形图 (seaborn.barplot)
1).语法:
seaborn.barplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None,estimator="mean", errorbar=("ci", 95), n_boot=1000, units=None, seed=None,orient=None, color=None, palette=None, saturation=.75, width=.8, errcolor=".26", errwidth=None, capsize=None, dodge=True, ci="deprecated", ax=None, **kwargs)
参数说明:
x,y:x,y轴数据
hue:分类字段
order,hue_order:变量绘图顺序
orient:条形图是水平显示还是竖直显示
capsize:误差线的宽度
estimator:每类变量的统计方式,默认值:mean
2).示例:
Excel中的数据:
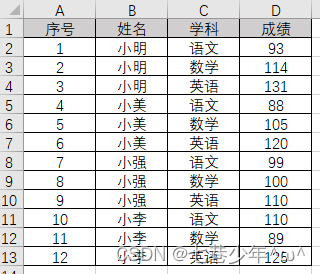
代码:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('F:\\Note\\清单.xlsx', sheet_name='Sheet8')
print(df)
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示的问题
# 设置画布大小
plt.figure(figsize=(8, 6), dpi=100)
# 绘制条形图
ax = sns.barplot(x='姓名', y='成绩', hue='学科', data=df)
# 设置文本标签
x_label = df['姓名']
x_label = np.arange(len(x_label))
width = 0.25
dis1 = x_label - width
dis2 = x_label
dis3 = x_label + width
for x, y in zip(x_label, df['成绩']):
discuss = int(x / 3)
if x % 3 == 0:
ax.text(dis1[discuss], y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
elif x % 3 == 1:
index = dis2[discuss]
ax.text(index, y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
else:
index = dis3[discuss]
ax.text(index, y, '%.1f' % y, ha='center', va='center', fontsize=8, color='black')
# 设置标题
ax.title.set_text('成绩统计表')
# 设置图例
ax.legend(loc='upper right')
# 显示图像
plt.show()
结果展示:
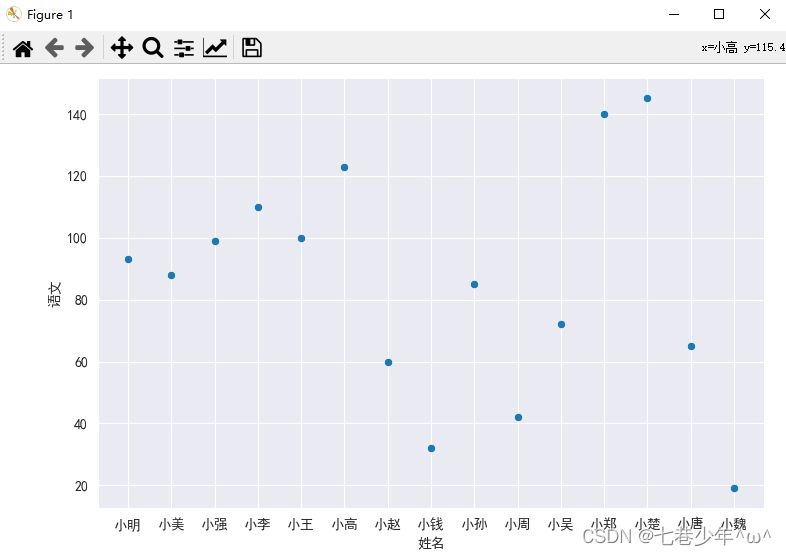
5.散点图 (seaborn.relplot)
1).语法:
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None,data=None, row=None,col=None, col_wrap=None,row_order=None,col_order=None, palette=None,hue_order=None, hue_norm=None, sizes=None,size_order=None, size_norm=None, markers=None,dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1,facet_kws=None, units=None, **kwargs)
参数说明:
x, y:x,y轴上的数据
hue: 将生成具有不同颜色的元素的分组变量。可以是按类别的(categorical),也可以是数字的,不过在后一种情况下,颜色映射的行为会有所不同。
data: 输入数据结构。要么是可以分配给命名变量的向量的长形式集合,要么是将进行内部整形的宽形式数据集
kind:需要绘制的图
2).示例:
Excel中的数据:
代码:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('F:\\Note\\清单.xlsx', sheet_name='Sheet4')
print(df)
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示的问题
# 绘制折线图
ax = sns.relplot(x='姓名', y='语文', data=df)
# 显示图像
plt.show()
结果展示: