Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
31、Flink的SQL Gateway介绍及示例
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
35、Flink 的 Formats 之CSV 和 JSON Format
36、Flink 的 Formats 之Parquet 和 Orc Format
41、Flink之Hive 方言介绍及详细示例
40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
45、Flink 的指标体系介绍及验证(1)-指标类型及指标实现示例
45、Flink 的指标体系介绍及验证(2)-指标的scope、报告、系统指标以及追踪、api集成示例和dashboard集成
45、Flink 的指标体系介绍及验证(3)- 完整版
46、Flink 的table api与sql之配项列表及示例
47、Flink 的指标报告介绍(graphite、influxdb、prometheus、statsd和datalog)及示例(jmx和slf4j示例)
48、Flink DataStream API 编程指南(1)- DataStream 入门示例
48、Flink DataStream API 编程指南(2)- DataStream的source、transformation、sink、调试
48、Flink DataStream API 编程指南(3)- 完整版
文章目录
- Flink 系列文章
- 一、Flink DataStream API 编程指南
- 1、DataStream 是什么?
- 2、Flink 程序剖析
- 3、第一个完整示例
- 4、入门示例
- 1)、maven依赖
- 2)、代码
- 3)、验证
- 5、Data Sources
- 1)、基于文件
- 2)、基于套接字
- 3)、基于集合
- 4)、自定义
- 6、DataStream Transformations
- 7、Data Sinks
- 8、Iterations
- 9、执行参数
- 1)、容错
- 2)、控制延迟
- 10、调试
- 1)、本地执行环境
- 2)、集合 Data Sources
- 3)、迭代器 Data Sink
本文介绍了Flink DataStream API的编程指南,主要内容是介绍flink的source、transformation和sink的编程过程以及执行参数、调试部分。其中source和sink各自的内容分别给出了具体的示例以及关于transformation的关联文章介绍。
本文由于是在IDE中做的例子,基本上不依赖外部环境,除了具体的示例,比如读写hdfs、kafka、mysql等则需要相应的环境。
本文分为10个部分,即介绍datastream、flink的编程模型、入门示例、source、transformation、sink、迭代器、执行参数及调试几部分。
本文的示例是在Flink 1.17和Flink 1.13.5版本中运行。
一、Flink DataStream API 编程指南
Flink 中的 DataStream 程序是对数据流(例如过滤、更新状态、定义窗口、聚合)进行转换的常规程序。数据流的起始是从各种源(例如消息队列、套接字流、文件)创建的。结果通过 sink 返回,例如可以将数据写入文件或标准输出(例如命令行终端)。Flink 程序可以在各种上下文中运行,可以独立运行,也可以嵌入到其它程序中。任务执行可以运行在本地 JVM 中,也可以运行在多台机器的集群上。
为了创建你自己的 Flink DataStream 程序,建议从 Flink 程序剖析开始,然后逐渐添加自己的 stream transformation。其余部分作为附加的算子和高级特性的参考。
1、DataStream 是什么?
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java 集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用 DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
你可以通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后,你可以基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。
2、Flink 程序剖析
Flink 程序看起来像一个转换 DataStream 的常规程序。每个程序由相同的基本部分组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行。
现在我们将对这些步骤逐一进行概述,更多细节请参考相关章节。请注意,Java DataStream API 的所有核心类都可以在 org.apache.flink.streaming.api 中找到。
StreamExecutionEnvironment 是所有 Flink 程序的基础。
可以使用 StreamExecutionEnvironment 的如下静态方法获取 StreamExecutionEnvironment:
/**
* Creates an execution environment that represents the context in which the program is
* currently executed. If the program is invoked standalone, this method returns a local
* execution environment, as returned by {@link #createLocalEnvironment()}.
*
* @return The execution environment of the context in which the program is executed.
*/
public static StreamExecutionEnvironment getExecutionEnvironment() {
return getExecutionEnvironment(new Configuration());
}
/**
* Creates an execution environment that represents the context in which the program is
* currently executed. If the program is invoked standalone, this method returns a local
* execution environment, as returned by {@link #createLocalEnvironment(Configuration)}.
