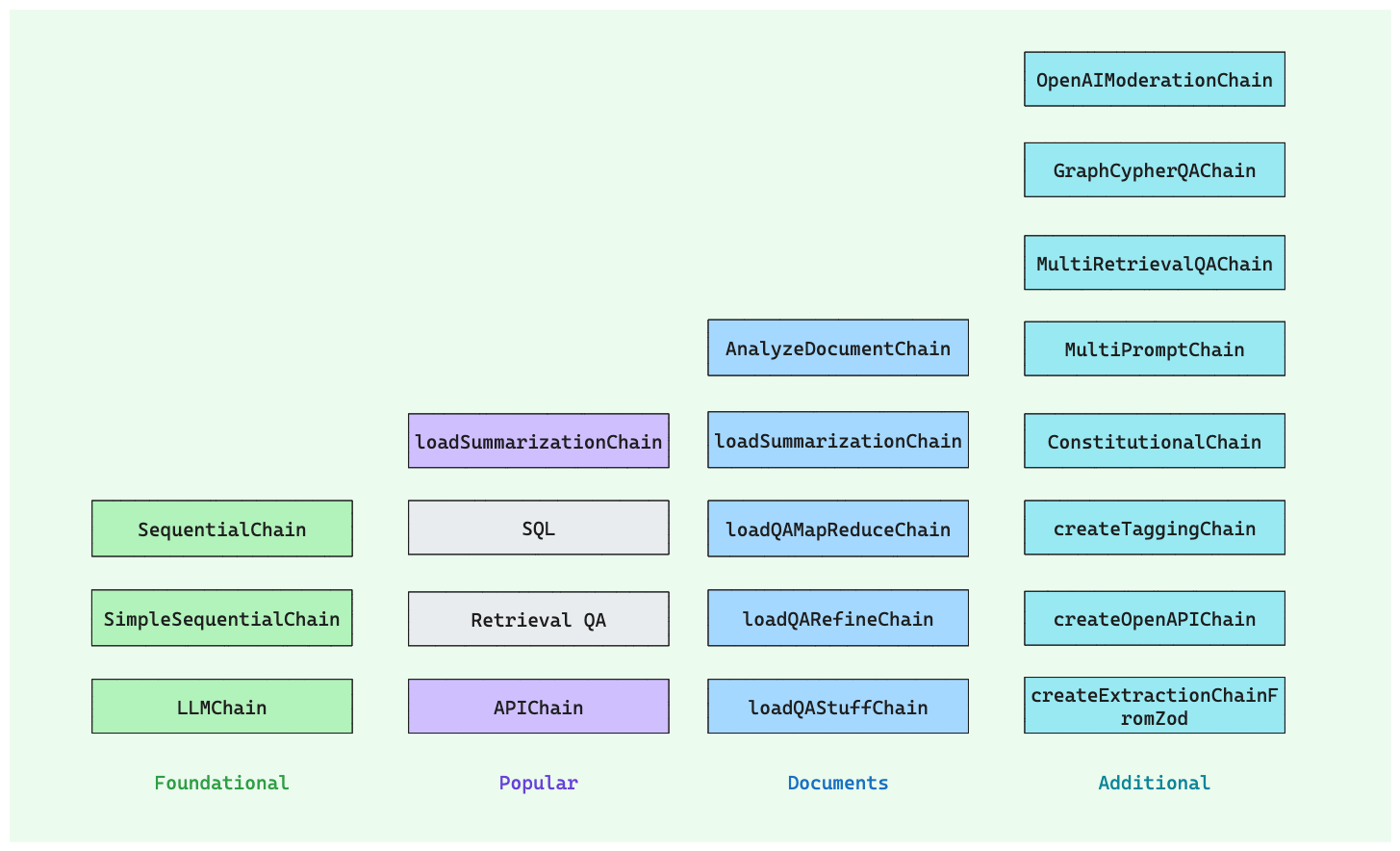
LLaVA-V1(2023/04)

网络结构
如下图 所示为 LLaVA-v1 的模型结构,可以看出其简化了很多,但整体来说还是由三个组件构成:
-
Vision Encoder:和 Flamingo 模型的 Vision Encoder 作用一样,也是用于提取视觉特征,作者采用的是CLIP ViT-L/14。
-
Projection W:其比 Flamingo 中的 Perceiver Resampler和 BLIP-2 中的 Q-Former 简单得多,只是一层简单的 Linear,将 image feature 映射到 LLM 的 word embedding 空间。
-
Large Language Model:和 Flamingo 模型的 LLM 作用相同,用于生成文本,不过作者没有对 LLM 的结构进行修改,直接使用了 基于LLaMA的Vicuna-v1.5 13B 模型。

训练
作者基于ChatGPT or GPT-4设计了一种策略,将现有的图像-文本对数据集,转化为具有更多多样性的视觉-语言指令数据集,从而用于端到端微调LLaVA模型。
模型训练任务是预测Assitant的答案和停止符,因此一条指令微调样本中,只有绿色部分是计算loss的,样本示例如下图所示

模型的训练分成以下2步进行:(采用的是图像-文本对数据转化成的指令微调数据)
- 首先,冻结住视觉编码器和LLM,只训练线性投影层W,从而将视觉特征和LLM的语言编码空间对齐。
- 然后,冻结住视觉编码器,训练线性投影层和LLM
LLaVA-v1.5(2023/08)
论文: Improved Baselines with Visual Instruction Tuning

网络结构
与LLaVA-v1相比变化很小,主要包括:
-
Vision Encoder:输入图像从 LLaVA-1 的 224x224 扩展到 336x336,作者采用的是CLIP ViT-L/336px。
-
Vision-Language Connector:从 LLaVA-1 的单层 Linear 扩展为两层 MLP,中间使用 GELU 激活。
-
