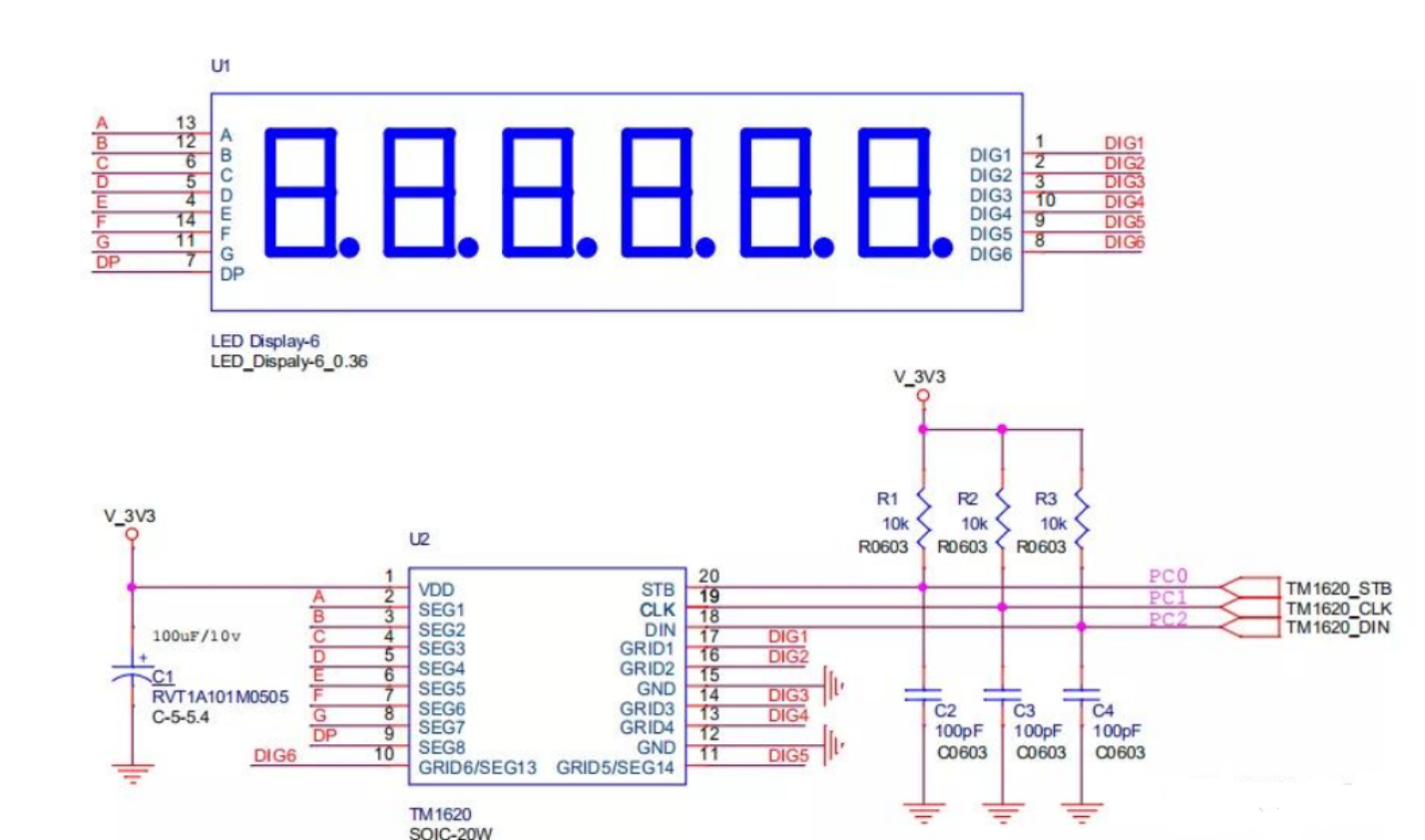
hadoop主要解决:海量数据的存储和海量数据的分析计算
hadoop发展历史
Google是hadoop的思想之源(Google在大数据方面的三篇论文)
2006年3月,Map-reduce和Nutch Distributed File System(NDFS)分别被纳入到Hadoop项目,Hadoop正式诞生。
MapReduce
对海量数据处理
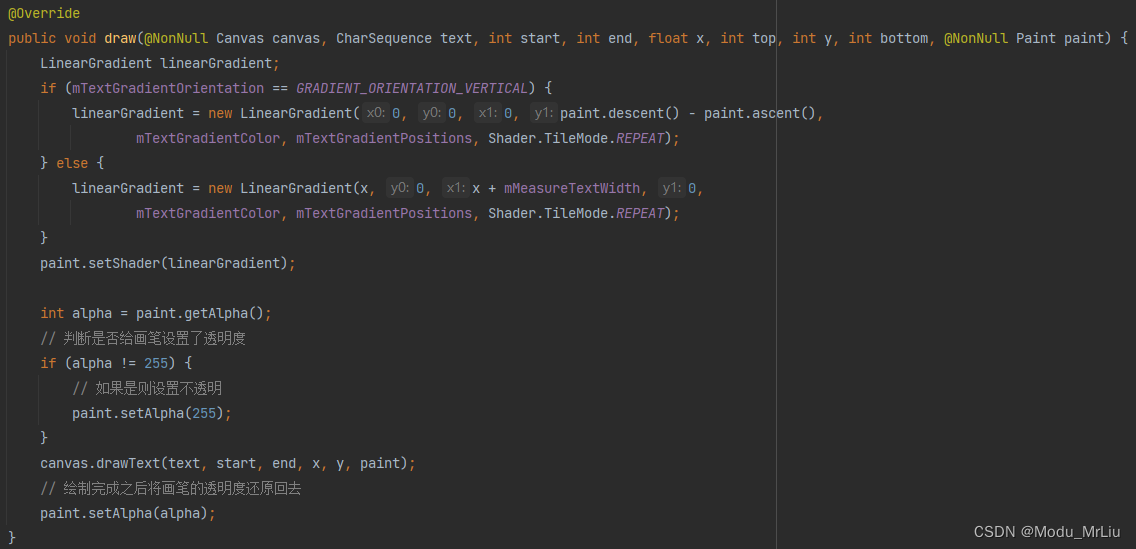
map函数进行数据的提取、排序,实现mapper,四个形参(输入key,输入value,输出key,输出value),重写map方法,将输出信息写入到context中
reduce函数进行数据的计算,实现reduce,四个形参也是指定输入输出类型,reduce的输入类型必须匹配map的输出类型
job负责执行,控制整个作业的运行。
分为两个阶段,map阶段并行处理输入数据,reduce阶段对map结果进行汇总。
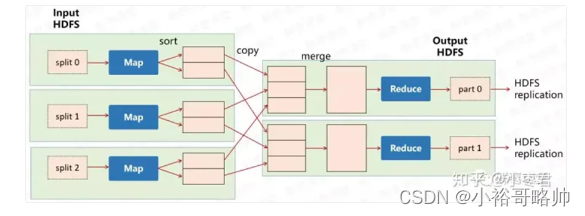
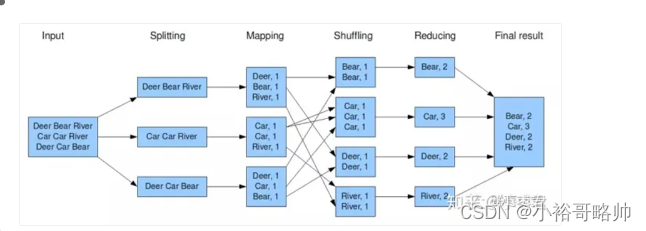
map阶段
第一个阶段把输入文件进行分片,
