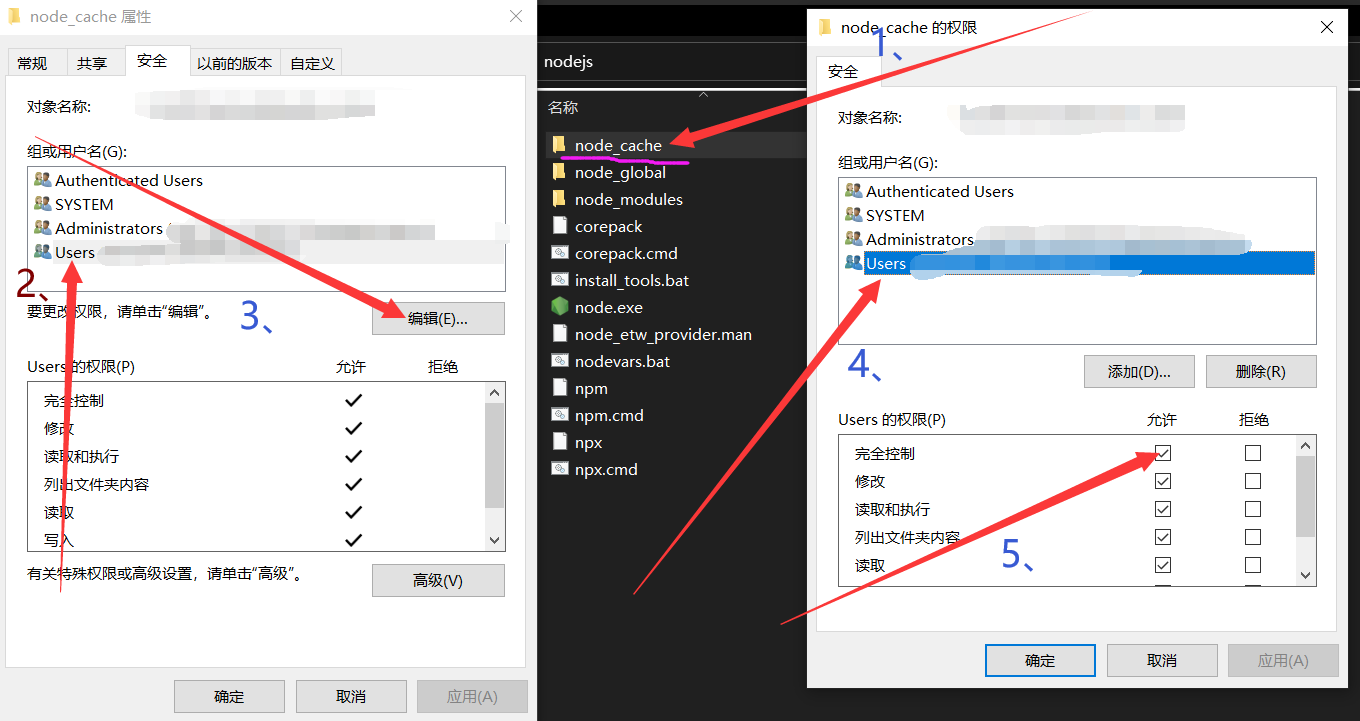
本文通过学习LBPH人脸识别算法,简要了解人脸识别技术的原理,实现人脸采集、训练人脸模型实现人脸识别。
文章目录
- 一、 LBPH人脸识别算法概述
- 二、 人脸识别技术原理
- 三、 关键模块
- 四、 实验准备
- 1. 第三方库
- 2. 新建相关文件夹
- 3. 实验环境
- 五、 人脸采集与检测实现
- 1.人脸采集与检测FaceCollect.py代码
- 2.程序执行效果
- 六、 人脸模型训练实现
- 1.训练人脸模型FaceTrain.py代码
- 2.程序执行效果
- 七、 人脸识别实现
- 1.人脸识别FaceRecognition.py代码
- 2.关于置信度confidence
- 3.程序执行效果
- 程序链接
一、 LBPH人脸识别算法概述
OpenCV库自带的人脸级联分级器具有很好的人脸检测和人脸追踪效果,它是一个基于Haar特征的Adaboost级联分类器。特别注意,OpenCV库虽然自带人脸级联分级器,但是识别效率一般。本项目使用的是OpenCV提供的人脸识别算法LBPH(Local Binary Pattern Histogram),即局部二进制模式直方图,它属于OpenCV拓展库opencv-contrib的一部分,需要另外单独安装opencv-contrib-python-4.1.2。
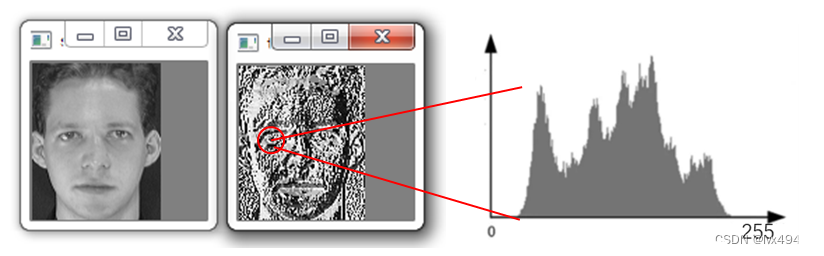
LBPH人脸识别算法思路如下:将检测到的人脸分为小单元如下图1所示,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图,如图2所示,通过对直方图的比较,算法将能够识别图像的边缘和角,能够识别直方图中哪些代表人的主要特征,比如眼睛的颜色、嘴巴的形状等等,这个算法的基本理论也就是基于直方图的创建和比较。由于这种方法通过比较不同人脸图像LBP编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
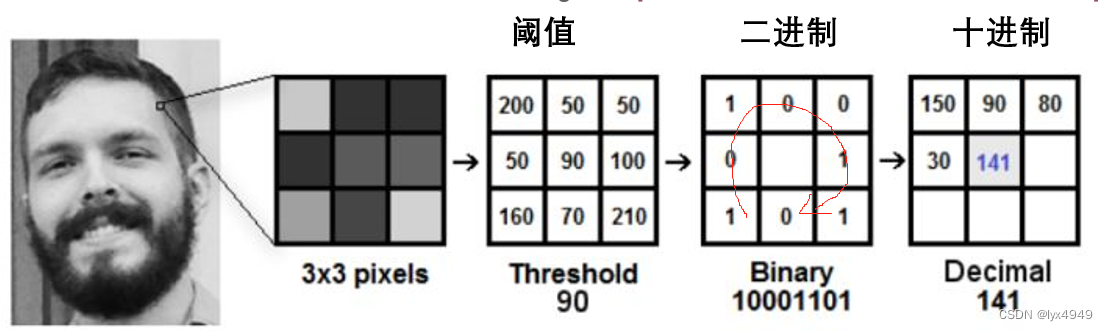
提示:二进制是将中间的数值“90”与四周数值进行对比,大于为1,小于为0,然后绕四周逆时针得出二进制10001101
*参考文档:
1.使用LBPH算法理解人脸识别
2.LBPH人脸识别
二、 人脸识别技术原理
一个完整的人脸识别系统包含五个主要部分,即人脸采集(Face Collect)、人脸检测(Face Detection)、人脸配准(Face Alignment)、人脸特征提取(Face Feature Extraction)、人脸识别(Face Recognition)。

