文章目录
- 前言
- 一、从外部迭代到内部迭代
- 二、实现机制
- 三、常用的流操作
- 1.collect(toList())
- 2.map
- 3.filter
- 4.flatMap
- 5.max和min
- 6.reduce
- 四、多次调用流操作
- 五、高阶函数
- 总结
前言
流是一系列与特定存储机制无关的元素——实际上,流并没有 “存储” 之说。利用流,我们无需迭代集合中的元素,就可以提取和操作它们。这些管道通常被组合在一起,在流上形成一条操作管道。
在大多数情况下,将对象存储在集合中是为了处理他们,因此你将会发现你将把编程的主要焦点从集合转移到了流上。流的一个核心好处是,它使得程序更加短小并且更易理解。当 Lambda 表达式和方法引用(method references)和流一起使用的时候会让人感觉自成一体。
一、从外部迭代到内部迭代
我们在使用集合类时,一个通用的模式是在集合上进行迭代,然后处理返回的每一个元素。比如要计算从上海来的艺术家的人数:
public class Artist {
private String from;
public Artist(String from) {
this.from = from;
}
public String getFrom() {
return from;
}
public void setFrom(String from) {
this.from = from;
}
public static void main(String[] args) {
int count = 0;
List<Artist> artists = new ArrayList<>();
artists.add(new Artist("上海"));
artists.add(new Artist("成都"));
artists.add(new Artist("北京"));
for (Artist artist : artists) {
if ("上海".equals(artist.getFrom())) {
count++;
}
}
}
}
尽管这样的操作可行,但存在几个问题。每次迭代集合类时,都需要写很多样板代码。将 for 循环改造成并行方式运行也很麻烦,需要修改每个 for 循环才能实现。
此外,上述代码无法流畅传达程序员的意图。for 循环的样板代码模糊了代码的本意,程序员必须阅读整个循环体才能理解。若是单一的 for 循环,倒也问题不大,但面对一个满是循环(尤其是嵌套循环)的庞大代码库时,负担就重了。
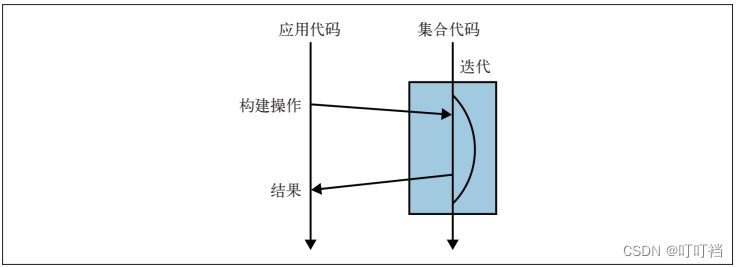
就其背后的原理来看,for 循环其实是一个封装了迭代的语法糖,我们在这里多花点时间,看看它的工作原理。首先调用 iterator 方法,产生一个新的 Iterator 对象,进而控制整个迭代过程,这就是外部迭代。迭代过程通过显式调用 Iterator 对象的 hasNext 和 next方法完成迭代。
Iterator<Artist> iterator = artists.iterator();
while(iterator.hasNext()) {
Artist artist = iterator.next();
if ("上海".equals(artist.getFrom())) {
count++;
}
}
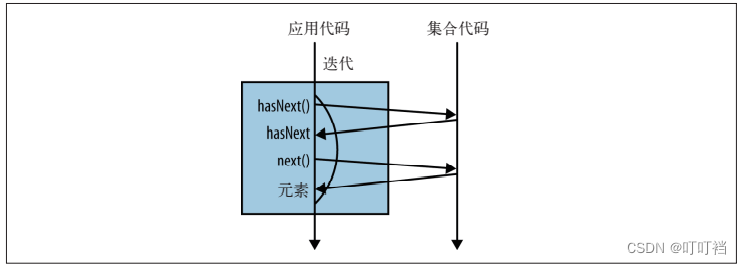
另一种方法就是内部迭代,如下所示。首先要注意 stream() 方法的调用,它和上面调用 iterator() 的作用一样。该方法不是返回一个控制迭代的 Iterator 对象,而是返回内部迭代中的相应接口:Stream。
long c = artists.stream().filter(artist -> "上海".equals(artist.getFrom())).count();
二、实现机制
上述整个过程被分解为两种更简单的操作:过滤和计数。通常,在 Java 中调用一个方法,计算机会随即执行操作:比如,System.out.println(“Hello World”); 会在终端上输出一条信息。Stream 里的一些方法却略有不同,它们虽是普通的 Java 方法,但返回的 Stream 对象却不是一个新集合,而是创建新集合的配方。
artists.stream().filter(artist -> “上海”.equals(artist.getFrom()));
