区间dp
文章目录
- 区间dp
- 概述
- 模板
- 例题
- 石子合并
- 思路
- 代码
- 环形石子合并
- 思路
- 代码
- 能量项链
- 思路
- 代码
- 加分二叉树
- 思路
- 代码
- 凸多边形的划分
- 思路
- 代码
- 棋盘分割
- 思路
- 代码
- 总结
概述
区间dp就是在区间上进行动态规划,求解一段区间上的最优解。主要是通过合并小区间的最优解进而得出整个大区间上最优解的dp算法。
模板
for (int len = 1; len <= n; len ++)
for (int L = 1; L + len - 1 <= n; L ++)
R = L + len - 1
\\在(L~R)间选取分隔点
例题
石子合并
设有 N 堆石子排成一排,其编号为 1,2,3,…,N。
每堆石子有一定的质量,可以用一个整数来描述,现在要将这 N 堆石子合并成为一堆。
每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子相邻的石子将和新堆相邻,合并时由于选择的顺序不同,合并的总代价也不相同。
例如有 4 堆石子分别为 1 3 5 2, 我们可以先合并 1、2 堆,代价为 4,得到 4 5 2, 又合并 1,2 堆,代价为 9,得到 9 2 ,再合并得到 11,总代价为 4+9+11=24;
如果第二步是先合并 2,3 堆,则代价为 7,得到 4 7,最后一次合并代价为 11,总代价为 4+7+11=22。
问题是:找出一种合理的方法,使总的代价最小,输出最小代价。
输入格式
第一行一个数 N 表示石子的堆数 N。
第二行 N 个数,表示每堆石子的质量(均不超过 1000)。
输出格式
输出一个整数,表示最小代价。
数据范围
1≤N≤300
输入样例:
4
1 3 5 2
输出样例:
22
思路
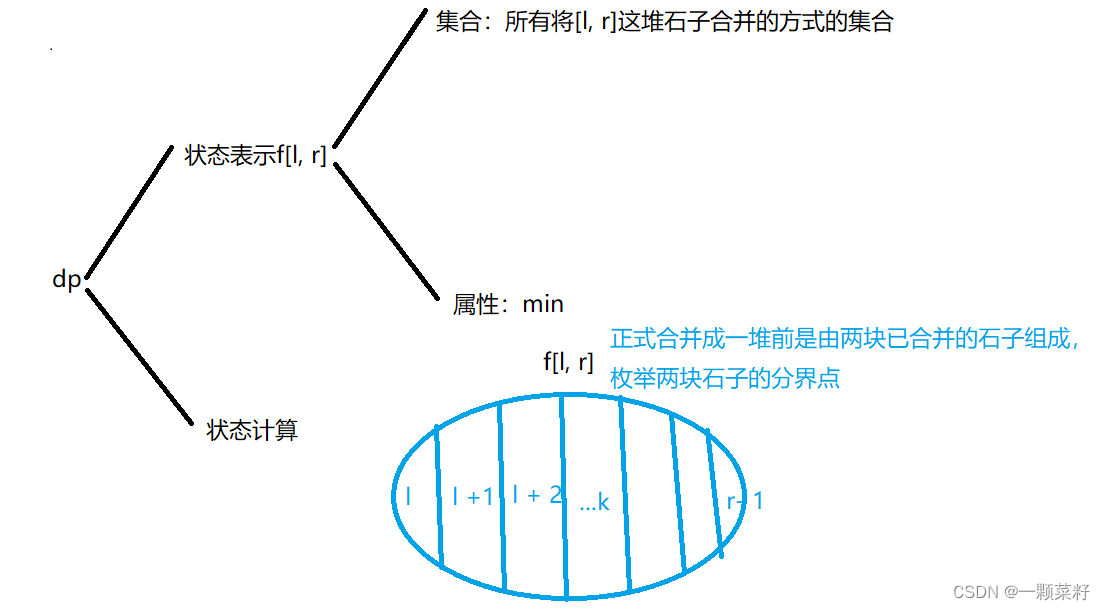
假设最后两块石子之间的分界点是k,左边石子合并的最小代价为f[l, k],右边石子合并的最小代价为f[k + 1, r],再将两块石子合并的代价为w[l, r],所以
f[l, r] = min(f[l, r], f[l, k] + f[k + 1, r] + w[l, r)
代码
N = 310
INF = 3000100
nums = [0]
f = [[0] * N for _ in range(N)]#不能初始化为无穷,因为f[i][i]默认为0
n = int(input())
nums[1 :] = list(map(int, input().split()))
for i in range(1, n + 1) :
nums[i] += nums[i - 1]
