目录
- 一、概念
- 1、特征
- 2、关系型数据库和非关系型数据库的区别
- 3、键的结构
- 4、Redis的Java客户端
- 5、缓存更新策略
- 5.1、概念
- 5.2、代码
- 6、缓存穿透
- 6.1、含义
- 6.2、解决办法
- 6.3、缓存空值代码举例
- 6.4、布隆过滤器代码举例
- 7、缓存击穿
- 7.1、概念
- 7.2、解决办法
- 7.3、互斥锁代码举例
- 7.4、逻辑过期代码举例
- 8、缓存雪崩
- 8.1、含义
- 8.2、解决办法
- 9、Lua脚本
- 9.1、Lua教程
- 9.2、Lua介绍
- 9.2.1、概念
- 9.2.2、Redis为Lua语言内置的lua函数
- 9.2.3、在Redis-cli中执行Lua脚本函数
- 9.3、代码
- 9.3.1、前置准备:application.yaml和依赖
- 9.3.2、unlock.lua(放在resources下的lua脚本,等待被调用)
- 9.3.3、ILock接口
- 9.3.4、SimpleRedisLock实现类
- 9.4、更复杂的lua脚本代码
- 9.4.1、前置准备:application.yaml和依赖
- 9.4.2、seckill.lua(放在resources下的lua脚本,等待被调用)
- 9.4.3、IVoucherOrderService 接口
- 9.4.4、VoucherOrderServiceImpl 实现类
- 10、Redission
- 10.1、概念
- 10.2、官方地址
- 10.3、为什么不使用Redis的setnx命令来实现分布式锁?
- 10.3.1、缺点
- 10.3.1、使用Redis的setnx命令来实现分布式锁的代码
- 10.3.1.1、前置准备:application.yaml和依赖
- 10.3.1.2、unlock.lua(放在resources下的lua脚本,等待被调用)
- 10.3.1.3、ILock接口
- 10.3.1.4、SimpleRedisLock实现类
- 10.4、Redisson分布式锁原理
- 10.4.1、解决不可重入问题
- 10.4.1.1、方案
- 10.4.1.2、画图介绍
- 10.4.1.3、代码分析
- 10.4.2、解决不可重试问题
- 10.4.2.1、方案
- 10.4.2.2、代码分析
- 10.4.3、解决超时释放问题
- 10.4.3.1、方案
- 10.4.3.2、代码解读
- 10.4.4、解决主从一致性问题
- 10.4.4.1、方案
- 10.4.4.2、代码
- 10.5、Redisson用途
- 10.5.1、用途概述
- 10.5.2、waitTime和leaseTime参数区别
- 10.5.3、lock()和tryLock()方法区别
- 11、RDB和AOF
- 11.1、RDB
- 11.1.1、概念
- 11.1.2、RDB触发机制(配置文件+手动输入命令操作)
- 11.1.2.1、Redis内部触发机制:配置文件
- 11.1.2.2、Redis命令行手动触发方式:手动操作(不建议使用)
- 11.1.3、RDB备份原理
- 11.1.4、总结
- 11.2、AOF
- 11.2.1、概念
- 11.2.2、如何修改Redis配置文件
- 11.2.2.1、普通配置
- 11.2.2.2、AOF文件瘦身配置
- 11.3、RDB和AOF对比
- 12、主从集群、哨兵集群、分片集群相关原理
- 12.1、主从集群
- 12.1.1、数据同步原理
- 12.1.2、从节点第一次加入主节点进行全量同步流程
- 12.1.3、从节点重启之后尝试再次加入主节点进行数据同步
- 12.1.4、总结
- 12.2、哨兵集群
- 12.2.1、哨兵作用
- 12.2.2、监控服务状态
- 12.2.3、选举新的master
- 12.2.4、实现故障转移
- 12.2.5、总结
- 12.2.6、RedisTemplate的哨兵模式
- 12.3、分片集群
- 12.3.1、分片集群结构
- 12.3.2、散列插槽
- 12.3.3、故障转移
- 13、小知识点
- 13.1、RedisTemplate的默认JDK序列化方式、RedisTemplate的自定义Jackson序列化方式、StringRedisTemplate字符串序列化方式,到底用哪个?
- 二、操作命令
- 1、Redis命令官网
- 2、数据结构列表
- 3、Redis通用命令使用介绍
- 4、String使用介绍(使用redis-cli命令行操作)
- 4.1、简单介绍
- 4.2、set ……、set …… ex ……(简写:setex)、set …… px ……、set …… nx(简写:setnx)、set …… xx
- 4.3、mset
- 4.4、getset
- 4.5、get
- 4.6、mget
- 4.7、del(所有类型可用)
- 4.8、incr、incrby、decr、decrby(仅限Integer类型(String类型可以转换成Integer类型))
- 4.9、incrbyfloat(仅限浮点类型(String类型可以转换成浮点类型))
- 4.10、exists(所有类型可用)
- 4.11、type(所有类型可用)
- 4.12、expire、pexpire(所有类型可用)
- 4.13、persist(所有类型可用)
- 4.14、ttl、pttl(所有类型可用)
- 5、List使用介绍(使用redis-cli命令行操作)
- 5.1、简单介绍
- 5.2、lpush(l:left)、rpush
- 5.3、lrange(l:list)
- 5.4、rpop、lpop(l:left)
- 5.5、ltrim(说明:1、l:list;2、获取限定数量的最新数据)
- 5.6、llen(l:list)
- 5.7、brpop(说明:和lpush结合用作队列)、blpop(说明:1、l:left;2、不常用)
- 5.8、小拓展
- 5.9、思考
- 6、Hash使用介绍(使用redis-cli命令行操作)
- 6.1、简单介绍
- 6.2、hset、hmset
- 6.3、hget、hmget、hgetall
- 6.4、hincrby
- 6.5、hkeys
- 6.6、hvals
- 6.7、hsetnx
- 7、Set使用介绍(使用redis-cli命令行操作)
- 7.1、简单介绍
- 7.2、sadd
- 7.3、spop
- 7.4、smembers
- 7.5、sismember
- 7.6、scard
- 7.7、sunionstore
- 7.8、sinter
- 7.9、sdiff
- 7.10、sunion
- 7.11、srandmember
- 7.12、srem
- 8、Sorted Set(使用介绍(使用redis-cli命令行操作))
- 8.1、简单介绍
- 8.2、zadd
- 8.3、zrange、zrevrange
- 8.4、zrangebyscore、zrevrangebyscore
- 8.5、zremrangebyscore
- 8.6、zrank
- 8.7、zrem
- 8.8、zscore
- 8.9、zcard
- 8.10、zcount
- 8.11、zincrby
- 8.12、zdiff
- 8.13、zinter
- 8.14、zunion
- 三、环境搭建
- 1、windows
- (1)单机版
- 1)下载
- 2)安装
- 3)启动
- 2、linux
- (1)单机版
- 1)下载
- 2)安装gcc编译器
- 3)安装Redis
- 4)修改Redis配置文件
- 5)启动Redis
- 6)关闭Redis
- 7)拓展:启动、停止方式1
- 8)拓展:停止方式2
- 9)拓展:Redis自带客户端使用方式
- (2)哨兵版
- 1)下载
- 2)安装gcc编译器
- 3)安装Redis
- 4)搭建Redis主从副本集群
- 5)搭建Redis哨兵集群
- (3)分片版
- 1)下载
- 2)安装gcc编译器
- 3)安装Redis
- 4)准备Redis节点
- 5)创建Redis集群
- 3、docker
- (1)单机版
- 4、k8s
- (1)单机版
- 5、Redis连接工具
- (1)RedisDesktopManager
- 四、代码
- 五、文档
一、概念
1、特征
Redis诞生于2009年全称是Remote Dictionary Server,远程词典服务器,是一个基于内存的键值型NoSQL数据,特征如下:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
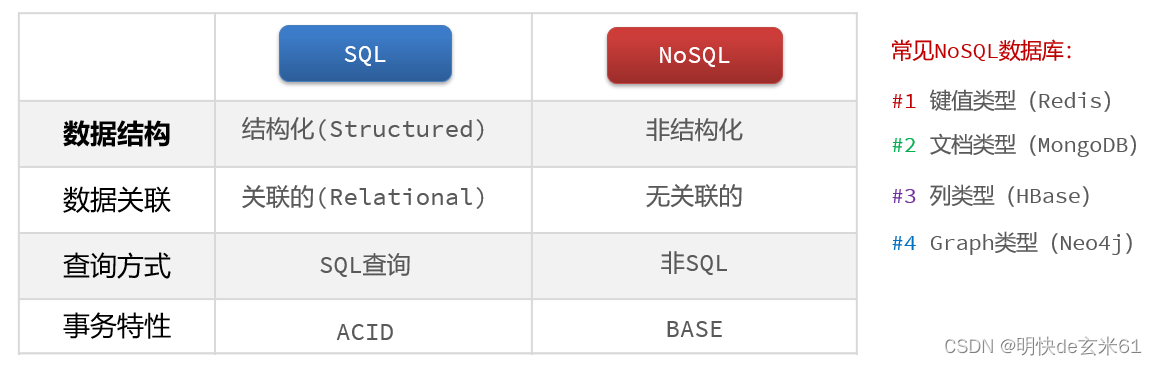
2、关系型数据库和非关系型数据库的区别
3、键的结构
Redis的key允许由多个单词形成层级结构,多个单词之间用:隔开,格式如下:
项目名:业务名:类型:id
这个格式并非固定,也可以根据自己的需求来删除或添加词条。
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
user相关的key:heima:user:1
product相关的key:heima:product:1

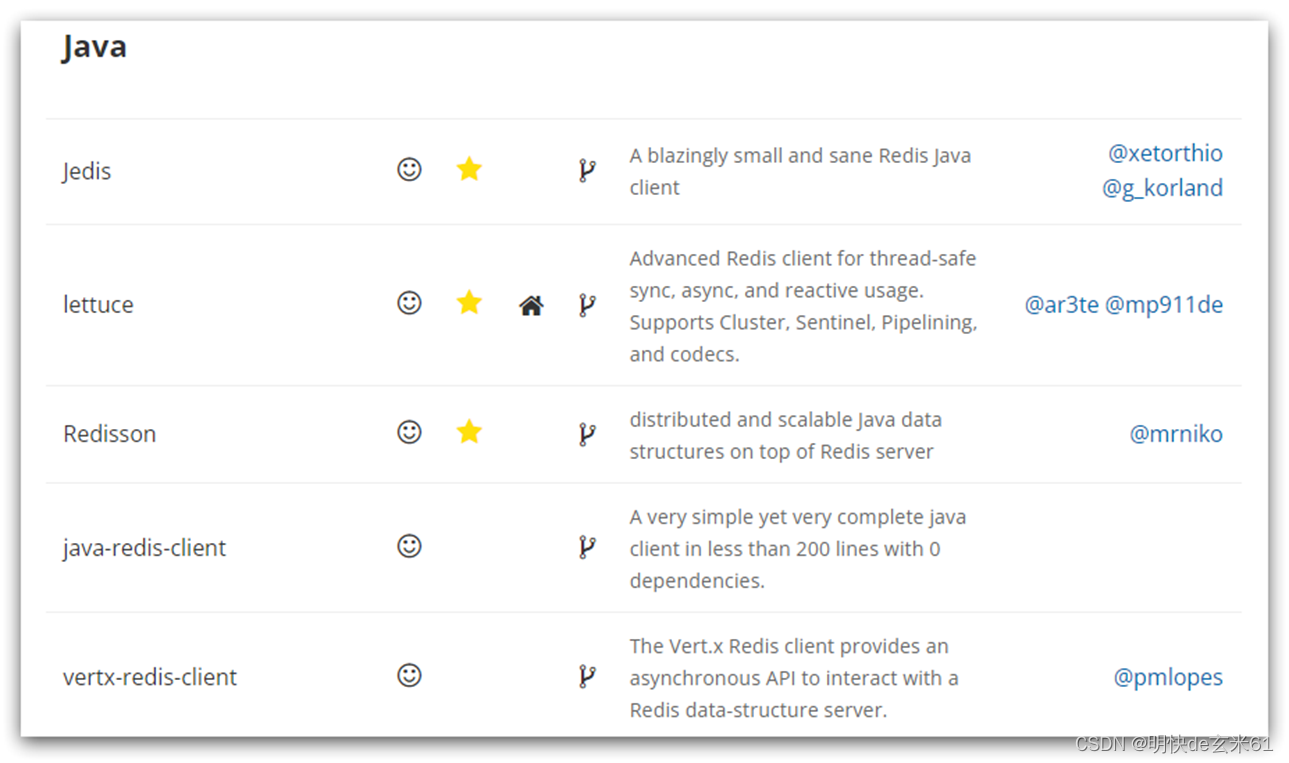
4、Redis的Java客户端
Spring data redis底层默认使用lettuce,但是lettuce存在并发问题,所以一般将底层替换成Jedis。
5、缓存更新策略
5.1、概念
说明: 缓存更新策略将会影响代码编写过程中的逻辑。
首先用一张图说明缓存作用:
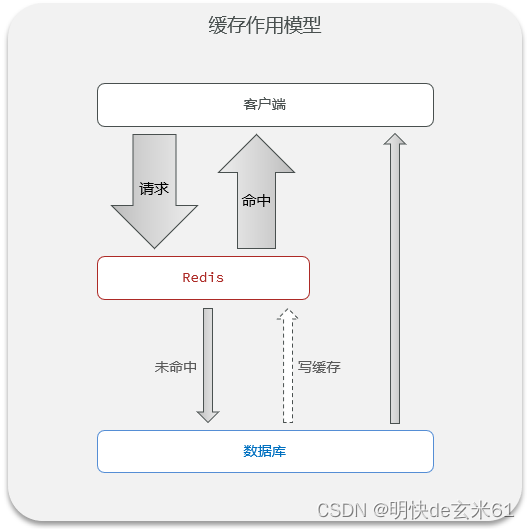
可以很清晰的看到Redis缓存是做前锋的,避免对关系型数据库造成影响
然后罗列一下几种缓存更新策略,如下:
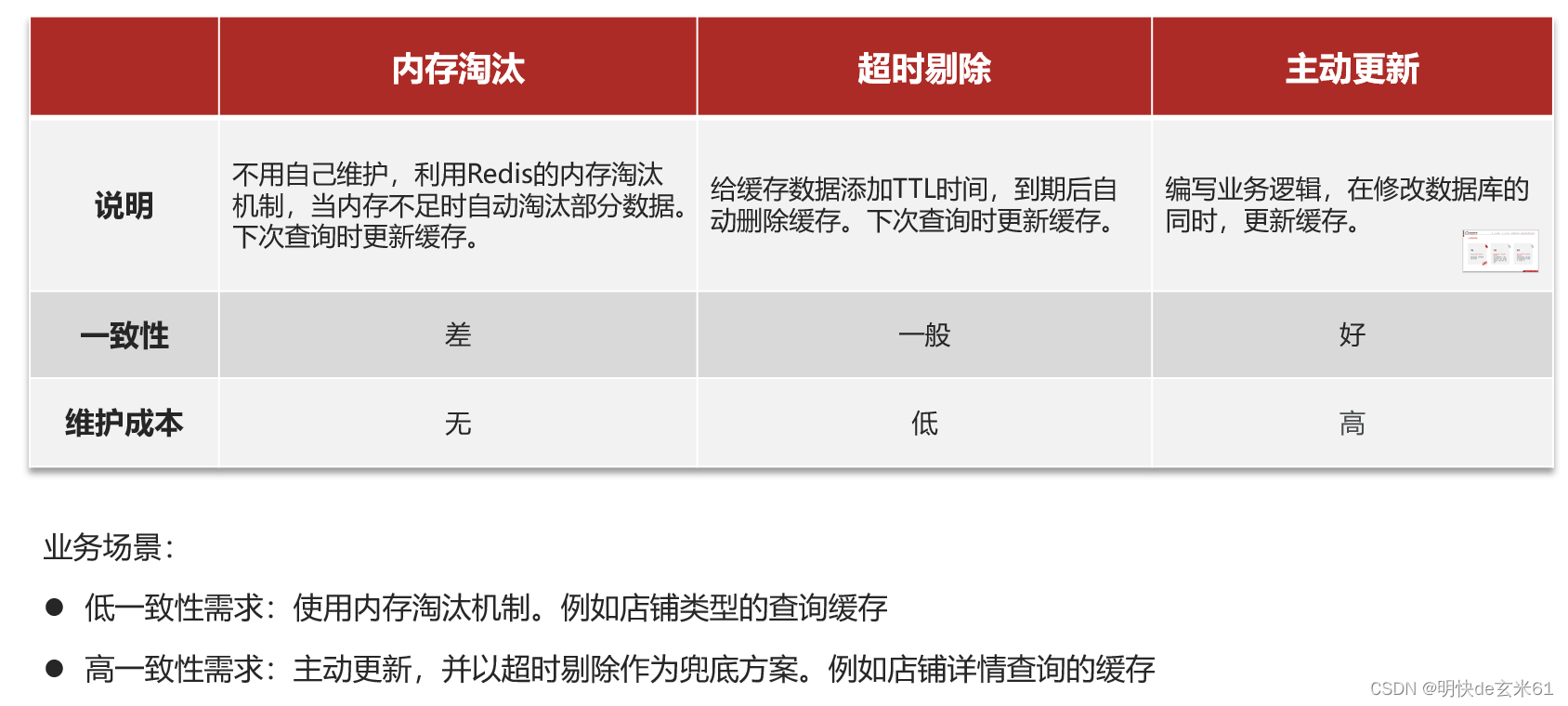
通过比对实现难度和最终效果,我们采用主动更新策略
然后罗列一下几种主动更新策略,如下:

