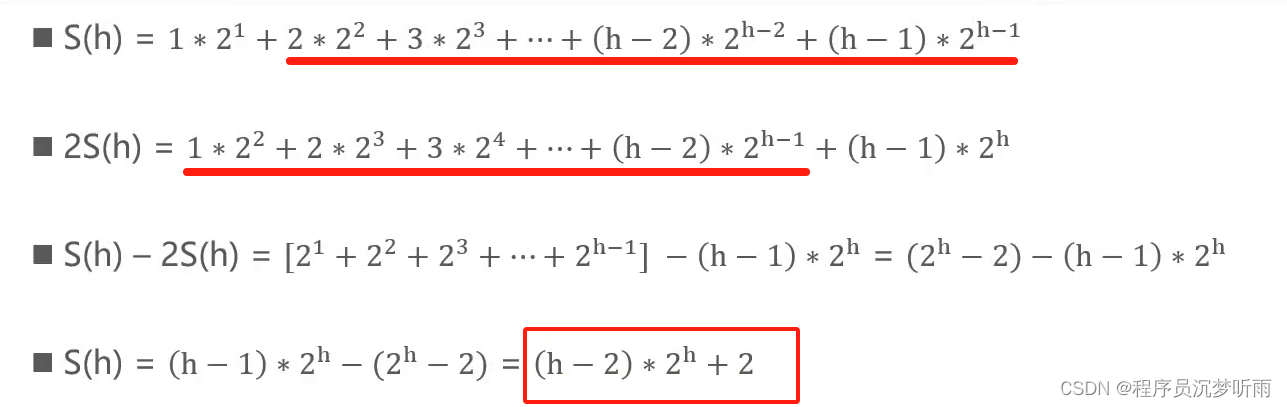Meta谷歌接连放出重磅成果!Meta开源无缝交流语音翻译模型,谷歌放出无监督语音翻译重大突破Translation 3。
就在Meta AI成立10周年之际,研究团队重磅开源了在语音翻译领域的突破性进展——「无缝交流」(Seamless Communication)模型。

作为首个开源的「大一统模型」,Seamless集成了其他三款SOTA模型的全部功能(SeamlessExpressive、SeamlessStreaming和SeamlessM4T v2),可以实时进行更自然、更真实的跨语言交流。
甚至可以说,它从本质上实现了通用语音翻译器(Universal Speech Translator)的概念。
紧接着,谷歌也分享了自己在无监督语音翻译的突破——Translation 3。
通过利用SpecAugment、MUSE嵌入和反向翻译,Translatotron 3在翻译词汇的同时,更能处理停顿、语速、说话者身份等非文本语音细微差异。
不仅如此,Translatotron 3在还可以直接从单语数据学习,摆脱了对并行数据的依赖。

论文地址:https://arxiv.org/abs/2305.17547
结果显示,在翻译质量、说话者相似性和语音自然度方面表现出色,Translation 3都超越了传统系统。
探索沟通的未来,Translatotron 3或将以前所未有的效率和准确性打破语言障碍。
Seamless:「无缝」语音翻译大一统
Seamless将SeamlessM4T v2的高质量和多语言、SeamlessStreaming的低延迟和SeamlessExpressive的表达一致性,全部融合到了一个统一的系统之中。