Large Language Model:从 LLaVA-1 的 Vicuna-v1.3 13B扩展为 Vicuna-v1.5 13B。
-
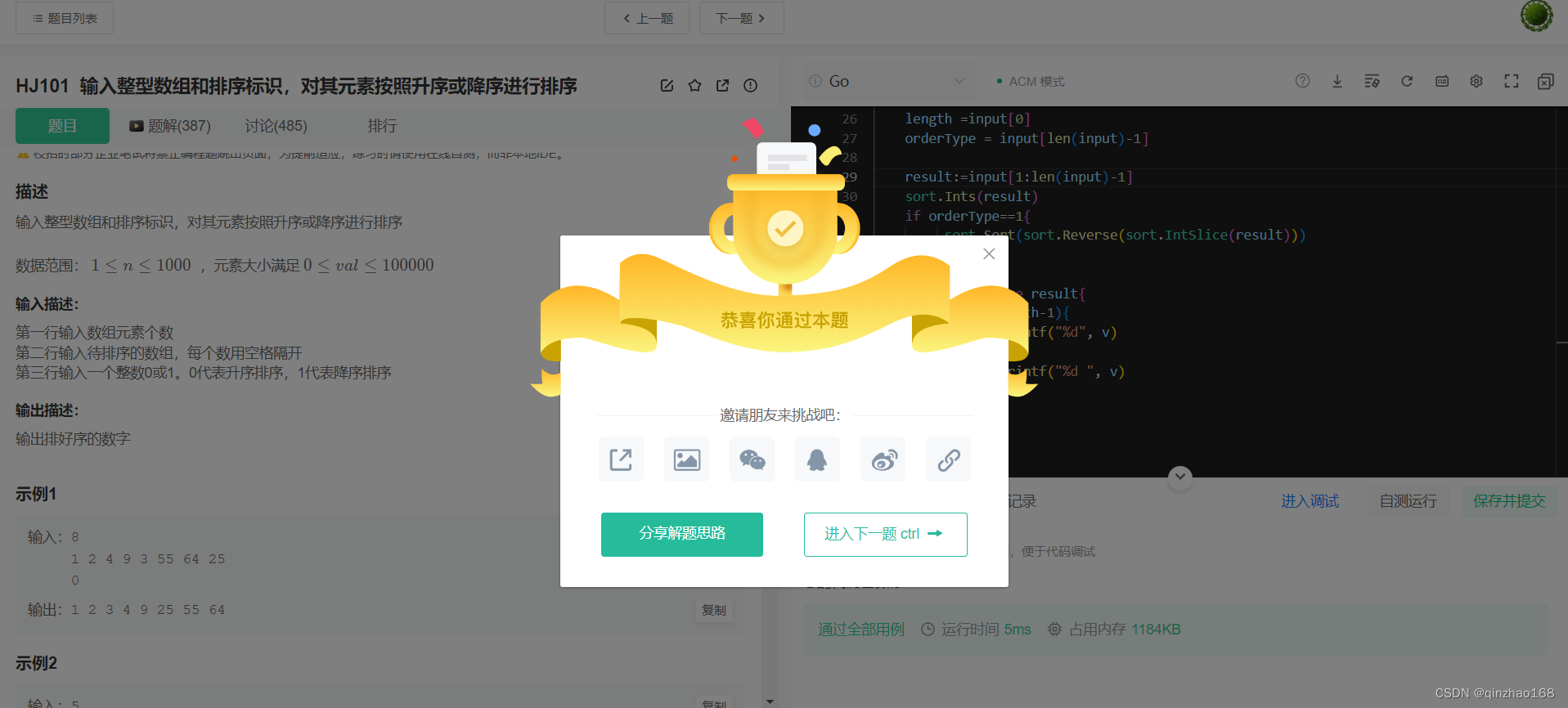
指令微调训练数据:增加了面向学术任务的视觉问答数据样本。
训练
训练一个指令跟随的视觉-语言多模态大模型LMM,通常分成2步:
- 采用图像-文本对数据集,将视觉特征对齐到大语言模型的语言word embedding space
- visual instruction tuning阶段
MiniGPT-v1(2023/04)
论文:[2304.10592v2] MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
网络结构
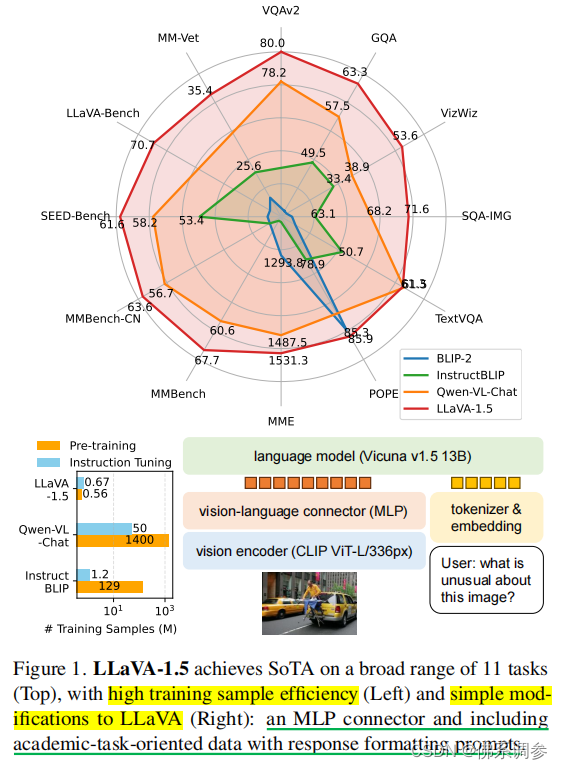
MiniGPT-4 的模型结构如下图所示,可以看出其和 BLIP-2 几乎一样:
-
Vision Encoder:直接使用了 BLIP-2 的方案,作者用的是EVA-CLIP ViT-G/14。
-
Projection:BLIP-2 的 Q-Former 也完整保留,同样后面增加了一层可训练的 Linear 层。
-
Large Language Model:使用 Vicuna-v0 模型作为 LLM。
训练
训练分成两步
- 特征对齐预训练:在整个预训练阶段,Vision Encoder + Q-Former 和 LLM 都保持冻结状态,只训练线性投影层。作者使用了 Conceptual Caption 数据集,SBU 数据集和 LAION 数据集的集合来训练,batch-size 为 256,经过 20,000 个 step,大概覆盖了 5M 个图像-文本对。整个过程在 4xA100 80G GPU 上经过 10 个小时训练完成。(预训练的LMM生成内容不够自然,还需要采用少量高质量数据进行进一步微调)
- 端到端微调:在微调阶段,作者从 Conceptual Caption 数据集中随机选择了 5,000 个图像,然后用预训练的模型为每个图像生成了一个文本描述,之后在经过一系列处理,最终挑选出 3,500 左右的高质量图像-文本对构成微调阶段的数据集。基于此,只需训练 400 个 step,batch size 为 12,在单个 A100 上 7 分钟即可完成训练。