通过比对实现难度和最终效果,我们采用01
但是01的实现方式也有两种,可以分为删除缓存策略还是更新缓存策略,其中删除缓存等待用户操作的时候才会把最新数据放到缓存中,而更新缓存是在用户往数据库新增或者更新数据的时候就把最新数据放到缓存中
既然提到这2种主动缓存更新策略,那就得说一下缓存数据有效性,以及查询数据时可能出现的缓存穿透、缓存击穿、缓存雪崩问题的解决方案;
- 对于
删除缓存策略,可以在删除缓存后通过用户主动获取数据(添加最新缓存数据)来保证数据有效性,当查询缓存时,可以通过缓存空值方式来解决缓存穿透问题,可以通过分布式锁方式解决缓存击穿问题,可以通过设置不同缓存过期时间方式解决缓存雪崩问题 - 对于
更新缓存策略,有两种实现方案- 方案1(完全符合):在添加 / 更新数据库的同时更新Redis缓存,可以
保证缓存数据有效性,由于缓存数据不会过期,并且我们查询数据的时候不会查询数据库,那其实不会产生缓存穿透、缓存击穿、缓存雪崩问题,但是这会造成很多无效写操作,并且还会占据很多缓存空间 - 方案2(不太符合):在添加数据到数据库的时候添加Redis缓存,并且为缓存数据添加逻辑过期时间,但是在更新数据库数据的时候不更新Redis缓存,而是等待过期逻辑过期时间到期才更新Redis缓存数据,
无法解决数据有效性问题(更新数据库不更新Redis缓存,不给Redis造成太大压力),当查询缓存时,如果从Redis查询不到值的时候直接返回null,所以不会产生缓存穿透问题,可以通过缓存逻辑过期时间方式来解决缓存击穿问题,不会产生缓存雪崩问题 - 方案3(不太符合):在添加数据到数据库的时候添加Redis缓存,并且为缓存数据添加真实过期时间,并且为
布隆过滤器添加数据标识,但是更新的时候不会在更新Redis缓存,无法解决数据有效性问题,当查询缓存时,可以通过布隆过滤器解决缓存穿透问题,可以通过分布式锁方式解决缓存击穿问题,可以通过设置不同缓存过期时间方式解决缓存雪崩问题
- 方案1(完全符合):在添加 / 更新数据库的同时更新Redis缓存,可以
基于实现难度、资源消耗、数据时效性考虑,我们采用删除缓存策略,下面进行详细介绍在读写操作时的作用:
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,也不一定要设置超时时间,看具体情况吧!
- 写操作:
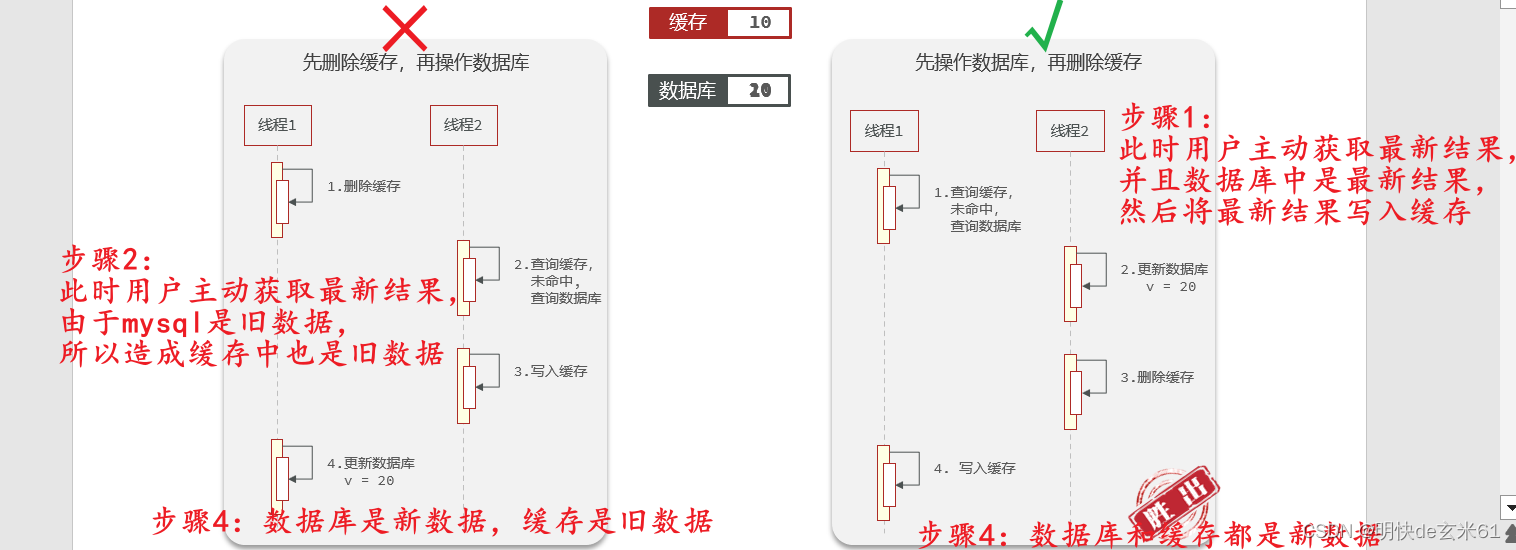
- 先写数据库,然后再删除缓存(原因:如果顺序反过来,将有可能造成缓存中有旧数据)
- 要确保数据库与缓存操作的原子性
- 单体系统(在同一个程序中操作数据库和Redis):将缓存与数据库操作放在一个事务
- 分布式系统(在不同程序中操作数据库和Redis):利用分布式事务方案
5.2、代码
概述: 先写数据库,然后再删除缓存,确保数据库与缓存操作的原子性,这就是代码。
解释: 如果用户修改数据库数据的操作会影响Redis中缓存值的准确性,那就需要在更新数据库值之后就删除Redis缓存值,当用户需要获取结果时会自动更新Redis缓存值,这样也能减轻缓存资源占用
代码:
// 更新店铺信息
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
6、缓存穿透
6.1、含义
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
6.2、解决办法
- 缓存空对象(
最常使用,简单好用,但是一定要设置缓存超时时间,并且要比普通值的缓存时间短) - 布隆过滤(
不常使用,原因是在查询缓存之前需要提前将缓存放入Redis,并且在布隆过滤器添加值(将字符串指定字节位设置为true),这样未来在查询的时候布隆过滤器才能起到作用,我感觉布隆过滤器的用途是:提前将数据放入Redis,并且设置过期时间,然后在查询缓存的时候查不到,说明已经过期了,那就从数据库取值即可)
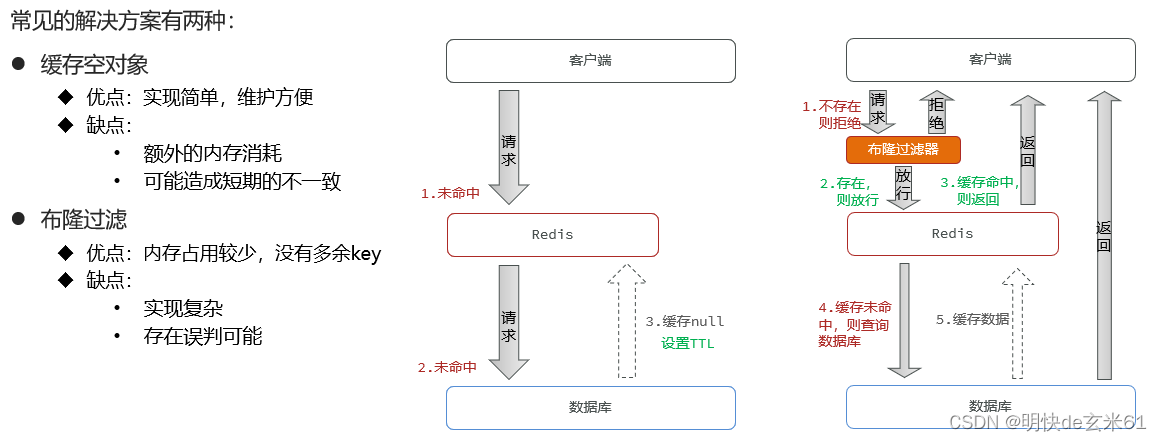
举一个缓存空值的例子:
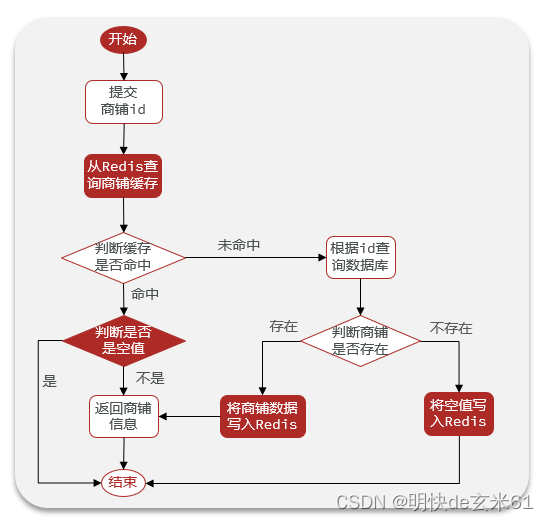
6.3、缓存空值代码举例
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
代码:
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import static com.hmdp.utils.RedisConstants.CACHE_NULL_TTL;
@Slf4j
@Component
public class CacheClient {
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {
// 设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
// 写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
// 通过缓存空值方式来解决缓存穿透
public <R,ID> R queryWithPassThrough(
String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(json)) {
// 3.存在,直接返回
return JSONUtil.toBean(json, type);
}
// 判断命中的是否是空值,不等于空那就是空字符串,也就是我们缓存的空值,所以直接返回即可
if (json != null) {
// 返回一个错误信息
return null;
}
// 4.不存在,根据id查询数据库
R r = dbFallback.apply(id);
// 5.不存在,返回错误
if (r == null) {
// 将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 返回错误信息
return null;
}
// 6.存在,写入redis
this.set(key, r, time, unit);
return r;
}
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
}
6.4、布隆过滤器代码举例
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--增加布隆过滤器-->
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
Redis工具类代码:
import com.google.common.base.Preconditions;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class RedisUtil {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
log.info("key : " + key + " " + "value : " + i);
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
log.info("key : " + key + " " + "value : " + i);
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
布隆过滤器工具类代码:
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
// 设定最小期望长度
p = Double.MIN_VALUE;
}
int sizeOfBitArray = (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
return sizeOfBitArray;
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
int countOfHash = Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
return countOfHash;
}
}
7、缓存击穿
7.1、概念
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
7.2、解决办法
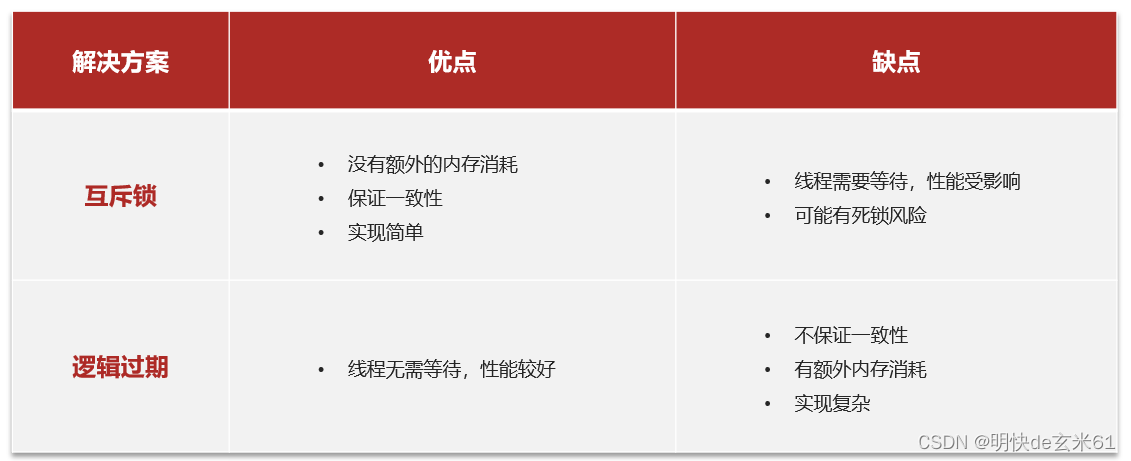
- 互斥锁 (
最常使用,简单好用,但是一定要设置锁超时时间) - 逻辑过期(
很少使用,也能考虑,首先很难保证数据准确性,毕竟可能返回旧数据,另外在数据库中数据新增或者更新的时候都需要更新缓存数据,这一点比较麻烦)
时序图:
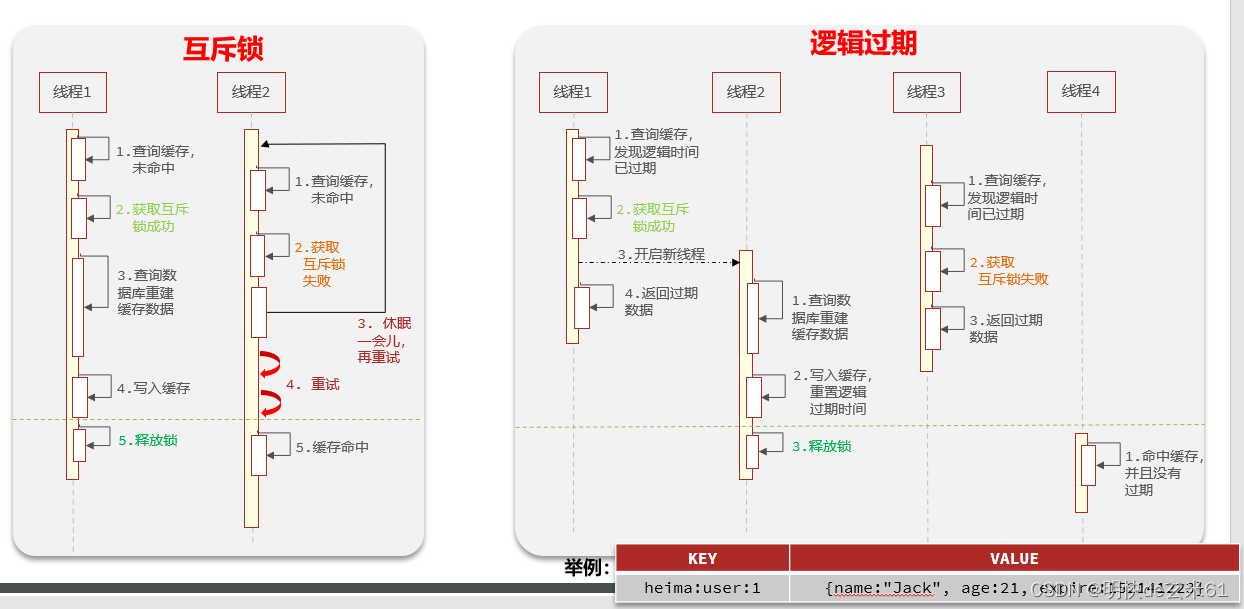
优缺点:
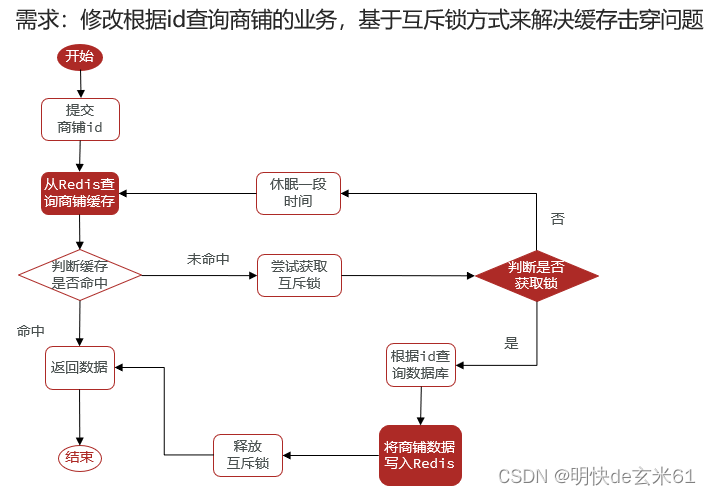
基于互斥锁方式解决缓存击穿问题举例:
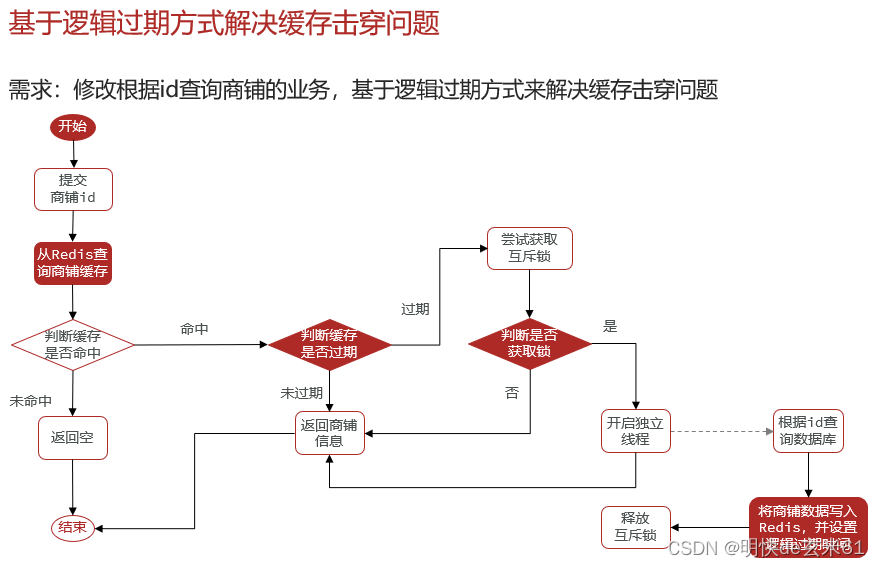
基于逻辑过期方式解决缓存击穿问题举例:
7.3、互斥锁代码举例
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
代码:
import cn.hutool.core.util.BooleanUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
// 不仅解决缓存击穿问题,也通过缓存空值方式来解决缓存穿透问题
@Slf4j
@Component
public class CacheClient {
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 通过缓存空值来解决缓存穿透问题
public <R, ID> R queryWithMutex(
String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, type);
}
// 判断命中的是否是空值,不等于空那就是空字符串,也就是我们缓存的空值,所以直接返回即可
if (shopJson != null) {
// 返回一个错误信息
return null;
}
// 4.实现缓存重建
// 4.1.获取互斥锁
String lockKey = "lock:shop:" + id;
R r = null;
try {
boolean isLock = tryLock(lockKey);
// 4.2.判断是否获取成功
if (!isLock) {
// 4.3.获取锁失败,休眠并重试
Thread.sleep(50);
return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);
}
// 4.4.获取锁成功,根据id查询数据库
r = dbFallback.apply(id);
// 5.不存在,返回错误
if (r == null) {
// 将空值(空串)写入redis,一定要加上时间
stringRedisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES);
// 返回错误信息
return null;
}
// 6.存在,写入redis
this.set(key, r, time, unit);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 7.释放锁
unlock(lockKey);
}
// 8.返回
return r;
}
// 添加互斥锁
private boolean tryLock(String key) {
// 做法类似于Redisson,作用:带等待时间的分布式锁
// 大部分情况下,10分钟完全可以完成一个业务功能,如果还不能完成,那肯定就是业务功能出现问题了,当然也可以使用Redisson分布式锁,毕竟它有看门口功能进行过期时间的无限续期
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// 解除互斥锁
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
}
7.4、逻辑过期代码举例
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
代码:
import cn.hutool.core.util.BooleanUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
// 不仅解决缓存击穿问题,甚至都不会面临缓存穿透问题,毕竟不存在直接就返回null了
@Slf4j
@Component
public class CacheClient {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
// 存储缓存数据的同时设置过期时间,这件事情在创建数据肯定要做,但是更新数据的时候一般不执行该方法
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {
// 设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
// 写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
// 查询缓存数据,不会面临缓存穿透问题,原因是没有就直接返回null了,否则才进行缓存击穿处理
public <R, ID> R queryWithLogicalExpire(
String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.不存在,直接返回,说明数据根本不存在,否则缓存中绝对有了
return null;
}
// 4.命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expireTime = redisData.getExpireTime();
// 5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
// 5.1.未过期,直接返回店铺信息
return r;
}
// 5.2.已过期,需要缓存重建
// 6.缓存重建
// 6.1.获取互斥锁
String lockKey = "lock:shop:" + id;
boolean isLock = tryLock(lockKey);
// 6.2.判断是否获取锁成功
if (isLock){
// 6.3.成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 查询数据库
R newR = dbFallback.apply(id);
// 重建缓存
this.setWithLogicalExpire(key, newR, time, unit);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
// 释放锁
unlock(lockKey);
}
});
}
// 6.4.返回过期的商铺信息
return r;
}
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
}
8、缓存雪崩
8.1、含义
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
8.2、解决办法
- 给不同的Key的TTL添加随机值:解决同一时段大量的缓存key同时失效问题
- 利用Redis集群提高服务的可用性:尽量避免Redis服务宕机
- 给缓存业务添加降级限流策略:为Redis服务宕机问题兜底
- 给业务添加多级缓存:避免完全依赖Redis,鸡蛋放到一个篮子里容易出问题
9、Lua脚本
9.1、Lua教程
访问链接:https://www.runoob.com/lua/lua-tutorial.html
9.2、Lua介绍
9.2.1、概念
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。
9.2.2、Redis为Lua语言内置的lua函数
redis.call('命令名称', 'key', '其它参数', ...)
举例:
// 总结:在redis中怎么写命令,这里就怎么写命令,只是之前命令参数之间用空格分隔,现在用逗号分隔而已
// 1、获取键值
redis.call('get', stockKey))
// 2、将键name设置为值jack
redis.call('set', 'name', 'jack')
// 3、设置多个键值
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
// 4、判断键值中是否已经存在该值
redis.call('sismember', orderKey, userId)
// 5、键值自增
redis.call('incrby', stockKey, -1)
9.2.3、在Redis-cli中执行Lua脚本函数
语法:
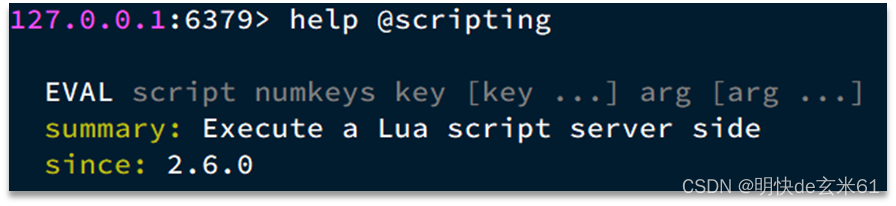
举例:
情况1:假设我们要执行 redis.call('set', 'name', 'jack') 这个脚本函数,语法如下:

情况2:如果脚本中的key、value不想写死,也可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数,如下:

总结:情况1和情况2都是我们经常使用的做法,只是使用场景不同,对于情况2来说,我们在java代码中也是经常用的,不过代码调用的时候只是传递了键集合和值可变参数,而Redis依赖底层会将这种调用形式转换成上述的EVAL脚本形式,比如:将键参数个数加上等
9.3、代码
9.3.1、前置准备:application.yaml和依赖
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
9.3.2、unlock.lua(放在resources下的lua脚本,等待被调用)
-- 比较线程标示与锁中的标示是否一致
if(redis.call('get', KEYS[1]) == ARGV[1]) then
-- 释放锁 del key
return redis.call('del', KEYS[1])
end
return 0
9.3.3、ILock接口
public interface ILock {
/**
* 尝试获取锁
* @param timeoutSec 锁持有的超时时间,过期后自动释放
* @return true代表获取锁成功; false代表获取锁失败
*/
boolean tryLock(long timeoutSec);
/**
* 释放锁
*/
void unlock();
}
9.3.4、SimpleRedisLock实现类
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
// 主要看静态代码块和unlock解锁方法,这两块在用lua脚本
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
// 调用lua脚本前的准备工作
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
// 读取lua脚本,也就是上面resources下的lua脚本文件
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
// 设置返回值类型
UNLOCK_SCRIPT.setResultType(Long.class);
}
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 调用lua脚本
// UNLOCK_SCRIPT:lua脚本
// Collections.singletonList(KEY_PREFIX + name):键集合
// ID_PREFIX + Thread.currentThread().getId():值可变参数
stringRedisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
}
9.4、更复杂的lua脚本代码
9.4.1、前置准备:application.yaml和依赖
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
9.4.2、seckill.lua(放在resources下的lua脚本,等待被调用)
-- 1.参数列表
-- 1.1.优惠券id
local voucherId = ARGV[1]
-- 1.2.用户id
local userId = ARGV[2]
-- 1.3.订单id
local orderId = ARGV[3]
-- 2.数据key
-- 2.1.库存key
-- ..是字符串连接符
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2.订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1.判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2.库存不足,返回1
return 1
end
-- 3.2.判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6.发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ...
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0
9.4.3、IVoucherOrderService 接口
import com.hmdp.dto.Result;
import com.hmdp.entity.VoucherOrder;
import com.baomidou.mybatisplus.extension.service.IService;
public interface IVoucherOrderService extends IService<VoucherOrder> {
Result seckillVoucher(Long voucherId);
}
9.4.4、VoucherOrderServiceImpl 实现类
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.dto.Result;
import com.hmdp.entity.VoucherOrder;
import com.hmdp.mapper.VoucherOrderMapper;
import com.hmdp.service.ISeckillVoucherService;
import com.hmdp.service.IVoucherOrderService;
import com.hmdp.utils.RedisIdWorker;
import com.hmdp.utils.UserHolder;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.Collections;
@Slf4j
@Service
public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
private RedisIdWorker redisIdWorker;
@Resource
private StringRedisTemplate stringRedisTemplate;
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
// 下订单接口,很多功能全部都使用Redis的lua脚本文件完成,可以保证原子性
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.返回订单id
return Result.ok(orderId);
}
}
10、Redission
10.1、概念
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。

10.2、官方地址
- 官网地址: https://redisson.org
- GitHub地址:
Redisson文档
10.3、为什么不使用Redis的setnx命令来实现分布式锁?
10.3.1、缺点
当然可以使用Redis的setnx命令来实现分布式锁,但是它是有缺点的,缺点如下:

10.3.1、使用Redis的setnx命令来实现分布式锁的代码
10.3.1.1、前置准备:application.yaml和依赖
application.yaml:
spring:
redis:
# ————————————————————单机配置————————————————————
host: 127.0.0.1
port: 6379
依赖:
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
10.3.1.2、unlock.lua(放在resources下的lua脚本,等待被调用)
-- 比较线程标示与锁中的标示是否一致
if(redis.call('get', KEYS[1]) == ARGV[1]) then
-- 释放锁 del key
return redis.call('del', KEYS[1])
end
return 0
10.3.1.3、ILock接口
public interface ILock {
/**
* 尝试获取锁
* @param timeoutSec 锁持有的超时时间,过期后自动释放
* @return true代表获取锁成功; false代表获取锁失败
*/
boolean tryLock(long timeoutSec);
/**
* 释放锁
*/
void unlock();
}
10.3.1.4、SimpleRedisLock实现类
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
// 主要看静态代码块和unlock解锁方法,这两块在用lua脚本
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
// 调用lua脚本前的准备工作
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
// 读取lua脚本,也就是上面resources下的lua脚本文件
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
// 设置返回值类型
UNLOCK_SCRIPT.setResultType(Long.class);
}
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 调用lua脚本
// UNLOCK_SCRIPT:lua脚本
// Collections.singletonList(KEY_PREFIX + name):键集合
// ID_PREFIX + Thread.currentThread().getId():值可变参数
stringRedisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
}
10.4、Redisson分布式锁原理
10.4.1、解决不可重入问题
10.4.1.1、方案
在redis中以hash结构来存储线程id和重入次数,类似于synchronized的做法,从而实现可重入锁
10.4.1.2、画图介绍
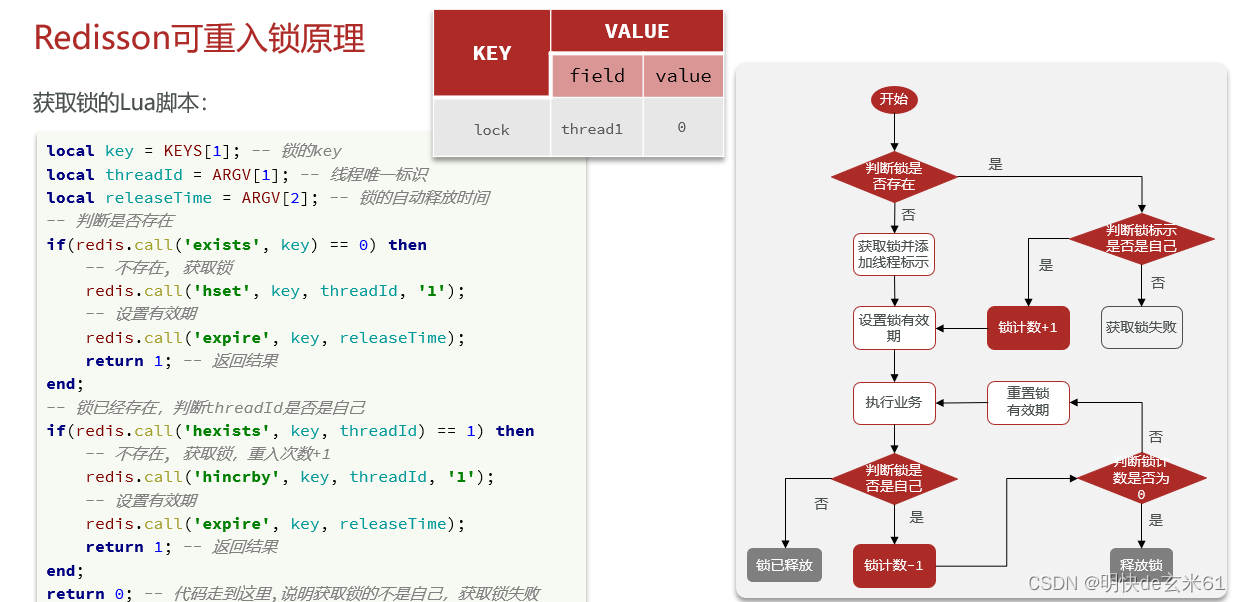
10.4.1.3、代码分析
首先找到tryLock方法,然后进入RedissonLock实现类,如下:

进入tryLock方法之后,可以看到leaseTime的值是-1,这个将会影响是否启用看门狗机制,后续在介绍解决锁超时释放问题的时候详细介绍,如下:

然后在进入tryLock方法内部,可以看到先获取了threadId,并且执行了tryAcquire方法,如下:
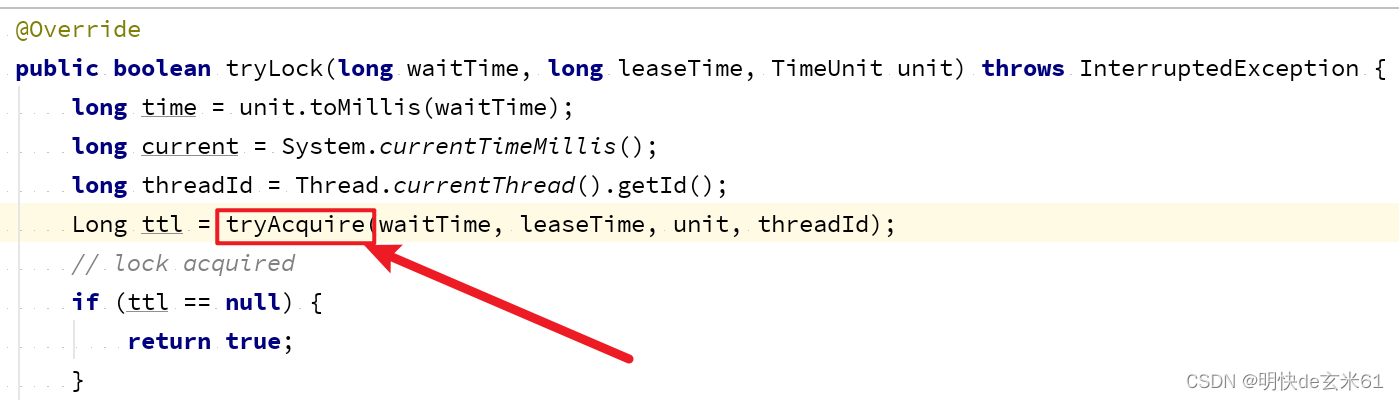
然后我们进入tryAcquire方法内部,看到调用了tryAcquireAsync方法,如下:

然后我们进入tryAcquireAsync方法内部,可以看到无论leaseTime是否等于-1,都会调用tryLockInnerAsync方法,如下:
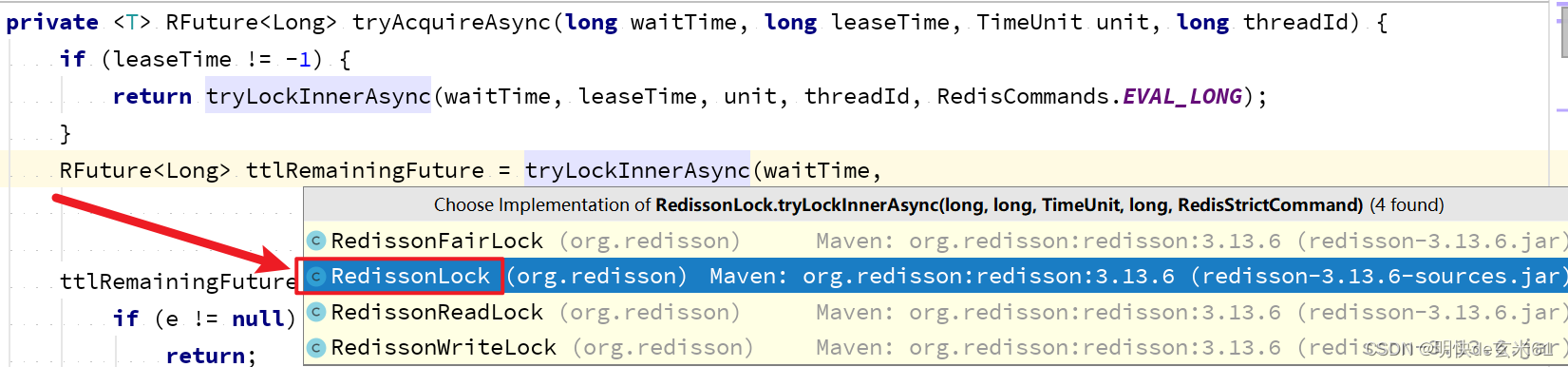
我们进入RedissonLock类的tryLockInnerAsync方法,如下:

上面这段lua脚本的作用就是判断是否加锁了,如果没有加锁,那就直接加锁,如果已经加锁,那就判断加锁的是当前线程吗,如果不是当前线程,那就直接返回锁过期时间。如果加锁的是当前线程,那就让重入次数加1,从而完成锁重入,如果加锁/锁重入成功,那就返回nil(空值),否则返回锁剩余有效时间
上述代码使用Fature方式,所以在调用get()方法的时候会阻塞,因此我们往上追溯到tryAcquire()方法处,如果获取锁(新锁 / 重入锁)成功,那ttl就返回null,然后tryLock方法就返回true,然后就能执行业务代码了,真正实现了可重入锁,代码如下:

10.4.2、解决不可重试问题
10.4.2.1、方案
如果当前锁是其他线程的,那就可以等待其他线程释放锁(等待过程不是while循环重试,而是使用Redis的pubsub事件通知方式进行重试,降低CPU使用率),其他线程释放锁之后重新尝试获取锁,获取不到那就等待其他线程释放锁,其他线程释放锁之后重新尝试获取锁,以此循环……
10.4.2.2、代码分析
大家可以先看上面关于解决可重入锁问题的解释,我们在上面提到,如果没有获取锁,那tryAcquire方法返回锁在Redis中的过期时间,那么ttl就不是null,如下:
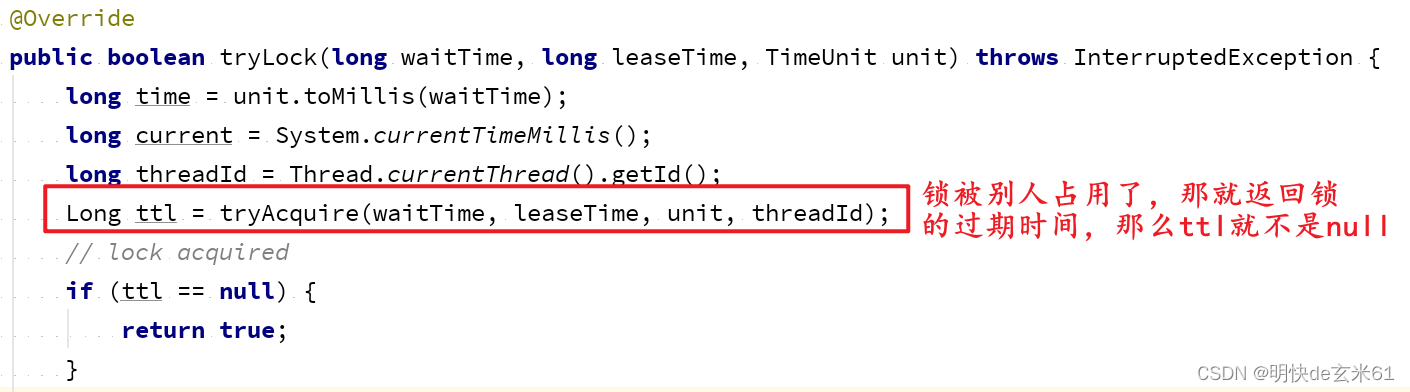
我们接着上面截图代码继续往下看,可以看到等待锁释放的过程,当然Redisson没有使用死循环,而是使用Redis的pubsub监听方式,如下:
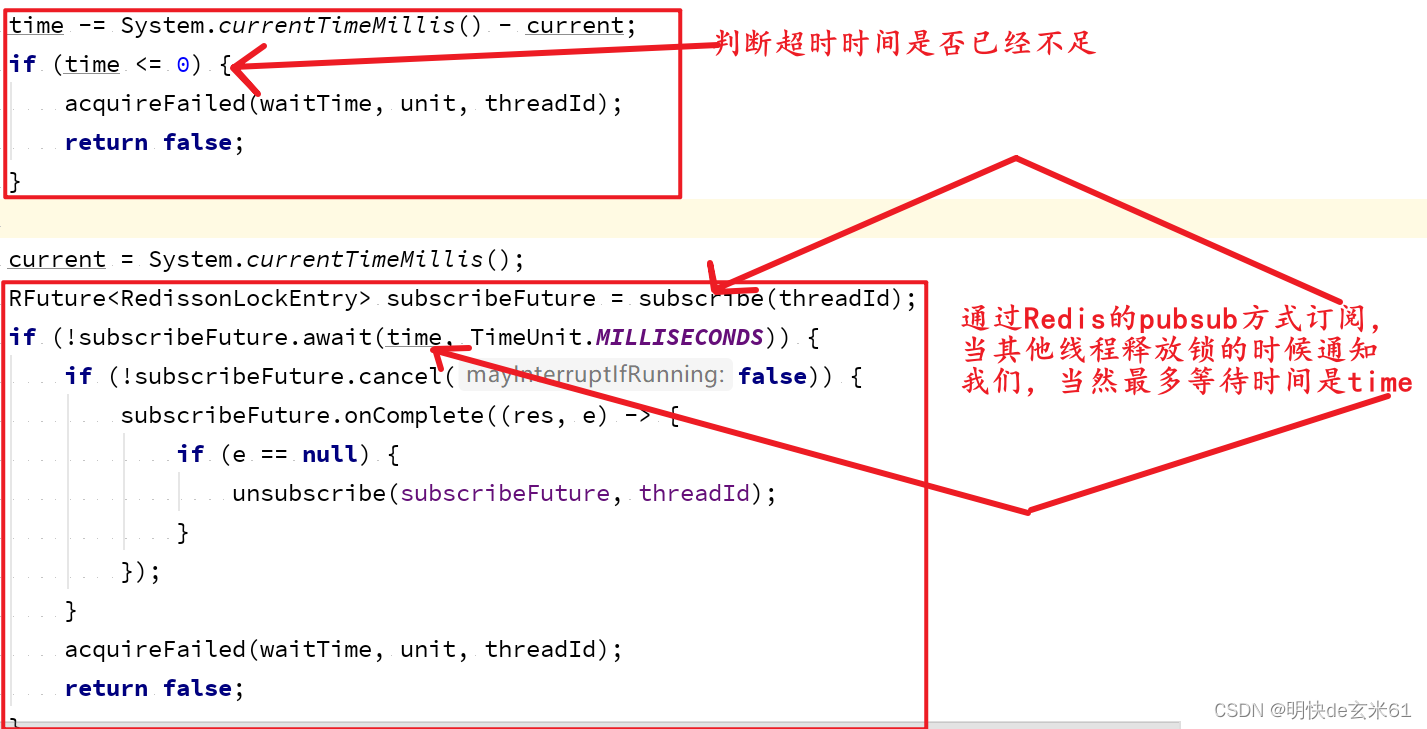
如果监听到其他线程释放锁了,那么代码会继续尝试获取锁,如下:
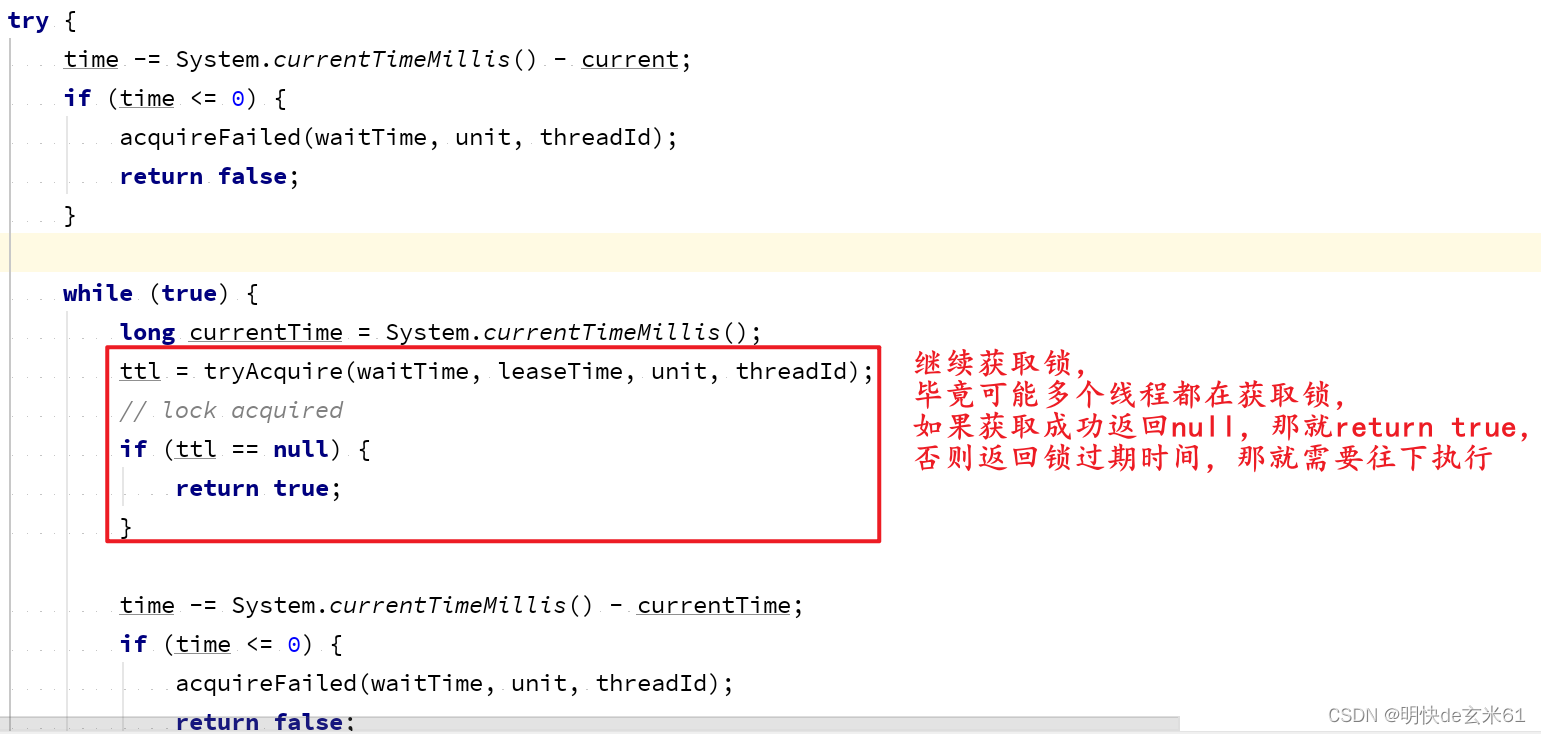
假设又获取锁失败了,那代码会继续往下执行,如下:

如果本次获取锁又失败了,那就会执行while循环,从而解决锁不可重试问题,如下:
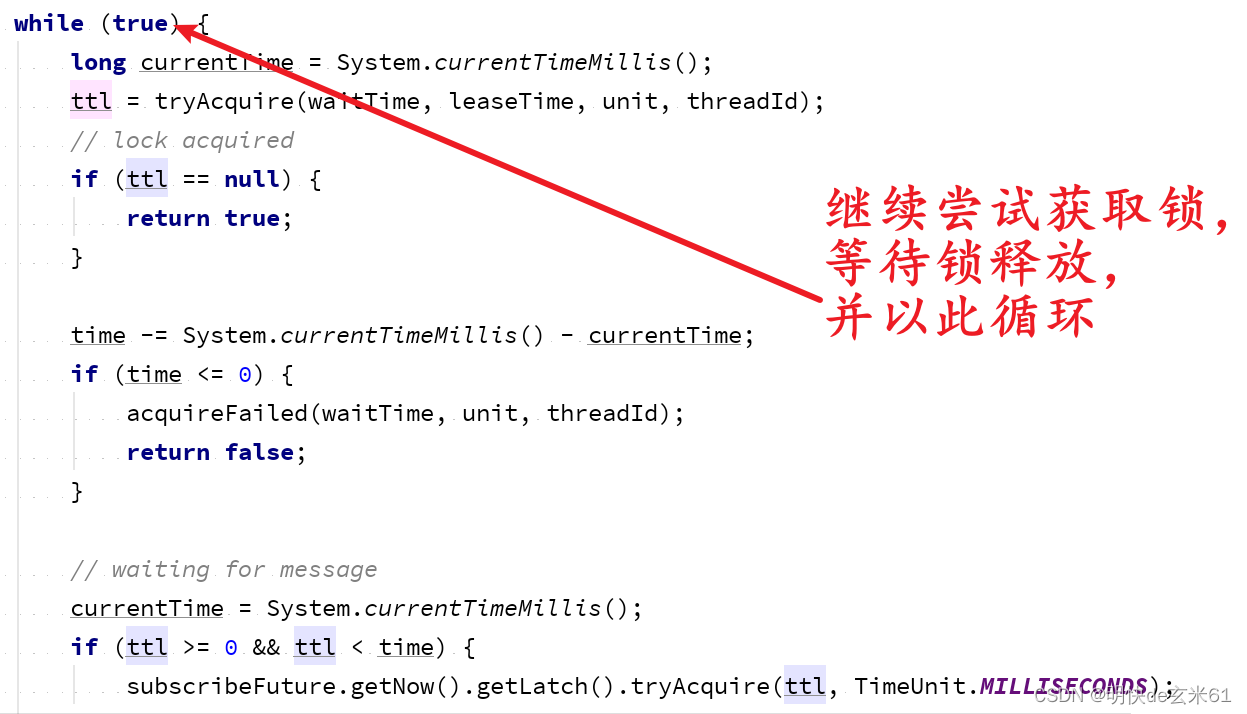
10.4.3、解决超时释放问题
10.4.3.1、方案
我们自己实现的redis分布式锁中的过期时间是指定的,由于业务执行时间不是完全确定的,甚至执行10分钟也不是不可能,但是我们不能把这个值设置太大了,否则会影响锁的自动过期释放,所以我们需要让锁可以自动续期,目前采用看门狗机制通过锁自动续期来解决锁超时释放问题
10.4.3.2、代码解读
首先找到tryLock方法,然后进入RedissonLock实现类,如下:
进入tryLock方法之后,可以看到leaseTime的值是-1,该值代表启用看门狗机制,所以特别注意要想启用看门口机制,就不用设置过期释放时间leaseTime,如下:
然后在进入tryLock方法内部,可以看到先获取了threadId,并且执行了tryAcquire方法,如下:
然后我们进入tryAcquire方法内部,看到调用了tryAcquireAsync方法,如下:
然后我们进入tryAcquireAsync方法内部,本次聊的是看门口机制,所以leaseTime是-1,代码如下:

我们进入scheduleExpirationRenewal方法,如下:
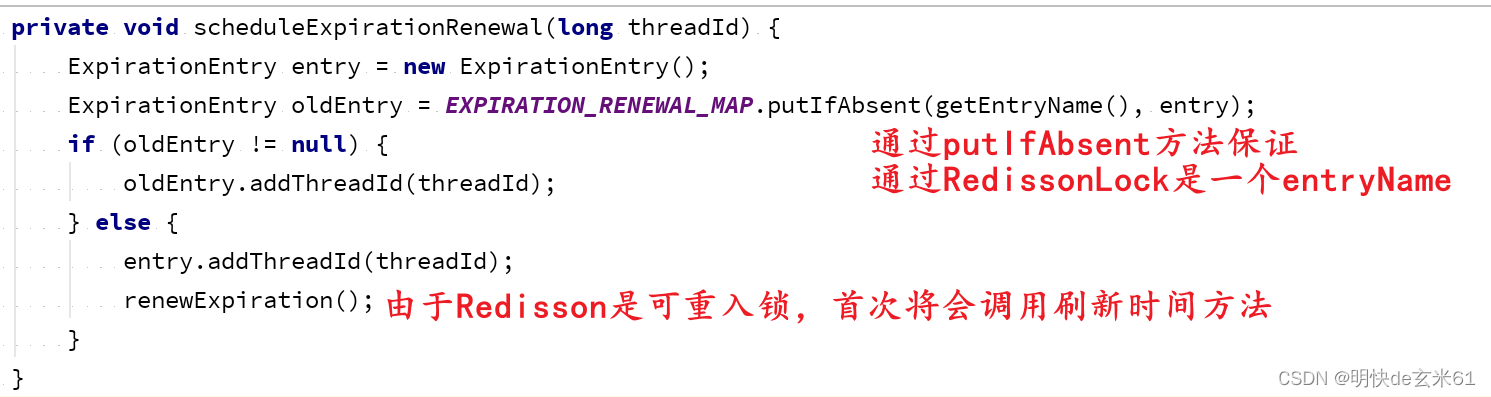
我们直接看renewExpiration方法内部代码吧,如下:
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
// 创建任务
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
// 2、为锁过期时间进行续期
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
// 3、重新调用自身,用于下次为锁过期时间进行续期
renewExpiration();
}
});
}
// 1、看门狗超时时间默认30s,也就是10s之后会执行当前任务
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
// 4、将任务放入ExpirationEntry对象中,用于后续取消任务,毕竟任务取消之后看门狗不能一直在吧
ee.setTimeout(task);
}
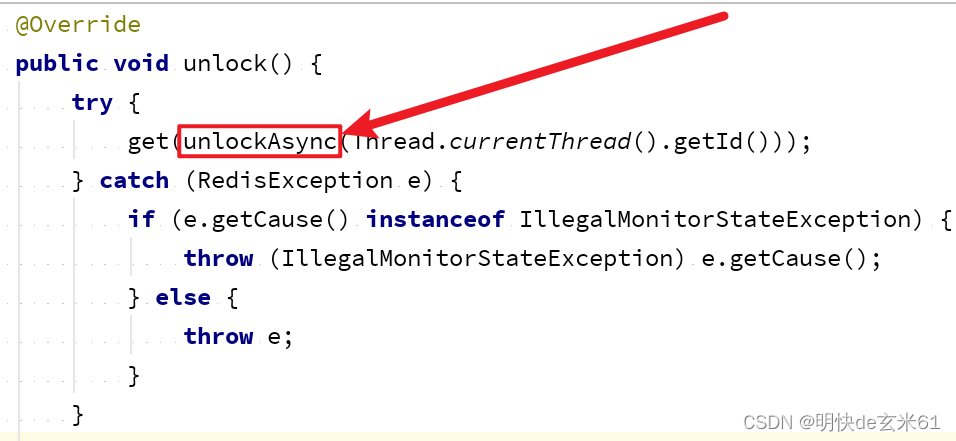
上面已经把看门狗机制进行了解释,也就是过一段时间会有看门狗进行过期时间刷新,但是当锁被取消之后,看门狗也要消失的,我们来看Redisson的unlock方法,如下:

进入unlock方法,我们进入unlockAsync方法,如下:
我们进入unlockAsync方法,然后在进入cancelExpirationRenewal方法,如下:
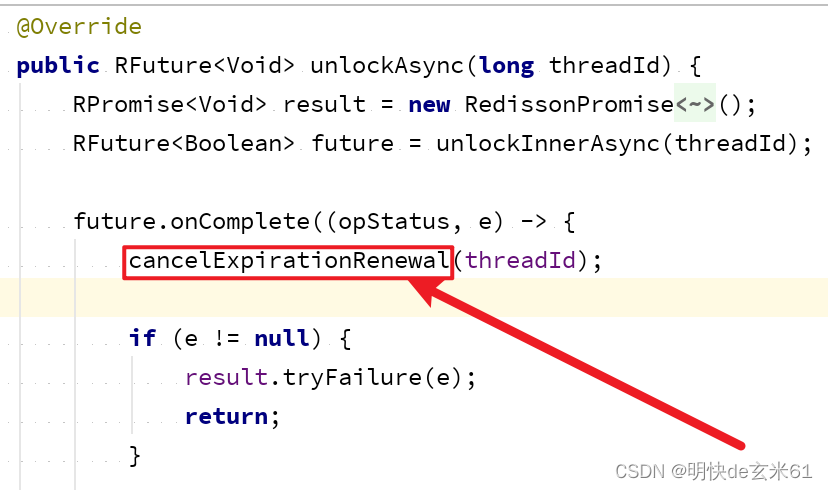
然后进入cancelExpirationRenewal方法,如下:

这样就完成了锁释放时对看门狗任务的移除工作
10.4.4、解决主从一致性问题
10.4.4.1、方案
假设现在把锁告诉了redis主节点,这个时候主节点挂机了,那redis从节点有没有redis锁数据,这个时候就出现问题了,所以最完美的解决办法就是让所有的redis节点都加上锁,这样才能真正解决主从一致性问题
10.4.4.2、代码
配置类:
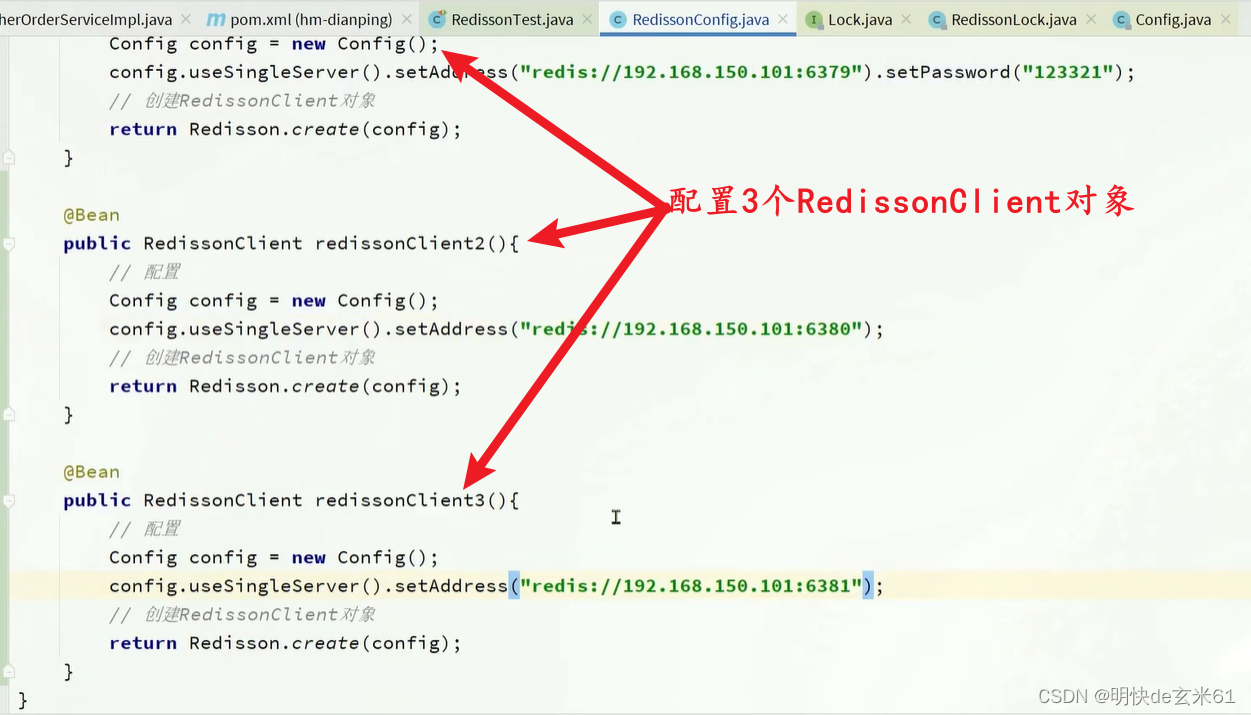
使用方式:
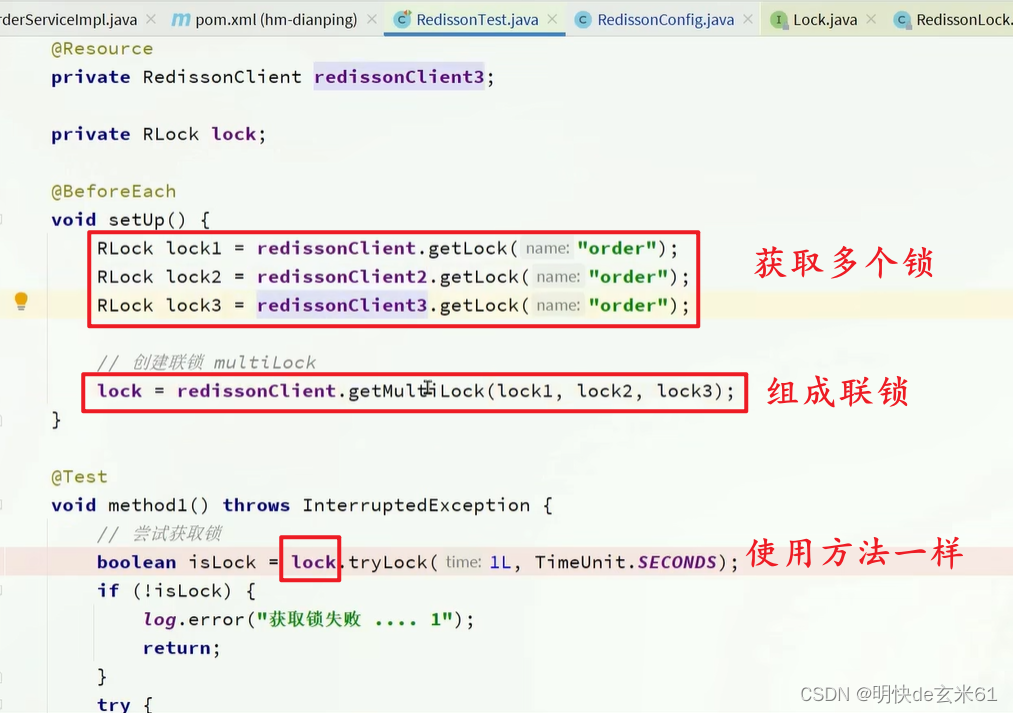
10.5、Redisson用途
10.5.1、用途概述
可用于以下几种用途:
- 可重入锁(Reentrant Lock)
- 公平锁(Fair Lock)
- 联锁(MultiLock)
- 红锁(RedLock,类似联锁)
- 读写锁(ReadWriteLock,只有读读不阻塞,其他组合都阻塞)
- 信号量(Semaphore)
- 可过期性信号量(PermitExpirableSemaphore)
- 闭锁(CountDownLatch)
点击我查看详细代码: 分布式锁和同步器
10.5.2、waitTime和leaseTime参数区别
- waitTime:等待获取锁的最大超时时间,一般默认值是-1,也就是不超时,一直等待
- leaseTime:Redis锁的过期时间,一般默认值是-1,也就是不过期
10.5.3、lock()和tryLock()方法区别
- lock():没有返回值,在获取到分布式锁之前都是阻塞的,会使用看门狗机制进行锁自动续期
- lock(long leaseTime, TimeUnit unit):没有返回值,在获取到分布式锁之前都是阻塞的,锁过期时间是leaseTime,单位是unit,不会使用看门狗机制进行锁自动续期
- tryLock():返回值是布尔类型,代表是否获取锁,代码会直接返回,不会阻塞
- tryLock(long time, TimeUnit unit):返回值是布尔类型,代表是否获取锁,获取锁超时时间是time,单位是unit,锁过期时间leaseTime是-1,代表会使用看门狗机制进行锁自动续期
- tryLock(long waitTime, long leaseTime, TimeUnit unit):返回值是布尔类型,代表是否获取锁,获取锁超时时间是time,单位是unit;如果leaseTime是-1,那代表会使用看门狗机制进行锁自动续期,否则不会使用看门狗机制进行锁自动续期,并且锁过期时间是leaseTime,单位是unit
11、RDB和AOF
11.1、RDB
11.1.1、概念
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
注意: Redis停机时会执行一次RDB。
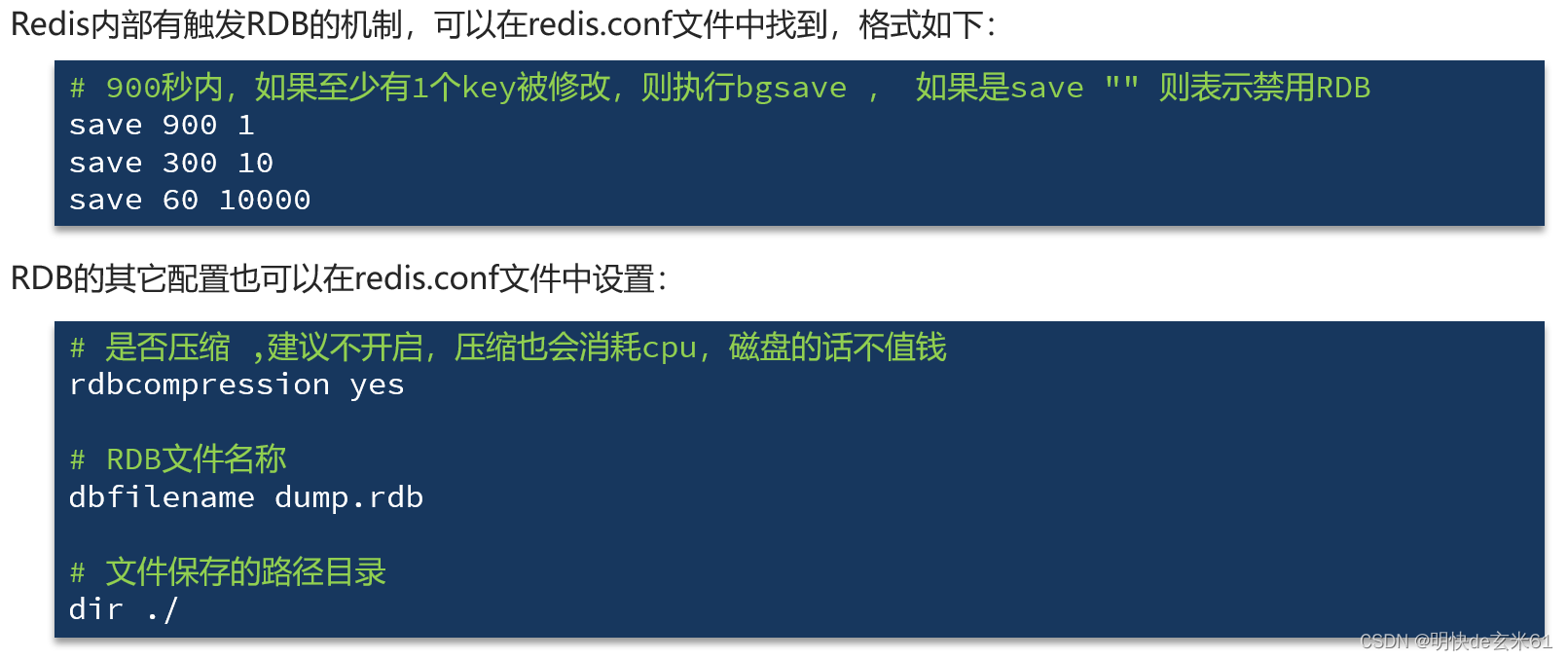
11.1.2、RDB触发机制(配置文件+手动输入命令操作)
11.1.2.1、Redis内部触发机制:配置文件
11.1.2.2、Redis命令行手动触发方式:手动操作(不建议使用)

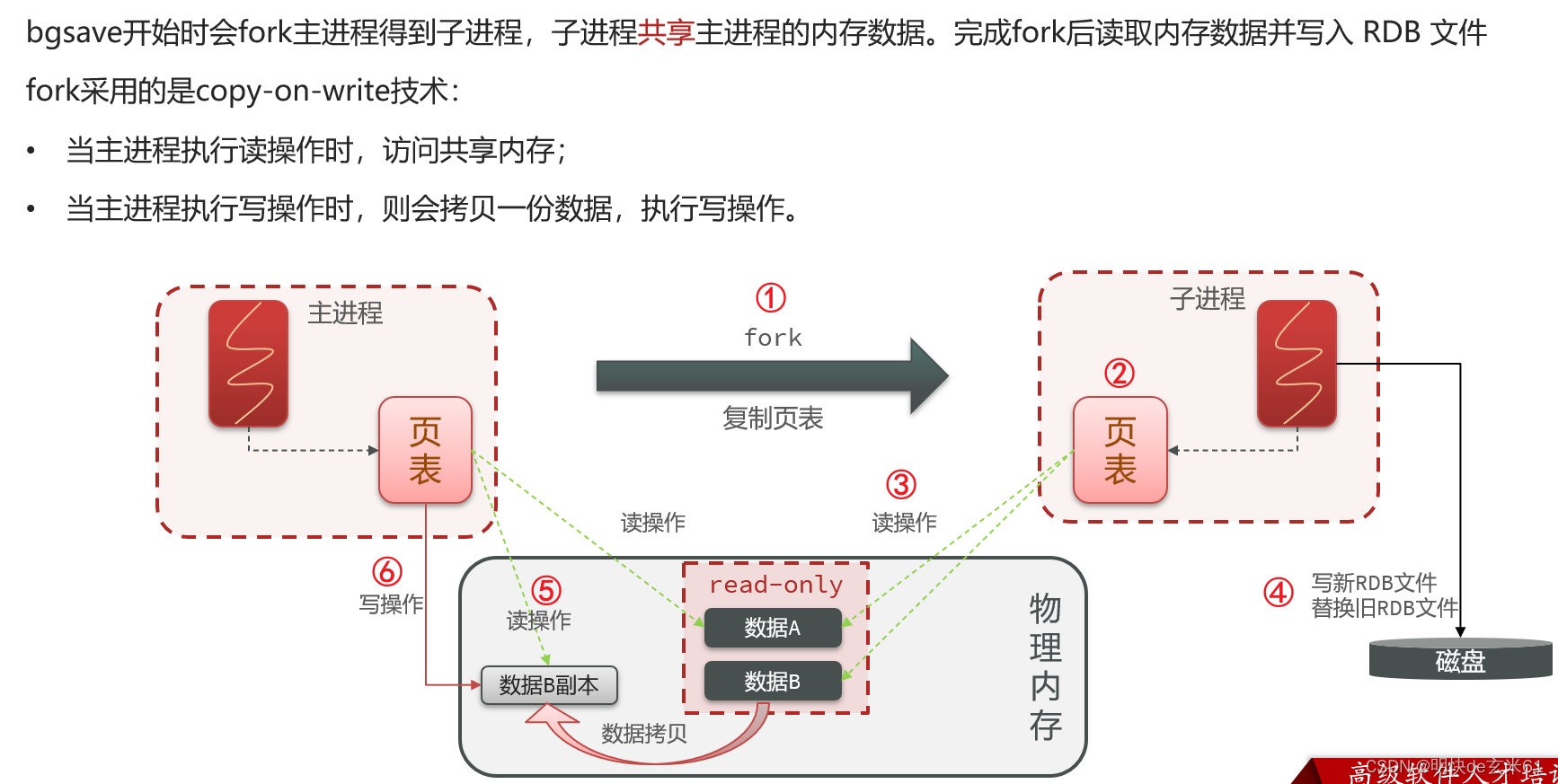
11.1.3、RDB备份原理
总结: 写时复制技术,详细做法如下:
11.1.4、总结
1、RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
2、RDB会在什么时候执行?
- 默认是服务停止时。
3、save 60 1000代表什么含义?
- 代表60秒内至少执行1000次修改则触发RDB
4、 RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
11.2、AOF
11.2.1、概念
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件中,可以看做是命令日志文件。
11.2.2、如何修改Redis配置文件
11.2.2.1、普通配置

