多租户动态多数据源系列
1、基于springboot+jpa 实现多租户动态切换多数据源 - 数据隔离方案选择分库还是分表
2、基于springboot+jpa 实现多租户动态切换多数据源 - 基于dynamic-datasource实现多租户动态切换数据源
3、基于springboot+jpa 实现多租户动态切换多数据源 - 使用Flyway实现多数据源数据库脚本管理和迭代更新
目录
- 多租户动态多数据源系列
- 多租户理解
- dynamic-datasource介绍
- 多租户多数据源实现
- pom配置
- yaml配置
- 项目文件结构
- 数据源相关操作
- 查看数据源
- 增改数据源
- 增加数据源
- 改数据源
- dataSourceProperty必要的配置参数
- 删除数据源
- 切换数据源
- 注解方式@DS
- 手动切换数据源
- 切换数据源不生效
- 多数据源事务
- 解决方法:本地事务
- 启动项目测试验证
多租户理解
多租户定义:多租户技术或称多重租赁技术,简称SaaS,是一种软件架构技术,是实现如何在多用户环境下(此处的多用户一般是面向企业用户)共用相同的系统或程序组件,并且可确保各用户间数据的隔离性。
简单讲:在一台服务器上运行单个应用实例,它为多个租户(客户)提供服务。
从定义中我们可以理解:多租户是一种架构,目的是为了让多用户环境下使用同一套程序,且保证用户间数据隔离。租户的数据既有隔离又有共享,从而解决数据存储的问题
多租户的三种实现方案:
1.独立数据库:即一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本也高。(正如我在分库分表文章中分析,所选就是独立数据库)
2.共享数据库,独立 Schema:多个或所有租户共享Database,但是每个租户一个Schema(也可叫做一个user)
3.共享数据库,共享 Schema,共享数据表:这个其实就类似权限了,所有租户用一个表,通过一个id字段进行区分
dynamic-datasource介绍
原本计划参考一些网上数据源切换的实现,自己造一个🛞,但是实际需求要实现的可能更复杂,自己造轮子费时费力,于是在冲浪中找到了便捷的现有🛞:dynamic-datasource-spring-boot-starter
文档: dynamic datasource
详细付费文档(好像就十几块钱):dynamic datasource
简介
dynamic-datasource-spring-boot-starter 是一个基于springboot的快速集成多数据源的启动器。
其支持 Jdk 1.7+, SpringBoot 1.4.x 1.5.x 2.x.x。
特性
- 支持 数据源分组 ,适用于多种场景 纯粹多库 读写分离 一主多从 混合模式。
- 支持数据库敏感配置信息 加密 ENC()。
- 支持每个数据库独立初始化表结构schema和数据库database。
- 支持无数据源启动,支持懒加载数据源(需要的时候再创建连接)。
- 支持 自定义注解 ,需继承DS(3.2.0+)。
- 提供并简化对Druid,HikariCp,BeeCp,Dbcp2的快速集成。
- 提供对Mybatis-Plus,Quartz,ShardingJdbc,P6sy,Jndi等组件的集成方案。
- 提供 自定义数据源来源 方案(如全从数据库加载)。
- 提供项目启动后 动态增加移除数据源 方案。
- 提供Mybatis环境下的 纯读写分离 方案。
- 提供使用 spel动态参数 解析数据源方案。内置spel,session,header,支持自定义。
- 支持 多层数据源嵌套切换 。(ServiceA >>> ServiceB >>> ServiceC)。
- 提供 基于seata的分布式事务方案。
- 提供 本地多数据源事务方案。 附:不能和原生spring事务混用。
使用体验: 支持较为功能功能,基于此实现了我在项目中的动态增、删、修改、切换数据源的需求,也支持解决事务问题
多租户多数据源实现
项目架构说明: 项目现有架构是springboot+jpa+maven
pom配置
<!-- https://www.kancloud.cn/tracy5546/dynamic-datasource/2394605 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
yaml配置
通过yaml配置主数据源,由于我要实现多租户的动态增删改数据源,这里就只配置了一个主数据源,后续通过代码来自由的增删数据源。
当然,如果你是确定的几个数据源,可以直接都在yaml配置完成
#mysql environment
spring:
datasource:
dynamic:
hikari:
connection-timeout: 5000
idle-timeout: 30000 # 经过idle-timeout时间如果连接还处于空闲状态, 该连接会被回收
min-idle: 5 # 池中维护的最小空闲连接数, 默认为 10 个
max-pool-size: 16 # 池中最大连接数, 包括闲置和使用中的连接, 默认为 10 个
max-lifetime: 60000 # 如果一个连接超过了时长,且没有被使用, 连接会被回收
is-auto-commit: true
