目录
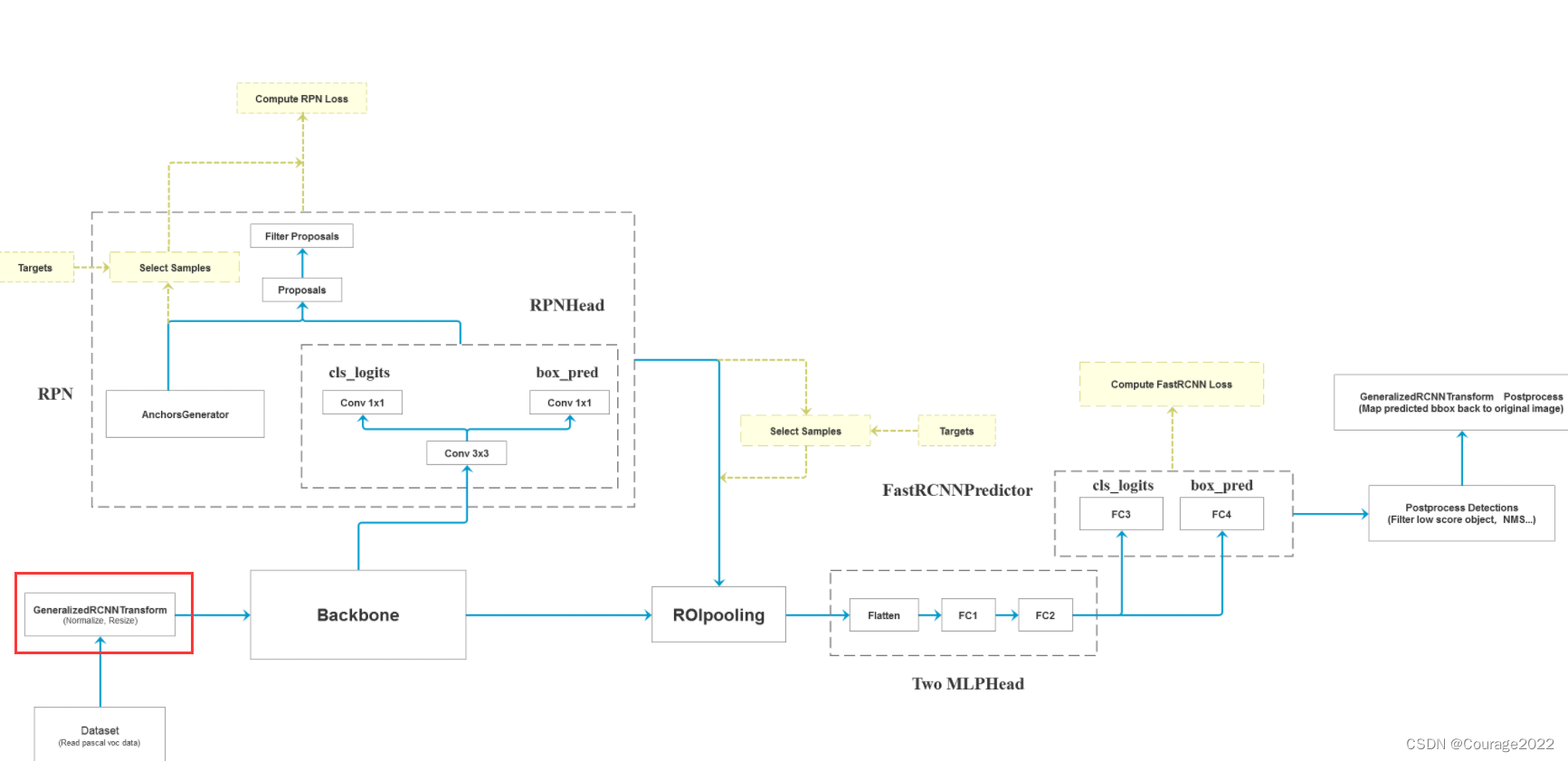
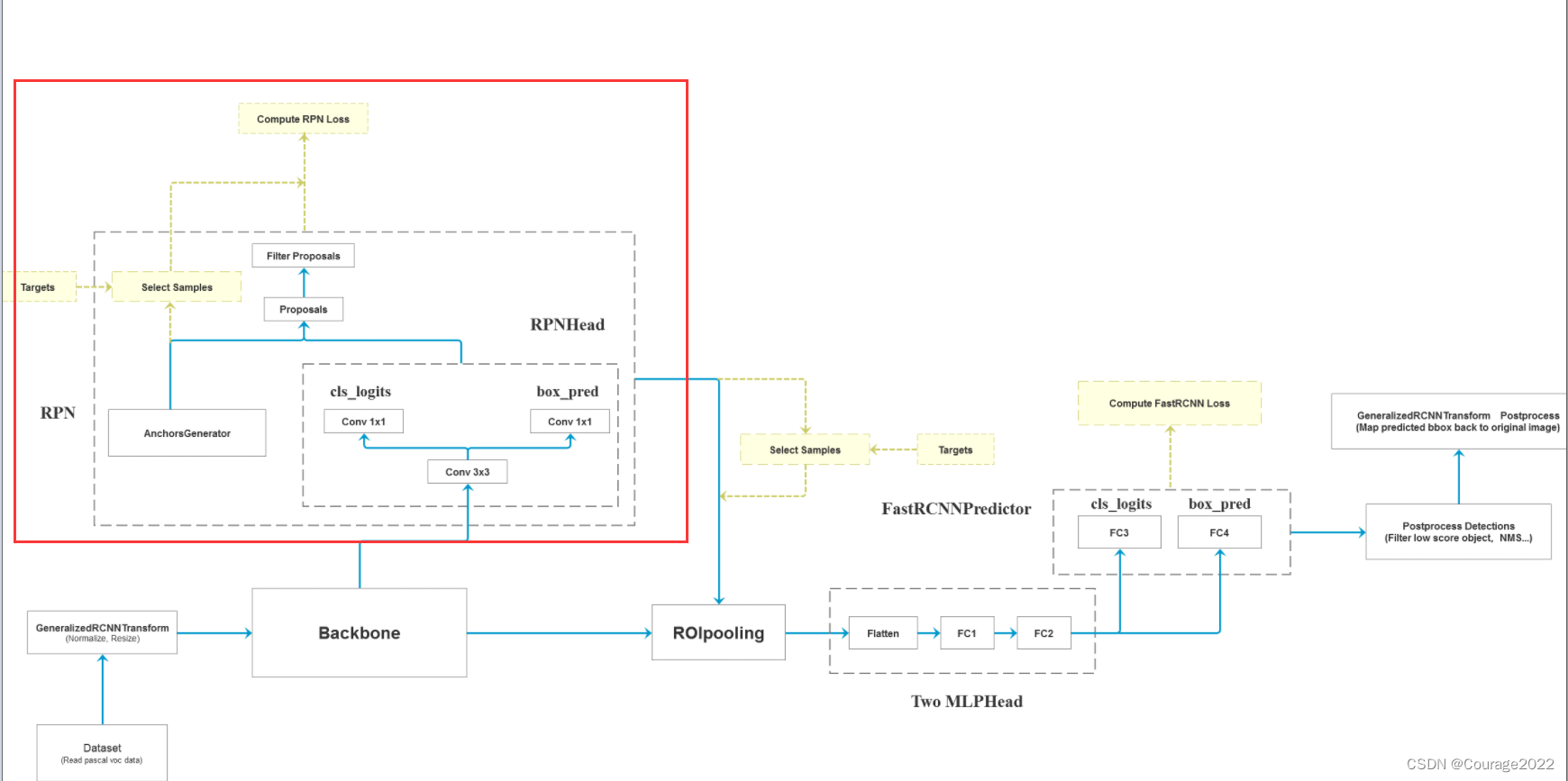
一、Faster R-CNN框架图
二、结合代码 (faster_rcnn_framework.py)
2.1 FasterRCNNBase类
2.2 FasterRCNN类
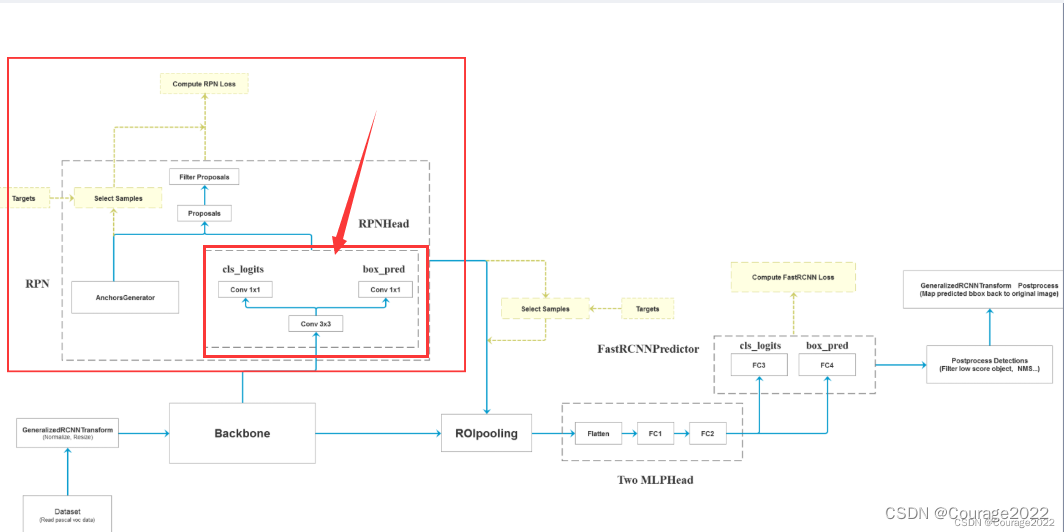
一、Faster R-CNN框架图
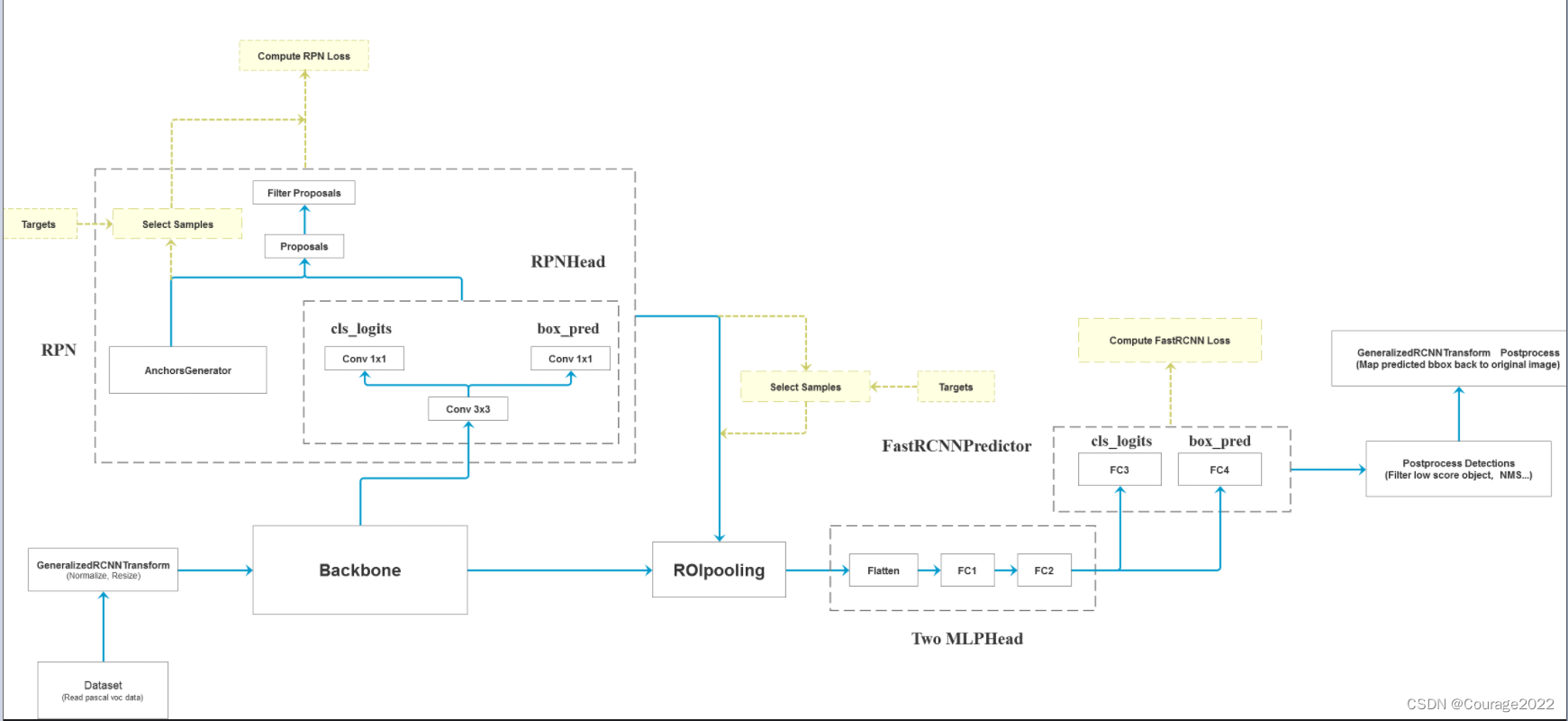
我们获取一张图片后将其输入特征提取网络Backbone中得到特征图,将特征图输入到RPN中得到一系列的proposal即目标建议框(2K左右),将建议框根据原图和特征图的投影关系可以得到一个个特征矩阵,将每个特征矩阵输入到ROIpooling层会得到一些大小相同的特征图(7*7),接着对他们进行展平处理,通过两个全连接层再通过类别预测层和边界框回归层进行后处理......
二、结合代码 (faster_rcnn_framework.py)
2.1 FasterRCNNBase类
我们来看FasterRCNNBase这个类,在它的初始化函数中,我们传入如下参数:
# self 特征提取网络 区域建议生成网络 (三部分) # backbone就是图像中特征提取网络部分 # rpn也是图中的一部分(区域建议生成网络部分) # roi_heads除了最后一步的所有 def __init__(self, backbone, rpn, roi_heads, transform): super(FasterRCNNBase, self).__init__() self.transform = transform self.backbone = backbone self.rpn = rpn self.roi_heads = roi_heads # used only on torchscript mode self._has_warned = False正向传播过程:
#注意:这里输入的images的大小都是不同的。