for len in range(2, n + 1) :#合并后的长度
for l in range(1, n + 1) :
r = i + len - 1
if r > n :
break
f[l][r] = INF #为了比较
for k in range(l, r) :
f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r] + nums[r] - nums[l - 1]) #合并操作
print(f[1][n])
环形石子合并
将 n 堆石子绕圆形操场排放,现要将石子有序地合并成一堆。
规定每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数记做该次合并的得分。
请编写一个程序,读入堆数 n 及每堆的石子数,并进行如下计算:
选择一种合并石子的方案,使得做 n−1 次合并得分总和最大。
选择一种合并石子的方案,使得做 n−1 次合并得分总和最小。
输入格式
第一行包含整数 n,表示共有 n 堆石子。
第二行包含 n 个整数,分别表示每堆石子的数量。
输出格式
输出共两行:
第一行为合并得分总和最小值,
第二行为合并得分总和最大值。
数据范围
1≤n≤200
输入样例:
4
4 5 9 4
输出样例:
43
54
思路
相比于上一题,本题是环形。但合并的石子数量不变,只是合并石子最终相连成的首尾状态不同。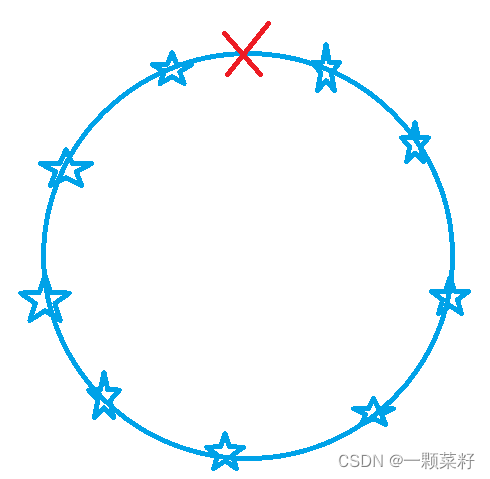 如图,最终的首尾是带×的边的两端,×可以在任意一条边上。于是我们可以枚举首尾状态,进行上面一题的迭代操作。这里有个更好的方法
如图,最终的首尾是带×的边的两端,×可以在任意一条边上。于是我们可以枚举首尾状态,进行上面一题的迭代操作。这里有个更好的方法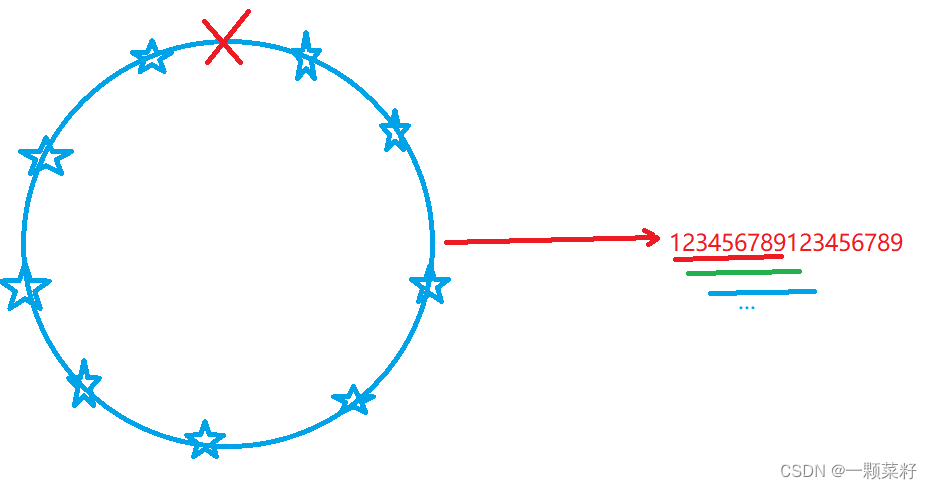
通过将将两块石堆节点首尾相连,枚举起点不同长度为n的最小代价,就能得到不同首尾中的最小代价。
代码
N = 410
INF = int(1e9) + 7
w = [0] * N
s = [0] * N
f = [[INF] * N for _ in range(N)]
g = [[-INF] * N for _ in range(N)]
n = int(input())
w[1 : n + 1] = list(map(int, input().split()))
w[n + 1 : 2 * n] = w[1 : n + 1]
for i in range(1, 2 * n + 1) : #前缀和
s[i] = s[i - 1] + w[i]
for len in range(1, n + 1) : #枚举区间长度
