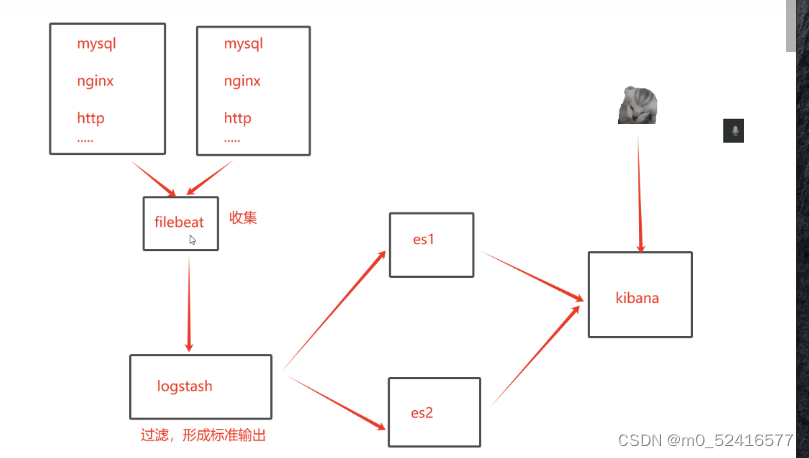
filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动使用的资源要小的多
filebeat可以允许在非java环境,他可以代替logstash在非java环境上收集日志
filebeat无法实现数据的过滤,一般是结合logstash的数据过滤功能一块使用
filebeat收集的数据可以发往多个主机,远程收集

nohup ./filebeat -e -c filebeat.yml > filebeat.out &
nohup 标识在后台记录执行命令的过程
./filebeat 允许文件
