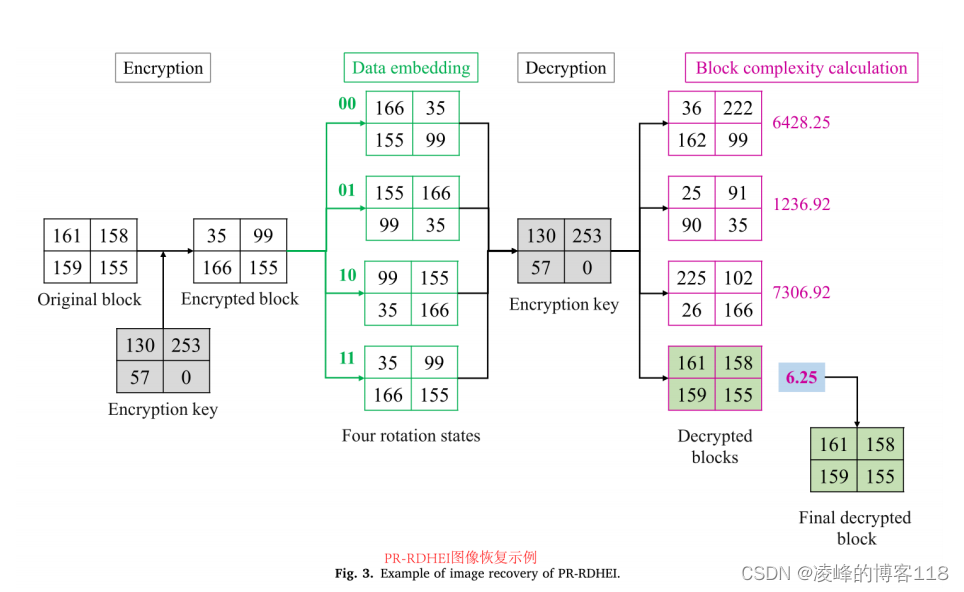
1. 加更多的层总是改进精度吗?
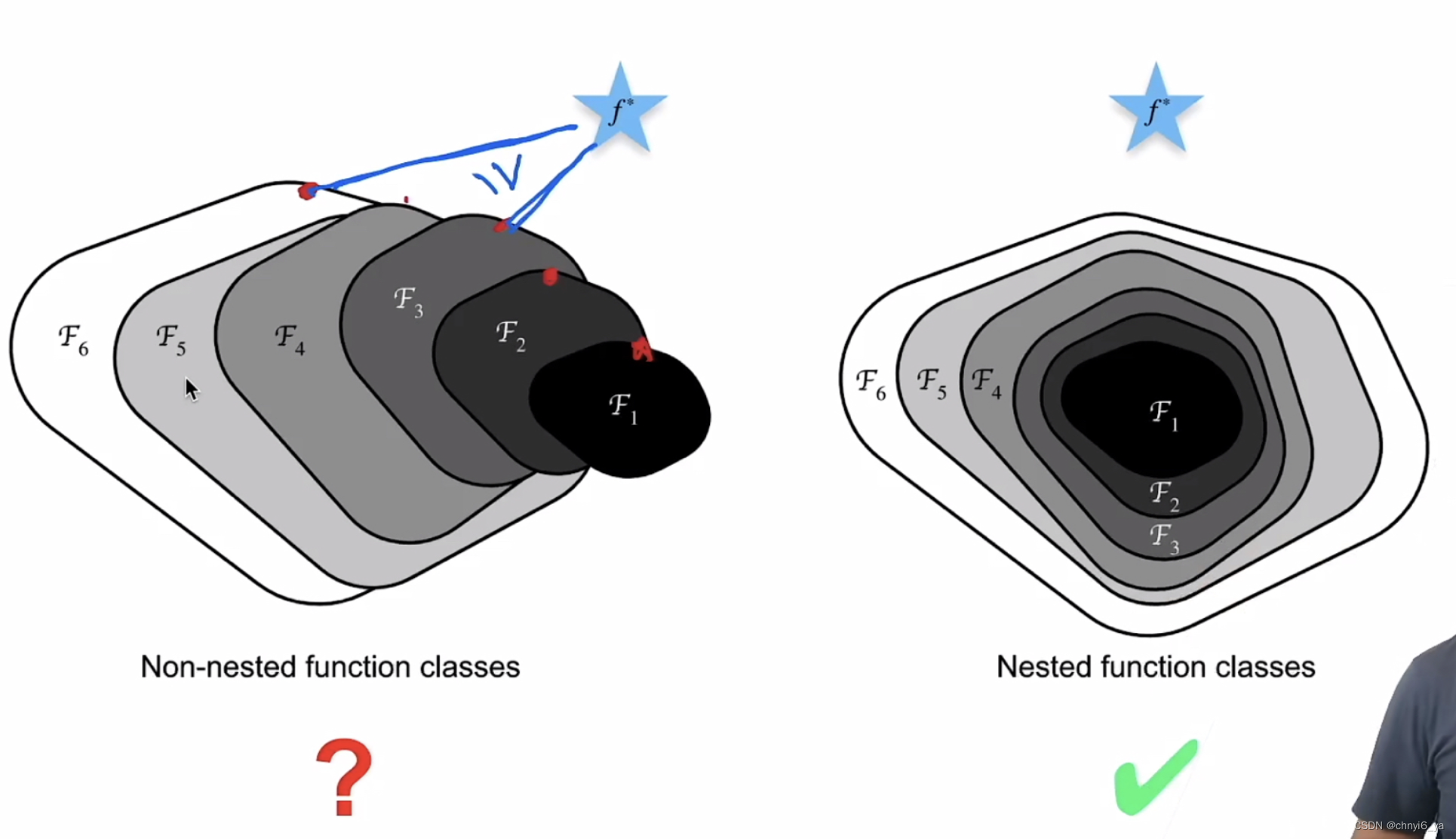
对于非嵌套函数类,较复杂(由较大区域表示)的函数类不能保证更接近“真”函数( f* )。这种现象在嵌套函数类中不会发生。
因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)f(x)=x,新模型和原模型将同样有效。 