MiniGPT-v2(2023/08)
论文:MiniGPT-v2:large language model as a unified interface for vision-language multi-task learning
网络结构
由三部分组成
- 视觉编码器:将 EVA([2211.07636] EVA: Exploring the Limits of Masked Visual Representation Learning at Scale) 作为视觉主干,并在整个模型训练期间冻结视觉主干。
-
Projection:采用更高分辨率的图像(448x448),投影所有图像 Token 会导致非常长的序列输入,其会显著降低训练和推理效率。因此,作者在嵌入空间中(ViT的输出层)将相邻的 4 个视觉 Token拼接起来,并将它们一起投影到大型语言模型的embedding 中,从而将视觉输入 Token 的数量减少了 75%。
-
Large Language Model:使用开源的 LLaMA2-chat(7B,[2302.13971] LLaMA: Open and Efficient Foundation Language Models)作为语言模型主干。
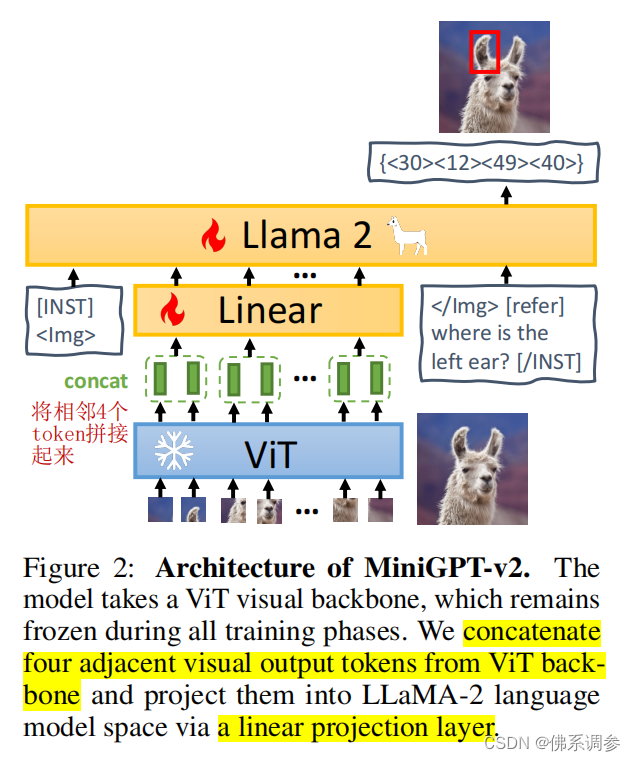
Multi-task Instruction Template
一个多模态大模型同时用于多种视觉-语言任务时,输出内容可能是不明确的。例如,当问图像中某个人的位置时,大模型的输出既可以是bounding box坐标形式,也可以是自然语言格式(例如upper right corner)。为了缓解这种不明确,降低LMM对多种任务的学习难度,作者提出multi-task instruction template中增加task-specific tokens(任务相关的标记符)
输入模板格式如下图所示:[INST]是user role,[/INST]是assignment role。将user input分成三部分:图像特征 + 任务标识符 + Instruction
