title: 23 种设计模式总结
date: 2022-12-30 16:53:46
tags:
- 设计模式
categories: - 设计模式
cover: https://cover.png
feature: false
文章目录
- 1. 创建型
- 1.1 单例模式(Singleton Design Pattern)
- 1.1.1 概述与实现
- 1.1.2 多例
- 1.2 工厂模式(Factory Design Pattern)
- 1.2.1 简单工厂(Simple Factory)
- 1.2.2 工厂方法(Factory Method)
- 1.2.3 工厂方法模式 VS 简单工厂模式
- 1.2.4 抽象工厂(Abstract Factory)
- 1.3 建造者/构建者/生成器模式(Builder Design Pattern)
- 1.3.1 与工厂模式有何区别?
- 1.4 原型模式(Prototype Design Pattern)
- 2. 结构型
- 2.1 代理模式(Proxy Design Pattern)
- 2.2 桥接/桥梁模式(Bridge Design Pattern)
- 2.3 装饰器模式(Decorator Design Pattern)
- 2.4 适配器模式(Adapter Design Pattern)
- 2.5 代理、桥接、装饰器、适配器 4 种设计模式的区别
- 2.6 门面/外观模式(Facade Design Pattern)
- 2.7 组合模式(Composite Design Pattern)
- 2.8 享元模式(Flyweight Design Pattern)
- 2.8.1 享元模式 vs 单例、缓存、对象池
- 3. 行为型
- 3.1 观察者/发布订阅模式(Observer Design Pattern/Publish-Subscribe Design Pattern)
- 3.2 模板模式(Template Method Design Pattern)
- 3.2.1 模板模式 VS 回调
- 3.3 策略模式(Strategy Design Pattern)
- 3.3.1 策略的定义
- 3.3.2 策略的创建
- 3.3.3 策略的使用
- 3.4 职责链模式(Chain Of Responsibility Design Pattern
- 3.5 状态模式(State Design Pattern)
- 3.6 迭代器/游标模式(Iterator Design Pattern/Cursor Design Pattern)
- 3.7 访问者模式(Visitor Design Pattern)
- 3.8 备忘录/快照(Snapshot)模式(Memento Design Pattern)
- 3.9 命令模式(Command Design Pattern)
- 3.9.1 命令模式 VS 策略模式
- 3.10 解释器模式(Interpreter Design Pattern)
- 3.11 中介模式(Mediator Design Pattern)
- 3.11.1 中介模式 VS 观察者模式
设计模式相关的详细知识见如下三篇:
- 设计模式之美总结(创建型篇)_凡 223 的博客
- 设计模式之美总结(结构型篇)_凡 223 的博客
- 设计模式之美总结(行为型篇)_凡 223 的博客
这里主要是对上面三篇内容的总结,用于清晰 23 种设计模式的原理概念和应用场景,以及它们之间的异同点,区分 23 种设计模式,对其有一个整体的认知,具体详细实现见上面三篇文章。建议先看完上面三篇文章或者对设计模式有一定了解再来阅读本章内容,对知识做一个归纳汇总,或者也可在本章任一一节末尾点击链接直达对应的详细知识部分
1. 创建型
创建型设计模式主要解决“对象的创建”问题
1.1 单例模式(Singleton Design Pattern)
1.1.1 概述与实现
一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式
应用场景:
- 解决资源访问冲突
- 表示全局唯一类
实现方式:
1、饿汉式:不支持延迟加载
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() {
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
2、懒汉式:支持延迟加载,但可以看到给 getInstance() 这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低,有性能问题,不支持高并发
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static synchronized IdGenerator getInstance() {
if (instance == null) {
instance = new IdGenerator();
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
3、双重检测:既支持延迟加载、又支持高并发
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static IdGenerator getInstance() {
if (instance == null) {
synchronized(IdGenerator.class) { // 此处为类级别的锁
if (instance == null) {
instance = new IdGenerator();
}
}
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
4、静态内部类:比双重检测更加简单的实现方法
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private IdGenerator() {}
private static class SingletonHolder{
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
return id.incrementAndGet();
}
}
5、枚举:利用 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private IdGenerator() {}
private static class SingletonHolder{
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
return id.incrementAndGet();
}
}
1.1.2 多例
单例”指的是,一个类只能创建一个对象。对应地,“多例”指的就是,一个类可以创建多个对象,但是个数是有限制的,比如只能创建 3 个对象
public class BackendServer {
private long serverNo;
private String serverAddress;
private static final int SERVER_COUNT = 3;
private static final Map<Long, BackendServer> serverInstances = new HashMap<>();
static {
serverInstances.put(1L, new BackendServer(1L, "192.134.22.138:8080"));
serverInstances.put(2L, new BackendServer(2L, "192.134.22.139:8080"));
serverInstances.put(3L, new BackendServer(3L, "192.134.22.140:8080"));
}
private BackendServer(long serverNo, String serverAddress) {
this.serverNo = serverNo;
this.serverAddress = serverAddress;
}
public BackendServer getInstance(long serverNo) {
return serverInstances.get(serverNo);
}
public BackendServer getRandomInstance() {
Random r = new Random();
int no = r.nextInt(SERVER_COUNT)+1;
return serverInstances.get(no);
}
}
对于多例模式,还有一种理解方式:同一类型的只能创建一个对象,不同类型的可以创建多个对象。这里的“类型”如何理解呢?
如下例,在代码中,loggerName 就是上面说的“类型”,同一个 loggerName 获取到的对象实例是相同的,不同的 loggerName 获取到的对象实例是不同的
public class Logger {
private static final ConcurrentHashMap<String, Logger> instances
= new ConcurrentHashMap<>();
private Logger() {}
public static Logger getInstance(String loggerName) {
instances.putIfAbsent(loggerName, new Logger());
return instances.get(loggerName);
}
public void log() {
//...