同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
针对这一问题,何恺明等人提出了残差网络(ResNet)。它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
于是,残差块(residual blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。 凭借它,ResNet赢得了2015年ImageNet大规模视觉识别挑战赛。
2. 残差块
- 串联一个层改变函数类,我们希望能扩大函数类
- 残差块加入快速通道(右边)来得到 f(x) = x + g(x)的结构
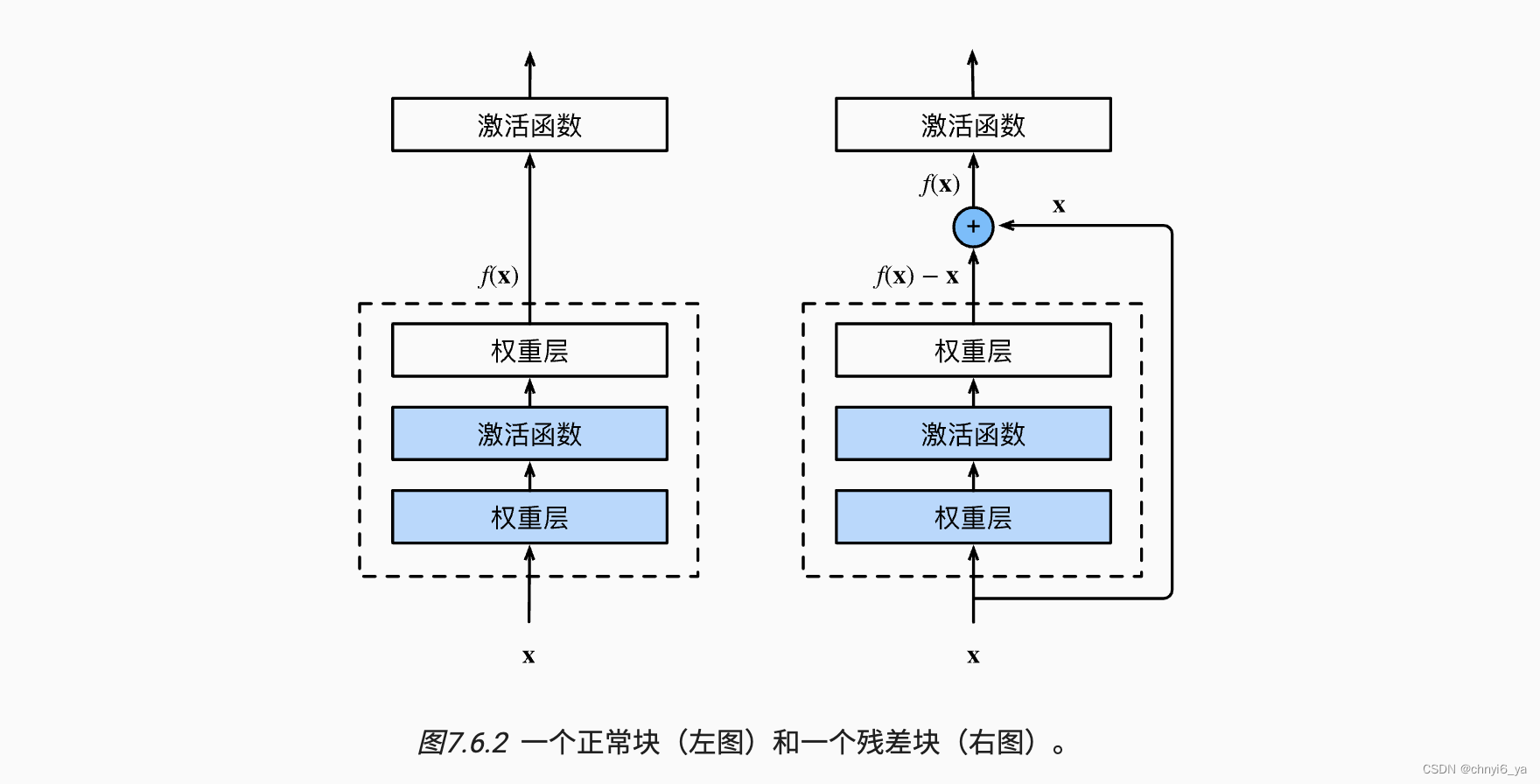
3. ResNet块细节

4. 不同的残差块

5. ResNet块
- 高宽减半ResNet块(步幅2)