由此,Seamless也为了第一个能够同时保持声音风格和语调的流式翻译模型。
SeamlessExpressive:完美保留语音语调
虽然现有的翻译工具能熟练地捕捉对话内容,但它们的输出通常依赖于单调的机器人文本到语音系统。
相比之下,SeamlessExpressive则可以保留语音的细微差别,如停顿和语速,以及声音风格和情感基调。
为了在不同语言中保留说话者的语音风格,研究人员在SeamlessM4T v2基础模型中加入了表现力编码器。这一过程可确保单元生成遵循预期的语速和节奏。
此外,将SeamlessM4T v2中的HiFi-GAN单元声码器替换为以源语音为条件的表现力单元到语音生成器,可实现音调、情感和风格的无缝传输。
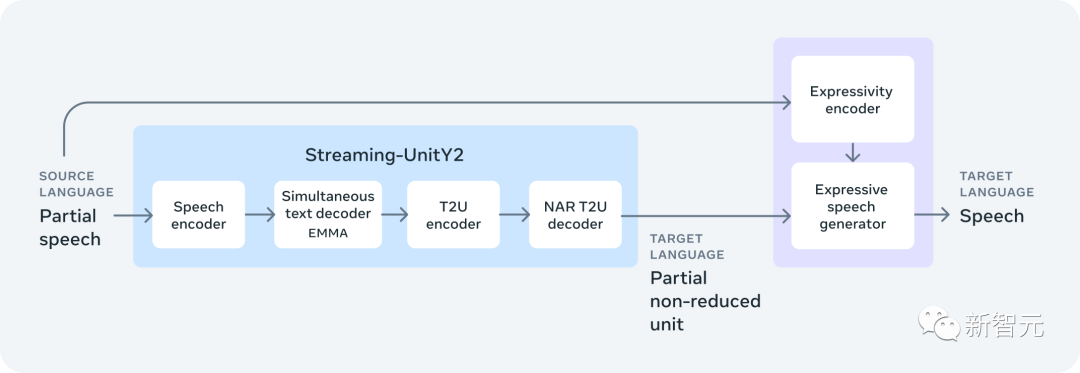
SeamlessStreaming:AI版「同声传译」
SeamlessStreaming是首个大规模多语言模型,其翻译延迟时间约为两秒,准确度几乎与离线模型相同。
SeamlessStreaming以SeamlessM4T v2为基础,支持近100种输入和输出语言的自动语音识别和语音到文本翻译,以及近100种输入语言和36种输出语言的语音到语音翻译。
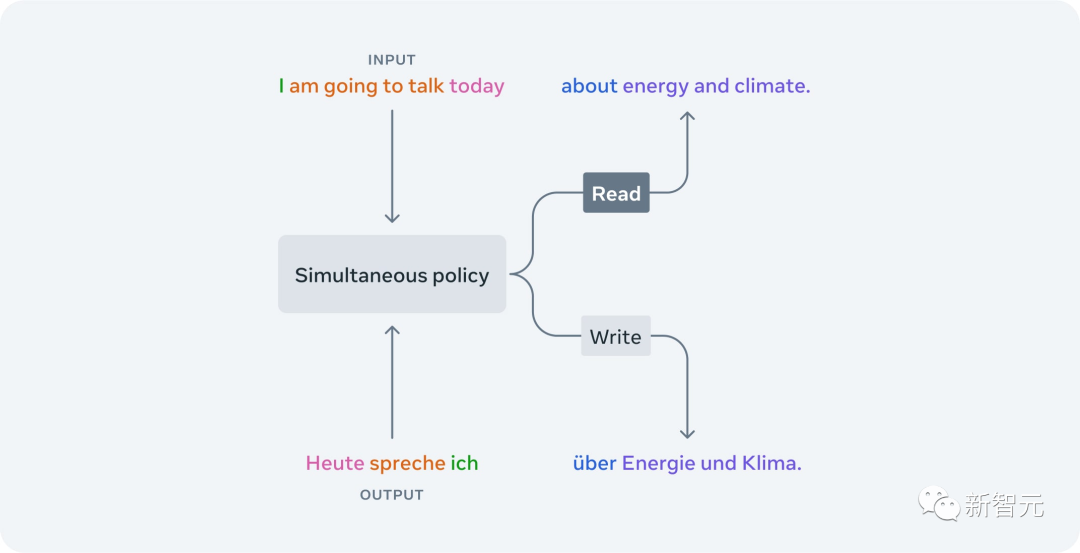
Meta AI最先进的流模型SeamlessStreaming能够智能地决定何时有足够的语境来输出下一个目标文本或语音片段。
SeamlessStreaming学习到的读/写策略,会根据部分音频输入来决定是「写」并生成输出,还是「读」并继续等待更多输入。并且,还可以自适应不同的语言结构,从而在许多不同的语言对中发挥更强的性能。