后面会进行预处理将这些图片放入同样大小的tensor中打包成一个batch #正向传播过程 params :预测的图片,为List[Tensor]型 #image和target我们再word上面有标注 def forward(self, images, targets=None): # type: (List[Tensor], Optional[List[Dict[str, Tensor]]]) -> Tuple[Dict[str, Tensor], List[Dict[str, Tensor]]] """ Arguments: images (list[Tensor]): images to be processed targets (list[Dict[Tensor]]): ground-truth boxes present in the image (optional) Returns: result (list[BoxList] or dict[Tensor]): the output from the model. During training, it returns a dict[Tensor] which contains the losses. During testing, it returns list[BoxList] contains additional fields like `scores`, `labels` and `mask` (for Mask R-CNN models). """ #判断是否是训练模式,若是训练模式一定要有targets,若targets为空,抛出异常 if self.training and targets is None: raise ValueError("In training mode, targets should be passed") #检查标注框是否有错误 if self.training: assert targets is not None for target in targets: # 进一步判断传入的target的boxes参数是否符合规定 boxes = target["boxes"] #判断boxes是不是torch.Tensor的格式 if isinstance(boxes, torch.Tensor): #shape对应的目标有几个,毕竟一个目标就对应一个边界框嘛 #box的第一个维度是N表示图像中有几个边界框 第二个维度是4(xminxmax..) #即如果最后一个维度!