Stabel Diffusion是由CompVis、stabel AI和LAION的研究人员和工程师创建的文本到图像的潜在扩散模型。它由来自LAION-5B数据库子集的512x512图像进行训练。LAION-5B是目前最大的、可自由访问的多模态数据集。
在这篇文章中,将介绍如何使用diffusion库实现Stabel Diffusion模型生成图像,并讲解Stabel Diffusion的工作原理,最后深入了解diffusion如何允许用户自定义图像生成管道。
如何有需要了解Diffusion原理的可以参考下面这篇博客
Diffusion Model算法
也可以在线实现stabel Diffusion模型,地址如下
https://huggingface.co/spaces/stabilityai/stable-diffusion
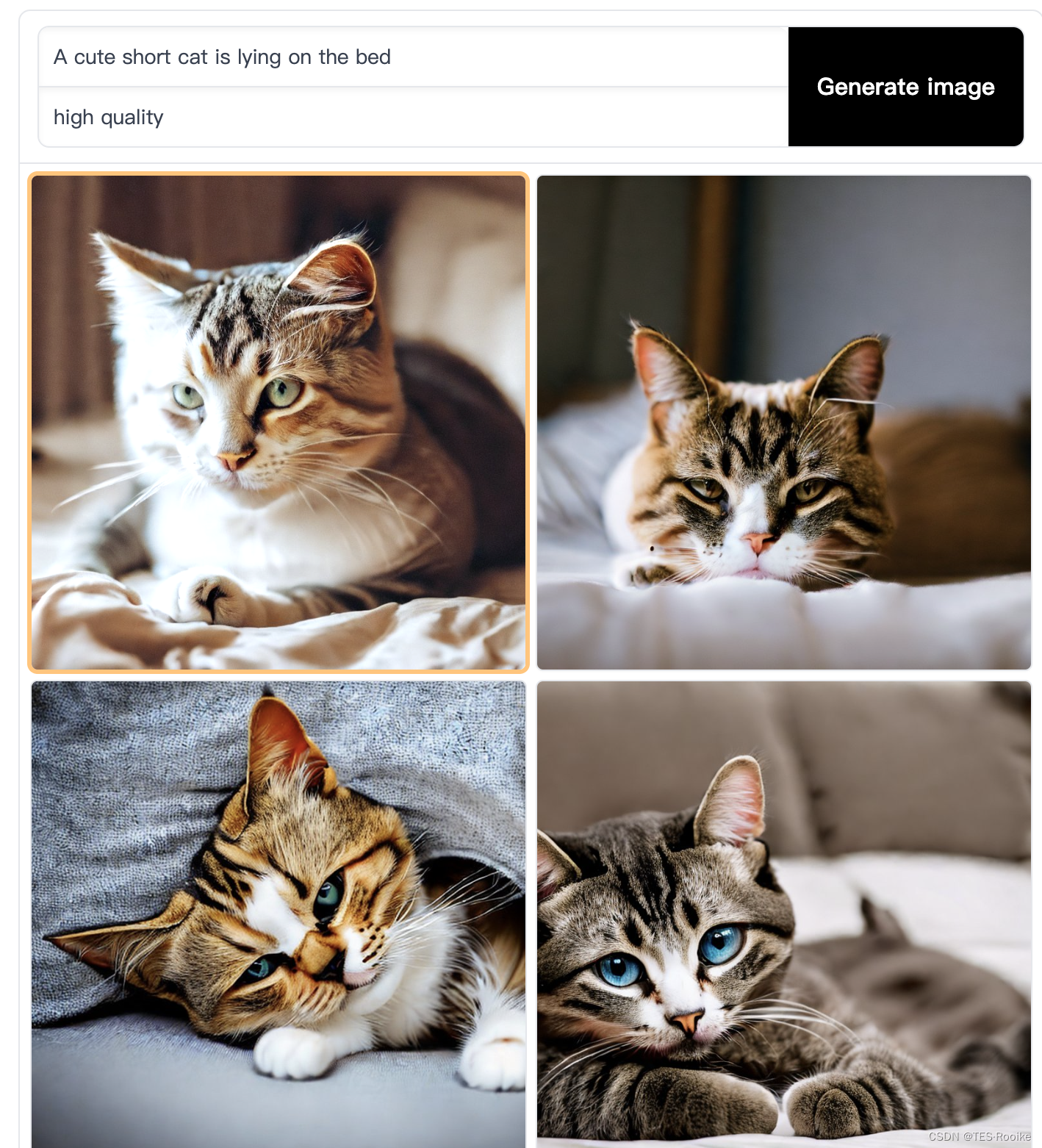
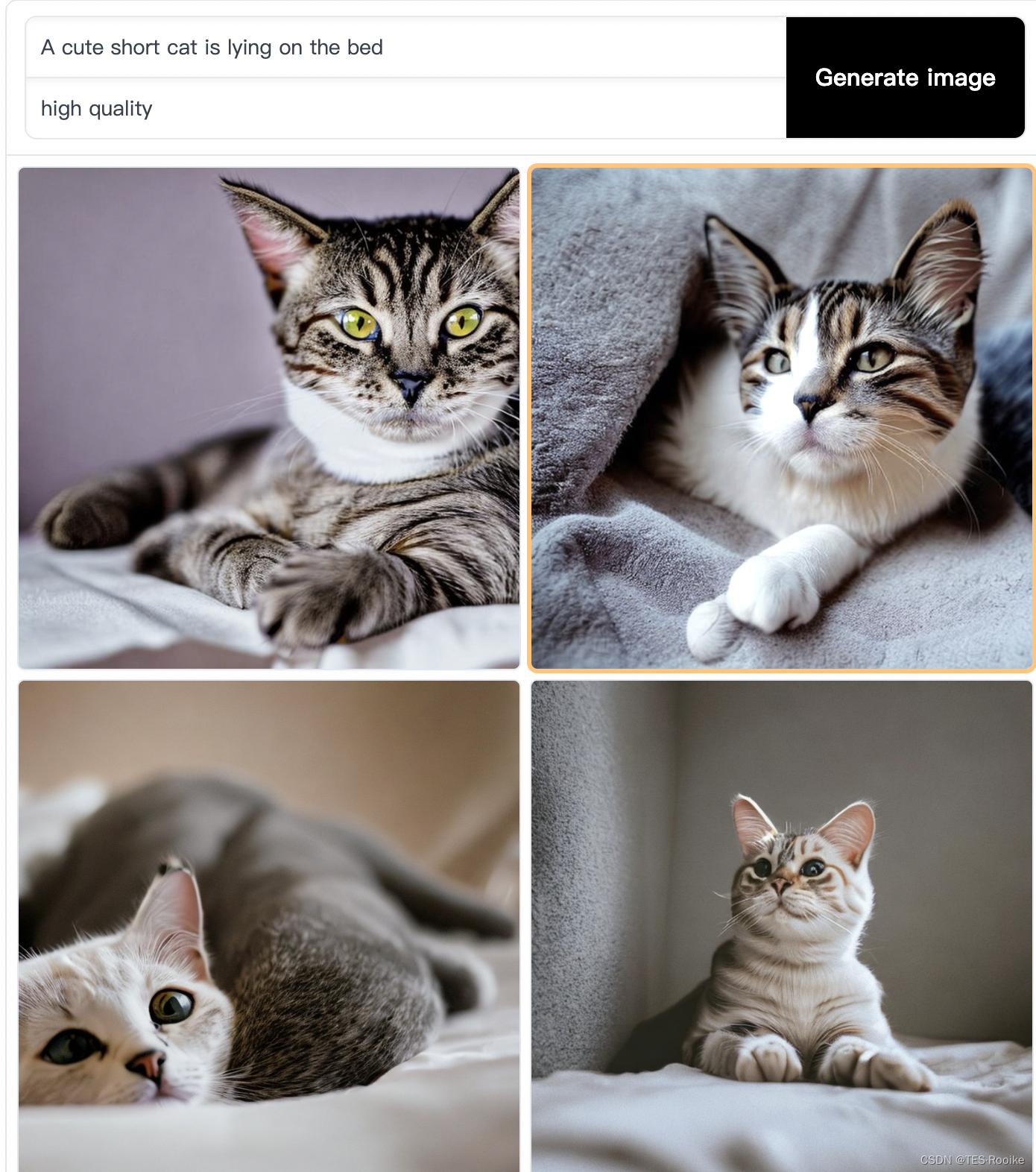
在输入框的第一行就是输入的text图像描述,第二行算是是生成图像模型的迭代时间,迭代时间越长图像质量画质越高,应该是分成三档(high quality,mid quality,low quality),也可以自己设置迭代次数
💰可以用来做自己的图片素材了,发家致富了!💰
使用Stabel Diffusion
- 如何运行Stabel Diffusion生成图像
- 安装
- 使用
- seed
- num_inference_steps
- guidance_scale
- Latent diffusion算法原理
- 自动编码器(VAE)
- U-Net
- 文本编码器
- 自定义Stabel Diffusion
如何运行Stabel Diffusion生成图像
在使用模型前,我们需要先获取模型的许可证,这样才能下载模型的参数和权重
许可证地址:https://huggingface.co/spaces/CompVis/stable-diffusion-license
安装
首先,安装 diffusers==0.10.2 运行以下代码片段:
pip install diffusers==0.10.2 transformers scipy ftfy accelerate
在这篇文章中,我们将使用模型版本v1-4,但您也可以使用模型的其他版本,如1.5、2和2.1,只需对代码进行少量更改。
使用 StableDiffusionPipeline 管道,只需几行代码即可在推理中运行Stabel Diffusion模型。
StableDiffusionPipeline是一个集成了大量函数的模型代码脚本,代码网站如下
https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
使用
我们只需要调用加载这个模块,就可以调用diffusion下面的函数,如下
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
如果要使用GPU增加一行
pipe.to("cuda")
注意:如果您受到 GPU 内存的限制并且可用的 GPU RAM 少于 10GB,请确保模型权重的值是 float16 精度而不是python默认 float32 精度加载