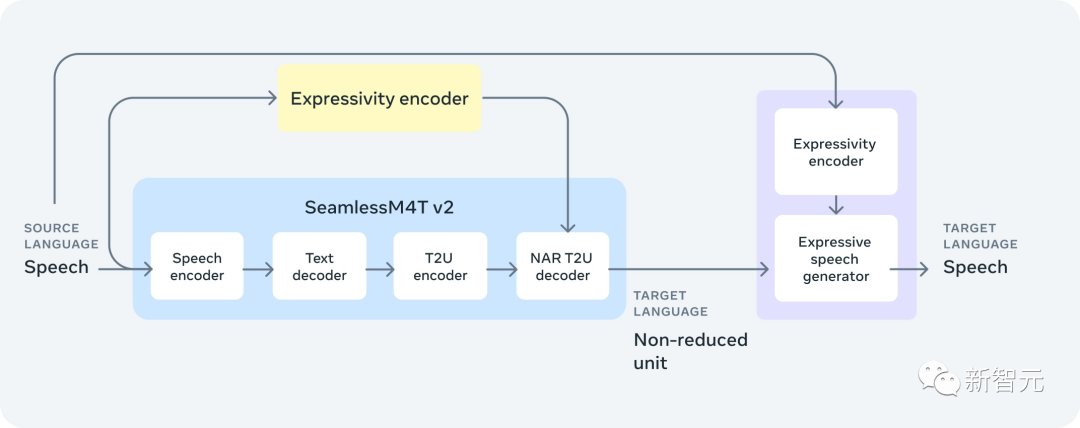
SeamlessM4T v2:更高质量、更高精度
2023年8月,Meta AI推出了第一版SeamlessM4T——一个基础多语言和多任务模型,可为跨语音和文本的翻译和转录提供SOTA的结果。
在此基础上,研究人员于11月推出了改进版的SeamlessM4T v2,作为全新SeamlessExpressive和SeamlessStreaming模型的基础。
升级后的SeamlessM4T v2采用非自回归文本到单元解码器,从而提高了文本和语音输出之间的一致性。
其中,w2v-BERT 2.0编码器是在450万小时的语音数据基础上训练出来的。相比之前,第一版的训练数据只有100万小时。
此外,SeamlessM4T v2还通过全新的SeamlessAlign,为低资源语言补充了更多数据。
评估结果显示,SeamlessM4T v2在BLEU、ASR-BLEU、BLASER 2等任务上的表现,明显优于之前的SOTA模型。

SeamlessAlignExpressive
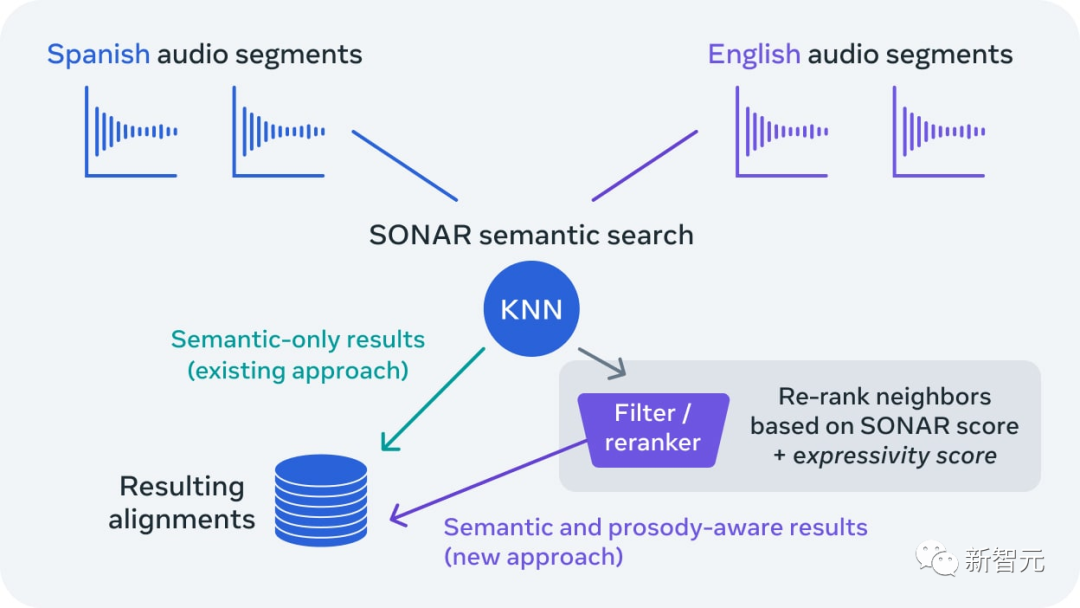
基于之前在WikiMatrix、CCMatrix、NLLB、SpeechMatrix和SeamlessM4T方面所做的工作,Meta AI推出了首个表达式语音对齐程序——SeamlessExpressive。
从原始数据开始,富有表现力的对齐程序会自动发现成对的音频片段,这些片段不仅具有相同的含义,而且具有相同的整体表现力。
基于此,Meta还创建了第一个用于基准测试的多语言音频对齐的大型基准测试数据集——SeamlessAlignExpressive。
Translatotron 3:引领无监督语音翻译新时代