第二个阶段对输入的数据按照一定的规则解析成键值对,key表示每行首字符偏移值,value表示行文本内容
第三阶段是调用map方法,解析出来的每个键值对,调用一次map方法
第四阶段是按照一定规则对第三阶段输出的键值对进行分区
第五阶段是对每个分区中的键值对进行排序,首先按照key排序,再按value进行排序,完成后将数据写入内存中,内存中这片区域叫做环形缓存区。
reduce阶段
第一阶段copy map阶段输出的键值对
第二阶段把数据进行合并排序,把复制到ruduce阶段的数据全部合并,在对合并后的数据进行排序
第三个阶段是对排序后的键值对调用reduce方法。最后把输出的键值对写入到HDFS文件中
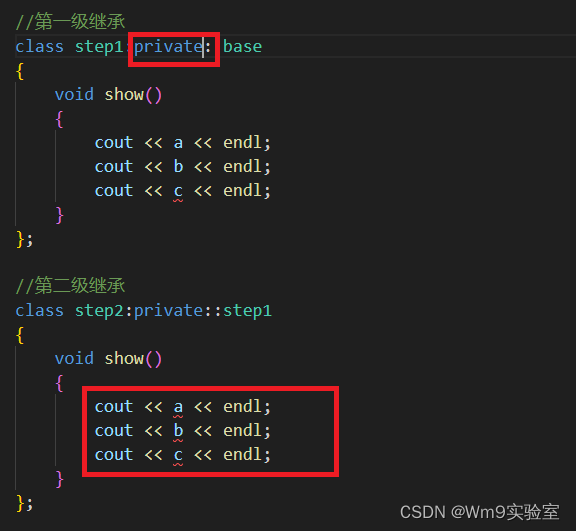
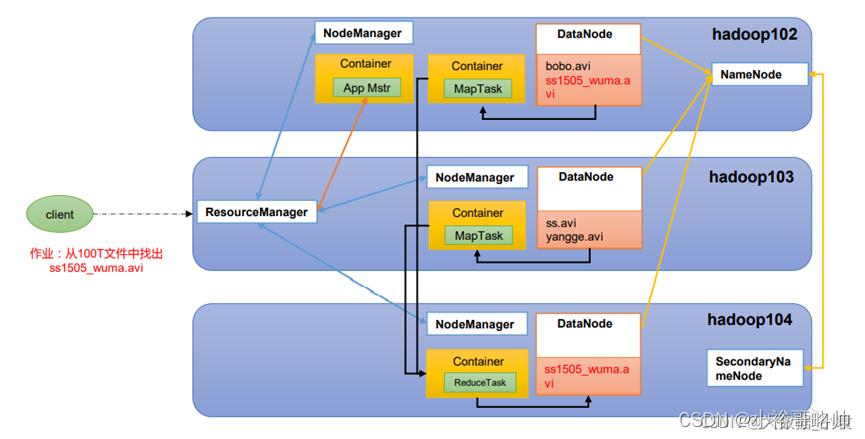
HDFS
是一个分布式文件系统
概念
整个HDFS有三个重要的角色:NameNode,DataNode,Client
NameNode:可看作是分布式文件系统的管理者,主要负责文件系统的命令空间,集群配置信息,存储块的复制,namenode会将文件系统的meta-data存储在内存中,这些信息主要包括了文件信息、每个文件对应的文件块的信息和每个文件块在datanode的信息等。