for l in range(1, 2 * n) : #枚举左边界
r = l + len - 1
if r > 2 * n : break
if len == 1 :
f[l][r] = 0
g[l][r] = 0
else :
for k in range(l, r) : #枚举分隔点
f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r] + s[r] - s[l - 1])
g[l][r] = max(g[l][r], g[l][k] + g[k + 1][r] + s[r] - s[l - 1])
minv, maxv = INF, - INF
for i in range(1, n + 1) :
minv = min(minv, f[i][i + n - 1])
maxv = max(maxv, g[i][i + n - 1])
print(f"{minv}\n{maxv}")
能量项链
在 Mars 星球上,每个 Mars 人都随身佩带着一串能量项链,在项链上有 N 颗能量珠。
能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某个正整数。
并且,对于相邻的两颗珠子,前一颗珠子的尾标记一定等于后一颗珠子的头标记。
因为只有这样,通过吸盘(吸盘是 Mars 人吸收能量的一种器官)的作用,这两颗珠子才能聚合成一颗珠子,同时释放出可以被吸盘吸收的能量。
如果前一颗能量珠的头标记为 m,尾标记为 r,后一颗能量珠的头标记为 r,尾标记为 n,则聚合后释放的能量为 m×r×n(Mars 单位),新产生的珠子的头标记为 m,尾标记为 n。
需要时,Mars 人就用吸盘夹住相邻的两颗珠子,通过聚合得到能量,直到项链上只剩下一颗珠子为止。
显然,不同的聚合顺序得到的总能量是不同的,请你设计一个聚合顺序,使一串项链释放出的总能量最大。
例如:设 N=4,4 颗珠子的头标记与尾标记依次为 (2,3)(3,5)(5,10)(10,2)。
我们用记号 ⊕ 表示两颗珠子的聚合操作,(j⊕k) 表示第 j,k 两颗珠子聚合后所释放的能量。则
第 4、1 两颗珠子聚合后释放的能量为:(4⊕1)=10×2×3=60。
这一串项链可以得到最优值的一个聚合顺序所释放的总能量为 ((4⊕1)⊕2)⊕3)=10×2×3+10×3×5+10×5×10=710。
输入格式
输入的第一行是一个正整数 N,表示项链上珠子的个数。
第二行是 N 个用空格隔开的正整数,所有的数均不超过 1000,第 i 个数为第 i 颗珠子的头标记,当 i<N 时,第 i 颗珠子的尾标记应该等于第 i+1 颗珠子的头标记,第 N 颗珠子的尾标记应该等于第 1 颗珠子的头标记。