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: true #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master: # 数据源名称
url:
username:
password:
driver-class-name: com.mysql.cj.jdbc.Driver
init:
schema: db/primary_db_table.sql # 配置则生效,自动初始化表结构
# 如下,如果你是确定的几个数据源,可以直接都在yaml配置写死即可
# slave_1:
# url:
# username:
# password:
# driver-class-name: com.mysql.cj.jdbc.Driver
项目文件结构
数据源相关操作
针对数据源的增删改查以及切换操作,由于方式不同是有区别的,可以只通过yaml配置,也可以代码中动态操作,更为灵活的可以yaml配置结合代码动态组合
查看数据源
//这是官方示例,直接返回PoolName(就是yaml配置中的数据源名称)的Set
@GetMapping
@ApiOperation("获取当前所有数据源")
public Set<String> now() {
DynamicRoutingDataSource ds = (DynamicRoutingDataSource) dataSource;
return ds.getDataSources().keySet();
}
//如果只是想知道具体的数据源,输出查看PoolName即可,如下
public void getDataSources() {
DynamicRoutingDataSource ds = (DynamicRoutingDataSource) dataSource;
for (String poolName : ds.getDataSources().keySet()) {
log.info("poolName:" + poolName);
}
}
增改数据源
增加数据源
如果是yaml配置方式写死的数据源,那么直接在yaml配置中添加即可
我是使用了更灵活的操作,通过yaml配置主数据源,在程序中动态添加其他数据源如下
这样就可以通过用户页面操作来动态添加数据源
//通用数据源会根据maven中配置的连接池根据顺序依次选择。
//默认的顺序为druid>hikaricp>beecp>dbcp>spring basic
@PostMapping("/add")
@ApiOperation("通用添加数据源(推荐)")
public Set<String> add(@Validated @RequestBody DataSourceDTO dto) {
DataSourceProperty dataSourceProperty = new DataSourceProperty();
// 这里主要是将dto的属性赋值给dataSourceProperty
//所以dataSourceProperty中必要的参数,dto都要提供
BeanUtils.copyProperties(dto, dataSourceProperty);
DynamicRoutingDataSource ds = (DynamicRoutingDataSource) dataSource;
DataSource dataSource = dataSourceCreator.createDataSource(dataSourceProperty);
// PoolName就是我们yaml配置中说的数据源名称
ds.addDataSource(dto.getPoolName(), dataSource);
return ds.getDataSources().keySet();
}
改数据源
DynamicRoutingDataSource中记录数据源是以map形式,如下

dataSourceMap的k就是poolName,所以如果想要更改poolName对应的数据源,直接覆盖同k的value即可。或者更为保险的做法可以先删除poolName对应的数据源,后续再次添加同名poolName数据源
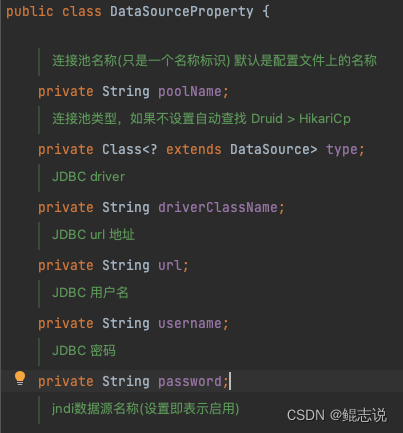
dataSourceProperty必要的配置参数
删除数据源
如果是yaml配置方式写死的数据源,那么直接在yaml配置中删除即可
通过程序动态删除数据源如下
@DeleteMapping
@ApiOperation("删除数据源")
public String remove(String poolName) {
DynamicRoutingDataSource ds = (DynamicRoutingDataSource) dataSource;
ds.removeDataSource(poolName);
return "删除成功";
}
切换数据源
前面的增删改查数据源操作还是比较简单,也没有太多逻辑在,但是切换数据源就要谨慎操作了,毕竟数据落入错误的库,后果是可大可小的
注解方式@DS
dynamic-datasource中DS作为切换数据源核心注解,一般明确哪个或哪组数据源的情况下是完全符合的(⚠️:如果是分组数据源会随机调用分组内的数据源)
但动态切换数据源方式不建议采用此种,可直接跳过看下面
DS放在哪里合适?