11.2.2.2、AOF文件瘦身配置
AOF文件用来记录用户输入的命令,所以AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过手动执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。但是手动执行命令不太靠谱,然后Redis也会在触发阈值时自动去重写AOF文件,其中阈值可以在redis.conf中配置,下面是默认值,一般不用修改:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
11.3、RDB和AOF对比
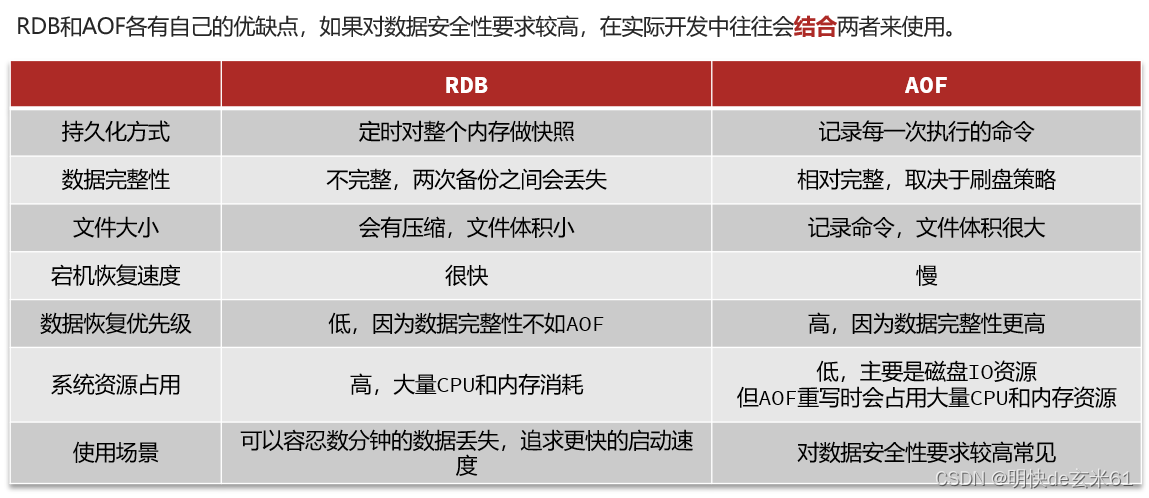
注意: 在搭建Redis集群的时候,哨兵模式主从集群之间的数据同步使用RDB文件,所以RDB方式一定不能少
12、主从集群、哨兵集群、分片集群相关原理
12.1、主从集群
12.1.1、数据同步原理
首先介绍几个概念:
- Replication Id:简称replid,这是数据集的标记。每一个master都有唯一的replid,slave则会继承master节点的replid,只有replid一致才说明是同一数据集
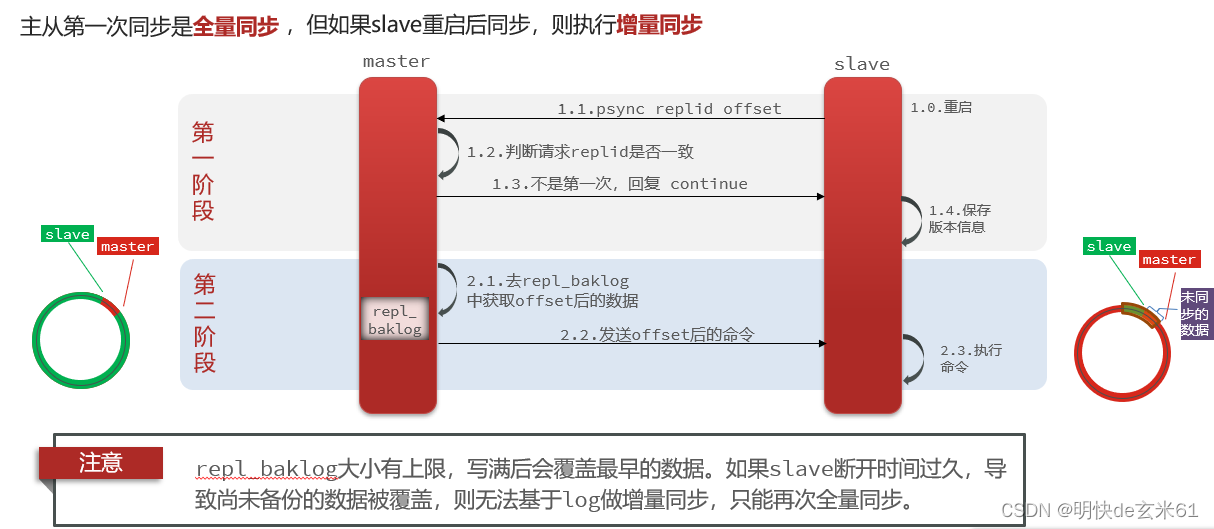
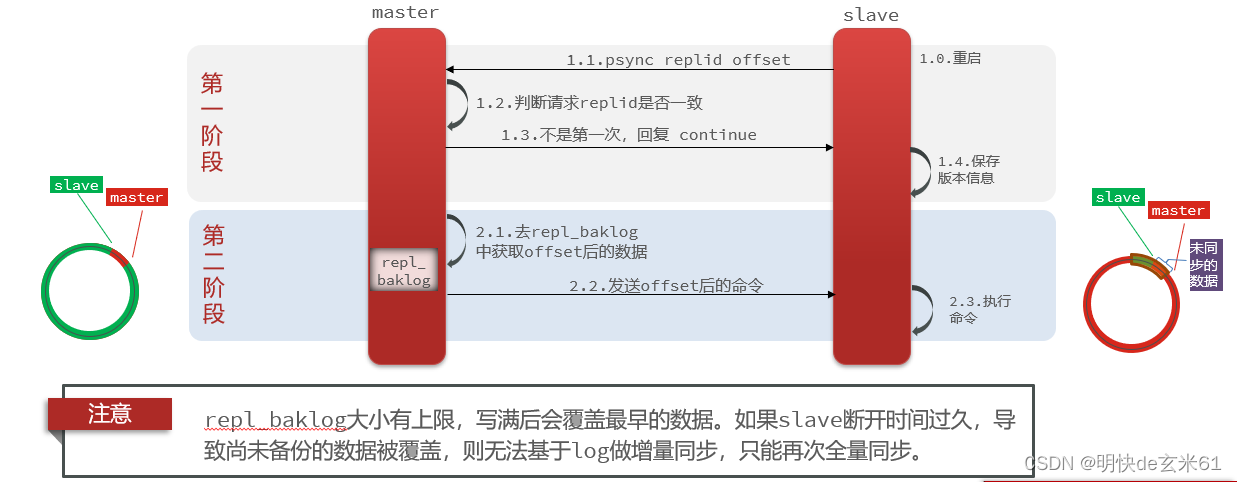
- repl_baklog:存储尚未备份到RDB文件的命令
- offset:偏移量,offset随着记录在repl_baklog中的数据增多而逐渐增大,slave完成同步时也会记录当前同步的offset,如果slave的offset小于master的offset,说明slave数据落后于master,需要更新repl_baklog中的命令
- 总结:当slave向master做数据同步,必须向master声明自己的replid和offset,然后master才可以判断到底需要同步哪些数据
-
如果replid不一致,那就需要进行全量同步

-
如果replid一致,但是从节点的offset小于主节点的offset,那就进行增量同步
-
如果replid一致,但是由于repl_baklog大小有上限,当repl_baklog命令环写满后会覆盖最早的数据,如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步
-
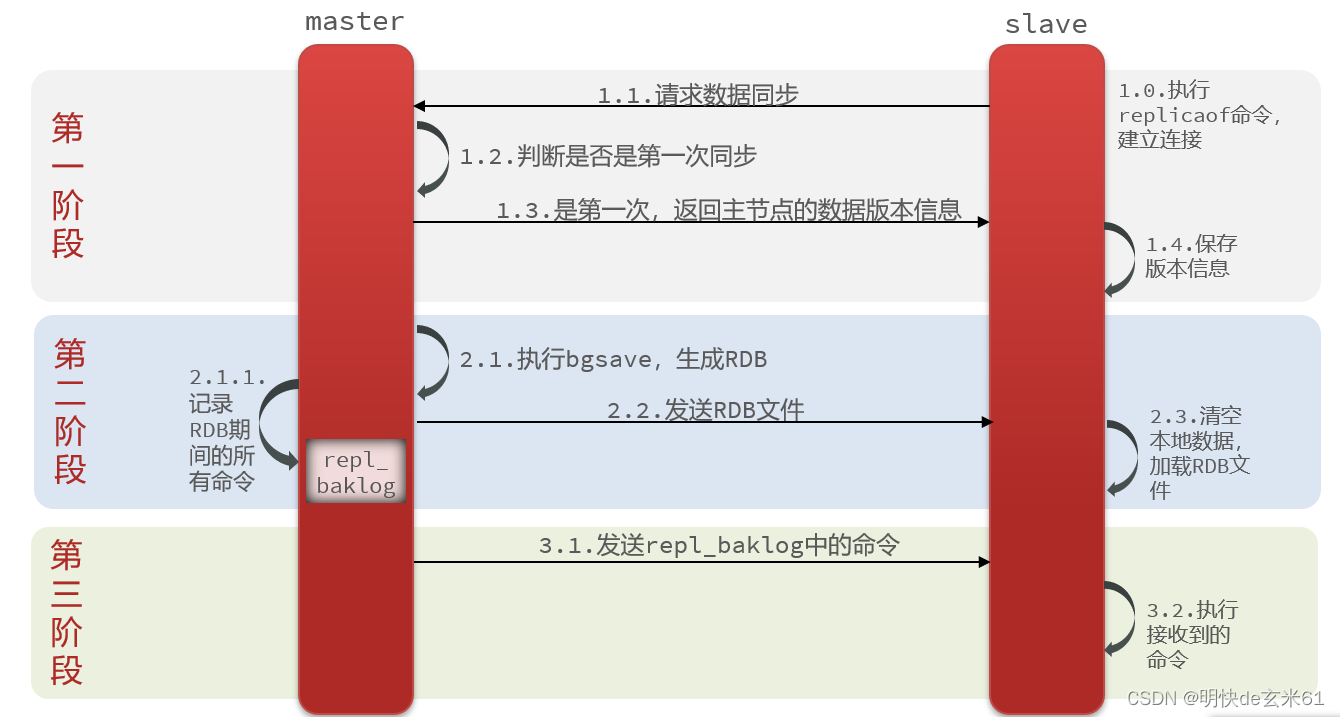
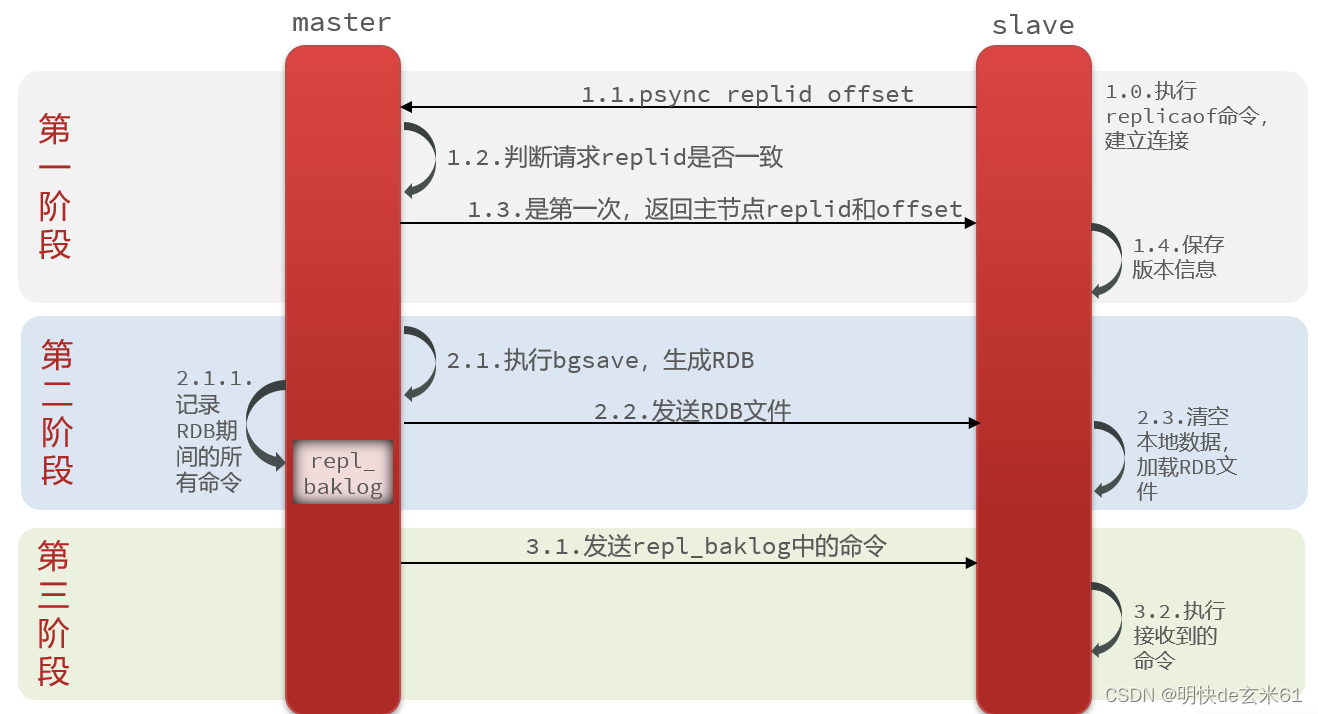
12.1.2、从节点第一次加入主节点进行全量同步流程
- 全量同步的流程slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
第一阶段用命令来解释:
12.1.3、从节点重启之后尝试再次加入主节点进行数据同步
注意: 可以适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
12.1.4、总结

12.2、哨兵集群
12.2.1、哨兵作用
对于主从集群来说,如果主节点宕机,那么整个集群的写功能直接瘫痪,而引入哨兵之后,哨兵可以发现宕机的主从节点,当主节点宕机之后,哨兵可以将从节点提升为主节点,如果从节点宕机之后,哨兵不会把读请求发送到该从节点
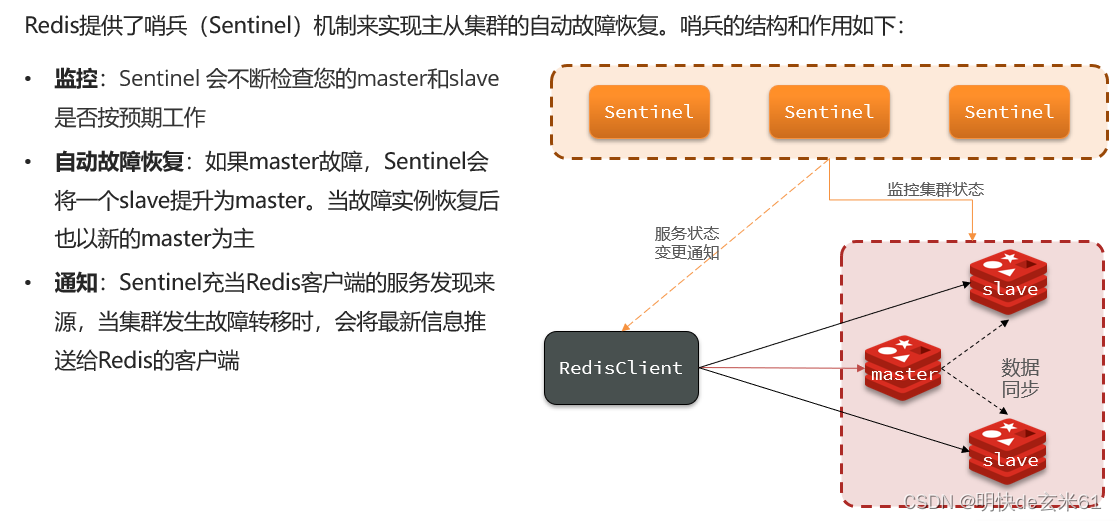
12.2.2、监控服务状态
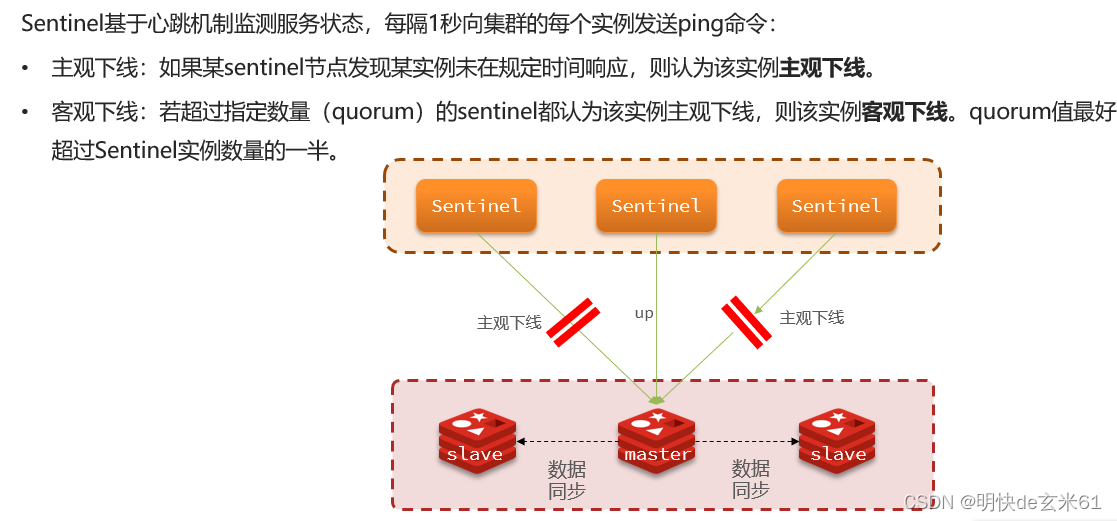
12.2.3、选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
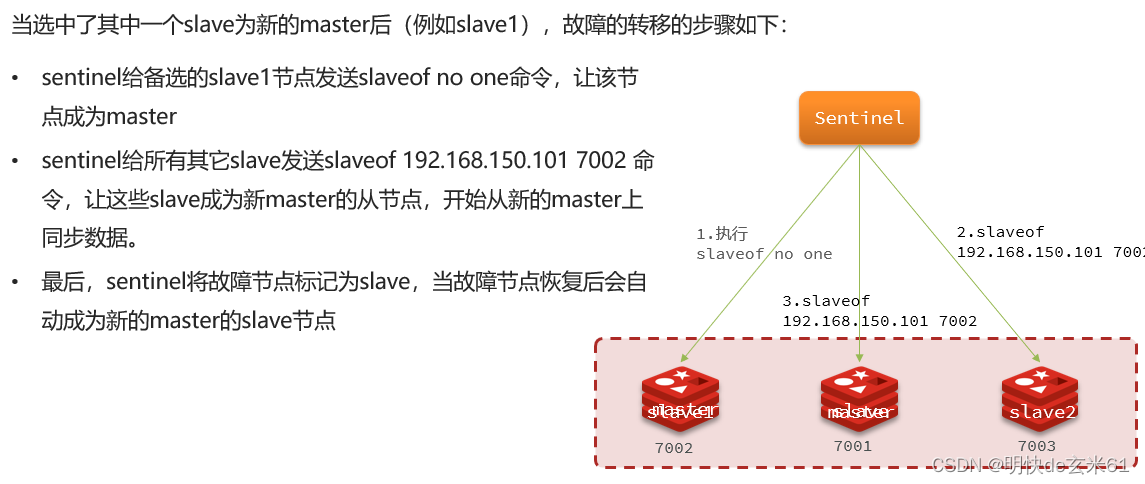
12.2.4、实现故障转移
12.2.5、总结

12.2.6、RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
1、在pom文件中引入redis的starter依赖