至于珠子的顺序,你可以这样确定:将项链放到桌面上,不要出现交叉,随意指定第一颗珠子,然后按顺时针方向确定其他珠子的顺序。
输出格式
输出只有一行,是一个正整数 E,为一个最优聚合顺序所释放的总能量。
数据范围
4≤N≤100,
1≤E≤2.1×109
输入样例:
4
2 3 5 10
输出样例:
710
思路
f[l,r]表示将[l, r]合并成一个矩阵的所释放的最大能量
由于第 i 颗珠子的尾标记应该等于第 i+1 颗珠子的头标记,第 N 颗珠子的尾标记应该等于第 1 颗珠子的头标记,所以此题是一个环形区间dp问题。
假设分隔点为k,左右合并后所释放的能量为f[l, k] + f[k, r] + w[l] * w[k] * w[r],枚举每个分隔点,找到最小值
代码
N = 210
w = [0] * N
f = [[0] * N for _ in range(N)]
n = int(input())
w[1 : n + 1] = list(map(int, input().split()))
w[n + 1 : 2 * n + 1] = w[1 : n + 1]
for length in range(3, n + 2) : #枚举长度
for l in range(1, 2 * n + 1) : #枚举左端点
r = l + length -1
if r > 2 * n : break
for k in range(l + 1, r) : #枚举分隔点
f[l][r] = max(f[l][r], f[l][k] + f[k][r] + w[l] * w[k] * w[r])
res = 0
for i in range(1, n + 1) :
res = max(res, f[i][i + n])
print(res)
加分二叉树
设一个 n 个节点的二叉树 tree 的中序遍历为(1,2,3,…,n),其中数字 1,2,3,…,n 为节点编号。
每个节点都有一个分数(均为正整数),记第 i 个节点的分数为 di,tree 及它的每个子树都有一个加分,任一棵子树 subtree(也包含 tree 本身)的加分计算方法如下:
subtree的左子树的加分 × subtree的右子树的加分 + subtree的根的分数
若某个子树为空,规定其加分为 1。
叶子的加分就是叶节点本身的分数,不考虑它的空子树。
试求一棵符合中序遍历为(1,2,3,…,n)且加分最高的二叉树 tree。
要求输出:
(1)tree的最高加分
(2)tree的前序遍历
输入格式
第 1 行:一个整数 n,为节点个数。
第 2 行:n 个用空格隔开的整数,为每个节点的分数(0<分数<100)。
输出格式