- 后街多个高宽不变的ResNet块

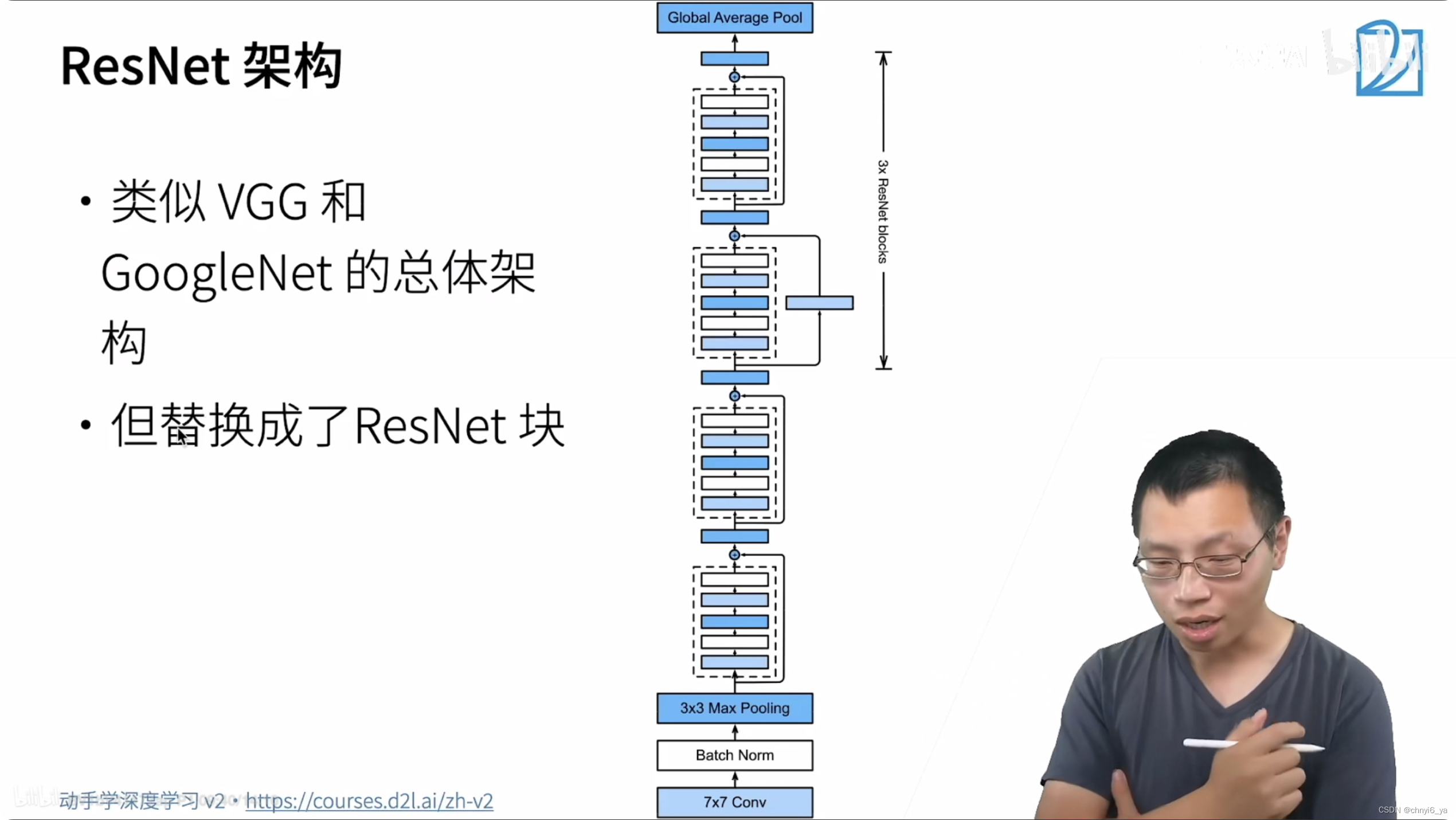
6. ResNet架构
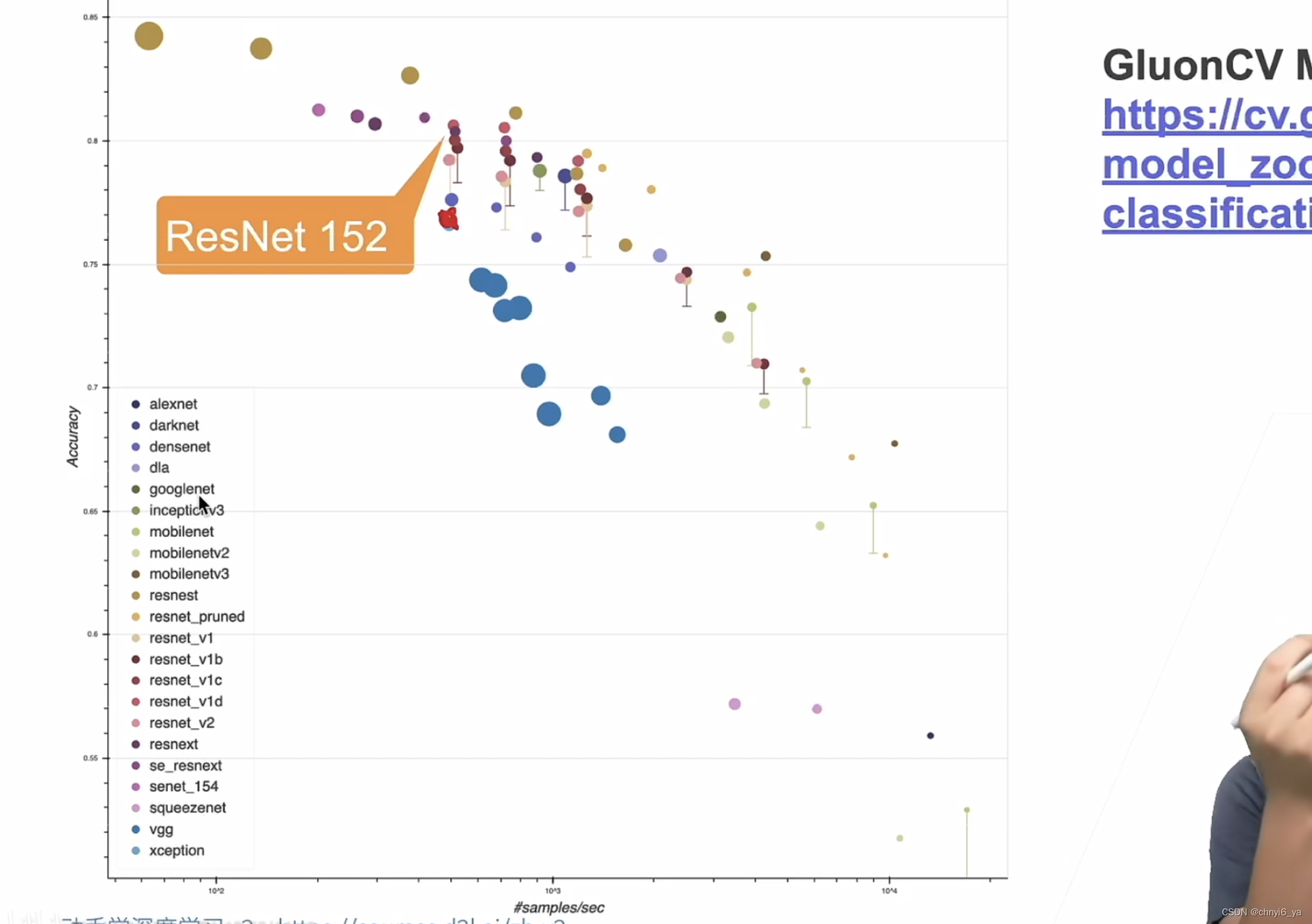
7. 效果
8. 总结
- 残差块使得很深的网络更加容易训练
- 甚至可以训练一千层的网络
- 残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接类网络