2、然后在配置文件application.yml中指定sentinel相关信息

3、配置主从读写分离

这里的ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
12.3、分片集群
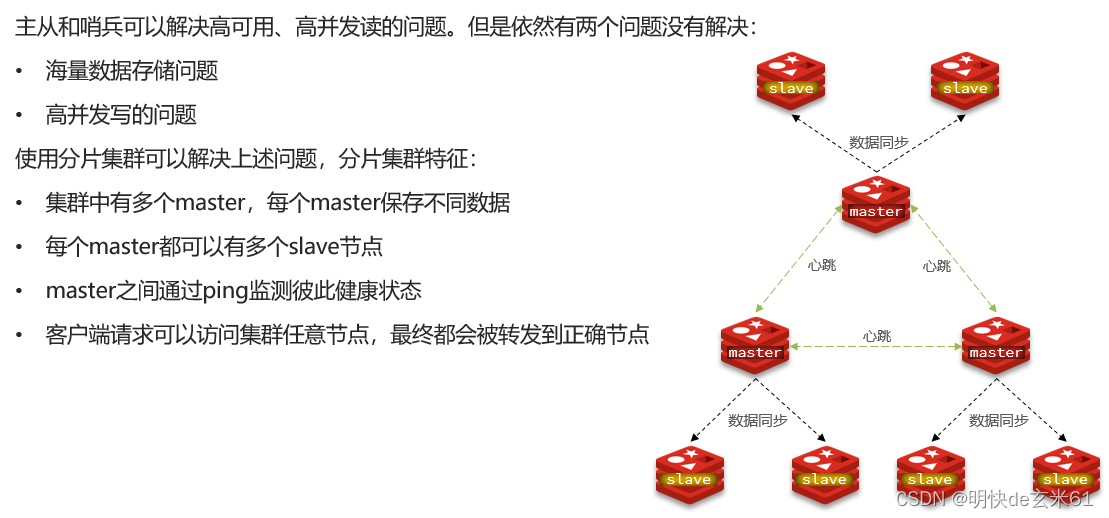
12.3.1、分片集群结构
12.3.2、散列插槽
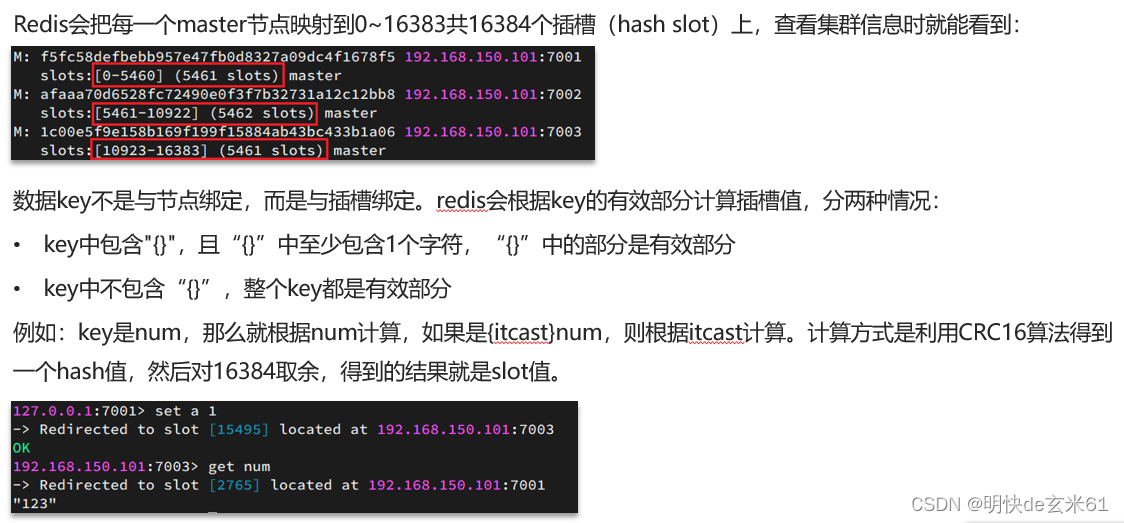
总结:
1、Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
2、如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
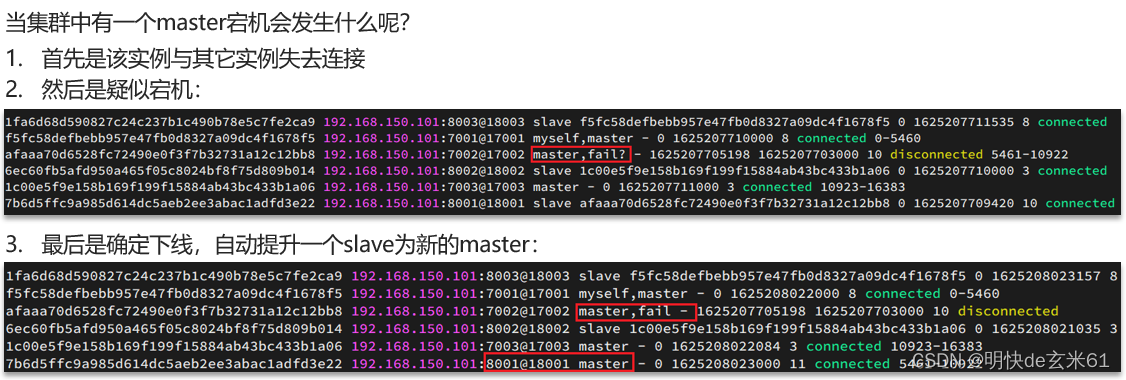
12.3.3、故障转移
13、小知识点
13.1、RedisTemplate的默认JDK序列化方式、RedisTemplate的自定义Jackson序列化方式、StringRedisTemplate字符串序列化方式,到底用哪个?
注意:用StringRedisTemplate字符串序列化方式,不用其他的
先解释下用StringRedisTemplate字符串序列化方式的优缺点:
-
优点:不用添加任何多余依赖,不用添加任何配置类,序列化之后效果也很棒,直接看到的就是字符串,即使是对象也不会存储全类名,统统都是字符串
-
缺点:存储到Redis时的序列化和从Redis读出结果的反序列化都需要自己来操作
再解释下其他序列化方式被弃用的原因,如下:
-
不用
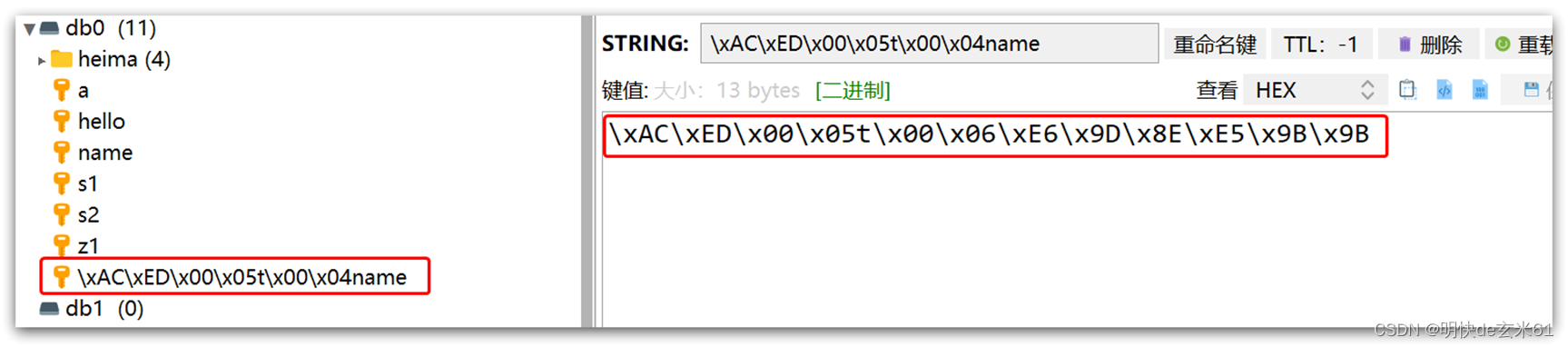
RedisTemplate的默认JDK序列化方式原因:默认情况下RedisTemplate使用JDK序列化方式,但是在将数据写入Redis之前会把Object序列化为字节形式,然后存储在Redis中的键值就变成了下图模样,缺点是:可读性差(通过Redis客户端连接之后根本看不出来存储的是啥)、内存占用较大(本来就存储中国这两个字,直接能给我序列化出一大坨东西)
-
不用
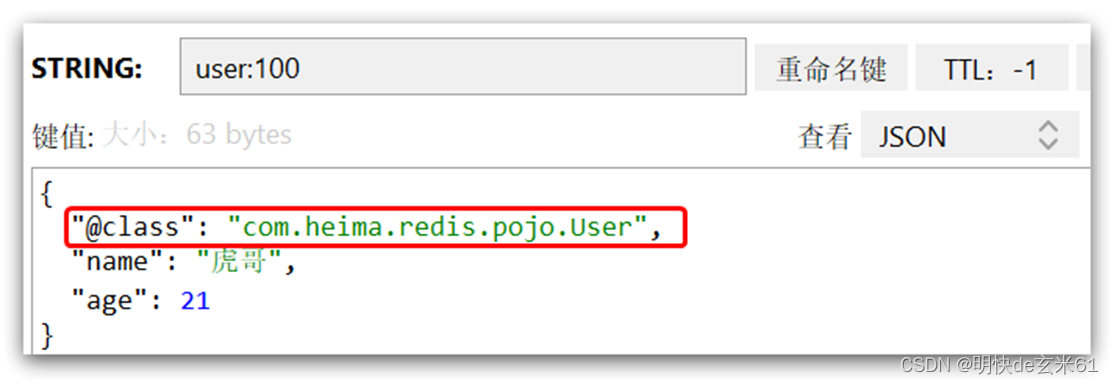
RedisTemplate的自定义Jackson序列化方式原因:虽然数据被很好的序列化,既不占用太多内存,也方便阅读,并且可以接收Object类型数据,不用我们操太多心,但是“成也萧何败也萧何”呀,当接收Object类型数据之后,在存储到Redis里面的时候,不仅会存储数据信息,还会存储对象信息,比如我将一个User对象交给这种方式的Redis进行存储,那Redis中存储的数据就像这种(下面第1张图),假设未来我把User的全路径位置改变了,那在Redis反序列的时候就会报错,这一点是我不能接受的,总不能被一个好处影响了我代码不能改动吧。当然这种方式还需要添加Jackson依赖(下面依赖),也需要对RestTemplate进行特殊配置(下面配置类)
Redis中对User对象的序列化结果:
Jackson依赖:<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency>RedisTemplate配置类:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.RedisSerializer; @Configuration public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){ // 创建RedisTemplate对象 RedisTemplate<String, Object> template = new RedisTemplate<>(); // 设置连接工厂 template.setConnectionFactory(connectionFactory); // 创建JSON序列化工具 GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer(); // 设置Key的序列化 template.setKeySerializer(RedisSerializer.string()); template.setHashKeySerializer(RedisSerializer.string()); // 设置Value的序列化 template.setValueSerializer(jsonRedisSerializer); template.setHashValueSerializer(jsonRedisSerializer); // 返回 return template; } }
二、操作命令
1、Redis命令官网
https://redis.io/commands
2、数据结构列表
- String:安全的二进制字符串
- List:有序可重复字符串集合,内部数据结构是链表,其中有序的含义是:按照插入顺序进行排序
- Set:无序不重复字符串集合
- Sorted set:无序不重复字符串集合,但是每一个字符串值都和一个浮点数相关联,这个浮点数叫做score分数,元素总是按照分数进行排序,所以我们可以按照分数来获取字符串元素值
- Hash:Map类型,其中键和值都是字符串
- Bit arrays:可以使用特殊命令来处理字符串值,如位数组:您可以设置和清除单个位,将所有设置为 1 的位计数,找到第一个设置或未设置的位,等等。常用来统计打卡情况。
- HyperLogLogs:这是一种概率数据结构,用于估计集合的基数。不要害怕,它比看起来更简单…。常用来统计日活、月活等。
- Streams:提供抽象日志数据类型的类似地图条目的仅附加集合。
3、Redis通用命令使用介绍
- KEYS:查看符合模板的所有key
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
通过help [command] 可以查看一个命令的具体用法,例如:
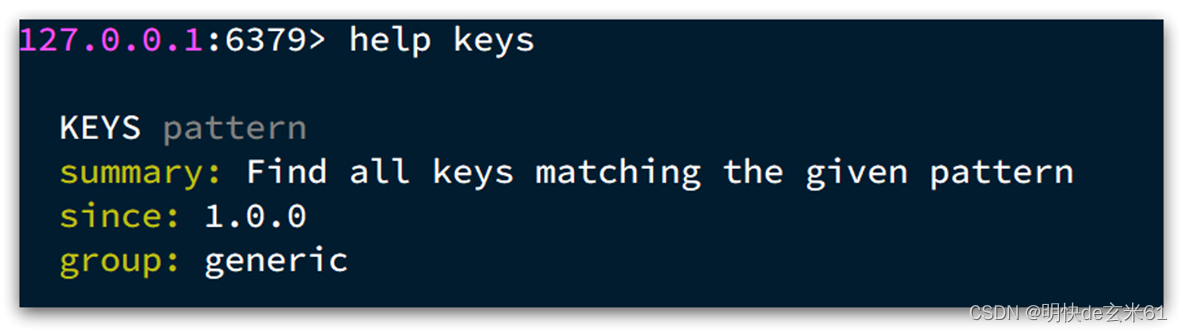
4、String使用介绍(使用redis-cli命令行操作)
4.1、简单介绍
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m.
常用命令汇总:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
4.2、set ……、set …… ex ……(简写:setex)、set …… px ……、set …… nx(简写:setnx)、set …… xx
概念: 设置键和值
返回值:
设置成功,将返回提示信息:OK
模式: set key value [EX seconds] [PX milliseconds] [NX|XX]
脚本:
// 过期时间为-1,即不过期
set key1 value1
// 过期时间单位是10秒
set key1 value1 ex 10
// 过期单位是10000毫秒
set key1 value1 px 10000
// key不存在才能设置成功,否则失败返回(nil)
set key1 value1 nx
// key存在才能设置成功,否则失败返回(nil)
set key1 value1 xx
说明:
- value替换:如果不设置nx或者xx,无论key存在与否都不会失败,如果key不存在,那么就添加value,如果key存在,那就就替换掉原来的value值
4.3、mset
概念: 批量设置键和值,可以设置一个或者多个
返回值:
设置成功,将返回提示信息:OK
模式: mset key value [key value ...]
脚本:
// 其中键a、b、c的值分别是1、2、3
mset a 1 b 2 c 3
说明:
- 键值写法:mset后面可以写多个键值对,单个键值对之间用空格隔离,多个键值对之间也用空格隔离
4.4、getset
概念: 获取原有键的值,并为键设置新值
返回值:
如果原有键存在,那么将返回原有键中的值;如果原有键不存在,那么将返回(nil)
模式: getset key value
脚本:
// 设置key1的值为新值;如果key1原来存在,那么将返回key1的原来值;如果key1不存在,将返回(nil)
getset key1 value1
4.5、get
概念: 获取单个键的值
返回值:
如果键存在,将返回键中的值;如果键不存在,将返回(nil)
模式: get key
脚本:
get key1
4.6、mget
概念: 批量获取键的值,可以获取一个或者多个
返回值:
如果所有键中的值都不存在,将返回:
1) (nil)
如果部分键中的值不存在,不存在的键值返回(nil),存在的键值将返回具体的值,如下:
1) (nil)
2) (nil)
3) "1"
4) (nil)
5) "2"
6) (nil)
模式: mget key [key ...]
脚本:
// 返回值是一个值数组
mget a b c
4.7、del(所有类型可用)
概念: 删除键,可以删除一个或者多个
返回值:
返回删除成功的键的数量,即使键不存在,也不会报错
模式: del key [key ...]
脚本:
del a b
4.8、incr、incrby、decr、decrby(仅限Integer类型(String类型可以转换成Integer类型))
概念: 只能对值能强转成Integer类型的键操作,含义如下:incr(增加1)、incrby(增加指定数量)、decr(减小1)、decrby(减小指定数量),另外incrby也可以增加负数,那相当代替了decr和decrby的作用
返回值:
返回增加/减小之后的数值
模式:
// 增加1
incr key
// 增加指定数量
incrby key increment
// 减小1
decr key
// 减小指定数量
decrby key decrement
脚本:
// 增加1
incr a
// 增加50
incrby a 50
// 减小1
decr a
// 减小50
decrby key 50
4.9、incrbyfloat(仅限浮点类型(String类型可以转换成浮点类型))
概念: 只能对值能强转成float类型的键操作,含义如下:incrbyfloat(增加或者减少指定数量,如果是正数就是增加,否则负数就是减少)
返回值:
返回增加/减小之后的数值
模式:
// 增加指定数量
INCRBYFLOAT key num
// 减小指定数量
INCRBYFLOAT key num
脚本:
// 增加指定数量
INCRBYFLOAT mykey 0.1
// 减小指定数量
INCRBYFLOAT mykey -5
4.10、exists(所有类型可用)
概念: 判断键是否存在,,可以判断一个或者多个,返回存在的键的个数
返回值:
返回存在的键的数量,即使键不存在,也不会报错
模式: exists key [key ...]
脚本:
exists a b
4.11、type(所有类型可用)
概念: 判断值类型
返回值:
如果键存在,将返回键值,比如string、list等;如果键不存在,将返回none
模式: type key
脚本:
// 键a中存储的是string类型
type a
4.12、expire、pexpire(所有类型可用)
概念: 设置键的过期时间,其中expire设置的过期时间单位是秒,而pexpire设置的过期时间单位是毫秒
返回值:
如果键存在,将返回1;如果键不存在,将返回0
模式:
// 过期时间是秒
expire key seconds
// 过期时间是毫秒
pexpire key milliseconds
脚本:
// 设置键a的过期时间是10s
expire a 10
// 设置键a的过期时间是10000毫秒,也就是10s
pexpire a 10000
4.13、persist(所有类型可用)
概念: 设置键不过期
返回值:
如果键存在,将返回1;如果键不存在,将返回0
模式: persist key
脚本:
// 设置键a不过期
persist a
4.14、ttl、pttl(所有类型可用)
概念: ttl(获取键的存活时间,以秒为单位)、pttl(获取键的存活时间,以毫秒为单位),如果键不过期,那么将返回-1
返回值:
如果键存在,将按照单位返回键的存活时间,如果键不过期,将返回-1;如果键不存在,将返回-2
模式: ttl key、pttl key
脚本:
// 获取键a的存活时间,以秒为单位
ttl a
// 获取键a的存活时间,以毫秒为单位
pttl a
5、List使用介绍(使用redis-cli命令行操作)
5.1、简单介绍
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
常用命令汇总:
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素 LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
5.2、lpush(l:left)、rpush
概念: lpush代表从左侧往list集合中添加元素,rpush代表从右侧往list集合中添加元素
返回值:
返回添加成功的元素数量
模式: lpush key value [value ...]、rpush key value [value ...]
脚本:
// 从左侧往mylist集合中添加元素
lpush mylist 1 2 3
// 从右侧往mylist集合中添加元素
rpush mylist "hello world" 4 5
5.3、lrange(l:list)
概念: 查看范围内的集合元素;我们可以从左往右数,第一个元素下标从0开始,往后下标依次递增;也可以从右往左数,最后一个元素下标是-1,往前下标依次递减,那么从左往右看集合中倒数第二个元素的下标是-2;并且这两种下标计算方式可以混用,比如lrange 集合名称 0 -1代表查看集合中的所有元素
返回值:
如果集合中存在元素,将返回集合元素列表,例如:
1) "3"
2) "2"
3) "1"
4) "hello world"
5) "4"
6) "5"
如果集合中不存在元素,将返回提示信息,如下:
(empty list or set)
模式: lrange key start stop
脚本:
// 查看列表中的所有元素
lrange mylist 0 -1
5.4、rpop、lpop(l:left)
概念: rpop代表从右侧弹出一个元素,lpop代表从左侧弹出一个元素
返回值:
如果集合中存在元素,返回值是弹出的元素值,元素弹出之后,集合中的该元素将会被删除;如果集合不存在元素,那么返回(nil)
模式: rpop key、lpop key
脚本:
// mylist是集合名称,从集合右侧弹出元素
rpop mylist
// mylist是集合名称,从集合左侧弹出元素
lpop mylist
5.5、ltrim(说明:1、l:list;2、获取限定数量的最新数据)
概念: 删除范围之外的元素,其中范围代表集合的范围;我们可以从左往右数,第一个元素下标从0开始,往后下标依次递增;也可以从右往左数,最后一个元素下标是-1,往前下标依次递减,那么从左往右看集合中倒数第二个元素的下标是-2;并且这两种下标计算方式可以混用,确实和lrange的用法相似
返回值:
无论什么情况,都是返回OK
模式: ltrim key start stop
脚本:
// 只保留集合中下标从0到2(包括边界)的元素,其他的集合元素都将被删除
ltrim mylist 0 2
作用:
比如我们只想在集合中保留最新的10个元素,我们可以这样执行命令:
// 添加元素到集合头部
lpush mylist <some element>
// 只保留集合中的前10个最新的元素
ltrim mylist 0 9
5.6、llen(l:list)
概念: 获取集合长度
返回值:
如果集合存在,将返回集合中的元素数量;如果集合不存在,将返回0
模式: llen key
脚本:
// 获取集合名称为mylist的元素个数
llen mylist
5.7、brpop(说明:和lpush结合用作队列)、blpop(说明:1、l:left;2、不常用)
概念: 列表上的阻塞操作,可以阻塞式弹出一个元素,可以把集合当队列来用;我们使用lpush(从左边插入元素)和brpop(弹出右边的元素)组合,就可以把集合当做队列来使用,满足队列的先进先出原则,并且我们可以设置阻塞时间(单位是秒);如果阻塞时间是0,那就可以无限期阻塞,直到队列中可以弹出元素,才会结束;如果阻塞时间是正整数,在时间结束之前没有弹出元素,将返回(nil),在时间内可以弹出元素,就返回弹出的元素;如果集合中原有就有元素,那是可以立即弹出元素的;另外多个集合中只要有一个集合弹出元素,阻塞就会停止,并且会返回集合名称和弹出的元素值