}
}
//l1==l2, l1!=l3
Logger l1 = Logger.getInstance("User.class");
Logger l2 = Logger.getInstance("User.class");
Logger l3 = Logger.getInstance("Order.class");
这种多例模式的理解方式有点类似工厂模式。它跟工厂模式的不同之处在于:
- 多例模式创建的对象都是同一个类的对象
- 而工厂模式创建的是不同子类的对象
实际上,它还有点类似享元模式。除此之外,实际上,枚举类型也相当于多例模式,一个类型只能对应一个对象,一个类可以创建多个对象
详细可见:设计模式之美总结(创建型篇)_凡 223 的博客 单例模式部分
1.2 工厂模式(Factory Design Pattern)
一般情况下,工厂模式分为三种更加细分的类型:简单工厂、工厂方法和抽象工厂。不过,在 GoF 的《设计模式》一书中,它将简单工厂模式看作是工厂方法模式的一种特例,所以工厂模式只被分成了工厂方法和抽象工厂两类。实际上,前面一种分类方法更加常见
1.2.1 简单工厂(Simple Factory)
如下,根据不同的后缀名,创建不同的解析器类。这里每次调用 createParser() 方法的时候,都要创建一个新的 parser,把这一种实现方法叫作简单工厂模式的第一种实现方法
public class RuleConfigParserFactory {
public static IRuleConfigParser createParser(String configFormat) {
IRuleConfigParser parser = null;
if ("json".equalsIgnoreCase(configFormat)) {
parser = new JsonRuleConfigParser();
} else if ("xml".equalsIgnoreCase(configFormat)) {
parser = new XmlRuleConfigParser();
} else if ("yaml".equalsIgnoreCase(configFormat)) {
parser = new YamlRuleConfigParser();
} else if ("properties".equalsIgnoreCase(configFormat)) {
parser = new PropertiesRuleConfigParser();
}
return parser;
}
}
如果 parser 可以复用,为了节省内存和对象创建的时间,可以将 parser 事先创建好缓存起来,如下。这种实现方法叫作简单工厂模式的第二种实现方法
public class RuleConfigParserFactory {
private static final Map<String, RuleConfigParser> cachedParsers = new HashMap<>();
static {
cachedParsers.put("json", new JsonRuleConfigParser());
cachedParsers.put("xml", new XmlRuleConfigParser());
cachedParsers.put("yaml", new YamlRuleConfigParser());
cachedParsers.put("properties", new PropertiesRuleConfigParser());
}
public static IRuleConfigParser createParser(String configFormat) {
if (configFormat == null || configFormat.isEmpty()) {
// 或抛出 IllegalArgumentException
return null;
}
IRuleConfigParser parser = cachedParsers.get(configFormat.toLowerCase());
return parser;
}
}
1.2.2 工厂方法(Factory Method)
在简单工厂模式的第一种实现方法中,有一组 if 分支逻辑,实际上,如果 if 分支并不是很多,代码中有 if 分支也是完全可以接受的
也可以应用多态或设计模式来替代 if 分支判断逻辑,但也并不是没有任何缺点的,它虽然提高了代码的扩展性,更加符合开闭原则,但也增加了类的个数,牺牲了代码的可读性。这里按照多态的实现思路,对上面的代码进行重构
public interface IRuleConfigParserFactory {
IRuleConfigParser createParser();
}
public class JsonRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new JsonRuleConfigParser();
}
}
public class XmlRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new XmlRuleConfigParser();
}
}
public class YamlRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new YamlRuleConfigParser();
}
}
public class PropertiesRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser() {
return new PropertiesRuleConfigParser();
}
}
这就是工厂方法模式的典型代码实现。这样当新增一种 parser 的时候,只需要新增一个实现了 IRuleConfigParserFactory 接口的 Factory 类即可。所以,工厂方法模式比起简单工厂模式更加符合开闭原则
但这些工厂类的使用上存在挺大的问题,如下:
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParserFactory parserFactory = null;
if ("json".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new JsonRuleConfigParserFactory();
} else if ("xml".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new XmlRuleConfigParserFactory();
} else if ("yaml".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new YamlRuleConfigParserFactory();
} else if ("properties".equalsIgnoreCase(ruleConfigFileExtension)) {
parserFactory = new PropertiesRuleConfigParserFactory();
} else {
throw new InvalidRuleConfigException("Rule config file fo support")rmat is not
从上面的代码实现来看,工厂类对象的创建逻辑又耦合进了 load() 函数中,跟简单工厂模式的第一种实现方法非常相似。怎么来解决这个问题呢?可以为工厂类再创建一个简单工厂,也就是工厂的工厂,用来创建工厂类对象
public class RuleConfigSource {
public RuleConfig load(String ruleConfigFilePath) {
String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
IRuleConfigParserFactory parserFactory = RuleConfigParserFactoryMap.getParserFactory(ruleConfigFileExtension);
if (parserFactory == null) {
throw new InvalidRuleConfigException("Rule config file format is not support");
}
IRuleConfigParser parser = parserFactory.createParser();
String configText = "";
// 从ruleConfigFilePath文件中读取配置文本到configText中
RuleConfig ruleConfig = parser.parse(configText);
return ruleConfig;
}
private String getFileExtension(String filePath) {
// ...解析文件名获取扩展名,比如rule.json,返回json
return "json";
}
}
// 因为工厂类只包含方法,不包含成员变量,完全可以复用,不需要每次都创建新的工厂类对象,
// 所以,简单工厂模式的第二种实现思路更加合适
public class RuleConfigParserFactoryMap { //工厂的工厂
private static final Map<String, IRuleConfigParserFactory> cachedFactories = new HashMap<>();
static {
cachedFactories.put("json", new JsonRuleConfigParserFactory());
cachedFactories.put("xml", new XmlRuleConfigParserFactory());
cachedFactories.put("yaml", new YamlRuleConfigParserFactory());
cachedFactories.put("properties", new PropertiesRuleConfigParserFactory())
}
public static IRuleConfigParserFactory getParserFactory(String type) {
if (type == null || type.isEmpty()) {
return null;
}
IRuleConfigParserFactory parserFactory = cachedFactories.get(type.toLowerCase());
return parserFactory;
}
}
1.2.3 工厂方法模式 VS 简单工厂模式
当对象的创建逻辑比较复杂,不只是简单的 new 一下就可以,而是要组合其他类对象,做各种初始化操作的时候,推荐使用工厂方法模式,将复杂的创建逻辑拆分到多个工厂类中,让每个工厂类都不至于过于复杂。而使用简单工厂模式,将所有的创建逻辑都放到一个工厂类中,会导致这个工厂类变得很复杂
除此之外,在某些场景下,如果对象不可复用,那工厂类每次都要返回不同的对象。如果使用简单工厂模式来实现,就只能选择第一种包含 if 分支逻辑的实现方式。如果还想避免烦人的 if-else 分支逻辑,这个时候,就推荐使用工厂方法模式
1.2.4 抽象工厂(Abstract Factory)
在上面简单工厂和工厂方法中,类只有一种分类方式。但是,如果类有两种分类方式,比如上面的解析器例子,假如既可以按照配置文件格式来分类,也可以按照解析的对象(Rule 规则配置还是 System 系统配置)来分类,那就会对应下面这 8 个 parser 类
针对规则配置的解析器: 基于接口IRuleConfigParser
JsonRuleConfigParser
XmlRuleConfigParser
YamlRuleConfigParser
PropertiesRuleConfigParser
针对系统配置的解析器: 基于接口ISystemConfigParser
JsonSystemConfigParser
XmlSystemConfigParser
YamlSystemConfigParser
PropertiesSystemConfigParser
如果还是继续用工厂方法来实现的话,要针对每个 parser 都编写一个工厂类,也就是要编写 8 个工厂类。如果未来还需要增加针对业务配置的解析器(比如 IBizConfigParser),那就要再对应地增加 4 个工厂类。过多的类也会让系统难维护。这个问题该怎么解决呢?