*
* <p>When executed from the command line the given configuration is stacked on top of the
* global configuration which comes from the {@code flink-conf.yaml}, potentially overriding
* duplicated options.
*
* @param configuration The configuration to instantiate the environment with.
* @return The execution environment of the context in which the program is executed.
*/
public static StreamExecutionEnvironment getExecutionEnvironment(Configuration configuration) {
return Utils.resolveFactory(threadLocalContextEnvironmentFactory, contextEnvironmentFactory)
.map(factory -> factory.createExecutionEnvironment(configuration))
.orElseGet(() -> StreamExecutionEnvironment.createLocalEnvironment(configuration));
}
/**
* Creates a {@link LocalStreamEnvironment}. The local execution environment will run the
* program in a multi-threaded fashion in the same JVM as the environment was created in. The
* default parallelism of the local environment is the number of hardware contexts (CPU cores /
* threads), unless it was specified differently by {@link #setParallelism(int)}.
*
* @return A local execution environment.
*/
public static LocalStreamEnvironment createLocalEnvironment() {
return createLocalEnvironment(defaultLocalParallelism);
}
/**
* Creates a {@link LocalStreamEnvironment}. The local execution environment will run the
* program in a multi-threaded fashion in the same JVM as the environment was created in. It
* will use the parallelism specified in the parameter.
*
* @param parallelism The parallelism for the local environment.
* @return A local execution environment with the specified parallelism.
*/
public static LocalStreamEnvironment createLocalEnvironment(int parallelism) {
return createLocalEnvironment(parallelism, new Configuration());
}
/**
* Creates a {@link LocalStreamEnvironment}. The local execution environment will run the
* program in a multi-threaded fashion in the same JVM as the environment was created in. It
* will use the parallelism specified in the parameter.
*
* @param parallelism The parallelism for the local environment.
* @param configuration Pass a custom configuration into the cluster
* @return A local execution environment with the specified parallelism.
*/
public static LocalStreamEnvironment createLocalEnvironment(
int parallelism, Configuration configuration) {
Configuration copyOfConfiguration = new Configuration();
copyOfConfiguration.addAll(configuration);
copyOfConfiguration.set(CoreOptions.DEFAULT_PARALLELISM, parallelism);
return createLocalEnvironment(copyOfConfiguration);
}
/**
* Creates a {@link LocalStreamEnvironment}. The local execution environment will run the
* program in a multi-threaded fashion in the same JVM as the environment was created in.
*
* @param configuration Pass a custom configuration into the cluster
* @return A local execution environment with the specified parallelism.
*/
public static LocalStreamEnvironment createLocalEnvironment(Configuration configuration) {
if (configuration.getOptional(CoreOptions.DEFAULT_PARALLELISM).isPresent()) {
return new LocalStreamEnvironment(configuration);
} else {
Configuration copyOfConfiguration = new Configuration();
copyOfConfiguration.addAll(configuration);
copyOfConfiguration.set(CoreOptions.DEFAULT_PARALLELISM, defaultLocalParallelism);
return new LocalStreamEnvironment(copyOfConfiguration);
}
}
/**
* Creates a {@link LocalStreamEnvironment} for local program execution that also starts the web
* monitoring UI.
*
* <p>The local execution environment will run the program in a multi-threaded fashion in the
* same JVM as the environment was created in. It will use the parallelism specified in the
* parameter.
*
* <p>If the configuration key 'rest.port' was set in the configuration, that particular port
* will be used for the web UI. Otherwise, the default port (8081) will be used.
*/
@PublicEvolving
public static StreamExecutionEnvironment createLocalEnvironmentWithWebUI(Configuration conf) {
checkNotNull(conf, "conf");
if (!conf.contains(RestOptions.PORT)) {
// explicitly set this option so that it's not set to 0 later
conf.setInteger(RestOptions.PORT, RestOptions.PORT.defaultValue());
}
return createLocalEnvironment(conf);
}
/**
* Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the
* program to a cluster for execution. Note that all file paths used in the program must be
* accessible from the cluster. The execution will use no parallelism, unless the parallelism is
* set explicitly via {@link #setParallelism}.