返回值:
如果可以弹出元素,那就返回弹出的元素,如下:
1) "mylist1"
2) "1"
(9.44s)
如果不能弹出元素,在时间结束之间,将会一直阻塞,在时间结束的时候,将会返回(nil),如下:
(nil)
(1.02s)
模式: brpop key [key ...] timeout、blpop key [key ...] timeout
脚本:
// 不限期阻塞,从mylist或者mylist1的右侧弹出元素
brpop mylist mylist1 0
// 最多阻塞1s,从mylist左侧弹出元素
blpop mylist 1
5.8、小拓展
对于聚合类型,比如List、Streams、Sets、Sorted Sets 和 Hashes,有以下几点需要说明:
- 当我们将元素添加到聚合数据类型时,如果目标键不存在,则在添加元素之前创建一个空的聚合数据类型。
- 当我们从聚合数据类型中删除元素时,如果最终值为空,则键会自动销毁。 Stream 数据类型是此规则的唯一例外。
- 调用只读命令,例如 LLEN(返回列表的长度),或使用del命令操作不存在的聚合类型,总是返回0,就好像命令找到了空聚合类型。
综上所述: 如果操作过后,聚合类型为空,那么将删除该聚合类型;当向聚合类型中添加元素的时候,如果聚合类型不存在,那么将创建一个空的聚合类型
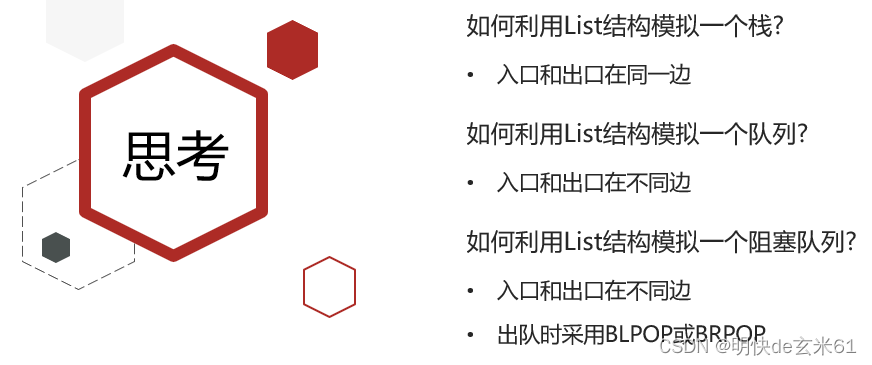
5.9、思考
6、Hash使用介绍(使用redis-cli命令行操作)
6.1、简单介绍
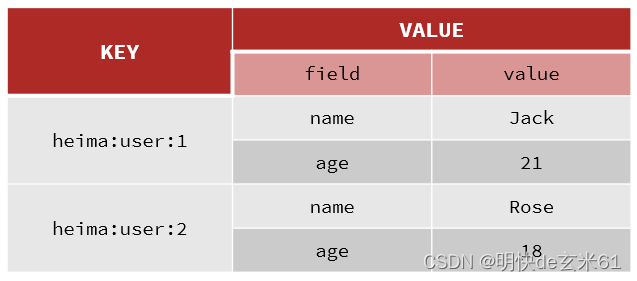
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
常用命令汇总:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field HVALS:获取一个hash类型的key中的所有的value
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
6.2、hset、hmset
概念: 设置hash中的键和值
返回值: hset(如果hash中的key之前已经存在,设置成功将返回0;如果hash中的key之前不存在,设置成功将返回1)、hmset(设置成功返回OK)
模式: hset key field value、hmset key field value [field value ...]
脚本:
// 键是user:1,设置键中的username的值是xiaoming
hset user:1 username xiaoming
// 键是user:1,设置键中的username是xiaoming,age是10
hmset user:1 username xiaoming age 10
6.3、hget、hmget、hgetall
概念: 获取hash中键对应的值
返回值:
hget(如果键存在,则返回值,如果键不存在,则返回(nil)):
hmget(如果键存在,则返回值,如果键不存在,则返回(nil))
1) "xiaoming"
2) (nil)
hgetall(返回hash中的所有键和值,其中前面的是键,后面的是值)
1) "username"
2) "xiaoming"
3) "age"
4) "10"
5) "address"
6) "china"
7) "high"
8) "2m"
模式: hget key field、hmget key field [field ...]、hgetall key
脚本:
// 键是user:1,获取username的值
hget user:1 username
// 键是user:1,获取username和age的值
hmget user:1 username age
// 键是user:1,获取所有键和值
hgetall user:1
6.4、hincrby
概念: 增加hash中键对应的值的数量
返回值: 设置之后的值
模式: hincrby key field increment
脚本:
// 年龄增加2岁
hincrby user:1 age 2
6.5、hkeys
概念: 获取hash中值键集合
返回值: hash中值键集合
1) "field1"
2) "field2"
模式: hkeys key
脚本:
// 获取用户hash的键集合
hkeys user
6.6、hvals
概念: 获取hash中所有值集合
返回值: hash中所有值集合
1) "Hello"
2) "World"
模式: hvals key
脚本:
// 获取用户hash的值集合
hvals user
6.7、hsetnx
概念: hash中键不存在才能设置成功,否则设置失败
返回值: 成功返回1,失败返回0
模式: hsetnx key field value
脚本:
// 如果用户hash中不存在键为name的情况,那么将设置name的值为“明快de玄米61”,然后返回1;如果用户hash中已经存在键为name的情况,那就就不设置,返回0
hsetnx user name "明快de玄米61"
7、Set使用介绍(使用redis-cli命令行操作)
7.1、简单介绍
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
常用命令汇总:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
- SINTER key1 key2 … :求key1与key2的交集
- SDIFF key1 key2 … :求key1与key2的差集
- SUNION key1 key2 …:求key1和key2的并集
7.2、sadd
概念: 添加元素到Set集合中
返回值: 添加成功的元素个数
模式: sadd key member [member ...]
脚本:
// 添加1和2到myset集合中
sadd myset 1 2
7.3、spop
概念: 从set结合中随机弹出特定数量的元素,弹出元素将被删除
返回值:
被弹出的元素列表,如下:
1) "1"
模式: spop key [count]
脚本:
// 从myset集合中随机弹出1个元素
spop myset 1
7.4、smembers
概念: 输出set集合中的所有元素
返回值: 集合中的所有元素列表,如下:
1) "1"
2) "2"
模式: smembers key
脚本:
// 输出myset集合中的所有元素
smembers myset
7.5、sismember
概念: 判断元素是否在set集合中
返回值: 如果元素在集合中,就返回1;如果元素不在集合中,就返回0
模式: sismember key member
脚本:
// 判断元素1是否在myset集合中
sismember myset 1
7.6、scard
概念: 查看set集合中的元素数量
返回值: set集合中的元素总数量
模式: scard key
脚本:
// 获取set集合中的元素总数量
scard myset
7.7、sunionstore
概念: 将一个或者一个以上集合的并集赋值给一个新的集合
返回值: 新集合中的元素总量
模式: sunionstore destination key [key ...]
脚本:
// 创建myset1
sadd myset1 1 2
// 创建myset2
sadd myset2 2 3
// 将myset1和myset2中的元素合并的myset3集合中
sunionstore myset3 myset1 myset2
7.8、sinter
概念: 获取一个或者多个集合的交集
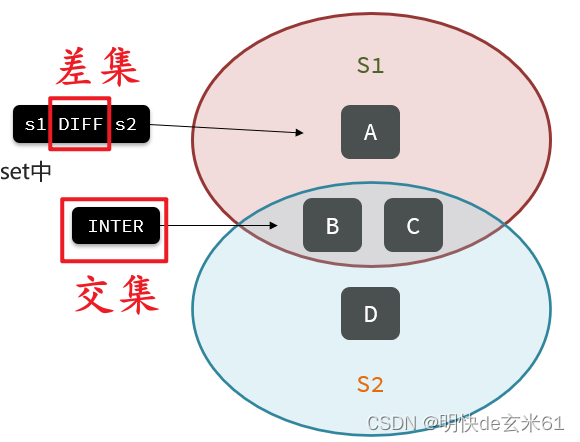
返回值: 集合交集列表,如果是单个集合,将返回该集合中的全部元素,例如sinter myset1 myset2的结果如下:
1) "2"
模式: sinter key [key ...]
脚本:
// 获取myset1和myset2的交集
sinter myset1 myset2
7.9、sdiff
概念: 获取一个或者多个集合对“第一个集合”的差集
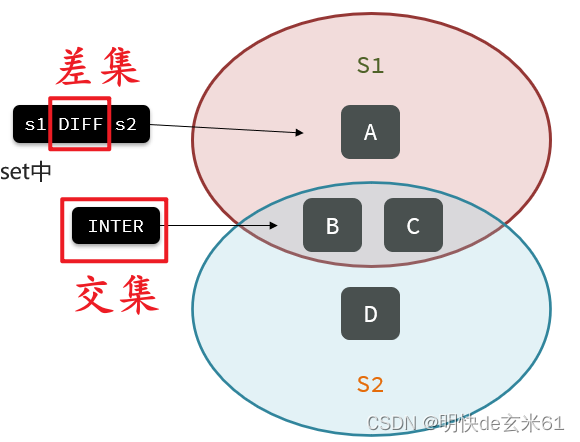
返回值: 集合差集列表,如果是单个集合,将返回空,例如sdiff myset1 myset2的结果如下:
1) "1"
模式: sdiff key [key ...]
脚本:
// 获取myset1和myset2的差集
sinter myset1 myset2
7.10、sunion
概念: 获取一个或者多个集合的并集
返回值: 集合并集列表,如果是单个集合,将返回集合总的全部元素,例如sunion myset1 myset2的结果如下:
1) "1"
2) "2"
3) "3"
模式: sunion key [key ...]
脚本:
// 获取myset1和myset2的并集
sunion myset1 myset2
7.11、srandmember
概念: 随机弹出一个或者多个集合中的元素,并且不会删除集合中的这些元素;根据count的大小不同将返回不同的结果,具体规则如下:

返回值: 如果不写count值,就返回一个元素,例如"1";如果count大于1,将返回元素列表,如下:
1) "3"
2) "2"
3) "1"
4) "3"
5) "3"
6) "2"
模式: srandmember key [count]
脚本:
// 随机返回一个元素
srandmember myset3
// 随机返回6个元素,不会重复,由于myset3中只有三个元素,所以会返回全部3个元素
srandmember myset3 6
// 随机返回6个元素,允许重复,将会返回6个元素
srandmember myset3 -6
7.12、srem
概念: 删除Set集合中的元素
返回值: 删除成功的元素个数
模式: srem key member [member ...]
脚本:
// 删除myset集合中的1和2
srem myset 1 2
8、Sorted Set(使用介绍(使用redis-cli命令行操作))
8.1、简单介绍
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
常用命令汇总:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
8.2、zadd
概念: 插入元素到排序集合中
返回值: 插入成功的元素数量
模式: zadd key [NX|XX] [CH] [INCR] score member [score member ...]
脚本:
// 其中0、1、2分别是a、b、c的分数
zadd hackers 0 a 1 b 2 c
说明:
对于NX和XX的含义可以看:https://redis.io/commands/zadd/
8.3、zrange、zrevrange
概念: zrange按照分数从大到小排序,而zrevrange按照分数从大到小排序,并且根据开始下标和结束下标来控制范围,其中的开始下标和结束下标解释如下:我们可以从左往右数,第一个元素下标从0开始,往后下标依次递增;也可以从右往左数,最后一个元素下标是-1,往前下标依次递减,那么从左往右看集合中倒数第二个元素的下标是-2;并且这两种下标计算方式可以混用
返回值: 如果不加WITHSCORES,将按照相关排序返回范围内的集合中的元素,如下:
1) "a"
2) "b"
3) "c"
如果加WITHSCORES,将按照相关排序返回范围内的集合中的元素,并且返回对应的分数,如下:
1) "a"
2) "0"
3) "b"
4) "1"
5) "c"
6) "2"
模式: zrange key start stop [WITHSCORES]、zrevrange key start stop [WITHSCORES]
脚本:
// 按照分数从小到大排序,目前获取的是集合中的全部元素
zrange hackers 0 -1
// 按照分数从小到大排序,并且添加withscores之后还会输出分数,目前获取的是集合中的全部元素
zrange hackers 0 -1 withscores
8.4、zrangebyscore、zrevrangebyscore
概念: zrangebyscore按照分数范围筛选(小分数边界在前面,大分数边界在后面,范围包括边界处的分数),然后按照分数从大到小排序,而zrevrangebyscore按照分数范围筛选(大分数边界在前面,小分数边界在后面,范围包括边界处的分数),然后按照分数从大到小排序,它们是根据分数来限制范围,而不是下标
返回值: 如果不加WITHSCORES,将按照相关分数排序后返回分数范围内的集合中的元素,如下:
1) "a"
2) "b"
3) "c"
如果加WITHSCORES,将按照相关分数排序后返回分数范围内的集合中的元素,并且返回对应的分数,如下:
1) "a"
2) "0"
3) "b"
4) "1"
5) "c"
6) "2"
模式: zrangebyscore key min max [WITHSCORES] [LIMIT offset count]、zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]
脚本:
// 按照分数范围进行筛选,其中小分数边界在前面,大分数边界在后面,范围包括边界处的分数,然后按照分数进行从小到大排序,并且输出分数
zrangebyscore hackers 1 2 withscores
// 按照分数范围进行筛选,其中大分数边界在前面,小分数边界在后面,范围包括边界处的分数,然后按照分数进行从大到小排序,并且输出分数
zrevrangebyscore hackers 2 1 withscores
8.5、zremrangebyscore
概念: 根据分数范围进行筛选之后,在删除
返回值: 删除成功的元素个数
模式: zremrangebyscore key min max
脚本:
// 根据分数删除分数范围内的集合元素,前面是小分数,后面是大分数,包括分数边界
zremrangebyscore hackers 0 1
8.6、zrank
概念: 获取元素在集合中的排行(按照分数从大到小排序),排行从0开始
返回值: 元素在集合中的排行(按照分数从大到小排序),排行从0开始
模式: zrank key member
脚本:
// 获取元素c元素在集合hackers中的排行(按照分数从大到小排序),排行从0开始
zrank hackers c
8.7、zrem
概念: 删除排序集合中的元素
返回值: 删除成功的元素数量
模式: zrem key member [member ...]
脚本:
// 其中one、two都是元素,不是分数
ZREM myzset "one" "two"
8.8、zscore
概念: 查询排序集合中的元素得分
返回值: 返回集合中的元素得分,如果该元素不存在集合中,那么返回null
模式: zscore key member
脚本:
// 其中three都是元素
zscore myzset "three"
8.9、zcard
概念: 查询排序集合中的元素个数
返回值: 返回集合中的元素个数,如果键不存在,那么返回0
模式: zcard key
脚本:
// 其中myzset是键名
zscore myzset
8.10、zcount
概念: 在查询排序集合中,返回在分数范围(包含边界值)内的元素个数
返回值: 返回分数范围内的元素个数
模式: zcount key min max
脚本:
// 其中myzset是键名,用来查找集合中分数大于等于1,并且小于等于2的元素数量
zcount myzset 1 2
8.11、zincrby
概念: 让集合中的指定元素自增,步长为指定的increment值
返回值: 集合中元素修改之后的得分
模式: zincrby key increment member
脚本:
// 其中myzset是键名,让集合中为one的元素分数值增加2分
zincrby myzset 2 one
8.12、zdiff
概念: 求差集
返回值: 关于第一个集合的差集元素集合
模式: zdiff numkeys key [key ...]
脚本:
// 其中myzset1和myzset2都是键名
zincrby myzset1 myzset2
8.13、zinter
概念: 求交集
返回值: 多个集合的交集
模式: zinter numkeys key [key ...]
脚本:
// 其中myzset1和myzset2都是键名
zinter myzset1 myzset2
8.14、zunion
概念: 求并集
返回值: 多个集合的并集
模式: zunion numkeys key [key ...]
脚本:
// 其中myzset1和myzset2都是键名
zunion myzset1 myzset2
三、环境搭建
1、windows
(1)单机版
1)下载
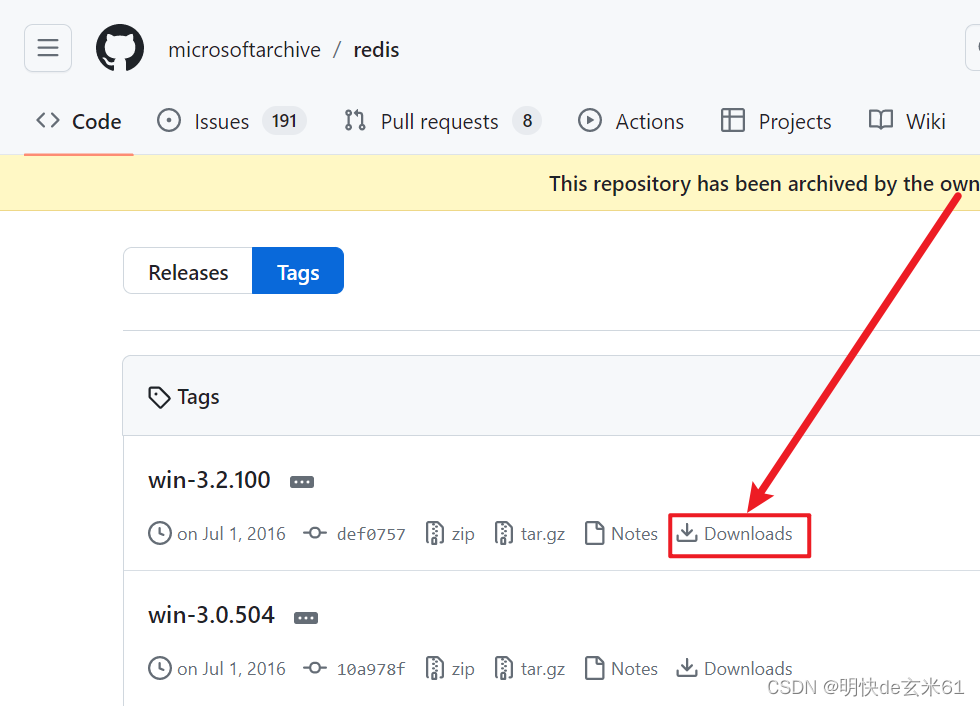
目前官方不提供windows版本的Redis,不过我们可以点击Windows版Redis来选择合适版本,然后点击Downloads按钮,如下(注意:别点下图中的zip下载,那是源码zip):
然后在里面选择zip版本进行下载,如下:
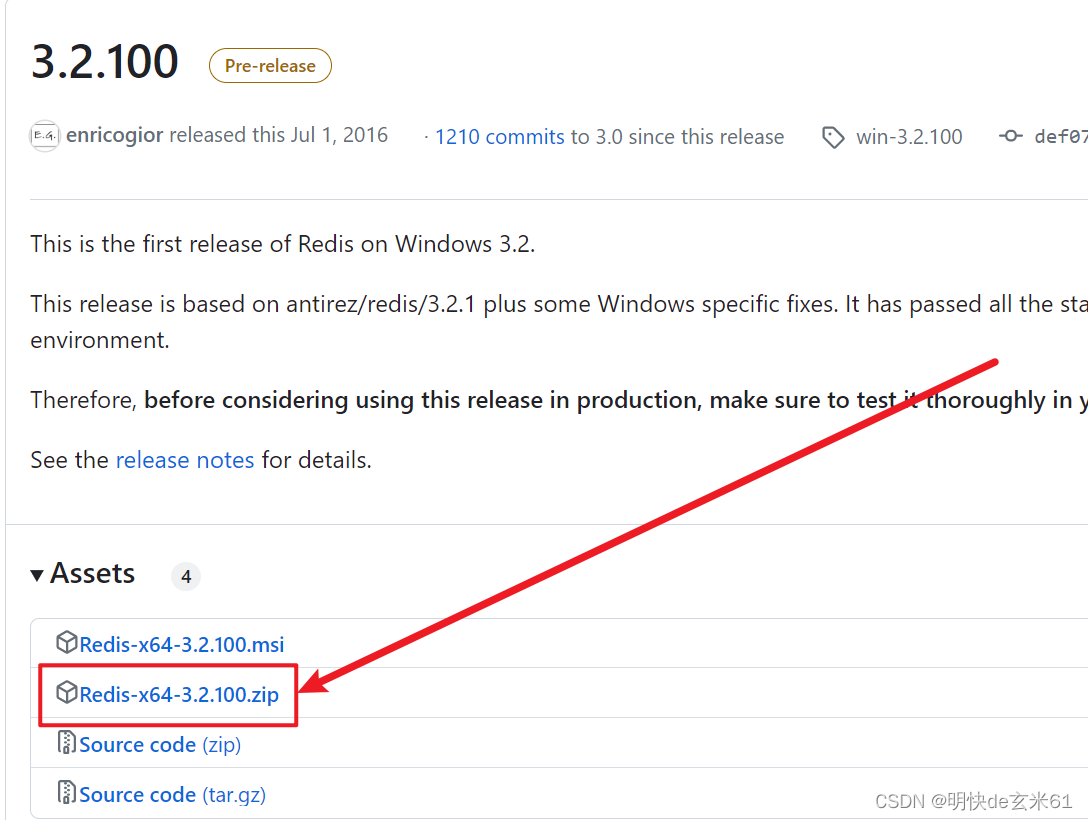
这里我给大家提供Redis-x64-3.2.100.zip安装包,如下:
链接:https://pan.baidu.com/s/1GzbARFP1cq4LjKUeXlYa_Q
提取码:zuw8
2)安装
解压即安装成功
3)启动
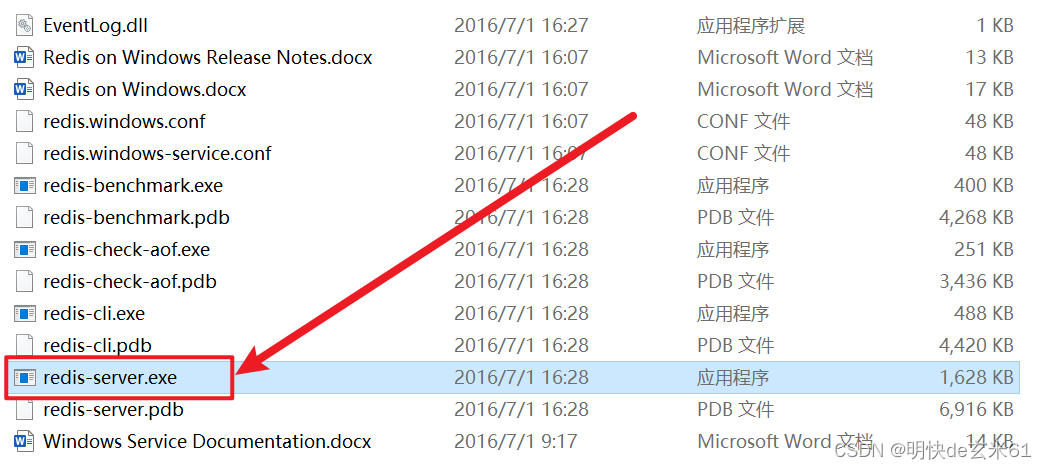
双击redis-service.exe即可启动
2、linux
(1)单机版
1)下载
首先打开Redis官网下载页面,然后选择合适的版本进行下载
下面为大家提供redis-6.2.13.tar.gz版本的安装包,如下:
链接:https://pan.baidu.com/s/1k910snMEfzbJP07uQqhOwA?pwd=1xuo
提取码:1xuo
2)安装gcc编译器
yum -y install gcc
说明: Redis是使用C语言编写的,我们使用源文件安装方式需要编译C语言源文件,所以需要安装gcc编译器
3)安装Redis
首先将redis-6.2.13.tar.gz上传到虚拟机的/usr/local/src目录下,如下:
在xshell中执行cd /usr/local/src命令进入压缩包所在目录
在上述src目录下执行tar -zxvf redis*.tar.gz命令解压安装包到当前目录,写*目的是都可以执行这些命令
在上述src目录下执行cd redis*进入解压Redis目录
在上述解压Redis目录下执行make && make install命令编译Redis源文件,如下:

等待执行成功即可
4)修改Redis配置文件
在redis解压目录中找到redis.conf文件,然后根据需要进行修改,下面我说两种情况,大家根据情况选择
情况1(推荐,安全): 设置Redis密码
-
将
bind 127.0.0.1 -::1改为bind 0.0.0.0
作用:不限制连接Redis的ip,支持Redis连接工具连接Redis -
将
daemonize no改为daemonize yes
作用:开启Redis守护模式,允许redis后台运行,所以在启动redis的时候就不用加&了 -
将
dir ./改为dir /usr/local/src/redis-6.2.13,请将/usr/local/src/redis-6.2.13替换成你自己的redis安装地址哦!
作用:首先dir的值是存储aof数据文件、rdb数据文件、日志文件的根目录,而dir ./代表redis-server命令启动的目录就是dir目录,由于redis-server的位置是/usr/local/bin/redis-server,所以/usr/local/bin就是根目录,这样放置数据文件不好,所以把dir的值修改成特定位置 -
将
logfile ""改为logfile "redis.log"
作用:设置Redis日志文件名称,用来存储日志信息,然后该日志文件将会存储在redis.conf配置文件中dir目录下 -
将
# requirepass foobared改为requirepass admin123456
作用:设置Redis连接密码,其中admin123456就是我的连接密码,大家可以替换成自己的 -
将
appendonly no改成appendonly yes
作用:Redis数据持久化
情况2(不推荐,不安全): 不设置Redis密码
-
将
bind 127.0.0.1 -::1改为bind 0.0.0.0
作用:不限制连接Redis的ip,支持Redis连接工具连接Redis -
将
protected-mode yes改为protected-mode no
作用:取消Redis保护模式,可以不设置密码登录,记得一定把配置中对requirepass的密码设置那一行注释,不然密码还是会起效的 -
将
daemonize no改为daemonize yes
作用:开启Redis守护模式,允许redis后台运行,所以在启动redis的时候就不用加&了 -
将
dir ./改为dir /usr/local/src/redis-6.2.13,请将/usr/local/src/redis-6.2.13替换成你自己的redis安装地址哦!
作用:首先dir的值是存储aof数据文件、rdb数据文件、日志文件的根目录,而dir ./代表redis-server命令启动的目录就是dir目录,由于redis-server的位置是/usr/local/bin/redis-server,所以/usr/local/bin就是Redis数据文件存储的dir根目录,这样放置数据文件不好,所以把dir的值修改成特定位置 -
将
logfile ""改为logfile "redis.log"
作用:设置Redis日志文件名称,用来存储日志信息,然后该日志文件将会存储在redis.conf配置文件中dir目录下 -
将
appendonly no改成appendonly yes
作用:Redis数据持久化
5)启动Redis
# 通过cd命令进入redis解压目录下,然后执行以下命令,主要是用到修改之后的redis.conf配置文件
redis-server redis.conf
6)关闭Redis
情况1: Redis有密码
我们在虚拟机中执行redis-cli -a 密码命令,比如redis-cli -a admin123456就可以登录redis客户端控制台,然后输入shutdown回车即可关闭Redis,之后Ctrl+C退出Redis客户端就可以了
情况2: Redis没有密码
我们在虚拟机中执行redis-cli命令就可以登录redis客户端控制台,然后输入shutdown回车即可关闭Redis,之后Ctrl+C退出Redis客户端就可以了
7)拓展:启动、停止方式1
执行命令打开并新建配置文件,文件名称是应用名称,可以用作快捷调用,后缀是固定的service
vim /lib/systemd/system/redis.service
然后粘贴以下内容到上述文件中并保存,注意修改你的启动命令,也就是ExecStart后面的值
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.13/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
- Description:描述信息,没啥作用,根据文件作用做修改
- ExecStart:启动命令,对于
Reids来说,编译Redis源码之后就会在/usr/local/bin/目录下生成对应启动脚本文件,所以启动脚本文件用这个也是ok的
执行以下命令重启系统服务(不会重启虚拟机):
systemctl daemon-reload
可以通过如下命令对Redis执行操作:
# 说明:虽然文件名称是redis.service,但是执行命令时可以省略.service
# 运行Redis
systemctl start redis
# 停止Redis
systemctl stop redis
# 重启Redis
systemctl restart redis
# 查看Redis运行状态
systemctl status redis
# Redis开机自启
systemctl enable redis
# 关闭Redis开机自启
systemctl disable redis
8)拓展:停止方式2
执行
ps -ef | grep redis
找到redis进程,然后执行
kill -9 Redis进程号
来关闭Redis
9)拓展:Redis自带客户端使用方式
# 连接方式:
# 1、有密码
redis-cli -a 密码
# 2、需要指定redis端口,并且有密码
redis-cli -p 端口 -a 密码
# 3、连接Redis主从分片集群
# 说明:如果不添加-c,那就不是以集群方式连接到客户的,按照这种情况来说,由于Redis主节点只存储一部分数据,当执行添加键值操作的时候,而有些数据的hash值不在当前节点可接受范围内,那么就需要存储到其他节点,对于这种无法存储的情况会报错的。如果添加-c,那就是以集群方式连接到客户的,这样即使出现了上面的情况,集群会把添加键值的请求转发到其他节点。
redis-cli -c -p 端口 -a 密码
# 客户端命令
# 1、查看集群副本信息
info replication
(2)哨兵版
1)下载
2)安装gcc编译器
3)安装Redis
请参考上述安装Linux单机版本中的前3步,由于我在自己笔记本上搭建集群,所以就使用一台虚拟机,但是Redis端口不同呢,利用这种方式来模拟Redis哨兵集群搭建的过程
4)搭建Redis主从副本集群
根据上述安装步骤,Redis依然安装在/usr/local/src/redis-6.2.13目录下面
首先我们创建三个目录来存储Redis主从集群配置文件redis.conf
mkdir -p /usr/local/src/redisMasterSlaveCluster/6001
mkdir -p /usr/local/src/redisMasterSlaveCluster/6002
mkdir -p /usr/local/src/redisMasterSlaveCluster/6003
创建完成如下图:
然后把/usr/local/src/redis-6.2.13目录下的原始redis.conf文件分别复制到上述6001、6002、6003目录下,我们来规划主节点和从节点,其中端口6001为主节点,而6002和6003为从节点,然后按照下面要求进行配置文件的修改
说明:下面没有做特殊说明的,那就是主、从节点都需要做修改
-
将
port 6379改为port 节点端口号
作用:修改redis端口号,由于6001、6002、6003目录下都存在redis.conf,那就把目录名称当做端口号来执行修改操作 -
将
bind 127.0.0.1 -::1改为bind 0.0.0.0
作用:不限制连接Redis的ip,支持Redis连接工具连接Redis -
将
daemonize no改为daemonize yes
作用:开启Redis守护模式,允许redis后台运行,所以在启动redis的时候就不用加&了 -
将
dir ./改为dir 6001、6002、6003目录全路径,比如:6001目录下的redis.conf中就需要将dir ./改为dir "/usr/local/src/redisMasterSlaveCluster/6001"
作用:首先dir的值是存储aof数据文件、rdb数据文件、日志文件的根目录,而dir ./代表redis-server命令启动的目录就是dir目录,由于redis-server的位置是/usr/local/bin/redis-server,所以/usr/local/bin就是根目录,这样放置数据文件不好,所以把dir的值修改成特定位置 -
将
logfile ""改为logfile "redis.log"
作用:设置Redis日志文件名称,用来存储日志信息,然后该日志文件将会存储在redis.conf配置文件中dir目录下 -
将
# requirepass foobared改为requirepass admin123456
作用:设置Redis连接密码,其中admin123456就是我的连接密码,大家可以替换成自己的 -
将
# masterauth <master-password>替换成masterauth "admin123456"
作用:设置连接主节点密码,我会把Redis节点密码都设置成admin123456,所以在哨兵模式下,即使出现故障的时候,无论哪个节点成为了主节点,其他从节点都是可以连接上主节点的 -
将
appendonly no改成appendonly yes
作用:Redis数据持久化 -
(只要求从节点执行,目前是6002和6003节点)将
# replicaof <masterip> <masterport>替换成replicaof 192.168.56.10 6001
作用:从节点要连接上主节点,那就需要知道主节点的ip和port信息,这就是用来指定主节点的连接信息的,其中192.168.56.10是主节点所在虚拟机ip,而6001主节点Redis端口
现在就把主从集群准备好了,我们可以通过执行命令redis-server redis.conf全路径来依次启动主节点(端口为6001的节点)和从节点(端口分别为6002和6003的节点),例如具体命令如下
# 1、启动主节点
redis-server /usr/local/src/redisMasterSlaveCluster/6001/redis.conf
# 2、启动6002从节点
redis-server /usr/local/src/redisMasterSlaveCluster/6002/redis.conf
# 3、启动6003从节点
redis-server /usr/local/src/redisMasterSlaveCluster/6003/redis.conf
现在我们就把一主二从的Redis主从副本集群搭建成功了。
对于搭建成功的主从集群,我们介绍一下它的特点:
- 主节点
支持读写,但是从节点只支持读。大家可以通过redis-cli -p 端口 -a 密码连接Redis本地客户端去尝试,也可以通过Redis远程客户端去尝试 - 无法自动完成故障转移。如果主节点挂掉,从节点只会无限尝试连接主节点,这个过程可以从6002和6003从节点的日志中看到
正是由于Redis主从副本集群无法完成故障转移,所以我们需要Redis哨兵集群来帮助完成自动故障转移
5)搭建Redis哨兵集群
首先我们创建三个目录来存储Redis哨兵集群配置文件sentinel.conf
mkdir -p /usr/local/src/redisSentinel/7001
mkdir -p /usr/local/src/redisSentinel/7002
mkdir -p /usr/local/src/redisSentinel/7003
创建完成如下图:
然后把/usr/local/src/redis-6.2.13目录下的原始sentinel.conf文件分别复制到上述7001、7002、7003目录下,之后按照下面要求进行配置文件的修改
-
将
port 26379改为port 哨兵节点端口号
作用:修改redis哨兵端口号,由于7001、7002、7003目录下都存在sentinel.conf,那就把目录名称当做端口号来执行修改操作 -
将
daemonize no改为daemonize yes
作用:开启守护模式,允许redis哨兵后台运行,所以在启动redis哨兵的时候就不用加&了 -
将
dir ./改为dir 7001、7002、7003目录全路径,比如:7001目录下的redis.conf中就需要将dir ./改为dir "/usr/local/src/redisSentinel/7001"
作用:首先dir的值是存储日志文件的根目录,而dir ./代表redis-sentinel命令启动的目录就是dir目录,由于redis-sentinel的位置是/usr/local/bin/redis-sentinel,所以/usr/local/bin就是根目录,这样放置数据文件不好,所以把dir的值修改成特定位置 -
将
logfile ""改为logfile "sentinel.log"
作用:设置Redis哨兵日志文件名称,用来存储日志信息,然后该日志文件将会存储在sentinel.conf配置文件中dir目录下 -
将
# sentinel monitor <master-name> <ip> <redis-port> <quorum>替换成sentinel monitor mymaster 192.168.56.10 6001 2
作用:Redis哨兵存在的意义就是监听我们上面搭建的Redis主从副本集群,由于所有信息都可以通过主节点获取到,所以在哨兵配置文件sentinel.conf中需要配置redis主节点连接信息,其中mymaster是主节点名称,这是我们自己定义的,192.168.56.10是Redis主节点ip,6001是Redis主节点端口,2表示当有两个哨兵节点认为节点无法连接,那就需要让节点下线 -
将
# sentinel auth-pass <master-name> <password>改成sentinel auth-pass mymaster admin123456
作用:由于Redis主节点设置了连接密码,所以我们需要指定Redis连接密码才能让Redis哨兵连接上Redis主节点,其中admin123456就是我的Redis主节点密码 -
将
sentinel down-after-milliseconds mymaster 30000改成sentinel down-after-milliseconds mymaster 5000
作用:设置Redis哨兵节点和Redis节点连接的最大中断时间,现在的设置是最多5s连接不上某节点,那就说明该节点下线了
现在就把Redis哨兵集群准备好了,我们可以通过执行命令redis-sentinel sentinel.conf全路径来依次启动端口为7001、7002、7003的三个Redis哨兵节点,例如具体命令如下
# 1、启动7001哨兵节点
redis-sentinel /usr/local/src/redisSentinel/7001/sentinel.conf
# 2、启动7002哨兵节点
redis-sentinel /usr/local/src/redisSentinel/7002/sentinel.conf
# 3、启动7003哨兵节点
redis-sentinel /usr/local/src/redisSentinel/7003/sentinel.conf
现在我们就把一个主节点(端口:6001)、两个从节点(端口:6002、6003)、三个哨兵节点(端口:7001、7002、7003)的Redis哨兵集群搭建成功了。
上面Redis主从副本集群无法实现自动故障转移,但是Redis哨兵集群可以,假设此时我们把Redis6001主节点关闭,那么Redis哨兵集群会发现该变化,然后将剩余的Redis从节点提升为主节点,并且完成其他从节点对主节点的监听功能。如果此时Redis6001节点完成了手动故障恢复,它此时会以从节点的身份加入Redis集群,这就实现了自动故障转移。
我们聊一下在Redis主从副本集群的基础上引入Redis哨兵集群的目的,引入哨兵就是为了解决Redis主节点宕机导致集群整体无法使用的问题,所以即使我们在代码中连接的是Redis哨兵集群,但是集群本质没有改变,依然是Redis主节点支持读写,但是从节点只支持读的状态
(3)分片版
上面介绍了Redis哨兵集群,但是哨兵集群有一个很大的问题是写能力受限,毕竟只有一个节点支持写操作,其他节点都只支持读操作。另外一个问题是Redis哨兵集群所有节点都存储全量数据,但是再好的机器也顶不住纵向扩容呀,所以很有可能出现空间不够用的情况。而我们Redis分片集群就能解决这些问题,并且依然支持数据副本备份、自动故障转移的能力
这种分片类似于Elasticsearch分片方式,我们下面来搭建一个三主三从的Redis分片集群,拓扑图如下:
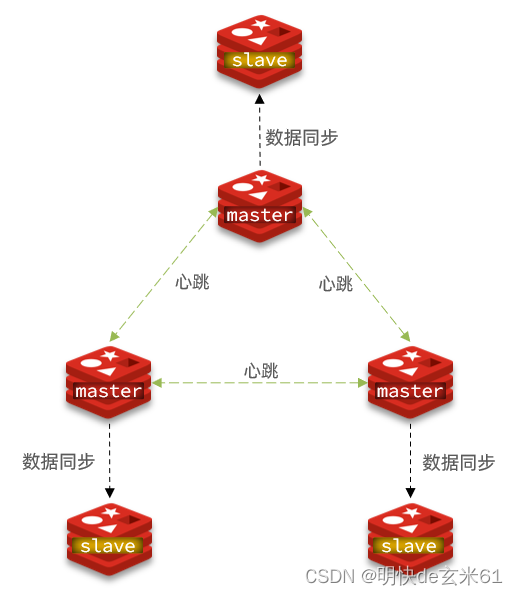
1)下载
2)安装gcc编译器
3)安装Redis
请参考上述安装Linux单机版本中的前3步,由于我在自己笔记本上搭建集群,所以就使用一台虚拟机,但是Redis端口不同呢,利用这种方式来模拟Redis哨兵集群搭建的过程
4)准备Redis节点
根据上述安装步骤,Redis依然安装在/usr/local/src/redis-6.2.13目录下面
首先我们创建6个目录来存储Redis分片集群配置文件redis.conf
mkdir -p /usr/local/src/redisShardedCluster/8001
mkdir -p /usr/local/src/redisShardedCluster/8002
mkdir -p /usr/local/src/redisShardedCluster/8003
mkdir -p /usr/local/src/redisShardedCluster/8004
mkdir -p /usr/local/src/redisShardedCluster/8005
mkdir -p /usr/local/src/redisShardedCluster/8006
创建完成如下图:
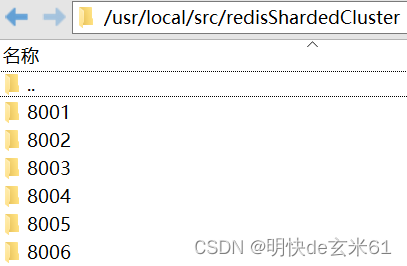
然后把/usr/local/src/redis-6.2.13目录下的原始redis.conf文件分别复制到上述8001、8002、8003、8004、8005、8006目录下,然后按照下面要求进行配置文件的修改
-
将
port 6379改为port 节点端口号
作用:修改redis端口号,由于8001、8002、8003、8004、8005、8006目录下都存在redis.conf,那就把目录名称当做端口号来执行修改操作 -
将
bind 127.0.0.1 -::1改为bind 0.0.0.0
作用:不限制连接Redis的ip,支持Redis连接工具连接Redis -
将
daemonize no改为daemonize yes
作用:开启Redis守护模式,允许redis后台运行,所以在启动redis的时候就不用加&了 -
将
dir ./改为dir 8001、8002、8003、8004、8005、8006目录全路径,比如:8001目录下的redis.conf中就需要将dir ./改为dir "/usr/local/src/redisShardedCluster/8001"
作用:首先dir的值是存储aof数据文件、rdb数据文件、日志文件的根目录,而dir ./代表redis-server命令启动的目录就是dir目录,由于redis-server的位置是/usr/local/bin/redis-server,所以/usr/local/bin就是根目录,这样放置数据文件不好,所以把dir的值修改成特定位置 -
将
logfile ""改为logfile "redis.log"
作用:设置Redis日志文件名称,用来存储日志信息,然后该日志文件将会存储在redis.conf配置文件中dir目录下 -
将
# requirepass foobared改为requirepass admin123456
作用:设置Redis连接密码,其中admin123456就是我的连接密码,大家可以替换成自己的 -
将
# masterauth <master-password>替换成masterauth "admin123456"
作用:设置连接主节点密码,我会把Redis节点密码都设置成admin123456,所以在分片集群模式下,即使出现故障的时候,无论哪个节点成为了主节点,其他从节点都是可以连接上主节点的 -
将
appendonly no改成appendonly yes
作用:Redis数据持久化 -
将
pidfile /var/run/redis_6379.pid改成pidfile /var/run/redis_cluster.pid
作用:这个文件的作用我还没有探究清晰,但是都用这个名称不太好,还是换一个吧 -
将
# cluster-enabled yes改成cluster-enabled yes
作用:开启Redis分片集群模式 -
将
# cluster-config-file nodes-6379.conf改成cluster-config-file node-cluster.conf
作用:Redis分片集群使用该conf文件存储集群自身所需的数据,我们只需要设置名称即可,集群会自动创建,不需要我们管它 -
将
# cluster-node-timeout 15000改成cluster-node-timeout 5000
作用:如果集群主节点之间超过5s没有通信,那么从节点将会变成主节点,通过主从切换来完成自动故障转移
现在就把主从集群准备好了,我们可以通过执行命令redis-server redis.conf全路径来依次启动8001、8002、8003、8004、8005、8006节点,具体命令如下
redis-server /usr/local/src/redisShardedCluster/8001/redis.conf
redis-server /usr/local/src/redisShardedCluster/8002/redis.conf
redis-server /usr/local/src/redisShardedCluster/8003/redis.conf
redis-server /usr/local/src/redisShardedCluster/8004/redis.conf
redis-server /usr/local/src/redisShardedCluster/8005/redis.conf
redis-server /usr/local/src/redisShardedCluster/8006/redis.conf
5)创建Redis集群
虽然上面已经把Redis节点准备好了,但是节点之间是无法互通的,所以我们需要创建集群,执行如下命令即可:
redis-cli --cluster create --cluster-replicas 1 192.168.56.10:8001 192.168.56.10:8002 192.168.56.10:8003 192.168.56.10:8004 192.168.56.10:8005 192.168.56.10:8006 -a admin123456
解释一下:
--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1) 得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master- 6个ip:port:这是上述创建的6个Redis节点的ip和port
- -a admin123456:由于Redis节点有密码,所以需要填写密码
上述命令执行完成之后,还需要我们输入yes并回车,我们照做就是,然后集群就创建完成了
上面我们提到Redis分片集群解决了节点数据写入能力不够的问题,现在搭建的是一个三主三从节点,所以有三个主节点可以用了数据写入,所以节点数据写入能力得到了大大提升。
上面我们还提到Redis分片集群可以解决纵向扩容的问题,现在三个主节点中存储的部分数据,而不是全量数据,相当于把全部数据分成了三个地方存储,并且从节点可以为对应主节点提供副本能力,这样横向扩容和数据安全都保障了
上面我们还提到Redis分片集群依然支持自动故障转移的功能,由于每一个主节点目前都有一个从节点,所以即使主节点挂了,那么从节点会被提升为主节点,从而实现自动故障转移
3、docker
(1)单机版
// 拉取镜像
docker pull redis:6.0.8
// 创建redis.conf所属的目录
mkdir /docker/reids/conf
// 将以下链接中的redis.conf文件复制到conf目录下
链接:https://pan.baidu.com/s/1OLPyYh0NcwmXlHIKhFr3dQ?pwd=oq8y
更改参数说明:1、开启密码验证,搜索“requirepass”可见;2、注释“bind 127.0.0.1”,允许外部连接;3、设置“daemonize no”,避免和docker run中-d参数冲突,导致容器启动失败;4、设置“appendonly yes ”,开启容器持久化
// 创建容器
docker run -d -p 6379:6379 --privileged=true --name="redis6.0.8" -v /docker/redis/conf/redis.conf:/etc/redis/redis.conf -v /docker/redis/data:/data redis:6.0.8 redis-server /etc/redis/redis.conf
说明:redis-server /etc/redis/redis.conf代表在redis-server启动的时候使用/etc/redis/redis.conf
// 进入容器
docker exec -it redis6.0.8 /bin/bash
4、k8s
(1)单机版
apiVersion: v1
kind: ConfigMap
metadata:
name: redis.conf
namespace: redis
data:
redis.conf: |-
protected-mode no
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize no
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile ""
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100
requirepass admin123456
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events Ex
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: redis
name: redis
namespace: redis
spec:
replicas: 1
selector:
matchLabels:
app: redis
serviceName: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- command:
- redis-server
- /etc/redis/redis.conf
image: 'redis:6.2.6'
imagePullPolicy: IfNotPresent
name: redis
ports:
- containerPort: 6379
name: client
protocol: TCP
- containerPort: 16379
name: gossip
protocol: TCP
volumeMounts:
- mountPath: /data
name: redis-data
- mountPath: /etc/redis/
name: redis-conf
volumes:
- configMap:
name: redis.conf
name: redis-conf
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes:
- ReadWriteMany
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 100Mi
---
apiVersion: v1
kind: Service
metadata:
labels:
app: redis
name: redis
namespace: redis
spec:
ports:
- name: client
port: 6379
protocol: TCP
targetPort: 6379
- name: gossip
port: 16379
protocol: TCP
targetPort: 16379
selector:
app: redis
type: NodePort
5、Redis连接工具
(1)RedisDesktopManager
点击RedisDesktopManager-Windows,然后找到合适版本,点击Downloads按钮,如下:
然后下载resp-XXX.zip即可,如下:
我给大家提供resp-2022.5.0.0.exe安装包,如下:
链接:https://pan.baidu.com/s/1MpAVdolmV4z5WPWuDxtn0A?pwd=3eui
提取码:3eui
四、代码
链接:https://pan.baidu.com/s/1manMY7Rm3-ueELqdQR9S9g?pwd=qjyd
提取码:qjyd
五、文档
链接:https://pan.baidu.com/s/1Bt9x4QdmNJJATEPyZDUQ4Q?pwd=82se
提取码:82se