抽象工厂就是针对这种非常特殊的场景而诞生的。可以让一个工厂负责创建多个不同类型的对象(IRuleConfigParser、ISystemConfigParser 等),而不是只创建一种 parser 对象。这样就可以有效地减少工厂类的个数
public interface IConfigParserFactory {
IRuleConfigParser createRuleParser();
ISystemConfigParser createSystemParser();
// 此处可以扩展新的parser类型,比如IBizConfigParser
}
public class JsonConfigParserFactory implements IConfigParserFactory {
@Override
public IRuleConfigParser createRuleParser() {
return new JsonRuleConfigParser();
}
@Override
public ISystemConfigParser createSystemParser() {
return new JsonSystemConfigParser();
}
}
public class XmlConfigParserFactory implements IConfigParserFactory {
@Override
public IRuleConfigParser createRuleParser() {
return new XmlRuleConfigParser();
}
@Override
public ISystemConfigParser createSystemParser() {
return new XmlSystemConfigParser();
}
}
// 省略YamlConfigParserFactory和PropertiesConfigParserFactory代码
详细可见:设计模式之美总结(创建型篇)_凡 223 的博客 工厂模式部分
1.3 建造者/构建者/生成器模式(Builder Design Pattern)
在平时的开发中,创建一个对象最常用的方式是,使用 new 关键字调用类的构造函数来完成。但什么情况下这种方式就不适用了,就需要采用建造者模式来创建对象呢?
先来看什么是对象的无效状态,如下,定义了一个长方形类,采用先创建后 set 的方式,那就会导致在第一个 set 之前,对象处于无效状态
Rectangle r = new Rectange(); // r is invalid
r.setWidth(2); // r is invalid
r.setHeight(3); // r is valid
为了避免这种无效状态的存在,就需要使用构造函数一次性初始化好所有的成员变量。如果构造函数参数过多,代码在可读性和易用性上都会变差。在使用构造函数的时候,就容易搞错各参数的顺序,传递进错误的参数值,导致非常隐蔽的 bug,这时就需要考虑使用建造者模式,先设置建造者的变量,然后再一次性地创建对象,让对象一直处于有效状态
public class ResourcePoolConfig {
private String name;
private int maxTotal;
private int maxIdle;
private int minIdle;
private ResourcePoolConfig(Builder builder) {
this.name = builder.name;
this.maxTotal = builder.maxTotal;
this.maxIdle = builder.maxIdle;
this.minIdle = builder.minIdle;
}
//...省略getter方法...
// 将Builder类设计成了ResourcePoolConfig的内部类。
// 也可以将Builder类设计成独立的非内部类ResourcePoolConfigBuilder。
public static class Builder {
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private String name;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public ResourcePoolConfig build() {
// 校验逻辑放到这里来做,包括必填项校验、依赖关系校验、约束条件校验等
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
if (maxIdle > maxTotal) {
throw new IllegalArgumentException("...");
}
if (minIdle > maxTotal || minIdle > maxIdle) {
throw new IllegalArgumentException("...");
}
return new ResourcePoolConfig(this);
}
public Builder setName(String name) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
this.name = name;
return this;
}
public Builder setMaxTotal(int maxTotal) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("...");
}
this.maxTotal = maxTotal;
return this;
}
public Builder setMaxIdle(int maxIdle) {
if (maxIdle < 0) {
throw new IllegalArgumentException("...");
}
this.maxIdle = maxIdle;
return this;
}
public Builder setMinIdle(int minIdle) {
if (minIdle < 0) {
throw new IllegalArgumentException("...");
}
this.minIdle = minIdle;
return this;
}
}
}
// 这段代码会抛出IllegalArgumentException,因为minIdle>maxIdle
ResourcePoolConfig config = new ResourcePoolConfig.Builder()
.setName("dbconnectionpool")
.setMaxTotal(16)
.setMaxIdle(10)
.setMinIdle(12)
.build();
详细可见:设计模式之美总结(创建型篇)_凡 223 的博客 建造者模式部分,这里只简要描述
1.3.1 与工厂模式有何区别?
工厂模式是用来创建不同但是相关类型的对象(继承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。建造者模式是用来创建一种类型的复杂对象,通过设置不同的可选参数,“定制化”地创建不同的对象
比如,顾客走进一家餐馆点餐,我们利用工厂模式,根据用户不同的选择,来制作不同的食物,比如披萨、汉堡、沙拉。对于披萨来说,用户又有各种配料可以定制,比如奶酪、西红柿、起司,我们通过建造者模式根据用户选择的不同配料来制作披萨
1.4 原型模式(Prototype Design Pattern)
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型设计模式(Prototype Design Pattern),简称原型模式
概念应该不难理解,通过概念应该就大致知道该设计模式的原理和用法,详细可见:设计模式之美总结(创建型篇)_凡 223 的博客 原型模式部分
2. 结构型
结构型设计模式主要解决“类或对象的组合或组装”问题
2.1 代理模式(Proxy Design Pattern)
在不改变原始类(或叫被代理类)代码的情况下,通过引入代理类来给原始类附加功能。如下例,在 UserController 中实现了接口 IUserController 的 login() 方法,用来处理登录逻辑
public interface IUserController {
UserVo login(String telephone, String password);
}
public class UserController implements IUserController {
//...省略其他属性和方法...
public UserVo login(String telephone, String password) {
// ... 省略login逻辑...
//...返回UserVo数据...