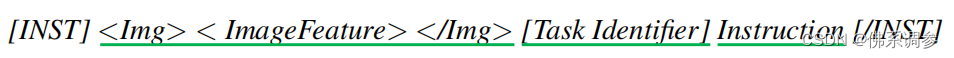
如下表1所示针对6种不同任务,设计了6种不同的标识符token,以减少各种任务之间的歧义。分别对应视觉问答(VQA)、图像描述(Image Caption)、图像定位描述(Grounded Caption)、指示表达理解(REC)、指示表达生成(REG)以及目标解析和定位(Object Parsing and Grounding,模型从输入文本中提取目标并检测它们对应的位置)。对于与视觉无关的指令,模型不会使用任何任务标识 Token。

训练
在整个训练过程中,MiniGPT-v2 的 Vision Encoder 都保持冻结状态。主要训练线性投影层、并使用 LoRA 有效地对 LLM 进行对齐。在 LoRA 中, 作者通过低秩适配器来微调 Wq 和 Wv,实现中,设置 rank = 64。所有阶段都以 448x448 的图像分辨率训练模型。在每个阶段,都是用设计的多模态指令模板进行视觉-语言任务训练。整个训练分成三个阶段:
- 第一阶段:预训练
为了拥有更广泛的视觉语言知识,作者在弱标签和细粒度数据集上进行混合训练,并给予弱标签数据更高的采样率,以便获得更多样化的知识。最终在 8xA100 GPU 上训练 400,000 步,全局批量大小为 96,最大学习率为 1e-4。这个阶段大约需要 90 个小时。
- 第二阶段:多任务训练
为了提高 MiniGPT-v2 在每个任务上的性能,作者排除了第一阶段中的弱标签数据集,例如 GRIT-20M 和 LAION,在此阶段只使用细粒度数据集进行训练,并根据每个任务的频率更新数据采样率。此策略使提出的模型能够优先考虑高质量的对齐图像-文本数据,以便在各种任务上实现卓越性能。训练模型对应后文的 MiniGPT-v2。最终在 4xA100 GPU 上训练 50,000 步,最大学习率为 1e-5,采用 64 的全局批量大小,此训练阶段持续大约 20 小时。
- 第三阶段:多模态指令微调
在第二阶段细粒度数据集基础上添加了多模态指令微调数据集(多模态指令微调数据集具有更大的采样频率),包括来自 LLaVA 的详细描述和复杂推理数据。在 4xA100 GPU 上再执行 35,000 个步骤的训练,使用 24 的全局 batch 大小,此训练阶段大约需要 7 小时,保持相同的最大学习率 1e-5。