谷歌联合DeepMind提出的无监督语音到语音翻译架构Translatotron 3,不仅为更多语言对之间的翻译,还为停顿、语速和说话人身份等非文本语音属性的翻译打开了大门。
这种方法不用对目标语言进行任何直接的监督,而且可以在翻译过程中保留源语音的其他特征(如语调、情感等)。
Translatotron 3在保留源语音其他特征(如语调、情感等)的同时,无需对目标语言进行任何直接的监督,并且还
摒弃了对双语语音数据集的需求。
其设计包含三个关键方面:
1. 使用SpecAugment将整个模型作为mask自动编码器进行预训练
SpecAugment是一种简单的语音识别数据增强方法,可在输入音频(而非原始音频本身)的对数梅尔频谱图上进行操作,从而有效提高编码器的泛化能力。
2. 基于MUSE的无监督嵌入映射
多语言无监督嵌入是在未配对的语言上进行训练的,可以让模型学习源语言和目标语言之间共享的嵌入空间。
3. 基于反向翻译的重构损失
这种方法可以完全采用无监督的方式,来训练编码器-解码器S2ST模型。
效果展示(西班牙语-英语)
输入
CommonVoice11 Input
CommonVoice11 Synthesized Input
Conversational Input
TTS合成
CommonVoice11 TTS
CommonVoice11 Synthesized TTS
Conversational TTS
Translatotron 3
CommonVoice11 Translation 3
CommonVoice11 Synthesized Translation 3
Conversational Translation 3
结构
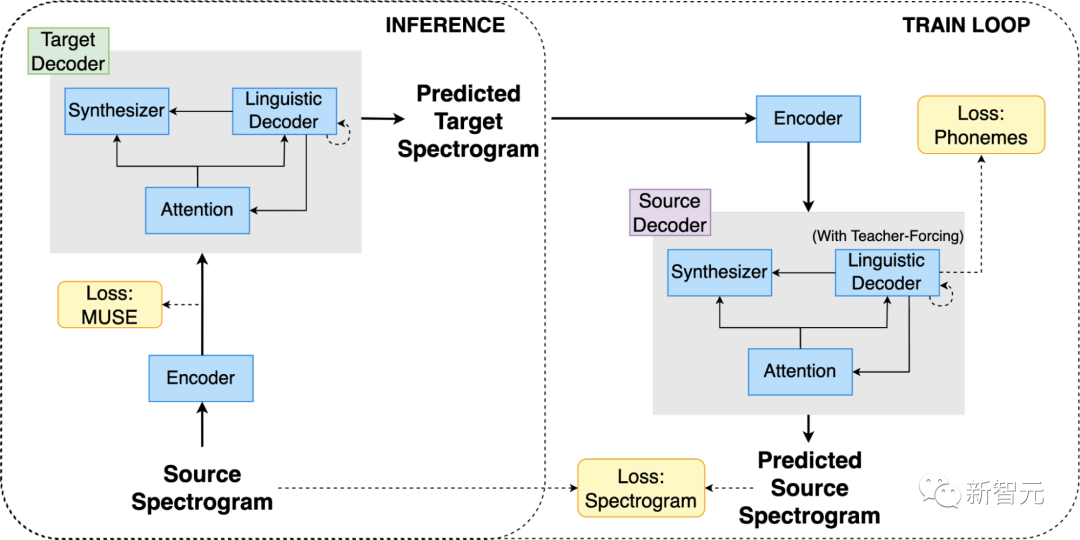