如何设置权重精度,可以通过从 fp16 分支加载权重并告诉扩散器期望权重为 float16 精度来做到这一点:
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
给模型一个提示(也就是图像的文字描述),运行管道生成出图像
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# image.save(f"astronaut_rides_horse.png")

每次运行之前的代码都会给你一个不同的图像。
如果在某个时候你得到一个黑色图像,可能是因为模型中内置的内容过滤器可能检测到 NSFW 结果,可以不妨输出你的pipe(prompt)结果
result = pipe(prompt)
print(result)
{
'images': [<PIL.Image.Image image mode=RGB size=512x512>],
'nsfw_content_detected': [False]
}
seed
如果您想要同一个文本提示,输出几次,都是同一图像,您可以设置一个随机种子类似于random.seed()的原理,并将生成器传递给管道。每次使用具有相同种子的生成器时,都会得到相同的图像输出。
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# image.save(f"astronaut_rides_horse.png")

num_inference_steps
您可以使用 num_inference_steps 参数更改模型推理的步数
一般来说,使用的步数越多,结果越好,但是步数越多,建议使用默认的推理步数 50。如果您想要更快的结果,可以使用较小的步数。如果您想要更高质量图像,您可以使用更大数字的步数。
这里使用一个小的step来生成图像看下
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator).images[0]
# image.save(f"astronaut_rides_horse.png")

对比图像发现,图像的内容和结构基本是一致的,但是宇航员和马的一些形状细节存在很多不同,这表明num_inference_steps=15的去噪步骤,提到的图像质量相对较低,通常使用50次去噪步骤,足以得到一个高质量图像。
guidance_scale
除了num_inference_steps之外,我们还使用了另一个函数参数,
在前面的所有示例中称为guidance_scale。guidance_scale是一种增加对指导生成(在本例中为文本)以及总体样本质量的条件信号的依从性的方法。它也被称为无分类器引导,简单地说,调整它可以更好的使用图像质量更好或更具备多样性。值介于7和8.5之间通常是稳定扩散的好选择。默认情况下,管道使用的guidance_scale为7.5。
- 如果值很大, 图像质量可能更好,但对应的多样性会降低
- 如果值很小, 图像质量可能更差,但对应的多样性会增加
默认情况下,稳定扩散生成512×512像素的图像。使用height和width参数以纵向或横向比例创建矩形图像非常容易出现缩放比例错误,部分图像内容,未展示出来,被覆盖了(这是因为你的图像内容大小大于你设置的图像尺寸大小了)