第 1 行:一个整数,为最高加分(结果不会超过int范围)。
第 2 行:n 个用空格隔开的整数,为该树的前序遍历。如果存在多种方案,则输出字典序最小的方案。
数据范围
n<30
输入样例:
5
5 7 1 2 10
输出样例:
145
3 1 2 4 5
思路
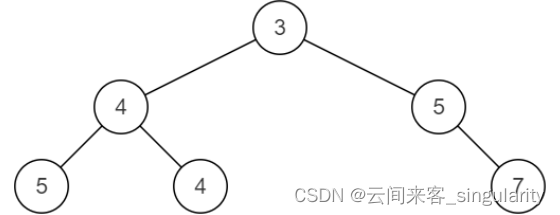
二叉树节点 向下投影,映射成的数组序列就是 中序遍历序列,如下图所示
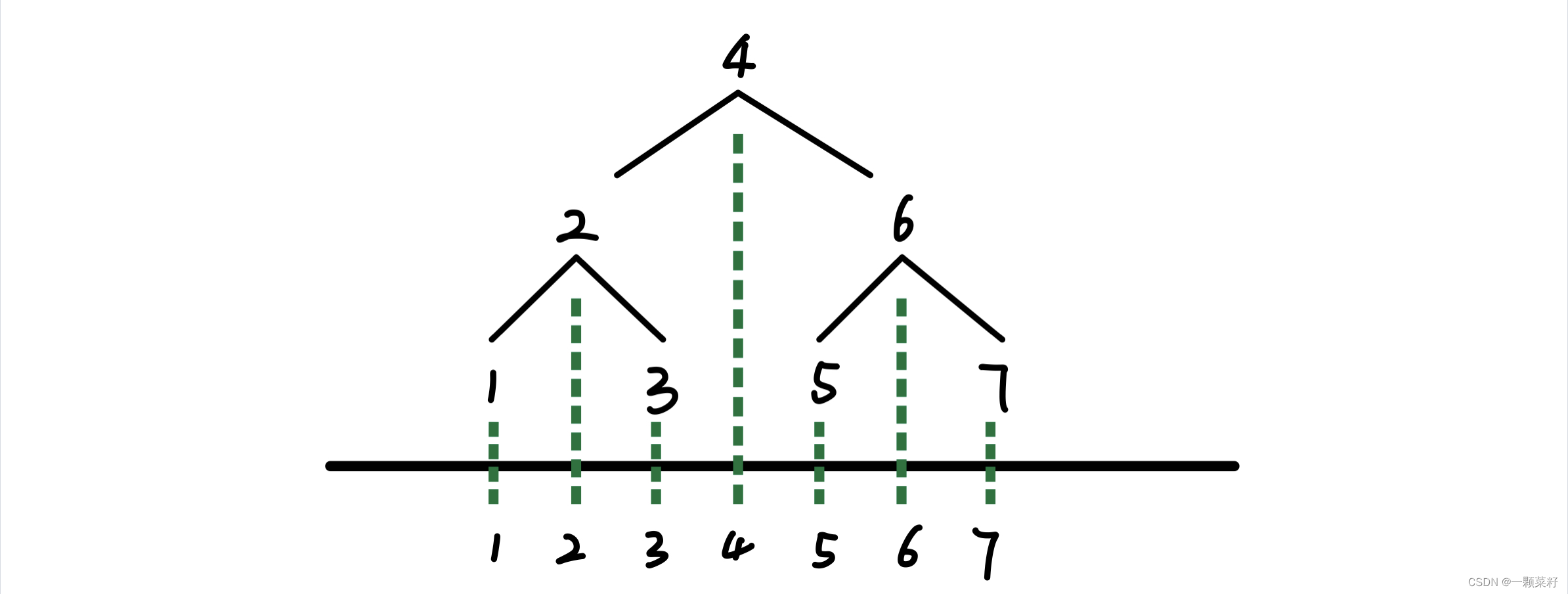
本题只给出了中序遍历的序列,并不知道具体的树是啥样。根节点可以将序列分为左子树一堆和右子树。枚举根节点就能得到并递归处理左子树和右子树根节点就能得到所有情况。
状态表示f[l, r]:中序遍历是[l, r]这一段序列的二叉树集合
属性:分值的最大值
状态计算:假设根节点是k,则f[l, k - 1] * f[k + 1, r] + w[k]为此时序列的分值,枚举每个根节点即可得到分值最小值
方案记录:开一个记录每个区间的最大值所对应的根节点编号的数组
代码
N = 35
w = [0] * N
f = [[0] * N for _ in range(N)]
g = [[0] * N for _ in range(N)]
n = int(input())
w[1 : n + 1] = list(map(int, input().split()))
def dfs(l, r) : #前序遍历
if l > r : return
root = f[l][r]
print(root, end = " ")
dfs(l, root - 1)
dfs(root + 1, r)
for length in range(1, n + 1) :
for l in range(1, n + 1) :
r = l + len - 1
if r > n : break
if length == 1 :
f[l][r] = w[l]
g[l][r] = l
else :
for k in range(l, r + 1) :
left = 1 if k == l else f[l][k - 1] #左边有无节点分情况考虑
right = 1 if k == r else f[k + 1][r] #右边有无节点分情况考虑
score = left * right + w[k]
if f[l][r] < score :
f[l][r] = score #保存最大得分
g[l][r] = k #保存最大得分的根节点
print(f[1][n])
dfs(1, n)
凸多边形的划分
给定一个具有 N 个顶点的凸多边形,将顶点从 1 至 N 标号,每个顶点的权值都是一个正整数。