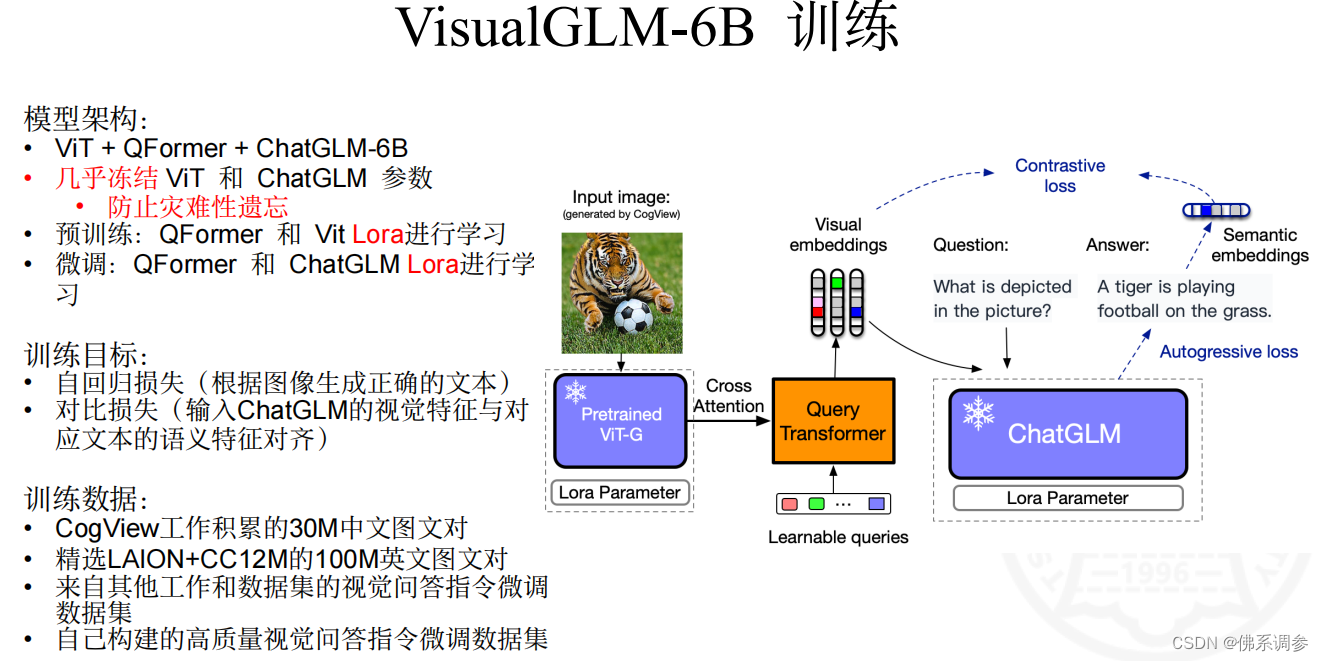
VisualGLM-6B(2023/05)
CogVLM(2023/10)
论文:CogVLM: Visual Expert for Large Language Models

网络结构
如下图 Figure 3 所示为 CogVLM 的模型结构,可以看出还是三个主要模块,不过对 LLM 进行了较大的修改:
-
Vision Encoder:直接使用预训练的 EVA-CLIP ViT-E/14([2303.15389] EVA-CLIP: Improved Training Techniques for CLIP at Scale),作者删除了 ViT 的最后一层,因为它是专门用于聚合特征以便进行对比学习的。
-
MLP Adapter:使用两层 MLP,用于将 ViT 的输出映射到文本特征空间。所有图像特征在LLM中共享相同的位置编码
-
Large Language Model:作者向Transformer 每一层都添加了一个visual expert module,以实现视觉-语言特征的深度对齐。具体来说,每一层的 visual expert module 都包含 QKV 矩阵和 MLP层,它们的形状与大语言模型中的形状相同,并且都是从 LLM 内的对应模块作为初始化权重。这样做的动机是:语言模型中的每个注意力头部都能捕捉到语义信息的某些方面,而可训练的visual expert 可以将图像特征与LLM不同的头部对齐,从而实现视觉-语言特征的深度融合。
训练
(1)预训练
数据采用图像-文本对,分成2个步骤:
- 采用image captioning loss,即预测文本中的下一个单词
- 采用image caption和Referring Expression Comprehension(REC)的混合训练任务。REC的训练任务是输出图像中物体的坐标,例如:"Question: Where is the object?” and “Answer: [[x0, y0, x1, y1]]”.