最好在设置height和width参数,值为8的倍数
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
# image.save(f"astronaut_rides_horse.png")

Latent diffusion算法原理
对于基础的Diffusion模型,虽然已实现生成图像数据的功能。但扩散模型的一个缺点是,反向去噪过程很慢,因为它具有重复、连续的性质。此外,这些模型消耗大量内存,因为它们在像素空间中运行,在生成高分辨率图像时,像素空间会变得巨大。因此,训练这些模型并将其用于推理是具有挑战性的。
而Latent diffusion模型可以通过在较低维度的潜在空间上应用扩散过程,而不是使用实际的像素空间,潜在扩散可以减少存储器和计算复杂性。这是标准扩散和潜在扩散模型之间的关键区别:在潜在扩散中,模型被训练以生成图像的潜在(压缩)表示。
潜在扩散有三个主要成分。
- 自动编码器(VAE)。
- U Net。
- 文本编码器,例如CLIP的文本编码器。
自动编码器(VAE)
VAE模型有两个部分,一个编码器和一个解码器。Encoder用于将图像转换为低维潜在表示,这将在反向扩散,推理过程作为U-Net模型的输入。相反,解码器将潜在表示转换回图像。
在潜在扩散训练期间,编码器用于获得前向扩散过程的图像的潜在表示(潜伏期),该过程在每个步骤施加越来越多的噪声。在推断过程中,使用VAE Decoder将反向扩散过程生成的去噪延迟转换回图像。正如我们将在推断过程中看到的,我们只需要VAE解码器。
U-Net
U-Net具有编码器部分和解码器部分,两者都由ResNet块组成。编码器将图像表示压缩成较低分辨率的图像表示,并且解码器将较低分辨率图像表示解码回原始的较高分辨率图像表示。更具体点,U-Net输出的预测可用于计算预测的去噪图像表示的噪声残差。
为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样ResNet和解码器的上采样ResNet之间添加捷径连接。此外,Stabel Diffusion中U-Net能够通过交叉注意力层在文本embedding上调节并输出。交叉关注层被添加到U-Net的编码器和解码器部分,通常在ResNet块之间。
文本编码器
文本编码器负责将输入提示(例如“宇航员骑马”)转换为U-Net可以理解的embedding空间。它通常是一个简单的基于变换器的编码器,它将输入的文本序列映射到潜在文本embedding的序列上。
受Imagen启发,Stable Diffusion在训练期间不训练文本编码器,而是直接使用CLIP已经训练过的文本编码器,CLIPTextModel。
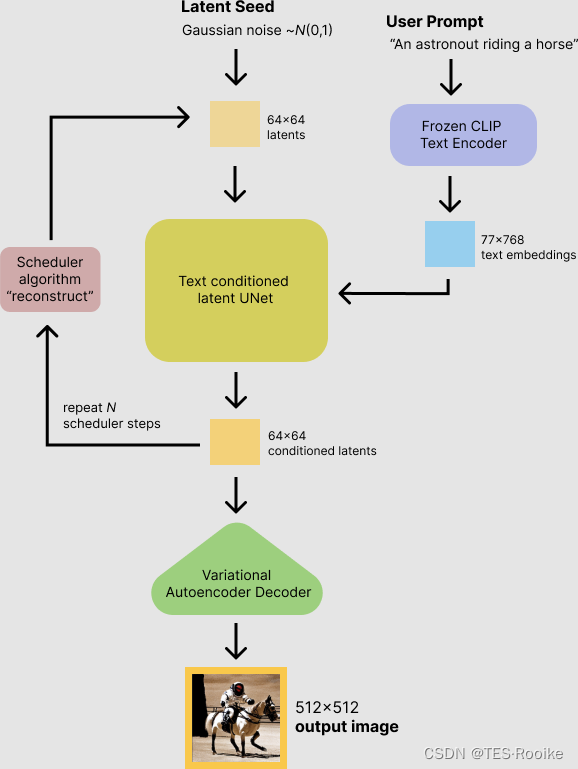
稳态扩散模型将潜在种子和文本提示作为输入。然后使用潜种子生成大小的随机潜图像(64x64),其中文本提示通过CLIP转换为文本embedding(77×768)
接下来,U-Net网络得到了随机种子和文本embedding,就开始随机迭代去噪后的潜在图像。U-Net的输出(即噪声残差)用于通过调度器算法计算去噪的潜在图像表示。(类似于常见的损失函数,拟合出更自然的图像),不同的调度器(损失函数),效果也不同。