人脸采集:
利用摄像机等采集设备拍摄人脸图像。
人脸检测:
人脸检测是检测出图像中人脸所在位置的一项技术,一般情况下就是用一个矩形框把人脸框出来。本项目使用Haar人脸识别分类器检测。
人脸配准:
人脸配准是根据输入的人脸图像,自动定位出人脸上五官关键点坐标的一项技术,一般有5点、68点、90点。
人脸特征提取:
人脸特征提取是将一张人脸图像转化为一串固定长度的数值的过程。

人脸识别:
人脸识别是一种识别出输入人脸图对应身份的算法技术。输入一张人脸图像,通过与注册在库中N个身份对应的特征进行逐个比对,找出“一个”与输入特征相似度最高的特征。
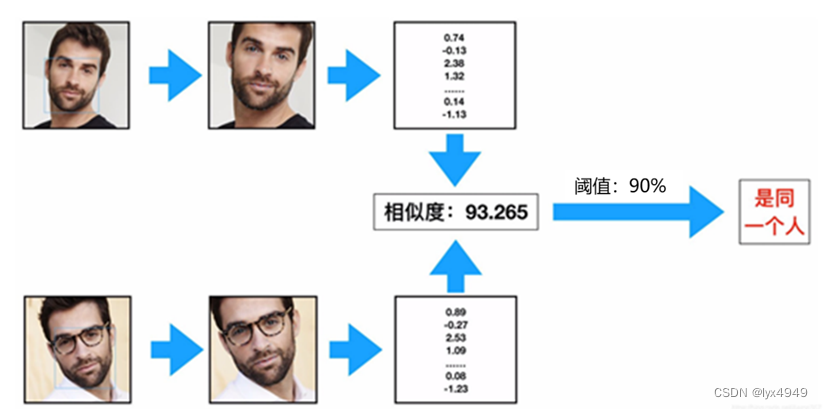
三、 关键模块
1.根据以上分析,本项目将实现人脸识别分为以下3个小任务,通过3个步骤来完成人脸采集与检测、人脸模型训练、人脸识别。