Translatotron 3采用共享编码器对源语言和目标语言进行编码。其中,解码器由语言解码器、声音合成器(负责翻译语音的声音生成)和单一注意力模块组成。
相比于上一代Translatotron 2,Translatotron 3配备有两个解码器,一个用于源语言,另一个用于目标语言。
在训练过程中,研究人员使用单语语音-文本数据集(这些数据由语音-文本对组成;并且没有进行翻译)。
编码器
编码器的输出分为两部分:第一部分包含语义信息,第二部分包含声学信息。
其中,前半部分的输出被训练成输入语音频谱图文本的MUSE嵌入。后半部分在没有MUSE损失的情况下进行更新。
值得注意的是,源语言和目标语言共享同一个编码器。
基于MUSE嵌入的多语言性质,编码器能够学习源语言和目标语言的多语言嵌入空间。
这样一来,编码器就能将两种语言的语音编码到一个共同的嵌入空间中,而不是为每种语言保留一个单独的嵌入空间,从而更高效、更有效地对输入进行编码。
解码器
解码器由三个不同的部分组成,即语言解码器、声音合成器和注意力模块。
为了有效处理源语言和目标语言的不同属性,Translatotron 3配备有两个独立的解码器,分别用于源语言和目标语言。
训练
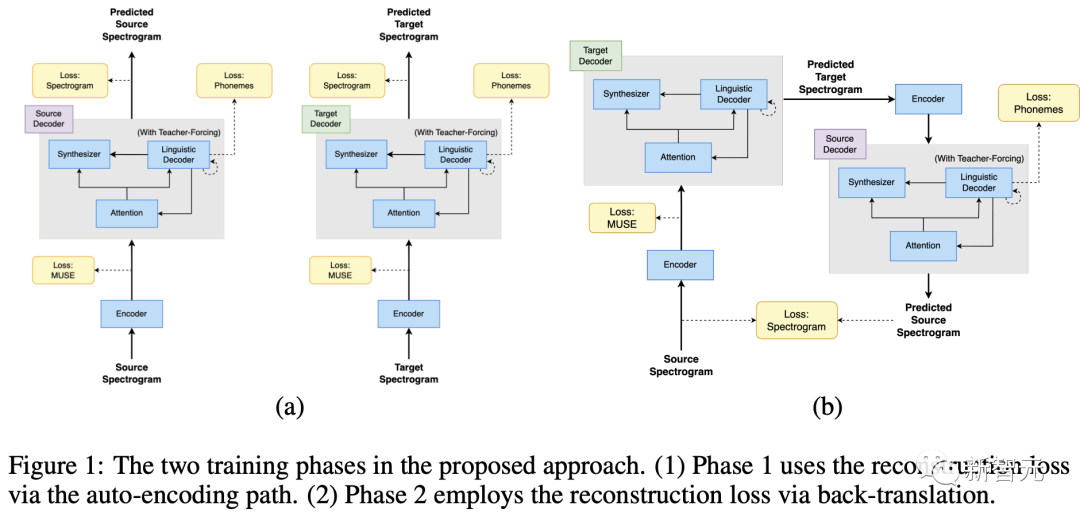
训练由两个阶段组成:(1)自动编码与重构;(2)反向翻译。
第一个阶段中,使用MUSE损失和重构损失对网络进行训练,从而将输入内容自动编码到多语言嵌入空间,确保网络生成有意义的多语言表征。
在第二阶段中,利用反向翻译损失进一步训练网络翻译输入频谱图。为了减轻灾难性遗忘的问题,并确保潜空间是多语言的,此阶段依然采用MUSE损失和重构损失。