首先开发者要了解的基础知识是,DS注解是基于AOP的原理实现的,aop的常见失效场景应清楚。 比如内部调用失效,shiro代理失效。 具体见切换数据源失败
- 通常建议DS放在serviceImpl的方法上,如事务注解一样。
- 注解在Controller的方法上或类上
并不是不可以,并不建议的原因主要是controller主要作用是参数的检验等一些基础逻辑的处理,这部分操作常常并不涉及数据库
- 注解在service的实现类的方法或类上
这是建议的方式,service主要是对业务的处理, 在复杂的场景涉及连续切换不同的数据库。 如果你的方法有通用性,其他service也会调用你的方法。 这样别人就不用重复处理切换数据源
- 注解在mapper上。
通常如果你某个Mapper对应的表只在确定的一个库,也是可以的。 但是建议只注解在Mapper的类上。
- 其他使用方式
继承抽象类上的DS - 继承接口上的DS
3.4.1开始支持, 但是需要注意的是,一个类能实现多个接口,如果多个接口都有DS会如何?
。。。。。。不知道,别这么干。。。。
- 问:比如我有一个抽象Service,我想实现继承我这个抽象Service下的子Service的所有方法除非重新指定,都用我抽象Service上注解的数据源。 是否支持?
- 答:支持。
手动切换数据源
动态数据源切换,尤其是像我这种多租户场景,同一个方法可能要根据实际情况切换对应的数据源,这时就不能使用上面DS注解方式写死数据源或者数据源组,只能手动切换
手动切换代码如下
public static void switchDataSource(String poolName) {
//需要注意的是手动切换的数据源,最好自己在合适的位置
//调用DynamicDataSourceContextHolder.clear()清空当前线程的数据源信息。
DynamicDataSourceContextHolder.clear();
//切换到对应poolName的数据源
DynamicDataSourceContextHolder.push(poolName);
}
这样就可以根据不同租户的操作来自由切换数据源,同一个方法来回切换数据源也不必担心,这是线程级别的,不会相互影响
如果需要通过用户每次请求,拦截token或url来切换数据源,可以参考下面写一个拦截器,注册进spring里即可。
public class DynamicDatasourceClearInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
DynamicDataSourceContextHolder.clear();
}
}
切换数据源不生效
开启了spring的事务
这里只举例我实际开发中也是遇到的问题,当然这个也是最普遍的情况
原因: spring开启事务后会维护一个ConnectionHolder,保证在整个事务下,都是用同一个数据库连接。
请检查整个调用链路涉及的类的方法和类本身还有继承的抽象类上是否有@Transactional注解。
如强烈需要事务保证多个库同时执行成功或者失败,请查看下面多数据源事务的解决办法。
有其他不生效的情况可以私信我
多数据源事务
@Transaction开启了事务,为什么多数据源事务不生效? 简单来说:嵌套数据源的service中,如果操作了多个数据源,不能在最外层加上@Transaction开启事务,否则切换数据源不生效,因为这属于分布式事务了,需要用seata方案解决,如果是单个数据源(不需要切换数据源)可以用@Transaction开启事务,保证每个数据源自己的完整性
加事务不生效的原因:
dynamic-datasource切换数据源的原理就是实现了DataSource接口,实现了getConnection方法,只要在service中开启事务,service中对其他数据源操作只会使用开启事务的数据源,因为开启事务数据源会被缓存下来,可以在DataSourceTransactionManager的doBegin方法中看见那个txObject,如果在一个事务内,就会复用Connection,所以切换不了数据源
解决方法:本地事务
通过本地事务实现很简单,就是循环提交,发生错误,循环回滚。 我们默认的前提是数据库本身不会异常,比如宕机。
如数据在回滚的过程突然宕机,本地事务就会有问题。如果你需要完整分布式方案请使用seata方案。
使用方法
在最外层的方法添加 @DSTransactional,底下调用的各个类就正常切换数据源即可。
简单举例如下:
@DeleteMapping
//只要@DSTransactional注解下任一环节发生异常,则全局多数据源事务回滚。
@DSTransactional()
@ApiOperation("删除数据源")
public String remove(String poolName) {
DynamicRoutingDataSource ds = (DynamicRoutingDataSource) dataSource;
ds.removeDataSource(poolName);
return "删除成功";
}
但一定要注意Spring事务@Transational和本地事务@DSTransactional,不能混用
启动项目测试验证
可以看到除了master数据源,我这里还有两个数据源,都是之前操作的时候加入的数据源

到这里,多数据源的动态切换应该就可以实现了,其他业务相关操作,可以自行补充了