机器学习笔记之Sigmoid信念网络——醒眠算法
- 引言
- 回顾
- 醒眠算法
- 基于平均场假设变分推断求解后验概率
- 平均场理论求解后验的弊端
- 醒眠算法
引言
上一节介绍了对 Sigmoid \text{Sigmoid} Sigmoid信念网络学习任务过程中,对模型参数的对数似然梯度进行求解,并描述了梯度求解过程中的问题。本节将针对该问题介绍醒眠算法。
回顾
Sigmoid \text{Sigmoid} Sigmoid信念网络的模型表示
Sigmoid
\text{Sigmoid}
Sigmoid信念网络是一个有向概率图模型。已知一个模型表示如下:
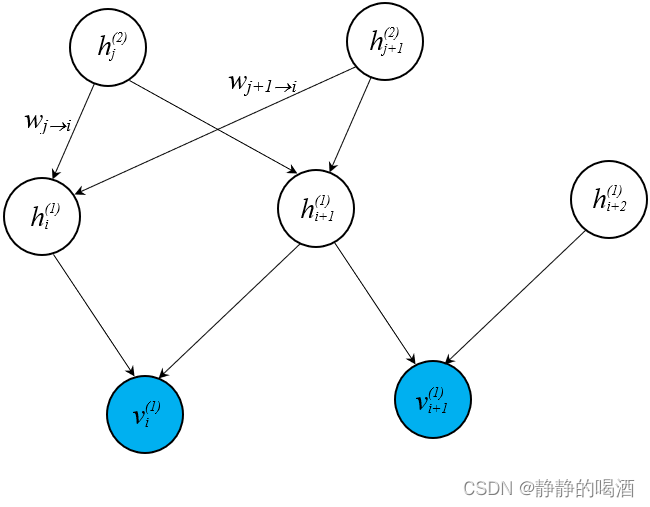
以隐变量
h
i
(
1
)
h_i^{(1)}
hi(1)为例,如果将其作为后验结点,它的条件结点有
h
j
(
2
)
,
h
j
+
1
(
2
)
h_j^{(2)},h_{j+1}^{(2)}
hj(2),hj+1(2)两个。根据
Sigmoid
\text{Sigmoid}
Sigmoid信念网络的定义,关于
h
i
(
1
)
h_i^{(1)}
hi(1)的后验概率表示如下:
P
(
h
i
(
1
)
∣
h
j
(
2
)
,
h
j
+
1
(
2
)
)
=
{
σ
(
W
j
→
i
⋅
h
j
(
2
)
+
W
j
+
1
→
i
⋅
h
j
+
1
(
2
)
)
h
i
(
1
)
=
1
1
−
σ
(
W
j
→
i
⋅
h
j
(
2
)
+
W
j
+
1
→
i
⋅
h
j
+
1
(
2
)
)
h
i
(
1
)
=
0
\mathcal P(h_i^{(1)} \mid h_j^{(2)},h_{j+1}^{(2)}) = \begin{cases} \sigma \left(\mathcal W_{j \to i} \cdot h_j^{(2)} + \mathcal W_{j+1 \to i} \cdot h_{j+1}^{(2)}\right) \quad h_i^{(1)} = 1 \\ 1 - \sigma\left(\mathcal W_{j \to i} \cdot h_j^{(2)} + \mathcal W_{j+1 \to i} \cdot h_{j+1}^{(2)}\right) \quad h_i^{(1)} = 0 \end{cases}
P(hi(1)∣hj(2),hj+1(2))=⎩
⎨
⎧σ(Wj→i⋅hj(2)+Wj+1→i⋅hj+1(2))hi(1)=11−σ(Wj→i⋅hj(2)+Wj+1→i⋅hj+1(2))hi(1)=0
其中
σ
\sigma
σ表示
Sigmoid
\text{Sigmoid}
Sigmoid函数。仔细观察发现,
P
(
h
i
(
1
)
=
1
∣
h
j
(
2
)
,
h
j
+
1
(
2
)
)
\mathcal P(h_i^{(1)} = 1 \mid h_j^{(2)},h_{j+1}^{(2)})
P(hi(1)=1∣hj(2),hj+1(2))就可以看作是
h
i
(
1
)
h_i^{(1)}
hi(1)作为入度相关联结点的线性组合后套一层
Sigmoid
\text{Sigmoid}
Sigmoid函数。因而可以通过该规律描述所有结点的后验概率:
P
(
h
i
∣
h
j
;
j
→
i
)
=
{
σ
(
∑
j
→
i
W
j
→
i
⋅
h
j
)
h
i
=
1
1
−
σ
(
∑
j
→
i
W
j
→
i
⋅
h
j
)
h
i
=
0