}
}
假设要在不改变该方法的情况下,扩展附加功能,比如收集接口请求的原始数据,比如访问时间、处理时长等,这时代理模式就派上用场了
如下,代理类 UserControllerProxy 和原始类 UserController 实现相同的接口 IUserController。UserController 类只负责业务功能。代理类 UserControllerProxy 负责在业务代码执行前后附加其他逻辑代码,并通过委托的方式调用原始类来执行业务代码
public class UserControllerProxy implements IUserController {
private MetricsCollector metricsCollector;
private UserController userController;
public UserControllerProxy(UserController userController) {
this.userController = userController;
this.metricsCollector = new MetricsCollector();
}
@Override
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
// 委托
UserVo userVo = userController.login(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("login", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
}
// 因为原始类和代理类实现相同的接口,是基于接口而非实现编程
// 将UserController类对象替换为UserControllerProxy类对象,不需要改动太多代码
IUserController userController = new UserControllerProxy(new UserController())
假如原始类并没有定义接口,并且原始类代码并不是我们开发维护的(比如它来自一个第三方的类库),我们也没办法直接修改原始类,给它重新定义一个接口。对于这种外部类的扩展,一般都是采用继承的方式。让代理类继承原始类,然后扩展附加功能,如下:
public class UserControllerProxy extends UserController {
private MetricsCollector metricsCollector;
public UserControllerProxy() {
this.metricsCollector = new MetricsCollector();
}
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
UserVo userVo = super.login(telephone, password);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
RequestInfo requestInfo = new RequestInfo("login", responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return userVo;
}
}
// UserControllerProxy使用举例
UserController userController = new UserControllerProxy();
应用场景:
- 业务系统的非功能性需求开发
- 在 RPC 中应用
- 在缓存中应用
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 代理模式部分
2.2 桥接/桥梁模式(Bridge Design Pattern)
在 GoF 的《设计模式》一书中,桥接模式是这么定义的:
Decouple an abstraction from its implementation so that the two can vary independently.
将抽象和实现解耦,让它们可以独立变化
弄懂定义中“抽象”、“实现”和“解耦”三个概念,就是理解桥接模式的关键
- 抽象,可以理解为存在于多个实体中的共同的概念性联系,就是忽略一些信息,从而把不同的实体当做同样的实体对待
- 实现,即抽象给出的具体实现,可能有多种不同的实现方式
- 解耦,所谓耦合,就是两个实体的行为的某种强关联。而将它们的强关联去掉,就是耦合的解脱,或称解耦。在这里,解耦是指将抽象和实现之间的耦合解脱开,或者说是将它们之间的强关联改换成弱关联。将两个角色之间的继承关系改为聚合关系,就是将它们之间的强关联改换成为弱关联,即抽象和实现之间使用组合/聚合关系而不是继承关系
建议对照示例来进行理解,具体可见:设计模式之美总结(结构型篇)_凡 223 的博客 桥接模式部分
2.3 装饰器模式(Decorator Design Pattern)
装饰器模式和代理模式比较相似,不过在代理模式中,代理类附加的是跟原始类无关的功能,而在装饰器模式中,装饰器类附加的是跟原始类相关的增强功能
// 代理模式的代码结构(下面的接口也可以替换成抽象类
public interface IA {
void f();
}
public class A impelements IA {
public void f() {
//...
}
}
public class AProxy impements IA {
private IA a;
public AProxy(IA a) {
this.a = a;
}
public void f() {
// 新添加的代理逻辑
a.f();
// 新添加的代理逻辑
}
}
// 装饰器模式的代码结构(下面的接口也可以替换成抽象类)
public interface IA {
void f();
}
public class A impelements IA {
public void f() {
//...
}
}
public class ADecorator impements IA {
private IA a;
public ADecorator(IA a) {
this.a = a;
}
public void f() {
// 功能增强代码
a.f();
// 功能增强代码
}
}
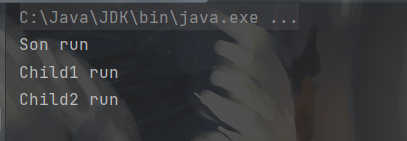
还可以进行多重装饰:
class Father {
public void run() {
System.out.println("Father run");
}
}
class Son extends Father{
public void run() {
System.out.println("Son run");
}
}
class ChildDecorator extends Father {
protected Father father;
public ChildDecorator(Father father) {
this.father = father;
}
public void run() {
father.run();
System.out.println("ChildDecorator run");
}
}
class Child1 extends ChildDecorator{
public Child1(Father father) {
super(father);
}
public void run() {
father.run();
System.out.println("Child1 run");
}
}
class Child2 extends ChildDecorator {
public Child2(Father father) {
super(father);
}
public void run() {
father.run();
System.out.println("Child2 run");
}
}
public static void main(String[] args) {
Father son = new Son();
Father child1 = new Child1(son);
Child2 child2 = new Child2(child1);
child2.run();
}
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 装饰器模式部分
2.4 适配器模式(Adapter Design Pattern)
顾名思义,这个模式就是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作
适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现
1、类适配器
// 类适配器: 基于继承
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() {
//...
}
public void fb() {
//...
}
public void fc() {
//...
}
}
public class Adaptor extends Adaptee implements ITarget {
public void f1() {
super.fa();
}
public void f2() {
//...重新实现f2()...
}
// 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
}
2、对象适配器
// 对象适配器:基于组合
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() {
//...
}
public void fb() {
//...
}
public void fc() {
//...
}
}
public class Adaptor implements ITarget {
private Adaptee adaptee;
public Adaptor(Adaptee adaptee) {
this.adaptee = adaptee;
}
public void f1() {
adaptee.fa(); //委托给Adaptee
}
public void f2() {
//...重新实现f2()...
}
public void fc() {
adaptee.fc();
}
}
针对这两种实现方式,在实际的开发中,到底该如何选择使用哪一种呢?判断的标准主要有两个,一个是 Adaptee 接口的个数,另一个是 Adaptee 和 ITarget 的契合程度
如果 Adaptee 接口并不多,那两种实现方式都可以。如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都相同,那推荐使用类适配器,因为 Adaptor 复用父类 Adaptee 的接口,比起对象适配器的实现方式,Adaptor 的代码量要少一些。如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都不相同,那推荐使用对象适配器,因为组合结构相对于继承更加灵活
应用场景:
- 封装有缺陷的接口设计
- 统一多个类的接口设计
- 替换依赖的外部系统
- 兼容老版本接口
- 适配不同格式的数据
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 适配器模式部分
2.5 代理、桥接、装饰器、适配器 4 种设计模式的区别
代理、桥接、装饰器、适配器,这 4 种模式是比较常用的结构型设计模式。它们的代码结构非常相似。笼统来说,它们都可以称为 Wrapper 模式,也就是通过 Wrapper 类二次封装原始类
尽管代码结构相似,但这 4 种设计模式的用意完全不同,也就是说要解决的问题、应用场景不同,这也是它们的主要区别
- 代理模式: 代理模式在不改变原始类接口的条件下,为原始类定义一个代理类,主要目的是控制访问,而非加强功能,这是它跟装饰器模式最大的不同
- 桥接模式: 桥接模式的目的是将接口部分和实现部分分离,从而让它们可以较为容易、也相对独立地加以改变
- 装饰器模式: 装饰者模式在不改变原始类接口的情况下,对原始类功能进行增强,并且支持多个装饰器的嵌套使用
- 适配器模式: 适配器模式是一种事后的补救策略。适配器提供跟原始类不同的接口,而代理模式、装饰器模式提供的都是跟原始类相同的接口
2.6 门面/外观模式(Facade Design Pattern)
在 GoF 的《设计模式》一书中,门面模式是这样定义的:
Provide a unified interface to a set of interfaces in a subsystem. Facade Pattern defines a higher-level interface that makes the subsystem easier to use.