=4也要报错 if len(boxes.shape) != 2 or boxes.shape[-1] != 4: raise ValueError("Expected target boxes to be a tensor" "of shape [N, 4], got {:}.".format( boxes.shape)) else: raise ValueError("Expected target boxes to be of type " "Tensor, got {:}.".format(type(boxes))) #存储每张图片的原始尺寸 定义是个List类型 每个list又是个元组类型 元组里面存放着图片的长宽 original_image_sizes = torch.jit.annotate(List[Tuple[int, int]], []) for img in images: #对每张图片取得最后两个元素,再pytorch中维度的排列为[channel,height,width] val = img.shape[-2:] assert len(val) == 2 # 防止输入的是个一维向量 original_image_sizes.append((val[0], val[1])) # original_image_sizes = [img.shape[-2:] for img in images] #GeneralizedRCNNTransform 函数 png的第二步(标准化处理、resize大小) #现在的image和targets才是真正的batch 我们在输入之前都是一张张尺寸大小不一样的图片,我们这样是没有办法打包成一个batch输入到gpu中进行运算的 images, targets = self.transform(images, targets) # 对图像进行预处理 # print(images.tensors.shape) features = self.backbone(images.tensors) # 将图像输入backbone得到特征图 #判断特征图是否是tensor类型的,对于上面的图片是img和target型的 但是我们经过backbone后就得到了一个个的特征图(仅有图) if isinstance(features, torch.Tensor): # 若只在一层特征层上预测,将feature放入有序字典中,并编号为‘0’ #将特征图加入有序字典 key=0 features = OrderedDict([('0', features)]) # 若在多层特征层上预测,传入的就是一个有序字典 # 将特征层以及标注target信息传入rpn中 # proposals: List[Tensor], Tensor_shape: [num_proposals, 4],是一个绝对坐标 # 每个proposals是绝对坐标,且为(x1, y1, x2, y2)格式 #proposal是一个list大小为2(batch_size)是2 每个元素是个tensor,对于每个list而言是个tensor 2000*4 2000代表rpn生成有2000个proposal proposals, proposal_losses = self.rpn(images, features, targets) # 将rpn生成的数据以及标注target信息传入fast rcnn后半部分 detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets) # 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上) detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes) losses = {} losses.update(detector_losses) losses.update(proposal_losses) if torch.jit.is_scripting(): if not self._has_warned: warnings.warn("RCNN always returns a (Losses, Detections) tuple in scripting") self._has_warned = True return losses, detections else: return self.eager_outputs(losses, detections)参数中的image是我们传入的需要预测的图片,是list[Tensor]类型的,注意:这里输入的images的大小都是不同的。