做美颜需要使用到人脸关键点,所以整理了一下最近的想法。
按模型结构分类:
1.Top-Down: 分为两个步骤,首先,对于原始输入图片做目标检测,比如做人脸检测,将人脸区域抠出,单独送进关键点检测模型,最终输出关键点的坐标。
2.Bottom-up: 只有一个模型,不需要进行目标检测,直接将原始图像送进关键点检测模型,即可输出所有关键点。如果有多个目标,则无法区分哪些点属于目标1,哪些点属于目标2。因此有多个目标时,还需要在后面接一个聚类的模块,将各个目标的关键点进行区分。
按回归/热力图分类:
1.回归(Regression): 优点:训练和推理速度快;是端到端全微分模型;缺点:空间泛化能力丢失,被reshape成一维向量,严重依赖于训练数据的分布,容易过拟合。
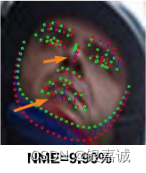
2.热力图(Heatmap): 输出特征图大,空间泛化能力强,精度高;缺点:训练和推理慢;不是端到端全微分模型;结果输出是整数(全连接输出是浮点数),会丢失精度,存在理论误差下界

个人选择使用的是Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild
论文地址:https://arxiv.org/abs/2003.03771
开源地址:jhb86253817/PIPNet: Efficient facial landmark detector (github.com)
亮点:PIP+NRM邻居节点回归模块(NRM, Neighbor Regression Module)。但NRM其实就是让原本每一格预测一个关键点,变成了预测多个关键点,也就是说,一块特征除了预测自己那个点外,还要预测周围最近的关键点,对于邻近点的定义,是从平均脸型上用欧氏距离计算得到的。
这个算法经过与PFLD还有RTMPose对比感觉要好一些(个人数据集上)。
但是代码中并没有给106人脸关键点的预处理等脚本,所以根据LaPa格式自己写了个,也可以在preprocess中自己复写。我原始的label是txt格式的,每个txt名与图片名一样,里面是106*2,每行是x y坐标(没有归一化),
import cv2
import os
import numpy as np
folder_path = r'data/hyy_image'
for filename in os.listdir(folder_path):
if filename.endswith('.png'):
new_filename = filename.replace('.png', '.jpg')
os.rename(os.path.join(folder_path, filename), os.path.join(folder_path, new_filename))
def resize_image_with_keypoints(image_path, label_path, target_width=256, target_height=256):
img = cv2.imread(image_path)
#print(img)
h, w = img.shape[:2]
# 计算缩放比例
c = max(w,h)
#ratio_w = target_width / w
#ratio_h = target_height / h
ratio = target_width/c
# 等比例缩放图像
img_resized = cv2.resize(img, (int(w * ratio), int(h * ratio)), interpolation=cv2.INTER_AREA)
print(img_resized.shape)
# 读取标签文件
with open(label_path, 'r') as label_file:
lines = label_file.readlines()
keypoints = []
for line in lines:
x, y = map(float, line.strip().split())
keypoints.append((x * ratio, y * ratio)) # 调整关键点坐标
# 创建新的空白图像
result = np.zeros((target_height, target_width, 3), dtype=np.uint8)
x = (target_width - img_resized.shape[1]) // 2
y = (target_height - img_resized.shape[0]) // 2
# 将调整后的图像粘贴到新图像中心
result[y:y + img_resized.shape[0], x:x + img_resized.shape[1]] = img_resized
# 归一化关键点坐标
normalized_keypoints = []
for kp in keypoints:
# 考虑了填充操作的影响,对关键点坐标进行调整
normalized_x = (kp[0] + (target_width - img_resized.shape[1]) / 2) / target_width
normalized_y = (kp[1] + (target_height - img_resized.shape[0]) / 2) / target_height
normalized_keypoints.append((normalized_x, normalized_y))
return result, normalized_keypoints
# 源图片路径
folder_A = r'data/xxx_image'
# 源label路径
folder_B = r'data/xxx_txt'
#resize后保存图片路径
folder_C = r'data/xxx/images_train'
# 生成 train.txt 的路径
train_txt_path = r'data/xxx/train.txt'
# 遍历 A 文件夹中的图片
with open(train_txt_path, 'w') as train_txt:
for filename in os.listdir(folder_B):
if filename.endswith('.txt'):
print(filename)
label_path = os.path.join(folder_B, filename)
image_path = os.path.join(folder_A, filename.replace('.txt', '.jpg'))
filename_image = os.path.join(folder_C,filename.replace('.txt', '.jpg'))
print(filename_image)
print(image_path)
#label_path = os.path.join(folder_B, filename.replace('.jpg', '.txt'))
if os.path.exists(label_path):
# 调整图片和关键点坐标
resized_img, normalized_keypoints = resize_image_with_keypoints(image_path, label_path)
# 保存调整后的图片
cv2.imwrite(f'{filename_image}', resized_img)
# 写入 train.txt
train_txt.write(filename.replace('.txt', '.jpg'))
for kp in normalized_keypoints:
train_txt.write(f' {kp[0]} {kp[1]}')
train_txt.write('\n')注意如果不在预处理中进行等比例缩放的话,train的时候会直接resize成256*256(或其他自定义尺寸),此时会将图片压缩或拉伸,所以我这里使用了等比例缩放图片,并将关键点坐标也对应处理后,转成train.py需要的train.txt。
这个文件中每一行是一张图片的label信息,第一个值为图片在images_train文件夹下的名字,后续106*2个值为归一化的关键点坐标。如4364054413_3.jpg 0.2863247863247863 0.3805309734513274 ......