门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用
概念很简单,假设有一个系统 A,提供了 a、b、c、d 四个接口。系统 B 完成某个业务功能,需要调用 A 系统的 a、b、d 接口。利用门面模式,我们提供一个包裹 a、b、d 接口调用的门面接口 x,给系统 B 直接使用
应用场景:
- 解决易用性问题:门面模式可以用来封装系统的底层实现,隐藏系统的复杂性,提供一组更加简单易用、更高层的接口
- 解决性能问题,通过将多个接口调用替换为一个门面接口调用,减少网络通信成本,提高 App 客户端的响应速度
- 解决分布式事务问题
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 门面模式部分
2.7 组合模式(Composite Design Pattern)
组合模式跟面向对象设计中的“组合关系(通过组合来组装两个类)”,完全是两码事。这里讲的“组合模式”,主要是用来处理树形结构数据。这里的“数据”,可以简单理解为一组对象集合
在 GoF 的《设计模式》一书中,组合模式是这样定义的:
Compose objects into tree structure to represent part-whole hierarchies.Composite lets client treat individual objects and compositions of objects uniformly.
将一组对象组织(Compose)成树形结构,以表示一种“部分 - 整体”的层次结构。组合让客户端(在很多设计模式书籍中,“客户端”代指代码的使用者)可以统一单个对象和组合对象的处理逻辑
比如公司的组织结构包含部门和员工两种数据类型。其中,部门又可以包含子部门和员工,这是一种嵌套结构,可以表示成树这种数据结构,这个时候就可以使用组合模式来设计和实现
再拿组合模式的定义跟这个例子对照一下:“将一组对象(员工和部门)组织成树形结构,以表示一种‘部分 - 整体’的层次结构(部门与子部门的嵌套结构)。组合模式让客户端可以统一单个对象(员工)和组合对象(部门)的处理逻辑(递归遍历)。”
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 组合模式部分
2.8 享元模式(Flyweight Design Pattern)
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象
具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元
定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何 set() 等修改内部状态的方法。之所以要求享元是不可变对象,那是因为它会被多处代码共享使用,避免一处代码对享元进行了修改,影响到其他使用它的代码
概念其实很简单,就是将重复对象或相似对象的重复部分进行复用
详细可见:设计模式之美总结(结构型篇)_凡 223 的博客 享元模式部分
2.8.1 享元模式 vs 单例、缓存、对象池
1、享元模式跟单例的区别
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于之前讲到的单例的变体:多例
但区别两种设计模式,不能光看代码实现,而是要看设计意图,也就是要解决的问题。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数
2、享元模式跟缓存的区别
在享元模式的实现中,通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。平时所讲的缓存,主要是为了提高访问效率,而非复用
3、享元模式跟对象池的区别
对象池、连接池(比如数据库连接池)、线程池等也是为了复用,那它们跟享元模式有什么区别呢?
很多人可能对连接池、线程池比较熟悉,对对象池比较陌生,这里简单解释一下对象池。像 C++ 这样的编程语言,内存的管理是由程序员负责的。为了避免频繁地进行对象创建和释放导致内存碎片,可以预先申请一片连续的内存空间,也就是这里说的对象池。每次创建对象时,从对象池中直接取出一个空闲对象来使用,对象使用完成之后,再放回到对象池中以供后续复用,而非直接释放掉
虽然对象池、连接池、线程池、享元模式都是为了复用,但是,如果再细致地抠一抠“复用”这个字眼的话,对象池、连接池、线程池等池化技术中的“复用”和享元模式中的“复用”实际上是不同的概念
池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间
3. 行为型
行为型设计模式主要解决的就是“类或对象之间的交互”问题
3.1 观察者/发布订阅模式(Observer Design Pattern/Publish-Subscribe Design Pattern)
在 GoF 的《设计模式》一书中,它的定义是这样的:
Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.
在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)。不过,在实际的项目开发中,这两种对象的称呼是比较灵活的,有各种不同的叫法,比如:Subject-Observer、Publisher-Subscriber、Producer-Consumer、EventEmitter-EventListener、Dispatcher-Listener。不管怎么称呼,只要应用场景符合刚刚给出的定义,都可以看作观察者模式
实际上,观察者模式是一个比较抽象的模式,根据不同的应用场景和需求,有完全不同的实现方式,这里来看最经典的一种实现方式,这也是在讲到这种模式的时候,很多书籍或资料给出的最常见的实现方式。具体的代码如下所示:
public interface Subject {
void registerObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObservers(Message message);
}
public interface Observer {
void update(Message message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList<Observer>();
@Override
public void registerObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
observers.remove(observer);
}
@Override
public void notifyObservers(Message message) {
for (Observer observer : observers) {
observer.update(message);
}
}
}
public class ConcreteObserverOne implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverOne is notified.");
}
}
public class ConcreteObserverTwo implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverTwo is notified.");
}
}
public class Demo {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
subject.registerObserver(new ConcreteObserverOne());
subject.registerObserver(new ConcreteObserverTwo());
subject.notifyObservers(new Message());
}
}
上面的代码算是观察者模式的“模板代码”,只能反映大体的设计思路。在真实的软件开发中,并不需要照搬上面的模板代码。观察者模式的实现方法各式各样,函数、类的命名等会根据业务场景的不同有很大的差别,比如 register 函数还可以叫作 attach,remove 函数还可以叫作 detach 等等。不过,万变不离其宗,设计思路都是差不多的
观察者模式的核心概念其实就在它的定义中。详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 观察者模式部分
3.2 模板模式(Template Method Design Pattern)
在 GoF 的《设计模式》一书中,它是这么定义的:
Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.
模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤
这里的“算法”,可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。代码示例如下:
public abstract class AbstractClass {
public final void templateMethod() {
//...
method1();
//...
method2();
//...