*
* @param host The host name or address of the master (JobManager), where the program should be
* executed.
* @param port The port of the master (JobManager), where the program should be executed.
* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the
* program uses user-defined functions, user-defined input formats, or any libraries, those
* must be provided in the JAR files.
* @return A remote environment that executes the program on a cluster.
*/
public static StreamExecutionEnvironment createRemoteEnvironment(
String host, int port, String... jarFiles) {
return new RemoteStreamEnvironment(host, port, jarFiles);
}
/**
* Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the
* program to a cluster for execution. Note that all file paths used in the program must be
* accessible from the cluster. The execution will use the specified parallelism.
*
* @param host The host name or address of the master (JobManager), where the program should be
* executed.
* @param port The port of the master (JobManager), where the program should be executed.
* @param parallelism The parallelism to use during the execution.
* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the
* program uses user-defined functions, user-defined input formats, or any libraries, those
* must be provided in the JAR files.
* @return A remote environment that executes the program on a cluster.
*/
public static StreamExecutionEnvironment createRemoteEnvironment(
String host, int port, int parallelism, String... jarFiles) {
RemoteStreamEnvironment env = new RemoteStreamEnvironment(host, port, jarFiles);
env.setParallelism(parallelism);
return env;
}
/**
* Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the
* program to a cluster for execution. Note that all file paths used in the program must be
* accessible from the cluster. The execution will use the specified parallelism.
*
* @param host The host name or address of the master (JobManager), where the program should be
* executed.
* @param port The port of the master (JobManager), where the program should be executed.
* @param clientConfig The configuration used by the client that connects to the remote cluster.
* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the
* program uses user-defined functions, user-defined input formats, or any libraries, those
* must be provided in the JAR files.
* @return A remote environment that executes the program on a cluster.
*/
public static StreamExecutionEnvironment createRemoteEnvironment(
String host, int port, Configuration clientConfig, String... jarFiles) {
return new RemoteStreamEnvironment(host, port, clientConfig, jarFiles);
}
/**
* Gets the default parallelism that will be used for the local execution environment created by
* {@link #createLocalEnvironment()}.
*
* @return The default local parallelism
*/
@PublicEvolving
public static int getDefaultLocalParallelism() {
return defaultLocalParallelism;
}
/**
* Sets the default parallelism that will be used for the local execution environment created by
* {@link #createLocalEnvironment()}.
*
* @param parallelism The parallelism to use as the default local parallelism.
*/
@PublicEvolving
public static void setDefaultLocalParallelism(int parallelism) {
defaultLocalParallelism = parallelism;
}
通常,只需要使用 getExecutionEnvironment() 即可,因为该方法会根据上下文做正确的处理:如果你在 IDE 中执行你的程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在你的本地机器上执行你的程序。如果你基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行你的程序。
为了指定 data sources,执行环境提供了一些方法,支持使用各种方法从文件中读取数据:你可以直接逐行读取数据,像读 CSV 文件一样,或使用任何第三方提供的 source。
如果你只是将一个文本文件作为一个行的序列来读取,那么可以使用:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> users = env.readTextFile("file:///D:/workspace/bigdata-component/hadoop/test/in/flink/");