DataNode:是slave节点,是文件存储的基本单位,他将block存储在本地文件系统中,保存了block的meta-data,同时周期性的将所有存在的block信息发送给namenode。
Client:切分文件,访问hdfs;与namenode交互,获取文件位置信息;与datanode交互,读取和写入数据。
还有一个block的概念,block是hdfs读写的基本单位,hdfs最初都是被切割为block块存储的,这些块被复制到多个datanode中,块的大小(通常为128M)与复制的块数量在创建文件时由client决定。
最小化寻址开销
也不能设置过大,map任务通常一次只处理一个块中的数据,如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢
写入流程:
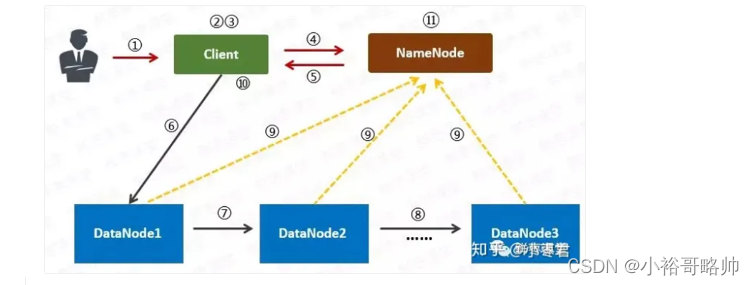
用户向客户端提出请求,要存储200M的数据;
client指定计划,将数据按照128M进行切分;
client告诉namenode,让把128m的数据复制为三份
namenode将三个datanode的地址告诉client,并且将他们根据到client的距离进行排序
client将数据与清单发送给第一个datanode,第一个datanode将数据复制给第二个datanode,第二个将数据复制给第三个datanode
