选择的模型有:
决策树、朴素贝叶斯、K近邻、感知机
调用的头文件有:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import warnings
from sklearn.metrics import roc_curve, auc
稍微解释一下调用的头文件,好歹别不能分不出来
numpy:提供了强大的数值计算功能,包括对多维数组对象的支持、广播功能、线性代数、傅里叶变换等,是进行科学计算的基础库。
pandas:提供了数据结构DataFrame和Series,使得数据处理变得更加简单高效,能够进行数据清洗、重塑、切片、聚合等操作,常用于数据预处理和数据分析中。
matplotlib:提供了丰富的绘图工具,可以创建各种类型的静态、交互式、嵌入式图表,用于数据可视化和结果展示。
sklearn.linear_model:包含了许多线性模型,如线性回归、逻辑回归、感知机等,用于解决回归和分类问题。
sklearn.naive_bayes:实现了朴素贝叶斯分类器,用于处理分类问题,尤其在文本分类等领域应用广泛。
sklearn.neighbors:包含了近邻算法,如K近邻分类器和回归器,用于解决分类和回归问题。
sklearn.tree:包含了决策树相关的算法,如决策树分类器和回归器,用于解决分类和回归问题。
sklearn.model_selection:提供了交叉验证、参数调优等功能,用于评估模型性能和选择最佳参数。
warnings:用于控制警告信息的输出和处理,可以帮助我们在开发过程中更好地管理警告信息。
sklearn.metrics:提供了常见的模型评估指标,如准确率、精确率、召回率、ROC曲线等,用于评估模型性能。
具体代码:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import warnings
from sklearn.metrics import roc_curve, auc
warnings.filterwarnings("ignore")#将警告信息的输出暂时忽略,从而在代码执行过程中不显示警告信息。这对于一些已知的、无关紧要的警告信息,或者在模型训练过程中产生的非致命性警告,可以减少干扰并简化输出结果。
df = pd.read_csv("balance.dat", sep=',')#read_csv支持读取.dat文件
df[" Class"] = df[" Class"].map({" L": 1, " R": -1, " B": np.nan})#将类别标签转换为数值标签
df = df.dropna()#去掉不想要的值
X = df[["Left-weight", " Left-distance", " Right-weight", " Right-distance"]]
Y = df[' Class']
scores, names_model = [], []
metrics = ["precision", "f1", "recall"]#精确率(Precision):表示模型在预测为正例的样本中,真正例的比例metrics = ["precision", "f1", "recall"]#精确率(Precision):表示模型在预测为正例的样本中,真正例的比例召回率(Recall):表示模型能够正确预测为正例的样本在总体正例中的比例。
for model in [DecisionTreeClassifier(), GaussianNB(), KNeighborsClassifier(n_neighbors=3), Perceptron()]:
names_model.append(str(model).replace('()', ''))#str()函数将当前迭代中选取的模型转换为字符串。这里的模型是从一个列表中选取的,如前面提到的决策树分类器(DecisionTreeClassifier())。调用字符串的replace()方法,将其中的空括号()替换为空字符串''。这是因为在模型的字符串表示中,通常会包含这些括号,但它们对于后续处理并不重要。
model.fit(X, Y)
tempt = []
for scoring in metrics:#三个指标轮流来
score = cross_val_score(model, X, Y, cv=10, scoring=scoring)#10折交叉验证 scoring:性能度量的得分
tempt.append(score.mean())#10个数的平均值
scores.append(tempt)