这将生成一个 DataStream,然后你可以在上面应用转换(transformation)来创建新的派生 DataStream。
你可以调用 DataStream 上具有转换功能的方法来应用转换。例如,一个 map 的转换如下所示:
DataStream<Tuple3<Integer, String, Integer>> parsed = users.map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {
@Override
public Tuple3<Integer, String, Integer> map(String value) {
// 文件数据格式形如:1|107860|7191
String[] line = value.split(",");
return Tuple3.of(Integer.valueOf(line[0]), line[1], Integer.valueOf(line[2]));
}
});
这将通过把原始集合中的每一行转换为一个Tuple3<Integer, String, Integer>来创建一个新的 DataStream。
一旦你有了包含最终结果的 DataStream,你就可以通过创建 sink 把它写到外部系统。下面是一些用于创建 sink 的示例方法:
parsed.print();
parsed.writeAsText("file:///D:/workspace/bigdata-component/hadoop/test/out/flink");
一旦指定了完整的程序,需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行。根据 ExecutionEnvironment 的类型,执行会在你的本地机器上触发,或将你的程序提交到某个集群上执行。
execute() 方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果。
如果不想等待作业完成,可以通过调用 StreamExecutionEnvironment 的 executeAsync() 方法来触发作业异步执行。它会返回一个 JobClient,你可以通过它与刚刚提交的作业进行通信。如下是使用 executeAsync() 实现 execute() 语义的示例。
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
关于程序执行的最后一部分对于理解何时以及如何执行 Flink 算子是至关重要的。所有 Flink 程序都是延迟执行的:当程序的 main 方法被执行时,数据加载和转换不会直接发生。相反,每个算子都被创建并添加到 dataflow 形成的有向图。当执行被执行环境的 execute() 方法显示地触发时,这些算子才会真正执行。程序是在本地执行还是在集群上执行取决于执行环境的类型。
延迟计算允许你构建复杂的程序,Flink 会将其作为一个整体的计划单元来执行。
3、第一个完整示例
- maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
- 代码
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestFileSystemDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> orders = env.readTextFile("file:///D:/workspace/bigdata-component/hadoop/test/in/flink/");
DataStream<Tuple3<Integer, String, Integer>> parsed = orders.map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {
@Override
public Tuple3<Integer, String, Integer> map(String value) {
// 文件数据格式形如:1|107860|7191
String[] line = value.split(",");
return Tuple3.of(Integer.valueOf(line[0]), line[1], Integer.valueOf(line[2]));
}
});
parsed.print();
parsed.writeAsText("file:///D:/workspace/bigdata-component/hadoop/test/out/flink");
env.execute();
}
}
- 运行结果
控制台输出结果
8> (1,alan,15)
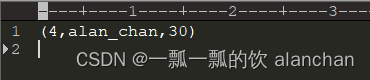
16> (4,alan_chan,30)
13> (3,alanchanchn,25)
3> (5,alan_chan_chn,45)
10> (2,alanchan,20)
文件输出结果见下图
4、入门示例
如下是一个完整的、可运行的程序示例,它是基于流窗口的单词统计应用程序,计算 5 秒窗口内来自 Web 套接字的单词数。
1)、maven依赖
见本文上述示例中的maven依赖。
2)、代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestWindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream =
env.socketTextStream("192.168.10.42", 9999)
.flatMap(new Splitter()).keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : sentence.split(",")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
3)、验证
前提是nc已经安装好了。
- 启动nc并输入数据
# 在192.168.10.42上使用nc -lk 9999 向指定端口发送数据
# nc是netcat的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据
# 如果没有该命令可以下安装 yum install -y nc
[alanchan@server2 bin]$ nc -lk 9999
alan,alach,alanchan,hello
alan_chan,hi,flink
alan,flink,good
alan,alach,alanchan,hello
hello,123
- 启动应用程序,并观察控制台输出
应用程序启动后,再在nc中输入数据
13> (alan,1)
5> (alanchan,1)
8> (alach,1)
5> (hello,1)
16> (alan_chan,1)
13> (flink,1)
6> (hi,1)
13> (alan,1)
11> (good,1)
13> (flink,1)
8> (alach,1)
5> (alanchan,1)
13> (alan,1)
5> (hello,1)
5> (hello,1)
4> (123,1)
如果想查看大于 1 的计数,在 5 秒内重复输入相同的单词即可(如果无法快速输入,则可以将窗口大小从 5 秒增加 )。
5、Data Sources
Source 是你的程序从中读取其输入的地方。你可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到你的程序。Flink 自带了许多预先实现的 source functions,不过你仍然可以通过实现 SourceFunction 接口编写自定义的非并行 source,也可以通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources。
通过 StreamExecutionEnvironment 可以访问多种预定义的 stream source:
1)、基于文件
- readTextFile(path) - 读取文本文件,例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。