如果某一个块的数据已经全部写入,就给namenode反馈已完成,对第二个block也进行相同的操作
所有的block已经全部写入,关闭文件,namenode会将数据持久化到磁盘上;
读取流程:
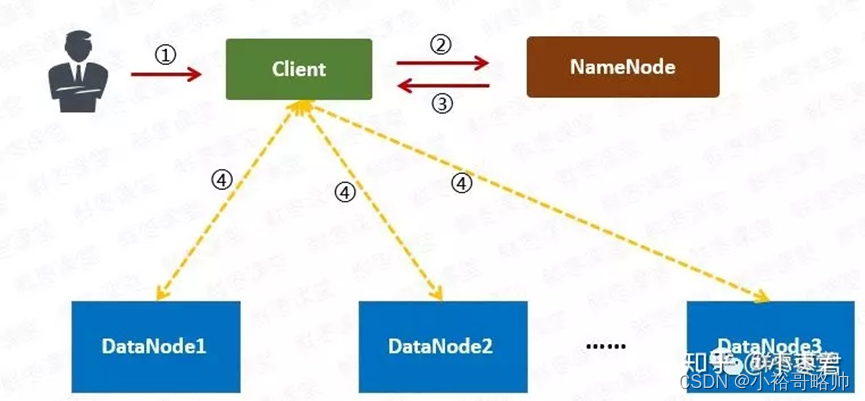
用户向客户端提出读取请求
client向namenode请求文件的所有信息
namenode将给client这个文件的块列表,以及存储各个块的数据节点清单(按照与client的距离排序)
client从最近的datanode下载所需的块。
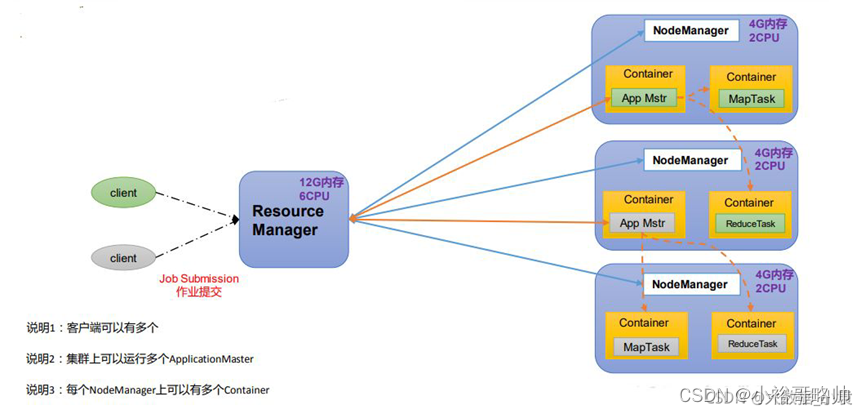
YARN
简称yarn,一种资源协调者,是hadoop的资源管理器
ResourceManager(RM):整个集群资源的老大
ApplicationMaster(AM):单个任务运行的老大
NodeManager(NM):单个节点服务器资源老大
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、cpu、磁盘、网络等。
HDFS,YARN,MapReduce三者关系
大数据技术生态系统
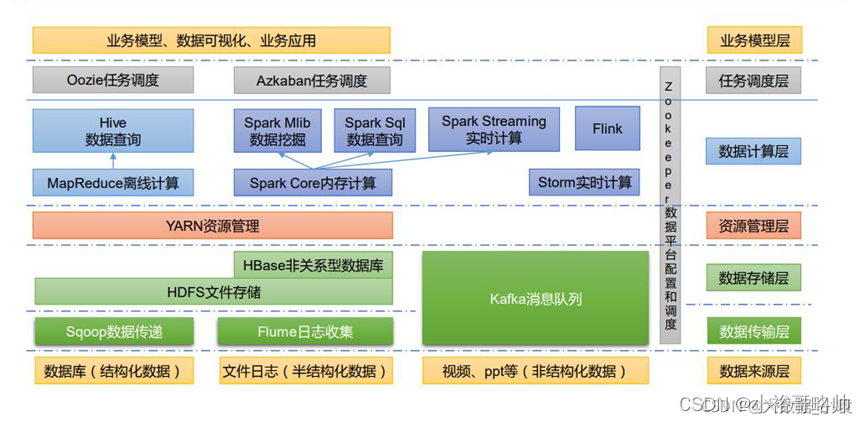
)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。