这行代码并未做什么实际性的工作,filter 只刻画出了 Stream,但没有产生新的集合。像 filter 这样只描述 Stream,最终不产生新集合的方法叫作惰性求值方法;而像 count 这样最终会从 Stream 产生值的方法叫作及早求值方法。
如果在过滤器中加入一条 println 语句,来输出艺术家的名字,就能轻而易举地看出其中的不同,艺术家名字没有被输出。
artists.stream().filter(artist -> {
System.out.println(artist.getFrom());
return "上海".equals(artist.getFrom());
});

如果将同样的输出语句加入一个拥有终止操作的流,如上面的计数操作,艺术家的名字就会被输出
artists.stream().filter(artist -> {
System.out.println(artist.getFrom());
return "上海".equals(artist.getFrom());
}).count();

判断一个操作是惰性求值还是及早求值很简单:只需看它的返回值。如果返回值是 Stream,那么是惰性求值;如果返回值是另一个值或为空,那么就是及早求值。使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果,这正是它的合理之处。
三、常用的流操作
为了更好地理解 Stream API,掌握一些常用的 Stream 操作十分必要。除此处的几种重要操作之外,该 API 的 Javadoc 中还有更多信息。
1.collect(toList())
collect(toList()) 方法由 Stream 里的值生成一个列表,是一个及早求值操作。
Stream 的 of 方法使用一组初始值生成新的 Stream。事实上,collect 的用法不仅限于此,它是一个非常通用的强大结构,下面是使用 collect 方法的一个例子:
List<String> collected = Stream.of("a", "b", "c").collect(Collectors.toList());
这段程序展示了如何使用 collect(toList()) 方法从 Stream 中生成一个列表。由于很多 Stream 操作都是惰性求值,因此调用 Stream 上一系列方法之后,还需要最后再调用一个类似 collect 的及早求值方法。
2.map
如果有一个函数可以将一种类型的值转换成另外一种类型,map 操作就可以使用该函数,将一个流中的值转换成一个新的流。使用 map 操作将字符串转换为大写形式:
List<String> collected = Stream.of("a", "b", "c").map(s -> s.toUpperCase()).collect(Collectors.toList());
传给 map 的 Lambda 表达式只接受一个 String 类型的参数,返回一个新的 String。参数和返回值不必属于同一种类型,但是 Lambda 表达式必须是 Function 接口的一个实例,Function 接口是只包含一个参数的普通函数接口。
3.filter
遍历数据并检查其中的元素时,可尝试使用 Stream 中提供的新方法 filter 进行过滤筛选。
假设要找出一组数字中大于5的,如下展示了如何使用函数式风格编写实现代码:
List<Integer> nums = Stream.of(1, 2, 8).filter(i -> i > 5).collect(Collectors.toList());
和 map 很像,filter 接受一个函数作为参数,该函数用 Lambda 表达式表示。该函数和前面示例中 if 条件判断语句的功能一样,如果数字大于5,则返回 true。
由于此方法和 if 条件语句的功能相同,因此其返回值肯定是 true 或者 false。经过过滤,Stream 中符合条件的,即 Lambda 表达式值为 true 的元素被保留下来。该 Lambda 表达式的函数接口正是前面介绍过的 Predicate。
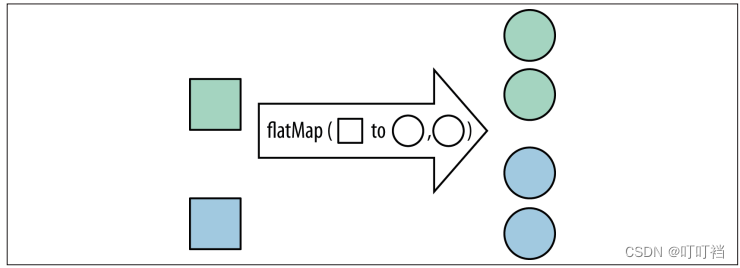
4.flatMap
flatMap 方法可用 Stream 替换值,然后将多个 Stream 连接成一个 Stream。
List<Integer> together = Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4))
.flatMap(numbers -> {
System.out.println(numbers);
return numbers.stream();
})