后面会进行预处理将这些图片放入同样大小的tensor中打包成一个batch。target就是关于图像的信息。
其实这两个信息就是上篇博客说的自定义的信息,即自定义数据集中的返回结果,image和target。再通过训练脚本的DataLoader方法传入我们的dataset就会将多张图片以及它们的信息合并在一起返回给我们,也就是这个函数传入的image和target。
此外,这里的collate.fn方法是代替torch.stack()方法,因为我们不是一个简单的tensor,而是(target,image)的tuple类型。
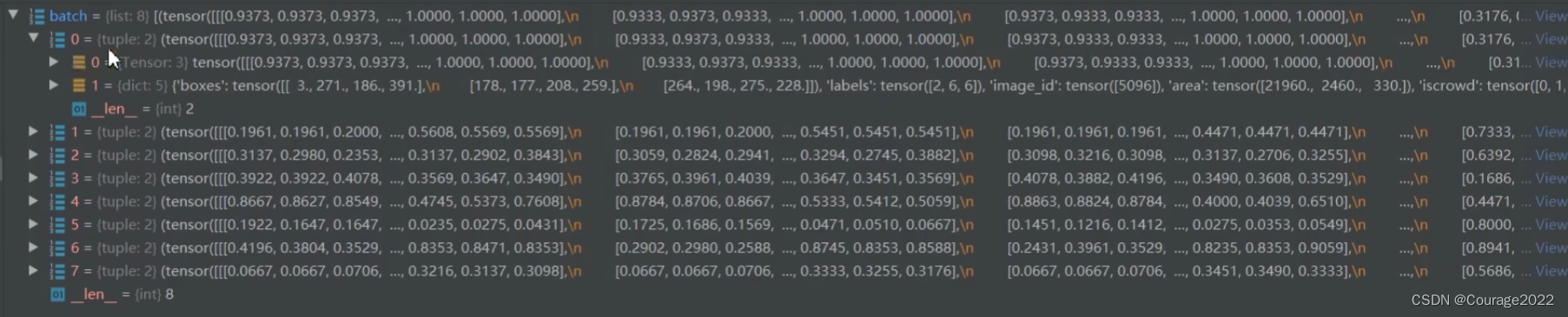
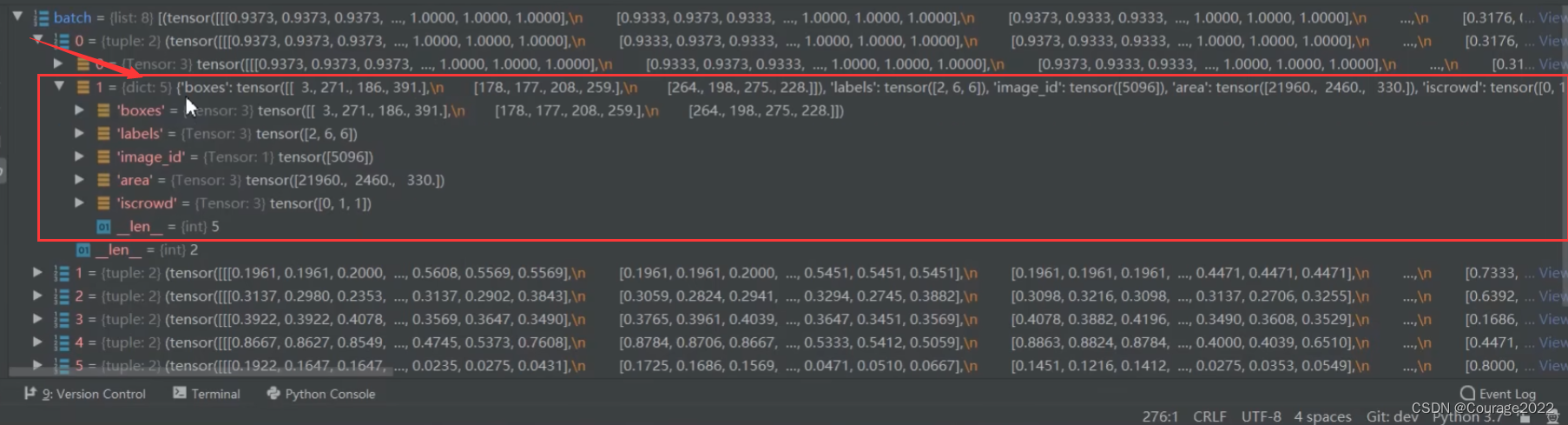
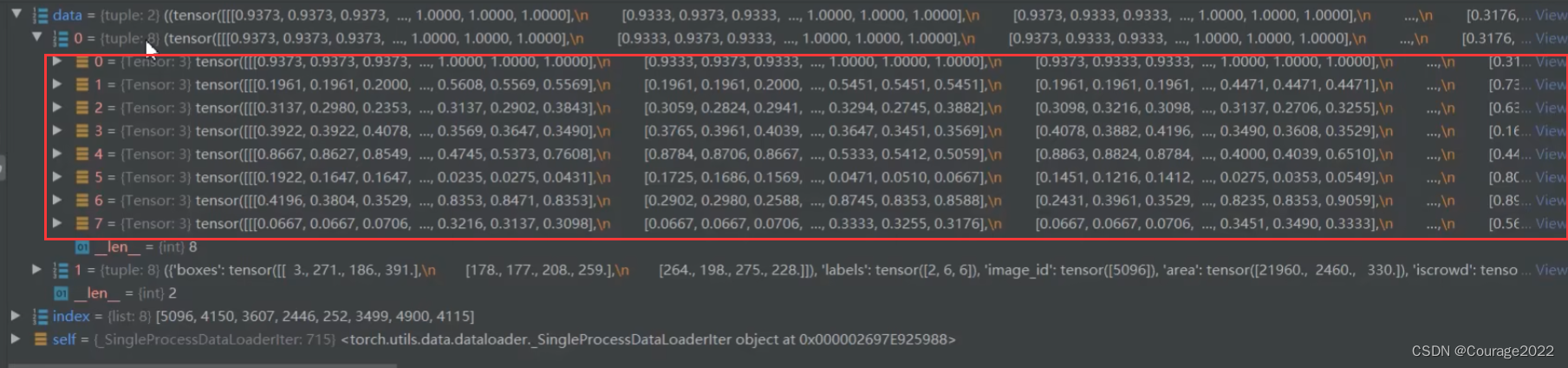
def collate_fn(batch) return tuple(zip(*batch))我们看看这个函数的输入是一个list型变量,每个list含八张图片(batch_size),每一个list是一个tuple类型,tuple的第一维是图像image信息,第二维是target信息。
当我们执行完这个代码后,我们会将每个tuple给拆开,将相同的部分放在一起,即将每一个图像数据image放在一起,将target信息放在一起进行打包。
现在的data数据是tuple类型的,只有两个元素;每个元素包含八个元素。

现在清晰明了了,这个函数的输入参数image和target是DataLoader返回的信息。
如果是训练模式,assert targets is not None要保证target不是空的。
然后检查target["boxes"]是否符合要求,shape第一维度对应的目标有几个,毕竟一个目标就对应一个边界框嘛,第二个维度是4(xminxmax..),如果最后一个维度!=4也要报错。