- readFile(fileInputFormat, path) - 按照指定的文件输入格式读取(一次)文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个方法内部调用的方法。它基于给定的 fileInputFormat 读取路径 path 上的文件。根据提供的 watchType 的不同,source 可能定期(每 interval 毫秒)监控路径上的新数据(watchType 为 FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次当前路径中的数据然后退出(watchType 为 FileProcessingMode.PROCESS_ONCE)。使用 pathFilter,用户可以进一步排除正在处理的文件。
- 实现
在底层,Flink 将文件读取过程拆分为两个子任务,即 目录监控 和 数据读取。每个子任务都由一个单独的实体实现。监控由单个非并行(并行度 = 1)任务实现,而读取由多个并行运行的任务执行。后者的并行度和作业的并行度相等。单个监控任务的作用是扫描目录(定期或仅扫描一次,取决于 watchType),找到要处理的文件,将它们划分为 分片,并将这些分片分配给下游 reader。Reader 是将实际获取数据的角色。每个分片只能被一个 reader 读取,而一个 reader 可以一个一个地读取多个分片。
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,当一个文件被修改时,它的内容会被完全重新处理。这可能会打破 “精确一次” 的语义,因为在文件末尾追加数据将导致重新处理文件的所有内容。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,source 扫描一次路径然后退出,无需等待 reader 读完文件内容。当然,reader 会继续读取数据,直到所有文件内容都读完。关闭 source 会导致在那之后不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class Source_File {
/**
* 一般用于学习测试 env.readTextFile(本地/HDFS文件/文件夹);//压缩文件也可以
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds1 = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/words.txt");
DataStream<String> ds2 = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/input/distribute_cache_student");
DataStream<String> ds3 = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/words.tar.gz");
DataStream<String> ds4 = env.readTextFile("hdfs://server2:8020///flinktest/wc-1688627439219");
// transformation
// sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
// execute
env.execute();
}
}
2)、基于套接字
socketTextStream - 从套接字读取。元素可以由分隔符分隔。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
* 在192.168.10.42上使用nc -lk 9999 向指定端口发送数据
* nc是netcat的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据
* 如果没有该命令可以下安装 yum install -y nc
*
*/
public class Source_Socket {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//source
DataStream<String> lines = env.socketTextStream("192.168.10.42", 9999);
//transformation
/*SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
words.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value,1);
}
});*/
//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回
// SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
// @Override
// public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// String[] arr = value.split(" ");
// for (String word : arr) {
// out.collect(Tuple2.of(word, 1));
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(t -> t.f0).sum(1);
//sink
lines.print();
//execute
env.execute();
}
}
3)、基于集合
- fromCollection(Collection) - 从 Java Java.util.Collection 创建数据流。集合中的所有元素必须属于同一类型。
- fromCollection(Iterator, Class) - 从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。
- fromElements(T …) - 从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
- fromParallelCollection(SplittableIterator, Class) - 从迭代器并行创建数据流。class 参数指定迭代器返回元素的数据类型。
- generateSequence(from, to) - 基于给定间隔内的数字序列并行生成数据流。
import java.util.Arrays;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class Source_Collection {
/**
* 一般用于学习测试时编造数据时使用
* 1.env.fromElements(可变参数);
* 2.env.fromColletion(各种集合);
* 3.env.generateSequence(开始,结束);
* 4.env.fromSequence(开始,结束);
*
* @param args 基于集合
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds1 = env.fromElements("i am alanchan", "i like flink");
DataStream<String> ds2 = env.fromCollection(Arrays.asList("i am alanchan", "i like flink"));
DataStream<Long> ds3 = env.generateSequence(1, 10);//已过期,使用fromSequence方法
DataStream<Long> ds4 = env.fromSequence(1, 100);
// transformation
// sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
// execute
env.execute();
}
}
4)、自定义