.collect(Collectors.toList());
System.out.println(together);

调用 stream 方法,将每个列表转换成 Stream 对象,其余部分由 flatMap 方法处理。flatMap 方法的相关函数接口和 map 方法的一样,都是 Function 接口,只是方法的返回值限定为 Stream 类型罢了。
5.max和min
Stream 上常用的操作之一是求最大值和最小值。Stream API 中的 max 和 min 操作足以解决这一问题。
int max = Stream.of(5, 2, 4).max(Comparator.comparingInt(o -> o)).get();
int min = Stream.of(5, 2,2, 4).min(Comparator.comparingInt(o -> o)).get();
查找 Stream 中的最大或最小元素,首先要考虑的是用什么作为排序的指标。为了让 Stream 对象按照曲大小进行排序,需要传给它一个 Comparator 对象。静态方法 comparingInt 可以方便地实现一个比较器。
6.reduce
reduce 操作可以实现从一组值中生成一个值。在上述例子中用到的 count、min 和 max 方法,因为常用而被纳入标准库中。事实上,这些方法都是 reduce 操作。
如下展示了如何通过 reduce 操作对 Stream 中的数字求和。以 0 作起点——一个空Stream 的求和结果,每一步都将 Stream 中的元素累加至 accumulator,遍历至 Stream 中的最后一个元素时,accumulator 的值就是所有元素的和。
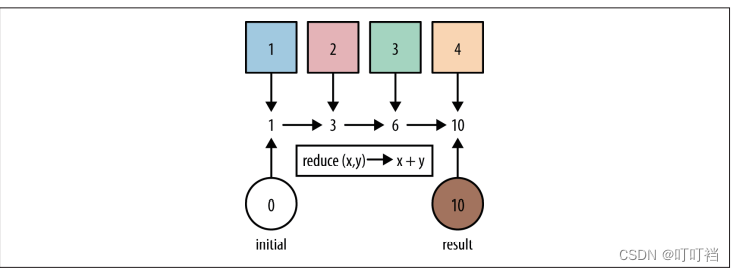
int num = Stream.of(1, 2, 3).reduce(0, (acc, element) -> acc + element);

四、多次调用流操作
用户也可以选择每一步强制对函数求值,而不是将所有的方法调用链接在在这里插入代码片一起,但是,最好不要如此操作。错误例子:
List<Artist> musicians = Stream.of(new Artist("上海")).collect(Collectors.toList());
List<Artist> bands = musicians.stream().filter(artist -> artist.getFrom().startsWith("The")).collect(Collectors.toList());
Set<String> origins = bands.stream().map(artist -> artist.getNationality()).collect(Collectors.toSet());
- 代码可读性差,样板代码太多,隐藏了真正的业务逻辑;
- 效率差,每一步都要对流及早求值,生成新的集合;
- 代码充斥一堆垃圾变量,它们只用来保存中间结果,除此之外毫无用处;
- 难于自动并行化处理。
正确示范:
Set<String> origins = Stream.of(new Artist("上海"))
.filter(artist -> artist.getFrom().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(Collectors.toSet());
五、高阶函数
本文中不断出现被函数式编程程序员称为高阶函数的操作。高阶函数是指接受另外一个函数作为参数,或返回一个函数的函数。高阶函数不难辨认:看函数签名就够了。如果函数的参数列表里包含函数接口,或该函数返回一个函数接口,那么该函数就是高阶函数。
map 是一个高阶函数,因为它的 mapper 参数是一个函数。事实上,本文介绍的 Stream 接口中几乎所有的函数都是高阶函数。之前的排序例子中还用到了 comparing 函数,它接受一个函数作为参数,获取相应的值,同时返回一个 Comparator。Comparator 可能会被误认为是一个对象,但它有且只有一个抽象方法,所以实际上是一个函数接口。
事实上,可以大胆断言,Comparator 实际上应该是个函数,但是那时的 Java 只有对象,因此才造出了一个类,一个匿名类。成为对象实属巧合,函数接口向正确的方向迈出了一步。
总结
内部迭代将更多控制权交给了集合类;和 Iterator 类似,Stream 是一种内部迭代方式;将 Lambda 表达式和 Stream 上的方法结合起来,可以完成很多常见的集合操作。