(2)有监督微调SFT
训练得到的模型称为CogVLM-Chat
采用高质量的多任务SFT数据,总共约50w VQA对数据
迭代8000次,batch size=640,基础学习率采用10-5,为了防止LLM过拟合,LLM部分的学习率是其他部分学习率的0.1倍。除了ViT外,其余部分的网络参数都进行更新。
Qwen-VL(2023/08)
来自阿里团队
论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
网络结构
其结构也由三个模块组成:
-
Vision Encoder:采用的是 OpenCLIP ViT-G/14,在第一和第二阶段的预训练阶段会微调。
-
Large Language Model:采用 Qwen-7B 作为 LLM,并且在训练的第一阶段保持冻结。
-
vision language Adapter:采用单层的 Cross Attention 模块,和 Q-Former 类似,包含一组可学习的 Query 向量(ViT是输出作为cross attention的keys)。经消融实验,选择了最优的 256 个 Query,这样视觉特征序列的长度就为固定的256,从而提高了效率。最后将长度为256的视觉特征输入LLM。
输入输出格式
- 图像输入:在固定长度为256的视觉特征嵌入的前后,加上特殊的标记符<img>和</img>
- bounding box的输入输出:对应任意的bbox,要标准化到[0,1000];将坐标转化为指定的字符串形式:"(Xtopleft, Ytopleft),(Xbottomright, Ybottomright)". 这个字符被分词成文本,不需要额外的位置词汇;为了与常规的文本字符串区分,在bbox字符串前后增加<box>和</box>特殊token;还增加特征字符<ref>和</ref>。
训练
训练分成3个阶段:2个预训练 + 1个指令微调
(1)预训练
数据集采用一个大规模的、弱标记的、网络爬取的图像-文本对集。收集的开源+阿里自家的数据集原始为5B,清洗之后保留1.4B用于训练,其中77.3%为英语,22.7%为中文文本。冻结LLM,只训练ViT和VL适配器, 图像大小采用224x224,训练目标函数为预测下一个token。

(2)多任务预训练
同时采用了7种任务的训练数据,将相同的任务数据打包成长度为2048的序列来构建交错的图像-文本数据。图像分辨率增大到448x448。此阶段训练整个模型,包括LLM。经过此阶段训练后的模型称为Qwen-VL。
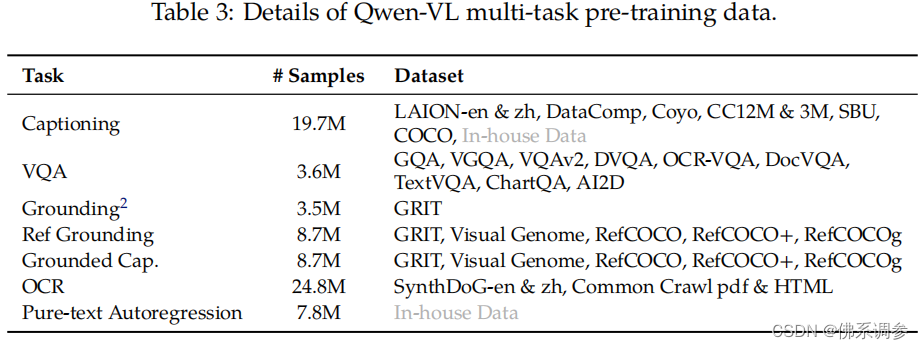
(3)指令微调
主要采用image caption数据 + 对话数据,一共350K。 冻结住ViT,只训练LLM和VL适配器。经过此阶段训练后的模型称为Qwen-VL-Chat