\mathcal P(h_i \mid h_j;j \to i) = \begin{cases} \sigma \left(\sum_{j \to i} \mathcal W_{j \to i} \cdot h_j\right) \quad h_i = 1\\ 1 - \sigma \left(\sum_{j \to i} \mathcal W_{j \to i} \cdot h_j \right) \quad h_i = 0 \end{cases}
P(hi∣hj;j→i)=⎩
⎨
⎧σ(∑j→iWj→i⋅hj)hi=11−σ(∑j→iWj→i⋅hj)hi=0
将上述分段结果描述成一个通式,可以表达为:
P
(
h
i
∣
h
j
;
j
→
i
)
=
σ
[
(
2
h
i
−
1
)
∑
j
→
i
W
j
→
i
⋅
h
j
]
\mathcal P(h_i \mid h_j;j \to i) = \sigma \left[(2h_i - 1) \sum_{j \to i} \mathcal W_{j \to i} \cdot h_j \right]
P(hi∣hj;j→i)=σ[(2hi−1)j→i∑Wj→i⋅hj]
Sigmoid \text{Sigmoid} Sigmoid信念网络——对数似然梯度求解过程中的问题
与玻尔兹曼机、受限玻尔兹曼机相同,概率图模型中的观测变量均来自 样本集合
V
=
{
v
(
i
)
}
i
=
1
N
\mathcal V = \{v^{(i)}\}_{i=1}^N
V={v(i)}i=1N。以某一具体样本
v
(
k
)
∈
V
v^{(k)} \in \mathcal V
v(k)∈V为例,在
Sigmoid
\text{Sigmoid}
Sigmoid信念网络中的随机变量集合
S
(
k
)
\mathcal S^{(k)}
S(k)表示如下:
S
(
k
)
=
{
v
(
k
)
,
h
(
k
)
}
\mathcal S^{(k)} = \{v^{(k)},h^{(k)}\}
S(k)={v(k),h(k)}
此时,以某隐变量
h
i
(
k
)
h_i^{(k)}
hi(k)与隐变量
h
j
(
k
)
h_j^{(k)}
hj(k)之间的因果关系为例,其在概率图中的表示如下:
(
h
i
(
k
)
,
h
j
(
k
)
∈
h
(
k
)
)
(h_i^{(k)},h_j^{(k)} \in h^{(k)})
(hi(k),hj(k)∈h(k))
这仅仅是一个示例,概率图中任意一组包含因果关系的随机变量结点均可以进行表示,无论它是观测变量还是隐变量。
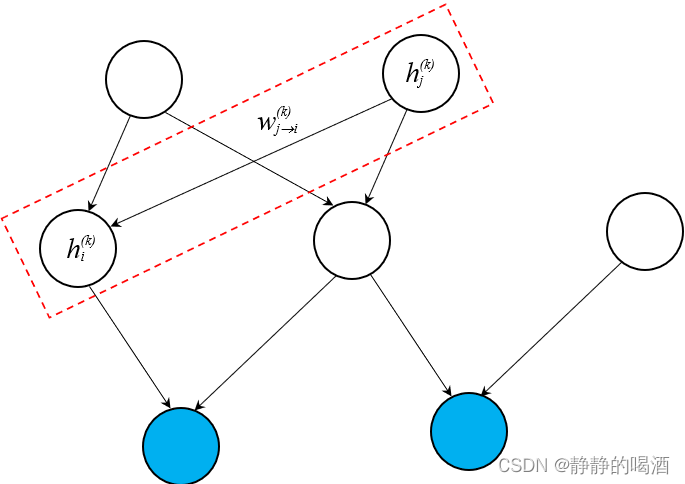
对应两隐变量之间 模型参数
W
j
→
i
(
k
)
\mathcal W_{j \to i}^{(k)}
Wj→i(k)的对数似然梯度 表示如下:
详细推导过程见
Sigmoid
\text{Sigmoid}
Sigmoid信念网络(一)对数似然梯度
∂
∂
W
j
→
i
[
∑
v
(
k
)
∈
V
log
P
(
v
(
k
)
)
]
=
∑
v
(
k
)
∈
V
∑
h
(
k
)
P
(
h
(
k
)
∣
v
(
k
)
)
⋅
σ
[
−
(
2
h
i
(
k
)
−
1
)
⋅
∑
j
→
i
W
j
→
i
(
k
)
⋅
h
j
(
k
)
]
⋅
(
2
h
i
(
k
)
−
1
)
⋅
h
j
(
k
)
\begin{aligned} \frac{\partial}{\partial \mathcal W_{j \to i}} \left[\sum_{v^{(k)} \in \mathcal V}\log \mathcal P(v^{(k)})\right] & = \sum_{v^{(k)} \in \mathcal V} \sum_{h^{(k)}}\mathcal P(h^{(k)} \mid v^{(k)}) \cdot \sigma \left[- (2h_i^{(k)} - 1)\cdot \sum_{j \to i} \mathcal W_{j \to i}^{(k)} \cdot h_j^{(k)}\right] \cdot (2h_i^{(k)} - 1) \cdot h_j^{(k)} \\ \end{aligned}