将这个凸多边形划分成 N−2 个互不相交的三角形,对于每个三角形,其三个顶点的权值相乘都可得到一个权值乘积,试求所有三角形的顶点权值乘积之和至少为多少。
输入格式
第一行包含整数 N,表示顶点数量。
第二行包含 N 个整数,依次为顶点 1 至顶点 N 的权值。
输出格式
输出仅一行,为所有三角形的顶点权值乘积之和的最小值。
数据范围
N≤50,
数据保证所有顶点的权值都小于109
输入样例:
5
121 122 123 245 231
输出样例:
12214884
思路
参考
在 选定 多边形中 两个点 后,找出 三角形 的 第三个点 的方案有 n−2 个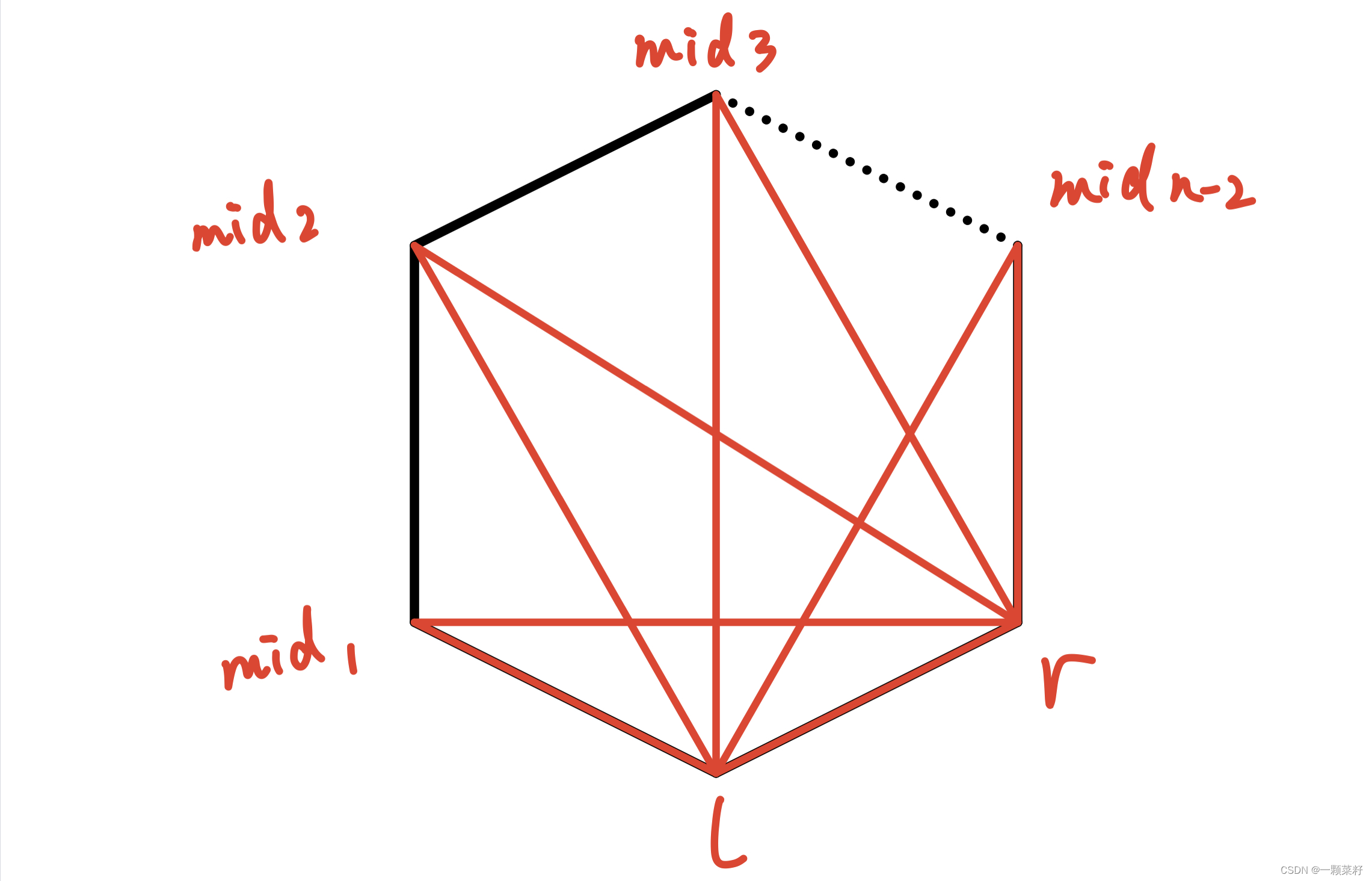
然后还要分别 划分 他的 左右两块区域
因此我们就会想到用 记忆化搜索 或者 区间DP 来进行处理
闫氏DP分析法
状态表示—集合
f
l
,
r
f_{l,r}
fl,r: 当前划分到的多边形的左端点是 ll,右端点是 rr 的方案
状态表示—属性
f
l
,
r
f_{l,r}
fl,r: 方案的费用最小
状态计算—
f
l
,
r
f_{l,r}
fl,r:
f
l
,
r
=
m
i
n
(
f
l
,
k
+
f
k
,
r
+
w
l
×
w
k
×
w
r
)
(
l
<
k
<
r
)
f_{l,r}=min(f_{l,k}+f_{k,r}+w_l×w_k×w_r)(l<k<r)
fl,r=min(fl,k+fk,r+wl×wk×wr)(l<k<r)
区间DP 在状态计算的时候一定要认真划分好边界 和 转移,对于不同题目是不一样的
代码
N = 55
INF = int(1e32) + 7
w = [0] * N
f = [[0] * N for _ in range(N)]
n = int(input())
w[1 : n + 1] = list(map(int, input().split()))
for length in range(3, n + 1) : #枚举区间长度
for l in range(1, n + 1) : #枚举左端点
r = l + length - 1
if r > n : break
f[l][r] = INF
for k in range(l + 1, r) : #枚举分隔点
f[l][r] = min(f[l][r], f[l][k] + f[k][r] + w[l] * w[k] * w[r])
print(f[1][n])
棋盘分割
将一个 8×8 的棋盘进行如下分割:将原棋盘割下一块矩形棋盘并使剩下部分也是矩形,再将剩下的部分继续如此分割,这样割了 (n−1) 次后,连同最后剩下的矩形棋盘共有 n 块矩形棋盘。(每次切割都只能沿着棋盘格子的边进行)