scores = pd.DataFrame(scores, index=names_model, columns=metrics)#得分、每个模型的名字、每个性能指标的名称
print(f'''F度量下最优模型为{scores['f1'].idxmax()}''')#三引号是大引号,用二引号是不行的
model_dt = DecisionTreeClassifier()#决策树
model_dt.fit(X, Y)
model_nb = GaussianNB()#朴素贝叶斯
model_nb.fit(X, Y)
y_prob_dt = model_dt.predict_proba(X)[:, 1]#决策树模型会返回每个类别的概率,而[:, 1]表示我们只关心预测为正类别的概率值。
y_prob_nb = model_nb.predict_proba(X)[:, 1]
fpr_dt, tpr_dt, _ = roc_curve(Y, y_prob_dt)#fpr_dt:false positive rate,即假正率,也就是当真实标签为负类时,被模型错误地预测为正类的样本比例。tpr_dt:true positive rate,即真正率,也就是当真实标签为正类时,被模型正确地预测为正类的样本比例。_:阈值,该值在此处被忽略。在roc_curve()函数中,阈值的值会被计算出来,但在大多数情况下,我们不需要直接使用它。因为在绘制ROC曲线和计算AUC时,我们关注的是不同阈值下的假正率(FPR)和真正率(TPR)的变化趋势,而不是具体的阈值值。我们使用_来忽略阈值的返回值,因为我们只关心fpr_dt和tpr_dt
roc_auc_dt = auc(fpr_dt, tpr_dt)
fpr_nb, tpr_nb, _ = roc_curve(Y, y_prob_nb)#ROC曲线可以帮助我们理解模型在不同阈值下的性能表现,从而选择合适的阈值。AUC是ROC曲线下方的面积,它反映了分类器性能的综合指标。AUC越大,分类器的性能越好,因为它意味着分类器在不同阈值下都有较低的假正率和较高的真正率。通常,AUC值在0.5到1之间,越接近1说明分类器的性能越好。
roc_auc_nb = auc(fpr_nb, tpr_nb)
print(f'决策树模型和朴素贝叶斯模型的AUC值分别为{roc_auc_dt}和{roc_auc_nb}')
plt.figure(figsize=(8, 8))
plt.plot(fpr_dt, tpr_dt, color='darkorange', lw=2, )#假正率 真正率 橙色 线宽为2
plt.plot(fpr_nb, tpr_nb, color='blue', lw=2, )
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--')# 灰色
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.show()
格式化后的代码:(跟上面一样,看你喜欢看哪个)
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import warnings
from sklearn.metrics import roc_curve, auc
warnings.filterwarnings(
"ignore") # 将警告信息的输出暂时忽略,从而在代码执行过程中不显示警告信息。这对于一些已知的、无关紧要的警告信息,或者在模型训练过程中产生的非致命性警告,可以减少干扰并简化输出结果。
df = pd.read_csv("balance.dat", sep=',') # read_csv支持读取.dat文件
df[" Class"] = df[" Class"].map({" L": 1, " R": -1, " B": np.nan}) # 将类别标签转换为数值标签(预处理)
df = df.dropna() # 去掉不想要的值
X = df[["Left-weight", " Left-distance", " Right-weight", " Right-distance"]]
Y = df[' Class']
scores, names_model = [], []
metrics = ["precision", "f1",
"recall"] # 精确率(Precision):表示模型在预测为正例的样本中,真正例的比例metrics = ["precision", "f1", "recall"]#精确率(Precision):表示模型在预测为正例的样本中,真正例的比例召回率(Recall):表示模型能够正确预测为正例的样本在总体正例中的比例。