addSource - 关联一个新的 source function。例如,你可以使用 addSource(new FlinkKafkaConsumer<>(…)) 来从 Apache Kafka 获取数据。
其中的maven依赖参考本专栏的相关文章
- kafka
该示例是基于flink1.13.5的版本
import java.util.Properties;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class Source_Kafka {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// 准备kafka连接参数
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092");// 集群地址
props.setProperty("group.id", "flink");// 消费者组id
props.setProperty("auto.offset.reset", "latest");// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// /earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("flink.partition-discovery.interval-millis", "5000");// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("enable.auto.commit", "true");// 自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("auto.commit.interval.ms", "2000");// 自动提交的时间间隔
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("t_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// transformation
// sink
kafkaDS.print();
// execute
env.execute();
}
}
- mysql
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.source_transformation_sink.bean.User;
/**
* @author alanchan
* 自定义数据源-MySQL
*/
public class Source_MySQL {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> studentDS = env.addSource(new MySQLSource()).setParallelism(1);
// transformation
// sink
studentDS.print();
// execute
env.execute();
}
private static class MySQLSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
// open只执行一次,适合开启资源
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
String sql = "select id,name,pwd,email,age,balance from user";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<User> ctx) throws Exception {
while (flag) {
rs = ps.executeQuery();
while (rs.next()) {
User user = new User(
rs.getInt("id"),
rs.getString("name"),
rs.getString("pwd"),
rs.getString("email"),
rs.getInt("age"),
rs.getDouble("balance")
);
ctx.collect(user);
}
Thread.sleep(5000);
}
}
// 接收到cancel命令时取消数据生成
@Override
public void cancel() {
flag = false;
}
// close里面关闭资源
@Override
public void close() throws Exception {
if (conn != null)
conn.close();
if (ps != null)
ps.close();
if (rs != null)
rs.close();
}
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
6、DataStream Transformations
详见文章4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
7、Data Sinks
Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们。Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里:
- writeAsText() / TextOutputFormat - 将元素按行写成字符串。通过调用每个元素的 toString() 方法获得字符串。
- writeAsCsv(…) / CsvOutputFormat - 将元组写成逗号分隔值文件。行和字段的分隔符是可配置的。每个字段的值来自对象的 toString() 方法。
- print() / printToErr() - 在标准输出/标准错误流上打印每个元素的 toString() 值。 可选地,可以提供一个前缀(msg)附加到输出。这有助于区分不同的 print 调用。如果并行度大于1,输出结果将附带输出任务标识符的前缀。
- writeUsingOutputFormat() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义 object 到 byte 的转换。
- writeToSocket - 根据 SerializationSchema 将元素写入套接字。
- addSink - 调用自定义 sink function。Flink 捆绑了连接到其他系统(例如 Apache Kafka)的连接器,这些连接器被实现为 sink functions。
注意,DataStream 的 write*() 方法主要用于调试目的。它们不参与 Flink 的 checkpointing,这意味着这些函数通常具有至少有一次语义。刷新到目标系统的数据取决于 OutputFormat 的实现。这意味着并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。
为了将流可靠地、精准一次地传输到文件系统中,请使用 FileSink。此外,通过 .addSink(…) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义。
下面提供三个sink的示例。
- kafka
import org.apache.kafka.common.serialization.ByteArrayDeserializer;
import java.util.Properties;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class SinkKafka {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "server1:9092");
// 消费者组id
props.setProperty("group.id", "flink");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("t_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// transformation
//以alan作为结尾