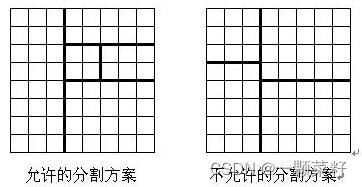
原棋盘上每一格有一个分值,一块矩形棋盘的总分为其所含各格分值之和。
现在需要把棋盘按上述规则分割成 n 块矩形棋盘,并使各矩形棋盘总分的均方差最小。
均方差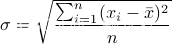 ,其中平均值
,其中平均值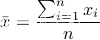 ,xi 为第 i 块矩形棋盘的总分。
,xi 为第 i 块矩形棋盘的总分。
请编程对给出的棋盘及 n,求出均方差的最小值。
输入格式
第 1 行为一个整数 n。
第 2 行至第 9 行每行为 8 个小于 100 的非负整数,表示棋盘上相应格子的分值。每行相邻两数之间用一个空格分隔。
输出格式
输出最小均方差值(四舍五入精确到小数点后三位)。
数据范围
1<n<15
输入样例:
3
1 1 1 1 1 1 1 3
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 0
1 1 1 1 1 1 0 3
输出样例:
1.633
思路
本题有这明显的 分治 引导,即给定一个初始的棋盘,然后我们选择进行分割
分割完后,选择保留一个棋盘,然后对另一个棋盘继续进行分割
直到分割次数达到上限 n − 1 n−1 n−1
这是一个排列数,计算方法很简单,每轮会使用一条分割线,且每条分割线在一个方案里仅能使用一次
不难发现,递归操作会有很多冗余的重复计算,于是我们可以采用 记忆化搜索 进行优化
f
k
,
x
1
,
y
1
,
x
2
,
y
2
f_{k,x_1,y_1,x_2,y_2}
fk,x1,y1,x2,y2 表示对棋盘进行了 k次划分,且 k 次划分后选择的棋盘是 左上角为
(
x
1
,
y
1
)
(x_1,y_1)
(x1,y1),右下角为
(
x
2
,
y
2
)
(x_2,y_2)
(x2,y2)
这一步分析就有点雷同于上面的 DP 了
关于如何枚举矩阵的分割
竖着切:
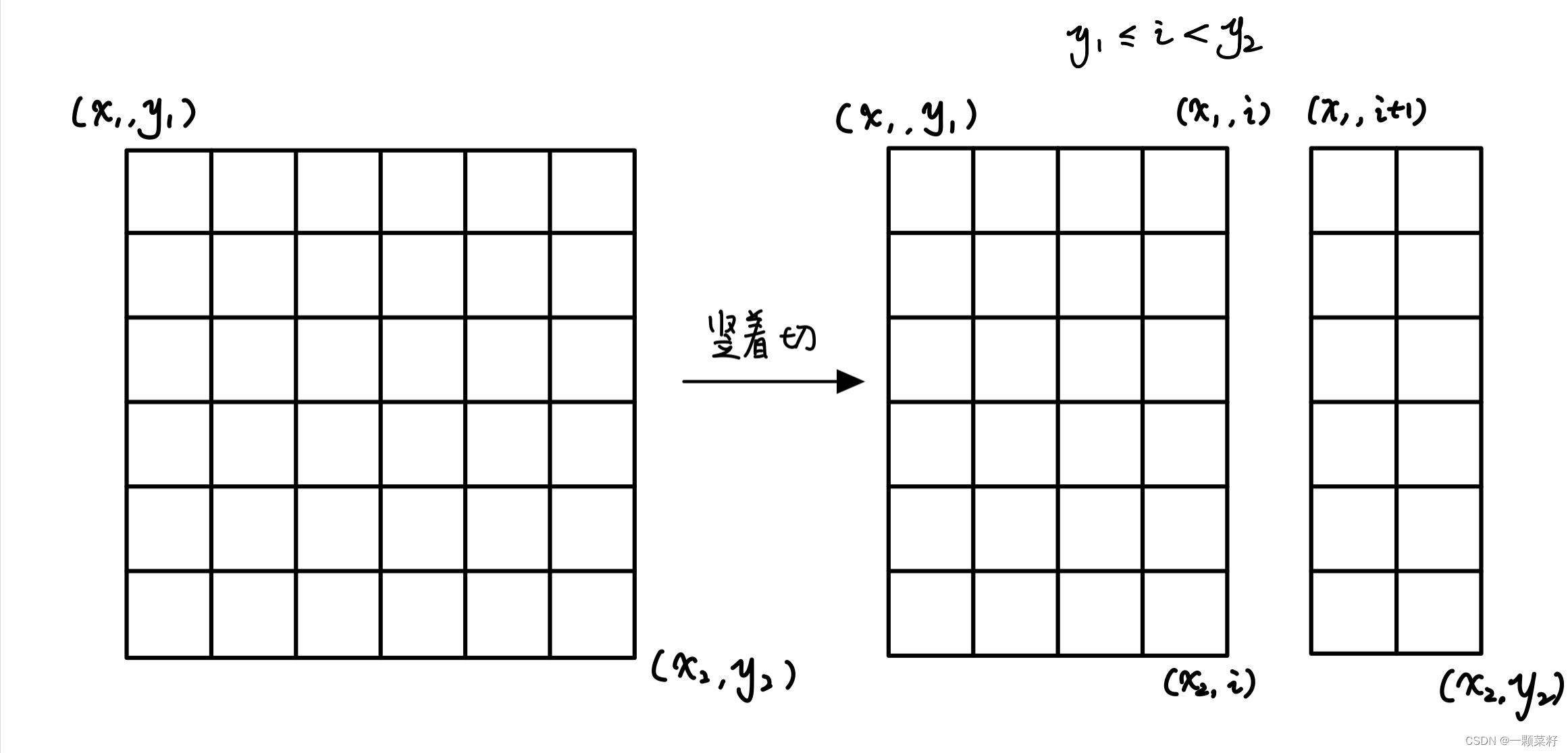
横着切:

作者:一只野生彩色铅笔
链接:https://www.acwing.com/solution/content/62836/
本题使用了前缀和
代码
import math
N, M = 15, 9
INF = 1e9 + 7
s = [[0] * M for _ in range(M)]
f = [[[[[-1] * N for _ in range(M)] for _ in range(M)] for _ in range(M)] for _ in range(M)]