for model in [DecisionTreeClassifier(), GaussianNB(), KNeighborsClassifier(n_neighbors=3), Perceptron()]:
names_model.append(str(model).replace('()',
'')) # str()函数将当前迭代中选取的模型转换为字符串。这里的模型是从一个列表中选取的,如前面提到的决策树分类器(DecisionTreeClassifier())。调用字符串的replace()方法,将其中的空括号()替换为空字符串''。这是因为在模型的字符串表示中,通常会包含这些括号,但它们对于后续处理并不重要。
model.fit(X, Y)
tempt = []
for scoring in metrics: # 三个指标轮流来
score = cross_val_score(model, X, Y, cv=10, scoring=scoring) # 10折交叉验证 scoring:性能度量的得分
tempt.append(score.mean()) # 10个数的平均值
scores.append(tempt)
scores = pd.DataFrame(scores, index=names_model, columns=metrics) # 得分、每个模型的名字、每个性能指标的名称
print(f'''F度量下最优模型为{scores['f1'].idxmax()}''') # 三引号是大引号,用二引号是不行的
model_dt = DecisionTreeClassifier() # 决策树
model_dt.fit(X, Y)
model_nb = GaussianNB() # 朴素贝叶斯
model_nb.fit(X, Y)
y_prob_dt = model_dt.predict_proba(X)[:, 1] # 决策树模型会返回每个类别的概率,而[:, 1]表示我们只关心预测为正类别的概率值。
y_prob_nb = model_nb.predict_proba(X)[:, 1]
fpr_dt, tpr_dt, _ = roc_curve(Y,
y_prob_dt) # fpr_dt:false positive rate,即假正率,也就是当真实标签为负类时,被模型错误地预测为正类的样本比例。tpr_dt:true positive rate,即真正率,也就是当真实标签为正类时,被模型正确地预测为正类的样本比例。_:阈值,该值在此处被忽略。在roc_curve()函数中,阈值的值会被计算出来,但在大多数情况下,我们不需要直接使用它。因为在绘制ROC曲线和计算AUC时,我们关注的是不同阈值下的假正率(FPR)和真正率(TPR)的变化趋势,而不是具体的阈值值。我们使用_来忽略阈值的返回值,因为我们只关心fpr_dt和tpr_dt
roc_auc_dt = auc(fpr_dt, tpr_dt)
fpr_nb, tpr_nb, _ = roc_curve(Y,
y_prob_nb) # ROC曲线可以帮助我们理解模型在不同阈值下的性能表现,从而选择合适的阈值。AUC是ROC曲线下方的面积,它反映了分类器性能的综合指标。AUC越大,分类器的性能越好,因为它意味着分类器在不同阈值下都有较低的假正率和较高的真正率。通常,AUC值在0.5到1之间,越接近1说明分类器的性能越好。
roc_auc_nb = auc(fpr_nb, tpr_nb)
print(f'决策树模型和朴素贝叶斯模型的AUC值分别为{roc_auc_dt}和{roc_auc_nb}')
plt.figure(figsize=(8, 8))
plt.plot(fpr_dt, tpr_dt, color='darkorange', lw=2, ) # 假正率 真正率 橙色 线宽为2
plt.plot(fpr_nb, tpr_nb, color='blue', lw=2, )
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--') # 灰色
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.show()
图像:(把标题放下面太麻烦了,我也没整明白,将就着看吧)
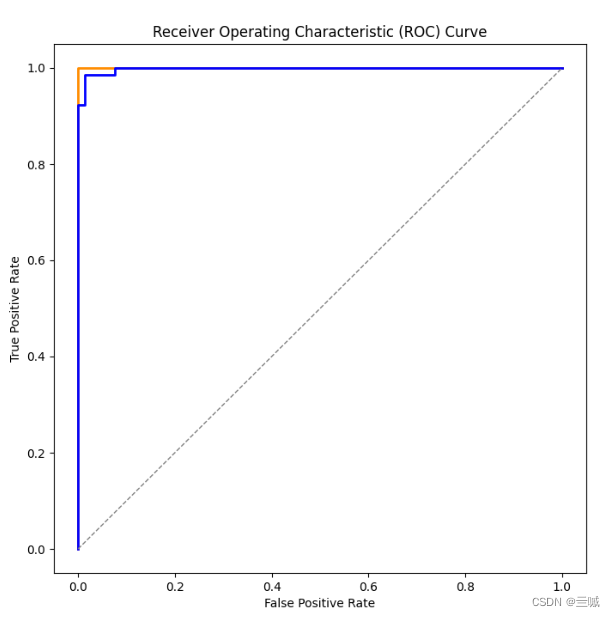
相比之下:在这个数据集中,决策树比朴素贝叶斯要好
补充一下
处理数据的时候别忘记数据预处理和数据归一化
上面这段代码并未执行归一化,当然也不太需要
对于分类模型的话:比较推荐logic回归和朴素贝叶斯