声明变量original_image_sizes存储每张图片初始的尺寸。
随后对数据进行预处理:
images, targets = self.transform(images, targets) # 对图像进行预处理
经过预处理后得到新的image和targets。因为现在的image和targets才是真正的batch,我们在输入之前都是一张张尺寸大小不一样的图片,我们这样是没有办法打包成一个batch输入到gpu中进行运算的。
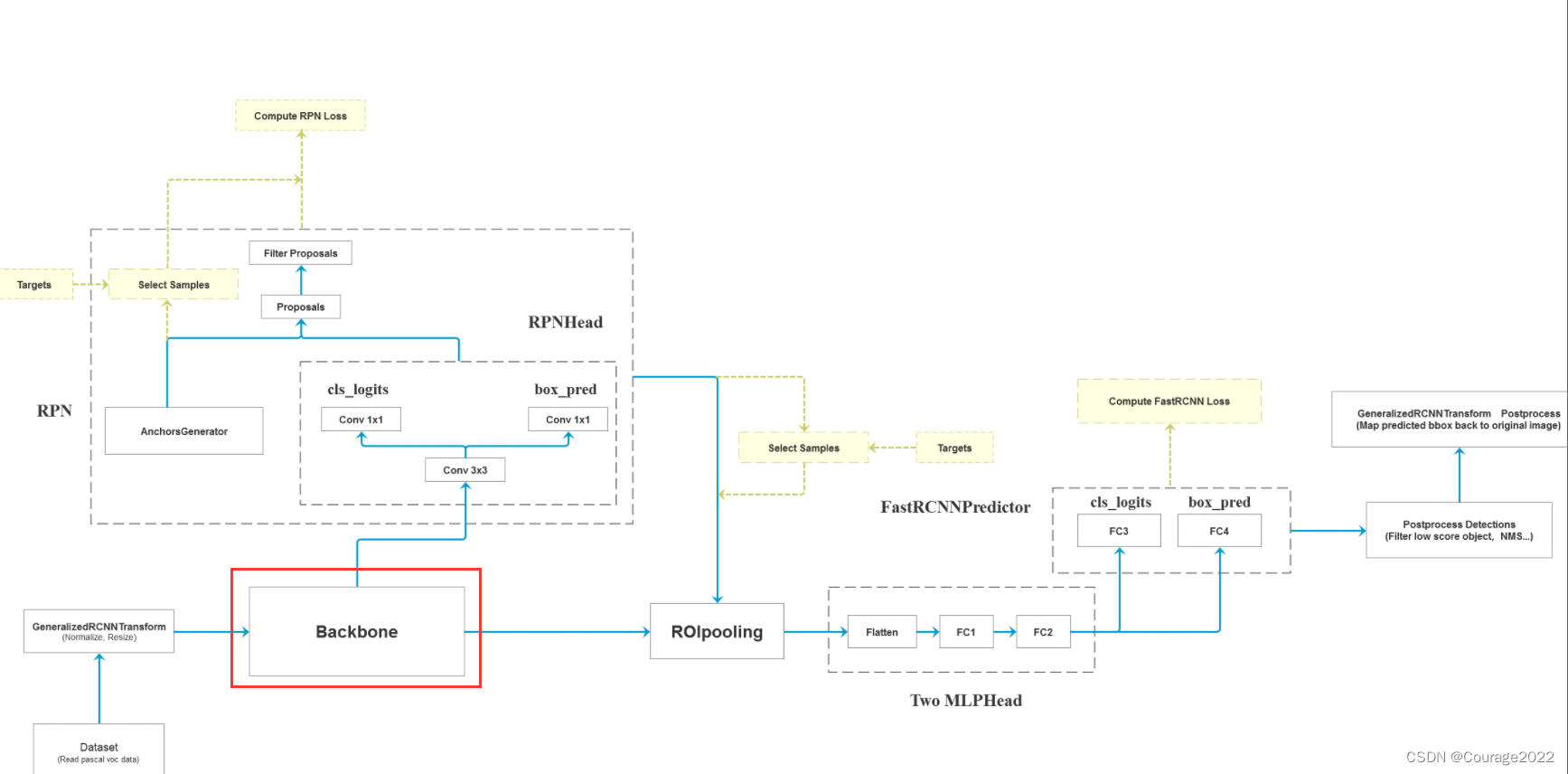
接下来将图像输入backbone得到特征图。
features = self.backbone(images.tensors)
判断特征图是否是tensor类型的,对于上面的图片是img和target型的,但是我们经过backbone后就得到了一个个的特征图(仅有图)。若只在一层特征层上预测,将feature放入有序字典中,并编号为‘0’。
将特征层以及标注target信息传入rpn中。
proposals: List[Tensor], Tensor_shape: [num_proposals, 4],是一个绝对坐标
每个proposals是绝对坐标,且为(x1, y1, x2, y2)格式
proposal是一个list大小为2(batch_size)是2 每个元素是个tensor,对于每个list而言是个tensor 2000*4 2000代表rpn生成有2000个proposal
proposals, proposal_losses = self.rpn(images, features, targets)
将rpn生成的数据以及标注target信息传入fast rcnn后半部分。
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
最后对网络进行后处理(主要将bboxes还原到原图像尺度上)
detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
记录损失信息,结束!



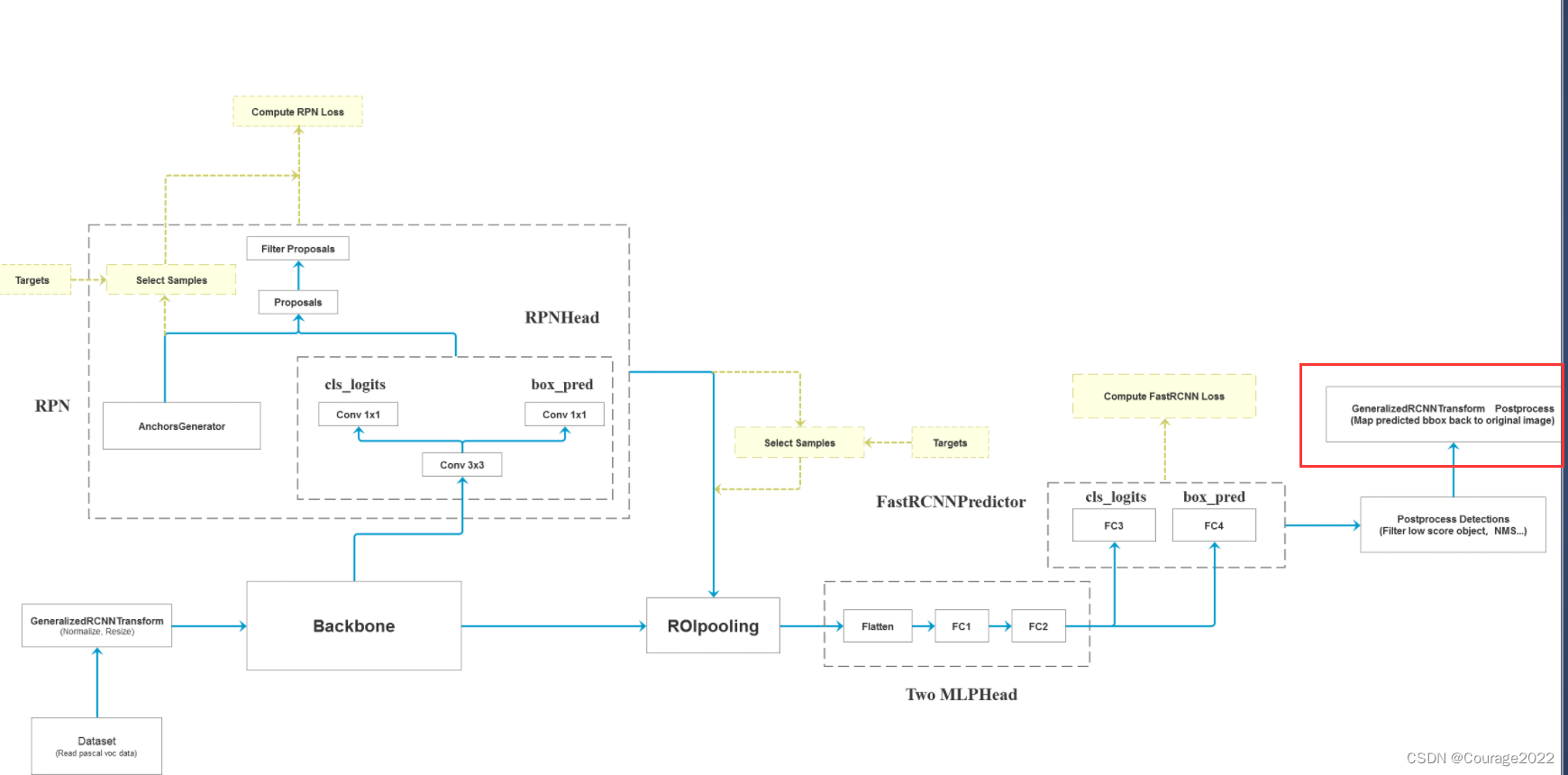
2.2 FasterRCNN类
在类初始化中,传入了相当多的参数!!