-e 使用标准输出的同时艰辛syslog文件输出
-c 指定配置文件
执行过程输出到filebeat。out这个文件当中。 &后台运行
logstash -f nginx.conf --path.data /opt/test1 &
logstash收集日志的过程
input (从哪里收集)
filer 作用过滤
output(发送到es实例)
本地收集:
远程收集,远程收集多个日志,
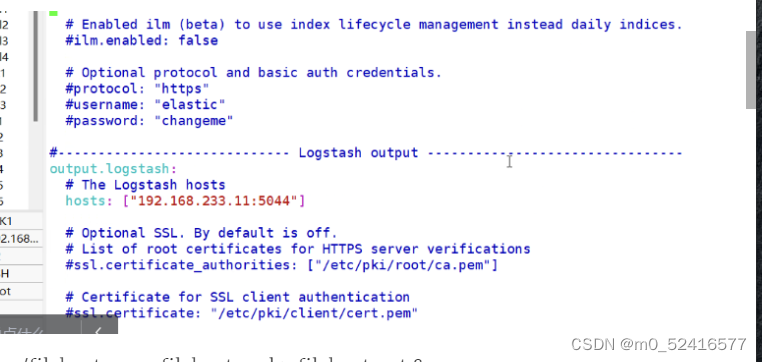
mysql上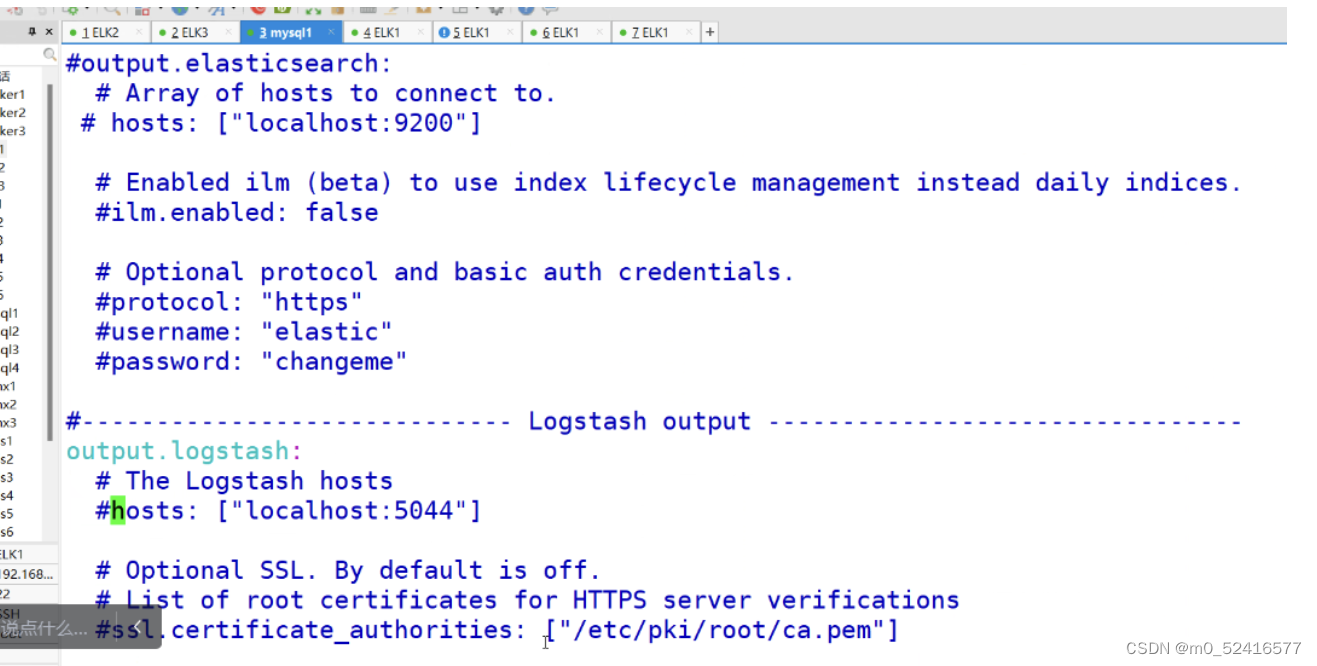

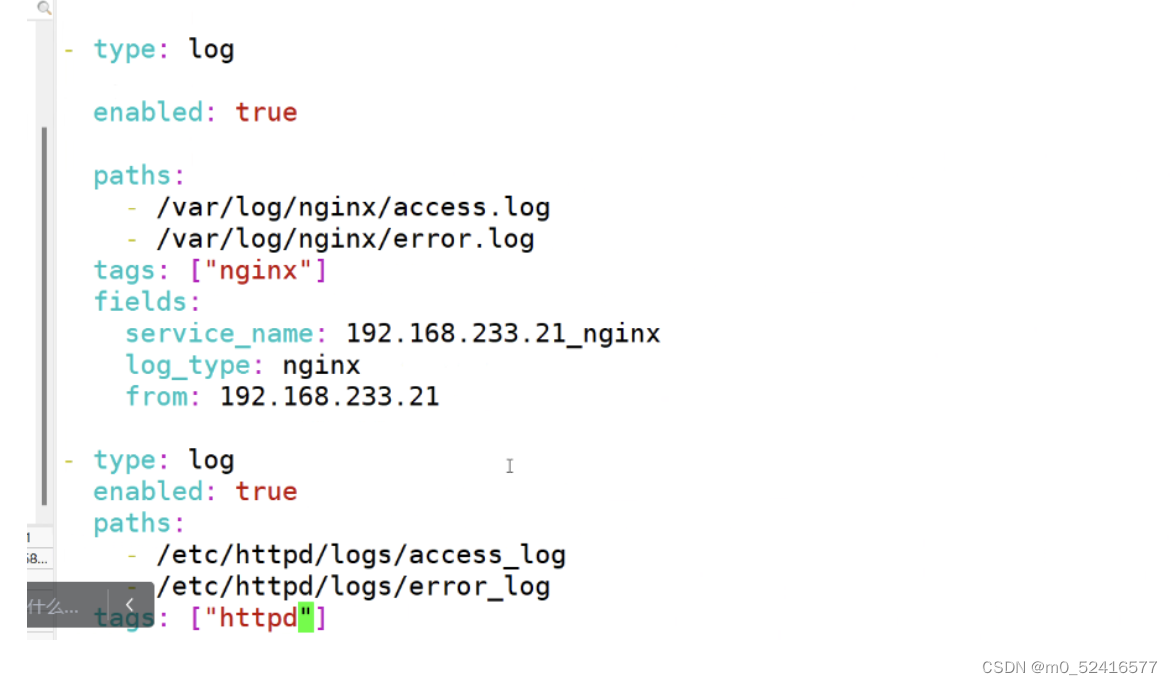