SingleOutputStreamOperator<String> etlDS = kafkaDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.contains("alan");
}
});
// sink
etlDS.print();
Properties props2 = new Properties();
props2.setProperty("bootstrap.servers", "server1:9092");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("t_kafkasink", new SimpleStringSchema(), props2);
etlDS.addSink(kafkaSink);
// execute
env.execute();
}
}
- flie
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*/
public class SinkDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/words.txt");
System.setProperty("HADOOP_USER_NAME", "alanchan");
// transformation
// sink
// ds.print();
// ds.print("输出标识");
// ds.printToErr();// 会在控制台上以红色输出
// ds.printToErr("输出标识");// 会在控制台上以红色输出
// 并行度与写出的文件个数有关,一个并行度写一个文件,多个并行度写多个文件
// ds.writeAsText("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/output/result1").setParallelism(1);
ds.writeAsText("hdfs://server2:8020///flinktest/words").setParallelism(2);
// execute
env.execute();
}
}
- mysql
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.source_transformation_sink.bean.User;
/**
* @author alanchan
*
*/
public class SinkToMySQL {
public static void main(String[] args) throws Exception {
// 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 1.source
DataStream<User> studentDS = env.fromElements(new User(1, "alanchan", "sink mysql", "alan.chan.chn@163.com", 19, 800));
// 2.transformation
// 3.sink
studentDS.addSink(new MySQLSink());
// 4.execute
env.execute();
}
private static class MySQLSink extends RichSinkFunction<User> {
private Connection conn = null;
private PreparedStatement ps = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection(
"jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false", "root", "123456");
// private int id;
// private String name;
// private String pwd;
// private String email;
// private int age;
// private double balance;
String sql = "INSERT INTO `user` (`id`, `name`, `pwd`, `email`, `age`, `balance`) VALUES (null, ?, ?, ?, ?, ?);";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(User value, Context context) throws Exception {
// 设置?占位符参数值
ps.setString(1, value.getName());
ps.setString(2, value.getPwd());
ps.setString(3, value.getEmail());
ps.setInt(4, value.getAge());
ps.setDouble(5, value.getBalance());
// 执行sql
ps.executeUpdate();
}
@Override
public void close() throws Exception {
if (conn != null)
conn.close();
if (ps != null)
ps.close();
}
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
8、Iterations
Iterative streaming 程序实现了 setp function 并将其嵌入到 IterativeStream 。由于 DataStream 程序可能永远不会完成,因此没有最大迭代次数。相反,你需要指定流的哪一部分反馈给迭代,哪一部分使用旁路输出或过滤器转发到下游。这里,我们展示了一个使用过滤器的示例。首先,我们定义一个 IterativeStream
IterativeStream<Integer> iteration = input.iterate();
然后,我们使用一系列转换(这里是一个简单的 map 转换)指定将在循环内执行的逻辑
DataStream<Integer> iterationBody = iteration.map(/* this is executed many times */);
要关闭迭代并定义迭代尾部,请调用 IterativeStream 的 closeWith(feedbackStream) 方法。提供给 closeWith 函数的 DataStream 将反馈给迭代头。一种常见的模式是使用过滤器将反馈的流部分和向前传播的流部分分开。
例如,这些过滤器可以定义“终止”逻辑,其中允许元素向下游传播而不是被反馈。
iteration.closeWith(iterationBody.filter(/* one part of the stream */));
DataStream<Integer> output = iterationBody.filter(/* some other part of the stream */);
下面的程序从一系列整数中连续减去 1,直到它们达到零:
DataStream<Long> someIntegers = env.generateSequence(0, 1000);
IterativeStream<Long> iteration = someIntegers.iterate();
DataStream<Long> minusOne = iteration.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1 ;
}
});
DataStream<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value > 0);
}
});
iteration.closeWith(stillGreaterThanZero);
DataStream<Long> lessThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value <= 0);
}
});