哦对了,还需要生成meanface.txt文件:
import os
import numpy as np
def gen_meanface(root_folder, data_name):
with open(os.path.join(root_folder, data_name, 'train.txt'), 'r') as f:
annos = f.readlines()
annos = [x.strip().split()[1:] for x in annos]
annos = [[float(x) for x in anno] for anno in annos]
annos = np.array(annos)
meanface = np.mean(annos, axis=0)
meanface = meanface.tolist()
meanface = [str(x) for x in meanface]
with open(os.path.join(root_folder, data_name, 'meanface.txt'), 'w') as f:
f.write(' '.join(meanface))
data_name = 'xxx'
root_folder = 'data'
gen_meanface(root_folder, data_name)然后在network.py中,可以对模型进行自定义更改,比如他原本的Pip_mbnetv2直接用mbnetv2作为骨干网络提取特征,再在head中使用五个卷积做热力图和回归还有近邻回归,但mbnetv2的最后一层输出960维,而我是106关键点,所以卷积输入960,输出106,感觉没必要,所以我想改一下,使用320或640的backbone输出:
class Pip_mbnetv2(nn.Module):
def __init__(self, mbnet, num_nb, num_lms=68, input_size=256, net_stride=32):
super(Pip_mbnetv2, self).__init__()
self.num_nb = num_nb
self.num_lms = num_lms
self.input_size = input_size
self.net_stride = net_stride
self.features = mbnet.features
self.sigmoid = nn.Sigmoid()
new_conv2d = nn.Conv2d(320, 640, kernel_size=(1, 1), stride=(1, 1), bias=False)
new_bn = nn.BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.features[18][0] = new_conv2d
self.features[18][1] = new_bn
self.cls_layer = nn.Conv2d(640, num_lms, kernel_size=1, stride=int(net_stride/32), padding=0)
self.x_layer = nn.Conv2d(640, num_lms, kernel_size=1, stride=int(net_stride/32), padding=0)
self.y_layer = nn.Conv2d(640, num_lms, kernel_size=1, stride=int(net_stride/32), padding=0)
self.nb_x_layer = nn.Conv2d(640, num_nb*num_lms, kernel_size=1, stride=int(net_stride/32), padding=0)
self.nb_y_layer = nn.Conv2d(640, num_nb*num_lms, kernel_size=1, stride=int(net_stride/32), padding=0)
nn.init.normal_(self.cls_layer.weight, std=0.001)
if self.cls_layer.bias is not None:
nn.init.constant_(self.cls_layer.bias, 0)
nn.init.normal_(self.x_layer.weight, std=0.001)
if self.x_layer.bias is not None:
nn.init.constant_(self.x_layer.bias, 0)
nn.init.normal_(self.y_layer.weight, std=0.001)
if self.y_layer.bias is not None:
nn.init.constant_(self.y_layer.bias, 0)
nn.init.normal_(self.nb_x_layer.weight, std=0.001)
if self.nb_x_layer.bias is not None:
nn.init.constant_(self.nb_x_layer.bias, 0)
nn.init.normal_(self.nb_y_layer.weight, std=0.001)
if self.nb_y_layer.bias is not None:
nn.init.constant_(self.nb_y_layer.bias, 0)
def forward(self, x):
#print(self.features)
x = self.features(x)
#print('x.shape',x.shape)
x1 = self.cls_layer(x)
x2 = self.x_layer(x)
x3 = self.y_layer(x)
x4 = self.nb_x_layer(x)
x5 = self.nb_y_layer(x)
return x1, x2, x3, x4, x5这里不直接拿mbnetv2的960维输出再加卷积变成640,而是直接对mbnetv2的features[18]里的内容进行更改,这样减少了该层和多余的计算量,还避免了特征冗余,如果想使用320的backbone输出的话,可以这样:self.features[18][0] = nn.Identity()
然后stride这里根据config的改动而动态变化,不然config的stride传不到这里来。


![CPP-SCNUOJ-Problem P24. [算法课贪心] 跳跃游戏](https://img-blog.csdnimg.cn/direct/0cbfd74c75b641c1acbdd337f613d27d.png)