def __init__(self, backbone, #检测的目标类别个数(20+背景) num_classes=None, # transform parameter min_size=800, max_size=1333, # 预处理resize时限制的最小尺寸与最大尺寸 image_mean=None, image_std=None, # 预处理normalize时使用的均值和方差 # RPN parameters rpn_anchor_generator=None, rpn_head=None, rpn_pre_nms_top_n_train=2000, rpn_pre_nms_top_n_test=1000, # rpn中在nms处理前保留的proposal数(根据score) rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=1000, # rpn中在nms处理后保留的proposal数 rpn_nms_thresh=0.7, # rpn中进行nms处理时使用的iou阈值 rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3, # rpn计算损失时,采集正负样本设置的阈值 rpn_batch_size_per_image=256, rpn_positive_fraction=0.5, # rpn计算损失时采样的样本数,以及正样本占总样本的比例 rpn_score_thresh=0.0, # Box parameters box_roi_pool=None, box_head=None, box_predictor=None, # 移除低目标概率 fast rcnn中进行nms处理的阈值 对预测结果根据score排序取前100个目标 box_score_thresh=0.05, box_nms_thresh=0.5, box_detections_per_img=100, box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5, # fast rcnn计算误差时,采集正负样本设置的阈值 box_batch_size_per_image=512, box_positive_fraction=0.25, # fast rcnn计算误差时采样的样本数,以及正样本占所有样本的比例 bbox_reg_weights=None): #检查backbone是否有out_channels这个属性,对应深度值 if not hasattr(backbone, "out_channels"): raise ValueError( "backbone should contain an attribute out_channels" "specifying the number of output channels (assumed to be the" "same for all the levels" ) #检查类别 assert isinstance(rpn_anchor_generator, (AnchorsGenerator, type(None))) assert isinstance(box_roi_pool, (MultiScaleRoIAlign, type(None))) if num_classes is not None: if box_predictor is not None: raise ValueError("num_classes should be None when box_predictor " "is specified") else: if box_predictor is None: raise ValueError("num_classes should not be None when box_predictor " "is not specified") # 预测特征层的channels out_channels = backbone.out_channels # 若anchor生成器为空,则自动生成针对resnet50_fpn的anchor生成器 #在五个预测特征层上预测 针对每个预测特征层会使用 if rpn_anchor_generator is None: anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) rpn_anchor_generator = AnchorsGenerator( anchor_sizes, aspect_ratios ) # 生成RPN通过滑动窗口预测网络部分 # # if rpn_head is None: rpn_head = RPNHead( out_channels, rpn_anchor_generator.num_anchors_per_location()[0] ) # 默认rpn_pre_nms_top_n_train = 2000, rpn_pre_nms_top_n_test = 1000, # 默认rpn_post_nms_top_n_train = 2000, rpn_post_nms_top_n_test = 1000, rpn_pre_nms_top_n = dict(training=rpn_pre_nms_top_n_train, testing=rpn_pre_nms_top_n_test) rpn_post_nms_top_n = dict(training=rpn_post_nms_top_n_train, testing=rpn_post_nms_top_n_test) # 定义整个RPN框架 rpn = RegionProposalNetwork( rpn_anchor_generator, rpn_head, rpn_fg_iou_thresh, rpn_bg_iou_thresh, rpn_batch_size_per_image, rpn_positive_fraction, rpn_pre_nms_top_n, rpn_post_nms_top_n, rpn_nms_thresh, score_thresh=rpn_score_thresh) # Multi-scale RoIAlign pooling # # if box_roi_pool is None: box_roi_pool = MultiScaleRoIAlign( featmap_names=['0', '1', '2', '3'], # 在哪些特征层进行roi pooling output_size=[7, 7], sampling_ratio=2) # fast RCNN中roi pooling后的展平处理两个全连接层部分 # out_channels 通过展平之后所拥有的节点个数 由于我们通过proposal通过ROIAlaign之后得到的是一个shape固定的特征矩阵,矩阵的faeatures的通道数=out_channels # 特征矩阵的output_size=[7, 7], 因此展平之后的节点个数是out_channels*7*7,第二个参数是全连接层1的节点个数 if box_head is None: resolution = box_roi_pool.output_size[0] # 默认等于7 representation_size = 1024 box_head = TwoMLPHead( out_channels * resolution ** 2, representation_size ) # 在box_head的输出上预测部分 #并联两个全连接层 一个全连接层并联(一个全连接层用于预测每个proposal的类别分数)(一个全连接层用于预测每个proposal的边界框回归参数) if box_predictor is None: representation_size = 1024 box_predictor = FastRCNNPredictor( representation_size, num_classes) #加上背景21 # 