为了确保编码器学习输入的有意义属性,而不是简单地重构输入,研究人员在两个阶段都对编码器输入应用了 SpecAugment。事实证明,通过增强输入数据,可以有效提高编码器的泛化能力。
- MUSE损失:MUSE损失衡量的是输入频谱图的多语言嵌入与反向翻译频谱图的多语言嵌入之间的相似性。
- 重构损失: 重构损失衡量的是输入频谱图与反向翻译频谱图之间的相似度。
性能
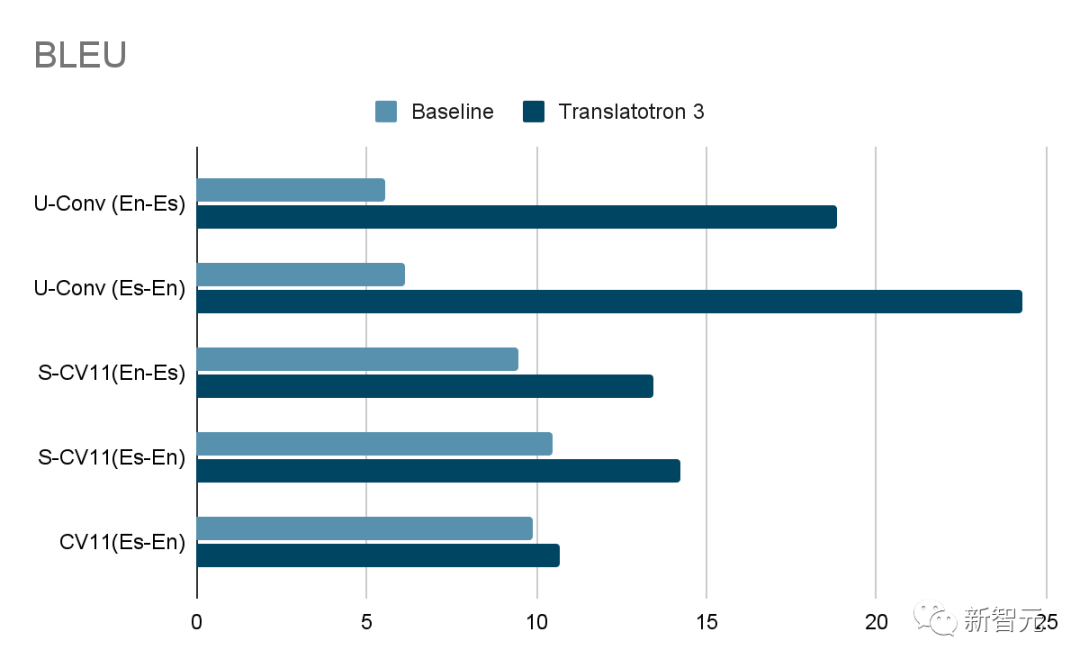
评估中包括Common Voice 11数据集,以及从对话和Common Voice 11数据集衍生出的两个合成数据集。
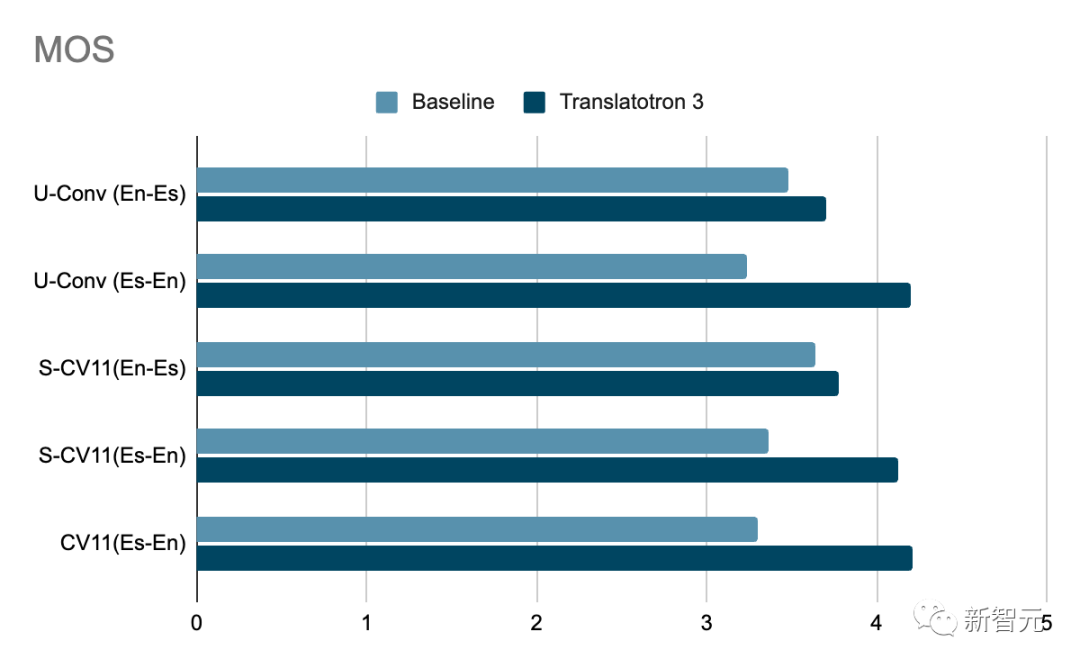
其中,翻译质量是通过翻译语音的ASR(自动语音识别)转录的BLEU(越高越好)与相应的参考翻译文本进行比较来衡量的。而语音质量则通过MOS分数来衡量(越高越好)。此外,说话人相似度是通过平均余弦相似度来衡量的(越高越好)。
由于Translatotron 3是一种无监督方法,因此研究人员使用了由ASR、无监督机器翻译(UMT)和 TTS(文本到语音)组合而成的级联S2ST系统作为基准。
结果显示,Translatotron 3在翻译质量、说话者相似性和语音质量等各方面的表现都远远优于基线,在会话语料库中的表现尤为突出。
此外,Translatotron 3实实现了与真实音频样本相似的语音自然度(以MOS衡量,越高越好)。

参考资料:
https://ai.meta.com/research/seamless-communication/
https://blog.research.google/2023/12/unsupervised-speech-to-speech.html