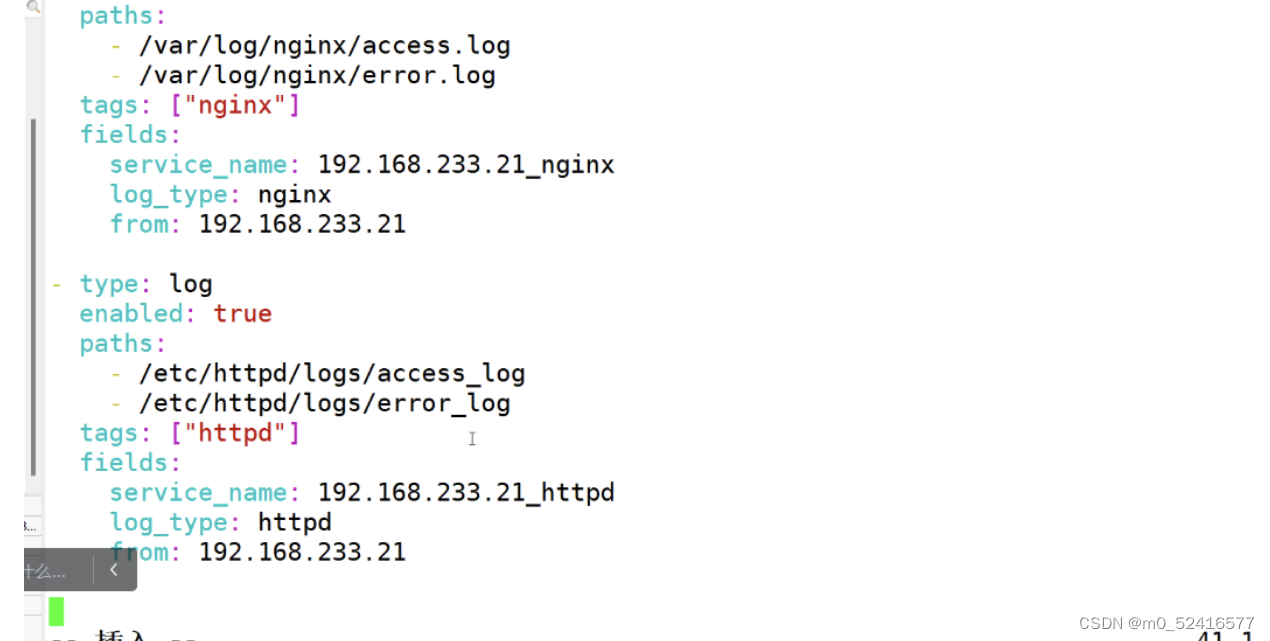
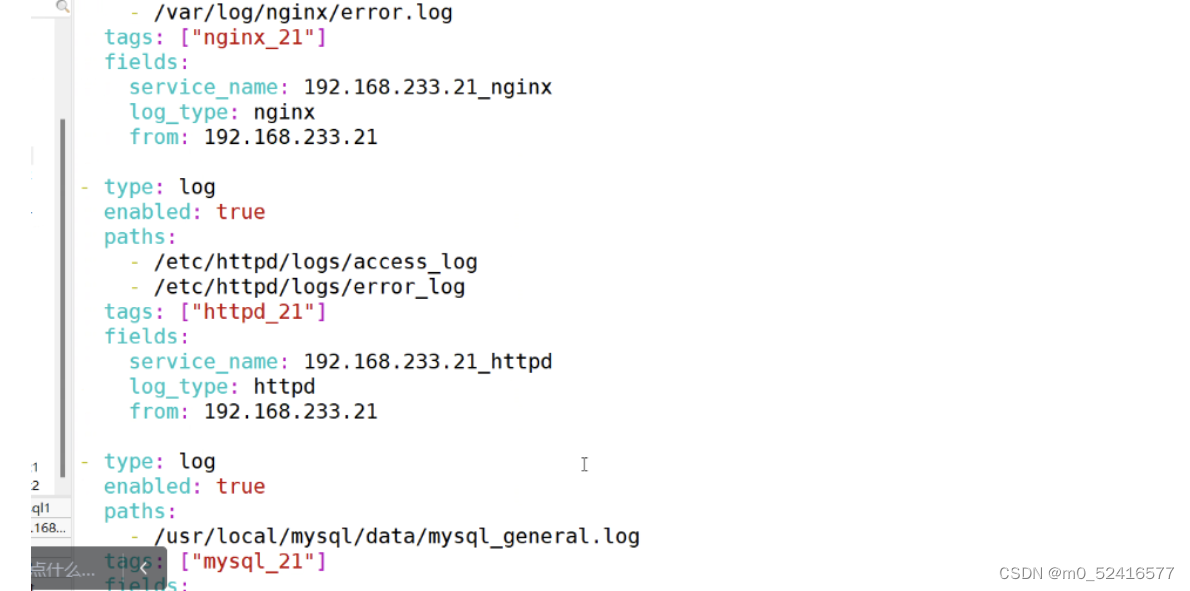
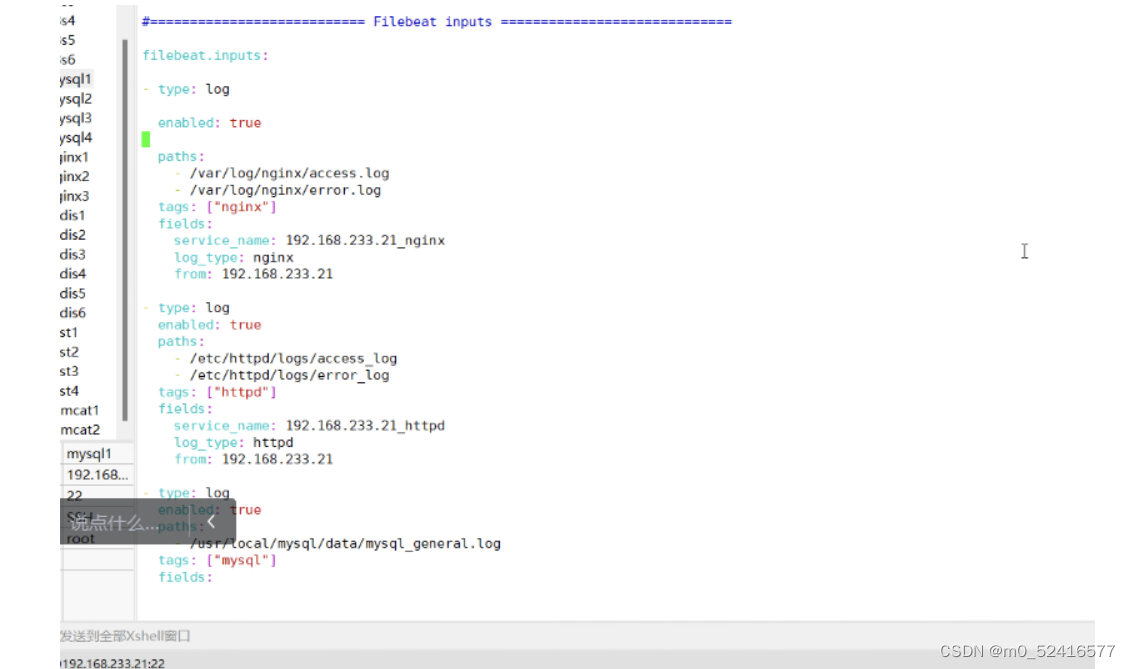 配置conf
配置conf
input {
beats { port=>"5045" }
}
output {
if "nginx_21" in [tags] {
elasticsearch {
hosts => ["20.0.0.77:9200","20.0.0.121:9200"]
index => "%{[fields] [service_name]}-%{+YYYY.MM.dd}"
}
}
if "httpd_21" in [tags] {