2.函数介绍
在OpenCV中,使用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH人脸识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
四、 实验准备
1. 第三方库

2. 新建相关文件夹
新建一个FaceRecognition工程文件夹,在里面Facedata文件夹、cv2data文件夹、Model文件夹

3. 实验环境
(1)摄像头设备。
(2) python3.7(文末提供的安装包是3.7版本的,如果是其他版本,请根据需要升级第三方库)。
备注:文末提供参考程序
五、 人脸采集与检测实现

1.人脸采集与检测FaceCollect.py代码
(实现效果见本程序后面)
#导入库函数
import cv2
import numpy as np
import random
#请先看主函数
# 将捕获照片的大小裁剪为正方形
def getpaddingSize(shape):
# 照片的长和宽
h, w = shape
longest = max(h, w)
# 将最长的边进行处理
result = (np.array([longest]*4, int) - np.array([h, h, w, w], int)) // 2
return result.tolist()
# 图像去噪处理,使得训练出来的模型具备一定的泛化能力
def dealwithimage(img, h=64, w=64):
top, bottom, left, right = getpaddingSize(img.shape[0:2])
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[0, 0, 0])
img = cv2.resize(img, (h, w))
return img
# 捕获人脸,要拍够100张人脸图像
def GetFace(name,face_id):
# 0: 笔记本内置摄像头; 1: USB摄像头
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
# 获取分类器
face_detector = cv2.CascadeClassifier(r'./cv2data/haarcascade_frontalface_default.xml')
count = 1
while True:
# 默认获取100张图片作为训练数据集
if(count<=100):
print("It's processing %s image." % count)
# 读取图片
success,img = camera.read()
# 图片灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_detector.detectMultiScale(gray,1.3,8)
for (x, y, w, h) in faces:
# 图像预处理,处理成64*64大小的图片
face = gray[y:y+h, x:x+w]
face = cv2.resize(face, (64, 64))
# 图像去噪处理
face = dealwithimage(face)
# 保存图片
cv2.imwrite("Facedata/User." + str(face_id) + '.' + str(count) + '.jpg', face)
# 在图片上显示名字
cv2.putText(img, name, (x, y-20), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2)
# 画一个矩形
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
count+=1
cv2.imshow('img', img)
# 保持画面持续
key = cv2.waitKey(30)&0xff
# 按下Esc退出
if key == 27:
break
else:
break
# 关闭摄像头
camera.release()
cv2.destroyAllWindows()
#主函数
if __name__ == '__main__':
# 请输入您的name和id
name = input('Please input your name:')
face_id = input('Please input face id:') #ID很重要,训练分类的时候根据id来识别对应的模型
GetFace(name,face_id)
2.程序执行效果
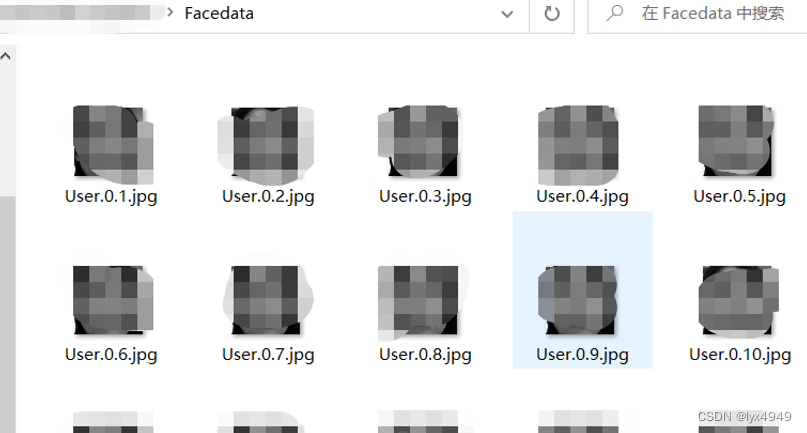
程序打印下列内容,输入人脸身份(如lyx),其次输入身份ID(序号0,1,2…)。当用户输入名字和ID,按下回车键后,只要用户正对着摄像头计算机会自动采集人脸图像,直到采集到100张有效照片后自动退出,照片默认保存在根目录下的Facedata文件夹