}
protected abstract void method1();
protected abstract void method2();
}
public class ConcreteClass1 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
public class ConcreteClass2 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
AbstractClass demo = ConcreteClass1();
demo.templateMethod();
- 作用一:复用
模板模式把一个算法中不变的流程抽象到父类的模板方法templateMethod()中,将可变的部分method1()、method2()留给子类 ContreteClass1 和 ContreteClass2 来实现。所有的子类都可以复用父类中模板方法定义的流程代码 - 作用二:扩展
这里所说的扩展,并不是指代码的扩展性,而是指框架的扩展性,有点类似之前讲到的控制反转。基于这个作用,模板模式常用在框架的开发中,让框架用户可以在不修改框架源码的情况下,定制化框架的功能
假如用过 Java Servlet,继承 HttpServlet 类然后重写 doGet() 和 doPost() 就是典型的模板模式,这里是框架的扩展作用。它将 Servlet 的执行流程进行了封装,然后将可变的 doGet() 和 doPost() 部分留给继承的子类来具体实现
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws Exception {
this.doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws Exception {
resp.getWriter().write("Hello World.");
}
}
3.2.1 模板模式 VS 回调
从应用场景上来看,同步回调跟模板模式几乎一致。它们都是在一个大的算法骨架中,自由替换其中的某个步骤,起到代码复用和扩展的目的。而异步回调跟模板模式有较大差别,更像是观察者模式
从代码实现上来看,回调和模板模式完全不同。回调基于组合关系来实现,把一个对象传递给另一个对象,是一种对象之间的关系;模板模式基于继承关系来实现,子类重写父类的抽象方法,是一种类之间的关系
前面也讲到,组合优于继承。实际上,这里也不例外。在代码实现上,回调相对于模板模式会更加灵活,主要体现在下面几点:
- 像 Java 这种只支持单继承的语言,基于模板模式编写的子类,已经继承了一个父类,不再具有继承的能力
- 回调可以使用匿名类来创建回调对象,可以不用事先定义类;而模板模式针对不同的实现都要定义不同的子类
- 如果某个类中定义了多个模板方法,每个方法都有对应的抽象方法,那即便只用到其中的一个模板方法,子类也必须实现所有的抽象方法。而回调就更加灵活,只需要往用到的模板方法中注入回调对象即可
回调等详细知识,可见:设计模式之美总结(行为型篇)_凡 223 的博客 模板模式部分
3.3 策略模式(Strategy Design Pattern)
在 GoF 的《设计模式》一书中,它是这样定义的:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)
工厂模式是解耦对象的创建和使用,观察者模式是解耦观察者和被观察者。策略模式跟两者类似,也能起到解耦的作用,不过,它解耦的是策略的定义、创建、使用这三部分
3.3.1 策略的定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。示例代码如下所示:
public interface Strategy {
void algorithmInterface();
}
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
一般来讲,如果策略类是无状态的,不包含成员变量,只是纯粹的算法实现,这样的策略对象是可以被共享使用的,不需要在每次调用 getStrategy() 的时候,都创建一个新的策略对象。针对这种情况,可以使用上面这种工厂类的实现方式,事先创建好每个策略对象,缓存到工厂类中,用的时候直接返回
相反,如果策略类是有状态的,根据业务场景的需要,希望每次从工厂方法中,获得的都是新创建的策略对象,而不是缓存好可共享的策略对象,那就需要按照如下方式来实现策略工厂类
public class StrategyFactory {
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
if (type.equals("A")) {
return new ConcreteStrategyA();
} else if (type.equals("B")) {
return new ConcreteStrategyB();
}
return null;
}
}
3.3.2 策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,需要对客户端代码屏蔽创建细节。可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。示例代码如下所示:
public class StrategyFactory {
private static final Map<String, Strategy> strategies = new HashMap<>();
static {
strategies.put("A", new ConcreteStrategyA());
strategies.put("B", new ConcreteStrategyB());
}
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return strategies.get(type);
}
}
3.3.3 策略的使用
策略模式包含一组可选策略,客户端代码一般如何确定使用哪个策略呢?最常见的是运行时动态确定使用哪种策略,这也是策略模式最典型的应用场景。这里的“运行时动态”指的是,事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略
// 策略接口:EvictionStrategy
// 策略类:LruEvictionStrategy、FifoEvictionStrategy、LfuEvictionStrategy...
// 策略工厂:EvictionStrategyFactory
public class UserCache {
private Map<String, User> cacheData = new HashMap<>();
private EvictionStrategy eviction;
public UserCache(EvictionStrategy eviction) {
this.eviction = eviction;
}
//...
}
// 运行时动态确定,根据配置文件的配置决定使用哪种策略
public class Application {
public static void main(String[] args) throws Exception {
EvictionStrategy evictionStrategy = null;
Properties props = new Properties();
props.load(new FileInputStream("./config.properties"));
String type = props.getProperty("eviction_type");
evictionStrategy = EvictionStrategyFactory.getEvictionStrategy(type);
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}
// 非运行时动态确定,在代码中指定使用哪种策略
public class Application {
public static void main(String[] args) {
//...
EvictionStrategy evictionStrategy = new LruEvictionStrategy();
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}
从上面的代码中,也可以看出,“非运行时动态确定”,也就是第二个 Application 中的使用方式,并不能发挥策略模式的优势。在这种应用场景下,策略模式实际上退化成了“面向对象的多态特性”或“基于接口而非实现编程原则”
详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 策略模式部分
3.4 职责链模式(Chain Of Responsibility Design Pattern
在 GoF 的《设计模式》中,它是这么定义的:
Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it.