∂Wj→i∂
v(k)∈V∑logP(v(k))
=v(k)∈V∑h(k)∑P(h(k)∣v(k))⋅σ[−(2hi(k)−1)⋅j→i∑Wj→i(k)⋅hj(k)]⋅(2hi(k)−1)⋅hj(k)
通过观察可以发现,关于
W
j
→
i
(
k
)
\mathcal W_{j \to i}^{(k)}
Wj→i(k)梯度中包含隐变量的后验概率分布,这个后验分布没有办法直接进行求解。
Neal
\text{Neal}
Neal本人针对该后验的求解使用MCMC方法进行处理:
Explain Away
\text{Explain Away}
Explain Away现象,本质原因是观测变量与‘和其存在因果关系的’隐变量之间属于
V
\mathcal V
V型结构,在给定观测变量(样本)的条件下,对应隐变量之间并不是条件独立关系。
∇
W
j
→
i
(
k
)
[
∑
v
(
k
)
∈
V
log
P
(
v
(
k
)
)
]
=
{
E
P
d
a
t
a
[
σ
(
−
(
2
h
i
(
k
)
−
1
)
⋅
∑
j
→
i
W
j
→
i
(
k
)
⋅
h
j
(
k
)
)
⋅
(
2
h
i
(
k
)
−
1
)
⋅
h
j
(
k
)
]
P
d
a
t
a
⇒
P
d
a
t
a
(
v
(
k
)
∈
V
)
⋅
P
m
o
d
e
l
(
h
(
k
)
∣
v
(
k
)
)
\nabla_{\mathcal W_{j \to i}^{(k)}} \left[\sum_{v^{(k)} \in \mathcal V} \log \mathcal P(v^{(k)})\right] = \begin{cases} \mathbb E_{\mathcal P_{data}} \left[ \sigma \left( - (2h_i^{(k)} - 1) \cdot \sum_{j \to i} \mathcal W_{j \to i}^{(k)} \cdot h_{j}^{(k)}\right)\cdot (2h_i^{(k)} - 1) \cdot h_j^{(k)}\right] \\ \mathcal P_{data} \Rightarrow \mathcal P_{data}(v^{(k)} \in \mathcal V) \cdot \mathcal P_{model}(h^{(k)} \mid v^{(k)}) \end{cases}
∇Wj→i(k)
v(k)∈V∑logP(v(k))
={EPdata[σ(−(2hi(k)−1)⋅∑j→iWj→i(k)⋅hj(k))⋅(2hi(k)−1)⋅hj(k)]Pdata⇒Pdata(v(k)∈V)⋅Pmodel(h(k)∣v(k))
关于MCMC方法求解过程,可能仅能在小规模的随机变量集合中使用,如果随机变量集合规模较大,实际上求解复杂度会呈指数级别增长,并且极难收敛至平稳分布。
醒眠算法
基于平均场假设变分推断求解后验概率
关于后验概率
P
(
h
k
∣
v
k
)
\mathcal P(h^{k} \mid v^{k})
P(hk∣vk)的求解,在玻尔兹曼机——梯度求解过程中介绍了基于平均场理论的变分推断求解方式。其核心思想是:基于平均场理论假设出的近似后验分布
Q
(
h
(
k
)
∣
v
(
k
)
)
\mathcal Q(h^{(k)} \mid v^{(k)})
Q(h(k)∣v(k))各个隐变量之间相互独立:
D
\mathcal D
D表示
Sigmoid
\text{Sigmoid}
Sigmoid信念网络中隐变量的数量,也可看做隐变量的下标编号。
Q
(
h
(
k
)
∣
v
(
k
)
)
=
∏
i
=
1
D
Q
(
h
i
(
k
)
∣
v
(
k
)
)
h
(
k
)
∈
{
0
,
1
}
D
\mathcal Q(h^{(k)} \mid v^{(k)}) = \prod_{i=1}^{\mathcal D} \mathcal Q(h_i^{(k)} \mid v^{(k)}) \quad h^{(k)} \in \{0,1\}^{\mathcal D}
Q(h(k)∣v(k))=i=1∏DQ(hi(k)∣v(k))h(k)∈{0,1}D
而基于平均场理论的近似后验分布
Q
(
h
(
k
)
∣
v
(
k
)
)
\mathcal Q(h^{(k)} \mid v^{(k)})
Q(h(k)∣v(k))可以得到一个关于模型参数的迭代关系。从而使用坐标上升法(Coordinate Ascent),每次固定其他随机变量的信息来更新一个随机变量的模型参数,直到所有模型参数均被更新一次,视作一次迭代;根据不动点方程必收敛的性质,最终必然会得到一个稳定的后验分布结果。
平均场理论求解后验的弊端
即便上面的描述无懈可击,但是平均场理论变分推断的计算过程同样是非常复杂的。假设在迭代若干次后,得到了一个稳定的后验结果,将其带入上式,得到一个梯度结果 ∇ W j → i ( k ) [ ∑ v ( k ) ∈ V log P ( v ( k ) ) ] \nabla_{\mathcal W_{j \to i}^{(k)}} \left[\sum_{v^{(k)}\in \mathcal V} \log \mathcal P(v^{(k)})\right] ∇Wj→i(k)[∑v(k)∈VlogP(v(k))]。
但仅仅得到一个梯度结果自然是不够的,这个梯度结果同样需要迭代。由于这里求解的是对数似然梯度,使用的策略通常是极大似然估计(Maximum Likelihood Estimation,MLE)。对应的算法通常是梯度上升法。而梯度上升法同样是需要迭代的:
W
j
→
i
(
t
+
1
)
=
W
j
→
i
(
t
)
+
η
∇
w
j
→
i
(
t
)
[
∑
v
(
k
)
∈
V
log
P
(
v
(
k
)
)
]
\mathcal W_{j \to i}^{(t+1)} = \mathcal W_{j \to i}^{(t)} + \eta \nabla_{w_{j \to i}^{(t)}} \left[\sum_{v^{(k)}\in \mathcal V} \log \mathcal P(v^{(k)})\right]
Wj→i(t+1)=Wj→i(t)+η∇wj→i(t)
v(k)∈V∑logP(v(k))
加上平均场理论变分推断的迭代,这明显是一个嵌套循环。复杂度同样是非常高的。
醒眠算法
醒眠算法(Wake-Sleep Algorithm)于 1995 1995 1995年被提出。该算法的作用在于对近似后验概率 Q ( h ( i ) ∣ v ( i ) ) \mathcal Q(h^{(i)} \mid v^{(i)}) Q(h(i)∣v(i))进行估计,相比于平均场理论的变分推断方法求解效率更高。
醒眠算法关于 Q ( h ( i ) ∣ v ( i ) ) \mathcal Q(h^{(i)} \mid v^{(i)}) Q(h(i)∣v(i))的求解思路在于:它并没有将 Q ( h ( i ) ∣ v ( i ) ) \mathcal Q(h^{(i)} \mid v^{(i)}) Q(h(i)∣v(i))视作一个概率分布,而是将其视作一个函数。从而基于神经网络的函数逼近定理对函数 Q ( h ( i ) ∣ v ( i ) ) \mathcal Q(h^{(i)} \mid v^{(i)}) Q(h(i)∣v(i))进行学习。