elasticsearch {
hosts => ["20.0.0.77:9200","20.0.0.121:9200"]
index => "%{[fields] [service_name]}-%{+YYYY.MM.dd}"
}
}
if "mysql_21" in [tags] {
elasticsearch {
hosts => ["20.0.0.77:9200","20.0.0.121:9200"]
index => "%{[fields] [service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec =>rubydebug
}
}
nohup ./filebeat -e -c filebeat.yml > filebeat.out &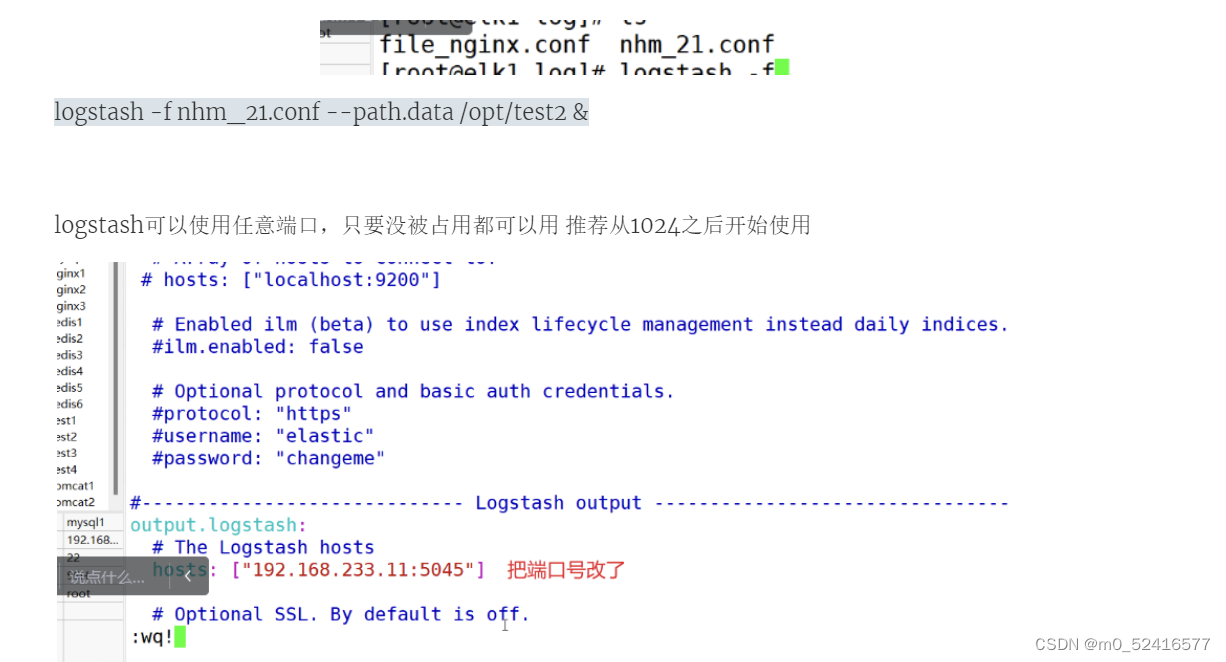
如何来对logstash性能上的小优化
logstash启动是在jvm虚拟机上当中其中,启动一次至少需要500M内存
pipeline.workers: 2
logstash工作线程,默认值就是cpu数,4 2 8 4给一般即可 2核, 2个
pipeline.batch.size: 125
一次性能够批量处理检索事件的大小 125条数 性能强设置成200
pioeline.batch.delay: 50
查询更新的延迟 50毫秒,也可以自行调整。15 10 也要看机器性能