将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止
在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式
职责链模式有多种实现方式,这里介绍两种比较常用的
1、链表
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
boolean handled = doHandle();
if (successor != null && !handled) {
successor.handle();
}
}
protected abstract boolean doHandle();
}
public class HandlerA extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
2、HandlerChain 类用数组而非链表来保存所有的处理器,并且需要在 HandlerChain 的 handle() 函数中,依次调用每个处理器的 handle() 函数
public interface IHandler {
boolean handle();
}
public class HandlerA implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerChain {
private List<IHandler> handlers = new ArrayList<>();
public void addHandler(IHandler handler) {
this.handlers.add(handler);
}
public void handle() {
for (IHandler handler : handlers) {
boolean handled = handler.handle();
if (handled) {
break;
}
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
在 GoF 给出的定义中,如果处理器链上的某个处理器能够处理这个请求,那就不会继续往下传递请求。实际上,职责链模式还有一种变体,那就是请求会被所有的处理器都处理一遍,不存在中途终止的情况。这种变体也有两种实现方式:用链表存储处理器和用数组存储处理器,跟上面的两种实现方式类似,只需要稍微修改即可
其实可以对照拦截器和过滤器链来理解,详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 责任链模式部分
3.5 状态模式(State Design Pattern)
在实际的软件开发中,状态模式并不是很常用,但是在能够用到的场景里,它可以发挥很大的作用。从这一点上来看,它有点像之前讲到的组合模式。状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。不过,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有 3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作
比如“超级马里奥”,在游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加 100 积分
实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)
概念不难理解,具体可见:设计模式之美总结(行为型篇)_凡 223 的博客 状态模式部分
3.6 迭代器/游标模式(Iterator Design Pattern/Cursor Design Pattern)
迭代器模式用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一
迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。简单的类图如下:
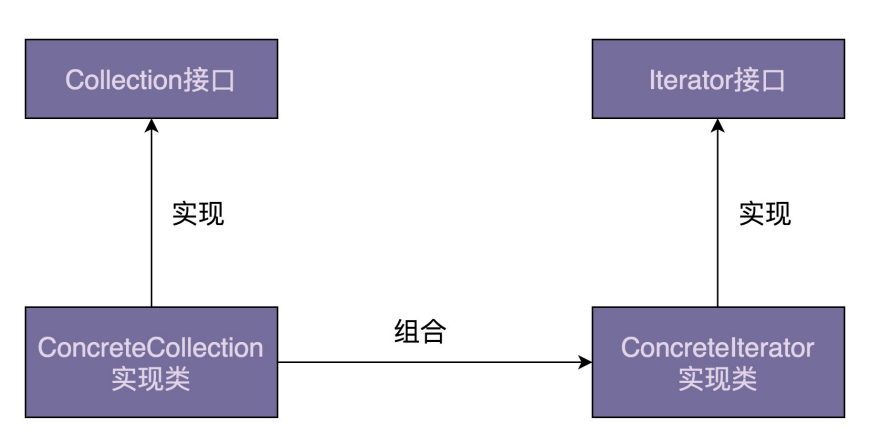
概念也很简单,可以对照 Java 的 Iterator 迭代器来理解,其他编程语言也大部分都提供了遍历容器的迭代器类,在平时开发中,直接拿来用即可,几乎不大可能从零编写一个迭代器
详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 迭代器模式部分
3.7 访问者模式(Visitor Design Pattern)
在 GoF 的《设计模式》一书中,它是这么定义的:
Allows for one or more operation to be applied to a set of objects at runtime, decoupling the operations from the object structure.
允许一个或者多个操作应用到一组对象上,解耦操作和对象本身
访问者模式这里不太好理解,建议直接去看详细的说明:设计模式之美总结(行为型篇)_凡 223 的博客 访问者模式部分
这里涉及到一个双分派的问题,Double Dispatch。既然有 Double Dispatch,对应的就有 Single Dispatch
- 所谓 Single Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的编译时类型来决定
- 所谓 Double Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的运行时类型来决定
支持双分派的语言是不需要访问者模式的,访问者模式主要是为了解决 Single Dispatch 下多态的时候,重载方法参数存在的多态问题
3.8 备忘录/快照(Snapshot)模式(Memento Design Pattern)
在 GoF 的《设计模式》一书中,备忘录模式是这么定义的:
Captures and externalizes an object’s internal state so that it can be restored later, all without violating encapsulation.
在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态
这个模式的定义主要表达了两部分内容,一部分是,存储副本以便后期恢复,另一部分是,要在不违背封装原则的前提下,进行对象的备份和恢复
概念理解起来也很简单,可以对照平时所说的备份进行理解。这两者的应用场景很类似,都应用在防丢失、恢复、撤销等场景中。它们的区别在于,备忘录模式更侧重于代码的设计和实现,备份更侧重架构设计或产品设计
详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 备忘录模式部分
3.9 命令模式(Command Design Pattern)
在 GoF 的《设计模式》一书中,它是这么定义的:
The command pattern encapsulates a request as an object, thereby letting us parameterize other objects with different requests, queue or log requests, and support undoable operations.
命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能
落实到编码实现,命令模式用的最核心的实现手段,是将函数封装成对象。C 语言支持函数指针,可以把函数当作变量传递来传递去。但是,在大部分编程语言中,函数没法作为参数传递给其他函数,也没法赋值给变量。借助命令模式,可以将函数封装成对象。具体来说就是,设计一个包含这个函数的类,实例化一个对象传来传去,这样就可以实现把函数像对象一样使用。从实现的角度来说,它类似前面提到的回调
当把函数封装成对象之后,对象就可以存储下来,方便控制执行。所以,命令模式的主要作用和应用场景,是用来控制命令的执行,比如,异步、延迟、排队执行命令、撤销重做命令、存储命令、给命令记录日志等等,这才是命令模式能发挥独一无二作用的地方
详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 命令模式部分
3.9.1 命令模式 VS 策略模式
看到上面的定义可能会觉得,命令模式跟策略模式、工厂模式非常相似,那它们的区别在哪里呢?不仅如此,感觉前面的很多模式都很相似,不知道你有没有类似的感觉呢?
实际上,每个设计模式都应该由两部分组成:第一部分是应用场景,即这个模式可以解决哪类问题;第二部分是解决方案,即这个模式的设计思路和具体的代码实现。不过,代码实现并不是模式必须包含的。如果单纯地只关注解决方案这一部分,甚至只关注代码实现,就会产生大部分模式看起来都很相似的错觉
实际上,设计模式之间的主要区别还是在于设计意图,也就是应用场景。单纯地看设计思路或者代码实现,有些模式确实很相似,比如策略模式和工厂模式
前面讲策略模式的时候有讲到,策略模式包含策略的定义、创建和使用三部分,从代码结构上来,它非常像工厂模式。它们的区别在于,策略模式侧重“策略”或“算法”这个特定的应用场景,用来解决根据运行时状态从一组策略中选择不同策略的问题,而工厂模式侧重封装对象的创建过程,这里的对象没有任何业务场景的限定,可以是策略,但也可以是其他东西。从设计意图上来,这两个模式完全是两回事儿
再来看命令模式跟策略模式的区别。你可能会觉得,命令的执行逻辑也可以看作策略,那它是不是就是策略模式了呢?实际上,这两者有一点细微的区别
在策略模式中,不同的策略具有相同的目的、不同的实现、互相之间可以替换。比如,BubbleSort、SelectionSort 都是为了实现排序的,只不过一个是用冒泡排序算法来实现的,另一个是用选择排序算法来实现的。而在命令模式中,不同的命令具有不同的目的,对应不同的处理逻辑,并且互相之间不可替换
3.10 解释器模式(Interpreter Design Pattern)
在 GoF 的《设计模式》一书中,它是这样定义的:
Interpreter pattern is used to defines a grammatical representation for a language and provides an interpreter to deal with this grammar.