六、 人脸模型训练实现
 对采集到的人脸数据集进行人脸特征提取并建立人脸模型,形成模型文件。
对采集到的人脸数据集进行人脸特征提取并建立人脸模型,形成模型文件。
1.训练人脸模型FaceTrain.py代码
import os
import cv2
from PIL import Image
import numpy as np
# 人脸训练集路径
path = './Facedata/'
# 初始化识别器
# opencv-contrib-python和opencv-python库版本要一致,否则运行会报错
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 获取分类器
detector = cv2.CascadeClassifier(r'./cv2data/haarcascade_frontalface_default.xml')
# 获取图像及标签
def getImagesAndLabels(path):
# join函数的作用
imagePaths = [os.path.join(path, f) for f in os.listdir(path)]
faceSamples = []
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert('L')
img_numpy = np.array(PIL_img, 'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = detector.detectMultiScale(img_numpy)
for (x, y, w, h) in faces:
faceSamples.append(img_numpy[y:y + h, x: x + w])
ids.append(id)
return faceSamples, ids
# 主程序入口
if __name__ == "__main__":
print('Training faces. It will take a few seconds. Waiting...')
faces, ids = getImagesAndLabels(path)
# 开始训练
recognizer.train(faces, np.array(ids))
print('Training has finished!')
# 保存文件,生成模型,模型名为“trainer20221230”
recognizer.write(r'./Model/trainer20221230.yml')
print("{0} faces trained. Exiting Program.".format(len(np.unique(ids))))
2.程序执行效果
当出现如下所示的信息时,说明模型训练完成,模型文件默认保存在当前程序目录下的Model文件夹
Training faces. It will take a few seconds. Waiting...
Training has finished!
1 faces trained. Exiting Program.

七、 人脸识别实现

通过摄像头实时捕获人脸图像,进行人脸追踪,跟训练好的人脸模型trainer-20221230.yml进行特征匹配,从而进行人脸识别,对应的用户名字会实时显示在人脸图像上。
1.人脸识别FaceRecognition.py代码
import cv2
# 人脸识别函数
def Face():
# 初始化识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 加载训练好的模型文件
recognizer.read('./Model/trainer-2021.yml')
# 获取分类器
faceCascade = cv2.CascadeClassifier(r'./cv2data/haarcascade_frontalface_default.xml')
# 设置图片显示的字体
font = cv2.FONT_HERSHEY_SIMPLEX
idnum = 0 #用户ID
# 用户需要在此添加自己的姓名(拼音),下标序号要与名字对应(ID从0开始,依次递增)
names = ['lin','Jack']
# 捕获图像
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
# 设置格式
minW = 0.1*camera.get(3)
minH = 0.1*camera.get(4)
print('请正对着摄像头...')
confidence = 150.00 #设置置信度初始值
score = 0 #设置匹配指数初始值
name = "unknown"
while True:
# 读取图片
success,img = camera.read()
# 图片灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.3,
minNeighbors=5,
minSize=(int(minW), int(minH))
)
for (x, y, w, h) in faces:
# 画一个矩形
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 图像预测 https://www.py.cn/jishu/jichu/26805.html
#predict()函数返回两个元素的数组:第一个元素是所识别 个体的标签,第二个是置信度评分。
# 图像预测predict函数,返回值一个是id,一个是置信度confidence,置信度值越小越好
idnum, confidence = recognizer.predict(gray[y:y+h, x:x+w])
# 设置匹配指数,200是根据confidence的结果估算出来的
score =int( "{0}".format(round(200 - confidence)))
# 匹配指数大于等于95即可验证通过人脸
if score > 95:
name = names[idnum]
else:
name = "unknown"
cv2.putText(img, str(name), (x+5, y-5), font, 1, (230, 250, 100), 1)
cv2.putText(img, str(score), (x+5, y+h-5), font, 1, (255, 0, 0), 1)
cv2.imshow('camera', img)
# 保持画面持续
key = cv2.waitKey(10)
# 按Esc键退出
if key==27 or score > 95:
cv2.imwrite('./image.jpg', img)
break
# 关闭摄像头
camera.release()
cv2.destroyAllWindows()
return name,confidence
if __name__ == '__main__':
name,confidence = Face()
score = "{0}".format(round(200 - confidence))
print("您的名字是:", name)
print("匹配指数:", score)
2.关于置信度confidence
LBPH中置信度评分用来衡量所识别人脸与原模型的差距,0 表示完全匹配,predict()函数返回两个元素的数组:第一个元素是所识别 个体的标签,第二个是置信度评分。其中由于本人采集人脸数据的干扰,confidence的值会在88-110以上(confidence想要接近0基本上概率为0),所以我设置了本项目score为200-confidence,反过来判断score的值大于我设定的阈值(95)那么就判定为人脸识别成功。
3.程序执行效果
在弹出图像窗口并在人脸图像上实时显示用户名和匹配指数。

程序链接
完成参考程序与第三方库:
链接:https://pan.baidu.com/s/1woGOnY8YWWfWSAQI6yldwg?pwd=lyx4
提取码:lyx4