下面一个示例是演示旁路输出的,即将数据分为2个部分。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AbstractRichFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.TimeDomain;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction.Context;
import org.apache.flink.streaming.api.functions.ProcessFunction.OnTimerContext;
import org.apache.flink.streaming.api.scala.OutputTag;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class Transformation_OutpuTagAndProcess {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source
DataStreamSource<String> ds = env.fromElements("alanchan is my vx", "i like flink", "alanchanchn is my name", "i like kafka too", "alanchanchn is my true vx");
// transformation
// 对流中的数据按照alanchanchn拆分并选择
OutputTag<String> nameTag = new OutputTag<>("alanchanchn", TypeInformation.of(String.class));
OutputTag<String> frameworkTag = new OutputTag<>("framework", TypeInformation.of(String.class));
SingleOutputStreamOperator<String> result = ds.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String inValue, Context ctx, Collector<String> outValue) throws Exception {
// out收集完的还是放在一起的,,ctx可以将数据放到不同的OutputTag
if (inValue.startsWith("alanchanchn")) {
ctx.output(nameTag, inValue);
} else {
ctx.output(frameworkTag, inValue);
}
}
});
DataStream<String> nameResult = result.getSideOutput(nameTag);
DataStream<String> frameworkResult = result.getSideOutput(frameworkTag);
// sink
System.out.println(nameTag);// OutputTag(Integer, 奇数)
System.out.println(frameworkTag);// OutputTag(Integer, 偶数)
nameResult.print("name->");
frameworkResult.print("framework->");
// execute
env.execute();
}
}
9、执行参数
StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置值。
大多数参数的说明可参考执行配置。这些参数特别适用于 DataStream API:
setAutoWatermarkInterval(long milliseconds):设置自动发送 watermark 的时间间隔。你可以使用 long getAutoWatermarkInterval() 获取当前配置值。
1)、容错
State & Checkpointing 描述了如何启用和配置 Flink 的 checkpointing 机制。
具体参考文章:9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
2)、控制延迟
默认情况下,元素不会在网络上一一传输(这会导致不必要的网络传输),而是被缓冲。缓冲区的大小(实际在机器之间传输)可以在 Flink 配置文件中设置。虽然此方法有利于优化吞吐量,但当输入流不够快时,它可能会导致延迟问题。要控制吞吐量和延迟,你可以调用执行环境(或单个算子)的 env.setBufferTimeout(timeoutMillis) 方法来设置缓冲区填满的最长等待时间。超过此时间后,即使缓冲区没有未满,也会被自动发送。超时时间的默认值为 100 毫秒。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
为了最大限度地提高吞吐量,设置 setBufferTimeout(-1) 来删除超时,这样缓冲区仅在它们已满时才会被刷新。要最小化延迟,请将超时设置为接近 0 的值(例如 5 或 10 毫秒)。应避免超时为 0 的缓冲区,因为它会导致严重的性能下降。
10、调试
在分布式集群中运行流程序之前,最好确保实现的算法能按预期工作。因此,实现数据分析程序通常是一个检查结果、调试和改进的增量过程。
Flink 通过提供 IDE 内本地调试、注入测试数据和收集结果数据的特性大大简化了数据分析程序的开发过程。
本节给出了一些如何简化 Flink 程序开发的提示。本节的示例与上述的示例基本上一致,变化的就是执行环境,本处避免冗余不再示例赘述。
1)、本地执行环境
LocalStreamEnvironment 在创建它的同一个 JVM 进程中启动 Flink 系统。如果你从 IDE 启动 LocalEnvironment,则可以在代码中设置断点并轻松调试程序。
一个 LocalEnvironment 的创建和使用如下:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
// 构建你的程序
env.execute();
2)、集合 Data Sources
Flink 提供了由 Java 集合支持的特殊 data sources 以简化测试。一旦程序通过测试,sources 和 sinks 可以很容易地被从外部系统读取/写入到外部系统的 sources 和 sinks 替换。
可以按如下方式使用集合 Data Sources:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 从元素列表创建一个 DataStream
DataStream<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// 从任何 Java 集合创建一个 DataStream
List<Tuple2<String, Integer>> data = ...
DataStream<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// 从迭代器创建一个 DataStream
Iterator<Long> longIt = ...
DataStream<Long> myLongs = env.fromCollection(longIt, Long.class);
截至Flink 1.17版本,集合 data source 要求数据类型和迭代器实现 Serializable。此外,集合 data sources 不能并行执行(parallelism = 1)。
3)、迭代器 Data Sink
Flink 还提供了一个 sink 来收集 DataStream 的结果,它用于测试和调试目的。可以按以下方式使用。
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = myResult.collectAsync();
以上,本文介绍了Flink DataStream API的编程指南,主要内容是介绍flink的source、transformation和sink的编程过程以及执行参数、调试部分。其中source和sink各自的内容分别给出了具体的示例以及关于transformation的关联文章介绍。