解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法
这里面有很多平时开发中很少接触的概念,比如“语言”“语法”“解释器”。实际上,这里的“语言”不仅仅指平时说的中、英、日、法等各种语言。从广义上来讲,只要是能承载信息的载体,都可以称之为“语言”,比如,古代的结绳记事、盲文、哑语、摩斯密码等
要想了解“语言”表达的信息,就必须定义相应的语法规则。这样,书写者就可以根据语法规则来书写“句子”(专业点的叫法应该是“表达式”),阅读者根据语法规则来阅读“句子”,这样才能做到信息的正确传递。而解释器模式,其实就是用来实现根据语法规则解读“句子”的解释器
假设我们定义了一个新的加减乘除计算“语言”,语法规则如下:
- 运算符只包含加、减、乘、除,并且没有优先级的概念
- 表达式(也就是前面提到的“句子”)中,先书写数字,后书写运算符,空格隔开
- 按照先后顺序,取出两个数字和一个运算符计算结果,结果重新放入数字的最头部位置,循环上述过程,直到只剩下一个数字,这个数字就是表达式最终的计算结果
比如“ 8 3 2 4 - + * ”这样一个表达式,按照上面的语法规则来处理,取出数字“8 3”和“-”运算符,计算得到 5,于是表达式就变成了“ 5 2 4 + * ”。然后,再取出“ 5 2 ”和“ + ”运算符,计算得到 7,表达式就变成了“ 7 4 * ”。最后,取出“ 7 4”和“ * ”运算符,最终得到的结果就是 28。处理出这个结果的,就是解释器
概念应该不难理解,具体可见:设计模式之美总结(行为型篇)_凡 223 的博客 解释器模式部分
3.11 中介模式(Mediator Design Pattern)
在 GoF 中的《设计模式》一书中,它是这样定义的:
Mediator pattern defines a separate (mediator) object that encapsulates the interaction between a set of objects and the objects delegate their interaction to a mediator object instead of interacting with each other directly.
中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互
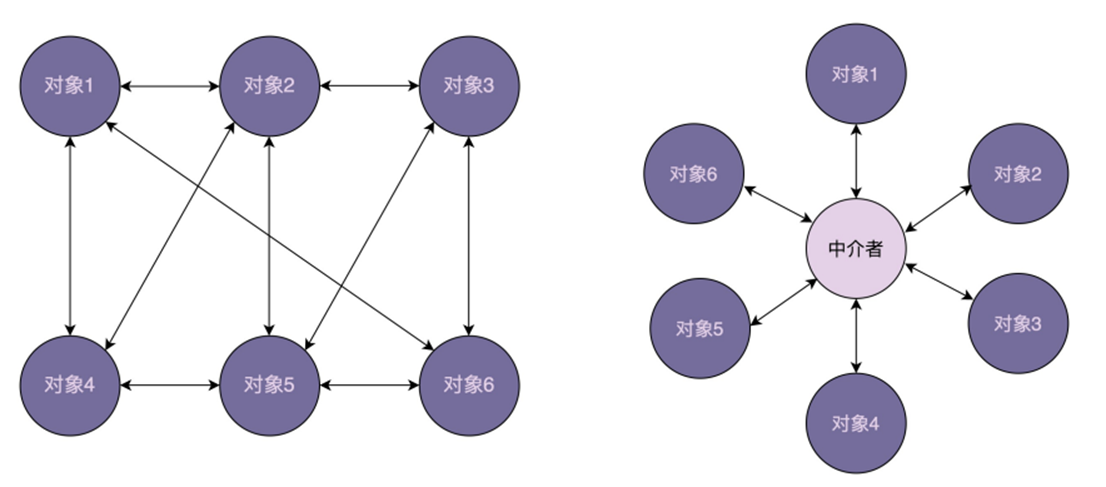
在讲到“如何给代码解耦”时,其中一个方法就是引入中间层。实际上,中介模式的设计思想跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系(或者说依赖关系)从多对多(网状关系)转换为一对多(星状关系)。原来一个对象要跟 n 个对象交互,现在只需要跟一个中介对象交互,从而最小化对象之间的交互关系,降低了代码的复杂度,提高了代码的可读性和可维护性
如下画了一张对象交互关系的对比图。其中,右边的交互图是利用中介模式对左边交互关系优化之后的结果,从图中可以很直观地看出,右边的交互关系更加清晰、简洁
提到中介模式,有一个比较经典的例子不得不说,那就是航空管制
为了让飞机在飞行的时候互不干扰,每架飞机都需要知道其他飞机每时每刻的位置,这就需要时刻跟其他飞机通信。飞机通信形成的通信网络就会无比复杂。这个时候,通过引入“塔台”这样一个中介,让每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来负责每架飞机的航线调度。这样就大大简化了通信网络
详细可见:设计模式之美总结(行为型篇)_凡 223 的博客 中介模式部分
3.11.1 中介模式 VS 观察者模式
前面讲观察者模式的时候讲到,观察者模式有多种实现方式。虽然经典的实现方式没法彻底解耦观察者和被观察者,观察者需要注册到被观察者中,被观察者状态更新需要调用观察者的 update() 方法。但是,在跨进程的实现方式中,可以利用消息队列实现彻底解耦,观察者和被观察者都只需要跟消息队列交互,观察者完全不知道被观察者的存在,被观察者也完全不知道观察者的存在
而中介模式也是为了解耦对象之间的交互,所有的参与者都只与中介进行交互。而观察者模式中的消息队列,就有点类似中介模式中的“中介”,观察者模式的中观察者和被观察者,就有点类似中介模式中的“参与者”。那问题来了:中介模式和观察者模式的区别在哪里呢?什么时候选择使用中介模式?什么时候选择使用观察者模式呢?
在观察者模式中,尽管一个参与者既可以是观察者,同时也可以是被观察者,但是,大部分情况下,交互关系往往都是单向的,一个参与者要么是观察者,要么是被观察者,不会兼具两种身份。也就是说,在观察者模式的应用场景中,参与者之间的交互关系比较有条理
而中介模式正好相反。只有当参与者之间的交互关系错综复杂,维护成本很高的时候,才考虑使用中介模式。毕竟,中介模式的应用会带来一定的副作用,它有可能会产生大而复杂的上帝类。除此之外,如果一个参与者状态的改变,其他参与者执行的操作有一定先后顺序的要求,这个时候,中介模式就可以利用中介类,通过先后调用不同参与者的方法,来实现顺序的控制,而观察者模式是无法实现这样的顺序要求的