将roi pooling, box_head以及box_predictor结合在一起 roi_heads = RoIHeads( # box box_roi_pool, box_head, box_predictor, box_fg_iou_thresh, box_bg_iou_thresh, # 0.5 0.5 box_batch_size_per_image, box_positive_fraction, # 512 0.25 在每张图片当中会选取多少个proposal用来计算fastrcnn的损失 bbox_reg_weights, box_score_thresh, box_nms_thresh, box_detections_per_img) # 0.05 0.5 100 if image_mean is None: image_mean = [0.485, 0.456, 0.406] if image_std is None: image_std = [0.229, 0.224, 0.225] # 对数据进行标准化,缩放,打包成batch等处理部分 transform = GeneralizedRCNNTransform(min_size, max_size, image_mean, image_std) super(FasterRCNN, self).__init__(backbone, rpn, roi_heads, transform)一、预处理相关参数
min_size=800, max_size=1333, # 预处理resize时限制的最小尺寸与最大尺寸
image_mean=None, image_std=None, # 预处理normalize时使用的均值和方差二、RPN网络参数
rpn_anchor_generator=None #anchor生成器
rpn_head=None #对应红色方框那块,包括一个3*3的Conv,分类层及框体回归层
rpn_pre_nms_top_n_train=2000, rpn_pre_nms_top_n_test=1000
#对应RPN在非极大值抑制保留的proposal数量,是根据预测分数进行保留的,这里NMS有时后相同主要是针对带有FPN的网络。FPN有多个预测特征层,每层在NMS前都保留2000个,总共加起来就上万了。然后在通过NMS保留2000个。
rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=1000#rpn中在nms处理后保留的proposal数。
rpn_nms_thresh=0.7 # rpn中进行nms处理时使用的iou阈值
rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3, # rpn计算损失时,采集正负样本设置的阈值。即anchor与groundtruth的iOu大于0.7标记为正样本,anchor与任何一个groundtruth小于0.3标记为负样本
rpn_batch_size_per_image=256, rpn_positive_fraction=0.5, # rpn计算损失时采样的样本数,以及正样本占总样本的比例
三、ROIHead的参数
box_roi_pool=None #对应图中的ROI Pooling层
box_head=None #对应图中Two MLPHead
box_predictor=None #框体预测及类别预测的两个全连接层
box_score_thresh=0.05 #PostProcess中滤除小概率目标的阈值
box_nms_thresh=0.5 #fast rcnn中进行nms处理的阈值
box_detections_per_img=100 # 对预测结果根据score排序取前100个目标
box_fg_iou_thresh=0.5 box_bg_iou_thresh=0.5
# fast rcnn计算误差时,采集正负样本设置的阈值
box_batch_size_per_image=512, box_positive_fraction=0.25, # fast rcnn计算误差时采样的样本数,以及正样本占所有样本的比例
四、其他初始化部分
if not hasattr(backbone, "out_channels"):检查backbone是否有out_channels这个属性,对应深度值。在定义模型时,我们会对out_channels设置一个参数。
def create_model(num_classes): # https://download.pytorch.org/models/vgg16-397923af.pth # 如果使用vgg16的话就下载对应预训练权重并取消下面注释,接着把mobilenetv2模型对应的两行代码注释掉 # vgg_feature = vgg(model_name="vgg16", weights_path="./backbone/vgg16.pth").features # backbone = torch.nn.Sequential(*list(vgg_feature._modules.values())[:-1]) # 删除features中最后一个Maxpool层 # backbone.out_channels = 512 # https://download.pytorch.org/models/mobilenet_v2-b0353104.pth backbone = MobileNetV2(weights_path="./backbone/mobilenet_v2.pth").features backbone.out_channels = 1280 # 设置对应backbone输出特征矩阵的channels anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),)) #有序字典 我们设置图片的key=0 roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行roi pooling output_size=[7, 7], # roi_pooling输出特征矩阵尺寸 sampling_ratio=2) # 采样率 model = FasterRCNN(backbone=backbone, num_classes=num_classes, rpn_anchor_generator=anchor_generator, box_roi_pool=roi_pooler) return model#检查类别
assert isinstance(rpn_anchor_generator, (AnchorsGenerator, type(None)))
assert isinstance(box_roi_pool, (MultiScaleRoIAlign, type(None)))box_roi_pool:featmap_names=['0'], # 在哪些特征层上进行roi pooling,因为这个网络只有一个预测特征层
output_size=[7, 7], # roi_pooling输出特征矩阵尺寸
若anchor生成器为空,则自动生成针对resnet50_fpn的anchor生成器。
对于mobilenet中,由于只有一个预测层,我们负责预测如下尺寸:注意这里的size是元组类型。
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),))在初始化resnet50+FPN中:每一个值都是一个元组,由于这个网络中有五个预测特征层,针对每个预测特征层不同的尺度分别预测不同的大小,尺寸最大的预测小目标,尺寸最小的特征层预测大目标。
if rpn_anchor_generator is None: anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) rpn_anchor_generator = AnchorsGenerator( anchor_sizes, aspect_ratios )