def get_sum(x1, y1, x2, y2) : #求子矩阵矩阵的和
return s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]
def get(x1, y1, x2, y2) : #方差
sum = get_sum(x1, y1, x2, y2) - X
return sum * sum / n
def dp(x1, y1, x2, y2, k) :
if f[x1][y1][x2][y2][k] >= 0 : return f[x1][y1][x2][y2][k]
if k == 1 :
f[x1][y1][x2][y2][k] = get(x1, y1, x2, y2)
return f[x1][y1][x2][y2][k]
f[x1][y1][x2][y2][k] = INF
for i in range(x1, x2) : #纵向
f[x1][y1][x2][y2][k] = min(f[x1][y1][x2][y2][k], get(x1, y1, i, y2) + dp(i + 1, y1, x2, y2, k - 1)) #去掉左边
f[x1][y1][x2][y2][k] = min(f[x1][y1][x2][y2][k], get(i + 1, y1, x2, y2) + dp(x1, y1, i, y2, k - 1)) #去掉右边
for i in range(y1, y2) : #横向
f[x1][y1][x2][y2][k] = min(f[x1][y1][x2][y2][k],get(x1, y1, x2, i) + dp(x1, i + 1, x2, y2, k - 1)) #去掉上面
f[x1][y1][x2][y2][k] = min(f[x1][y1][x2][y2][k],get(x1, i + 1, x2, y2) + dp(x1, y1, x2, i, k - 1)) # 去掉下面
return f[x1][y1][x2][y2][k]
n = int(input())
m = 8
for i in range(1, m + 1) :
tmp = list(map(int, input().split()))
for j in range(1, m + 1) :
s[i][j] = tmp[j - 1]
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1]
X = s[m][m] / n
print(f"{math.sqrt(dp(1, 1, m, m, n)) :.3f}")
总结
区间dp主要运用了分治的思想,将大问题差分成一个个小问题求解,最终将得到全局最优解。