在整个模型架构中,有些组件是可以替换成其他的,例如文本编码器可以不用CLIPTextModel,可以用BERT,只要替换的组件的输出可以下个阶段组件的输入是匹配
自定义Stabel Diffusion
下面代码将展示一个自定义的Stabel Diffusion
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. 加载自动编码器模型,该模型将用于将潜在图像表示解码到图像空间中。
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. 加载标记器和文本编码器以标记和编码文本。
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. 加载UNet模型。
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
接下来使用加载K-LMS调度器,使用自定义的参数,而不是加载预定义的调度器。并使用GPU
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
自定义生成图像的参数
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)
首先,我们获取传递的文本提示到tokenizer,再将输出的标记输入到text_encoder中。这些embeddings向量将作为UNet模型的输入,并引导图像生成输入提示的内容。
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
接下来,生成初始随机噪声。
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
如果我们在这个阶段检查潜在图像空间,我们会看到它们的形状是torch大小([1,4,64,64]),比我们想要生成的图像小得多。该模型稍后把潜在空间(纯噪声)转换为512×512图像。
接下来,自定义的num_inference_steps初始化调度器。
scheduler.set_timesteps(num_inference_steps)
K-LMS调度器需要将潜在空间乘以其sigma值
latents = latents * scheduler.init_noise_sigma
准备配置的组件,现在开始编写去噪循环。
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# 预测噪声残差
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# 执行指导
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# 计算先前的噪声样本x_t->x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
我们现在使用VAE将生成的潜在图像空间解码回图像。
# 利用VAE缩放和解码潜在图像空间
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
最后,让我们将图像转换为PIL,以便显示或保存它。
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]