很明显,思路性质变了,这将关于
Q
(
h
(
i
)
∣
v
(
i
)
)
\mathcal Q(h^{(i)} \mid v^{(i)})
Q(h(i)∣v(i))的近似推断任务 转换成了关于
Q
(
h
(
i
)
∣
v
(
i
)
)
\mathcal Q(h^{(i)} \mid v^{(i)})
Q(h(i)∣v(i))函数的学习任务。
该思想就是‘花书’在P397页中提到的‘学成近似推断’。
关于醒眠算法,它提出一个假设作为前提:如果将
Sigmoid
\text{Sigmoid}
Sigmoid信念网络中隐变量信息向观测变量传递的过程称作生成过程
(Generative Connection)
\text{(Generative Connection)}
(Generative Connection) 的话,假设对应的存在识别过程
(Recognization Connection)
\text{(Recognization Connection)}
(Recognization Connection),也可以称作反馈过程,其意思是从观测变量反过来向隐变量反馈信息。具体模型表示如下:
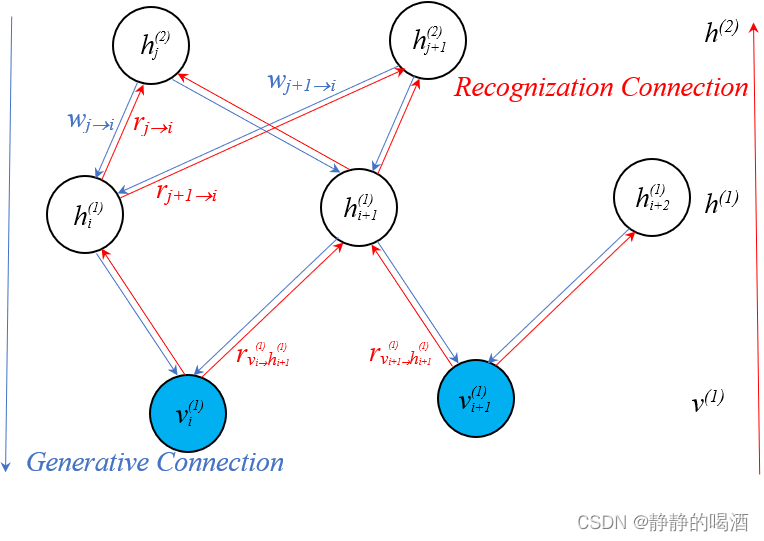
通过观察可以发现,结点之间的生成过程与识别过程是相对应的,识别过程中的参数使用 r r r 进行表示。
醒眠算法本身也是一个迭代算法。每次迭代过程中包含两个步骤:
-
Weak Phase \text{Weak Phase} Weak Phase:由于 v ( i ) = ( v 1 ( i ) , v 2 ( i ) , ⋯ , v P ( i ) ) v^{(i)} = (v_1^{(i)},v_2^{(i)},\cdots,v_{\mathcal P}^{(i)}) v(i)=(v1(i),v2(i),⋯,vP(i))都是基于样本集合给定的样本,因此执行如下操作:
-
Bottom-up Activate Neuron
\text{Bottom-up Activate Neuron}
Bottom-up Activate Neuron目标是获取各层隐变量的后验样本:以随机变量
v
1
(
i
)
,
⋯
,
v
P
(
i
)
v_1^{(i)},\cdots,v_{\mathcal P}^{(i)}
v1(i),⋯,vP(i)为起点,对与其相关联的隐变量结点逐层进行激活:
以上图描述的结点为例。再次提醒v 1 ( i ) v_1^{(i)} v1(i)中的上标表示样本编号( i = 1 , 2 , ⋯ , N ) (i=1,2,\cdots,N) (i=1,2,⋯,N),下面公式中的上标是层的编号:
S = { v ( 1 ) , h ( 1 ) , h ( 2 ) } = { v i ( 1 ) , v i + 1 ( 1 ) , h i ( 1 ) , h i + 1 ( 1 ) , h i + 2 ( 1 ) , ⋯ } h ( 1 ) : { h i ( 1 ) ⇒ P ( h i ( 1 ) ∣ v i ( 1 ) ) h i + 1 ( 1 ) ⇒ P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) h i + 2 ( 1 ) ⇒ P ( h i + 2 ( 1 ) ∣ v i + 1 ( 1 ) ) h ( 2 ) : { h j ( 2 ) ⇒ P ( h j ( 2 ) ∣ h i ( 1 ) , h i + 1 ( 1 ) ) h j + 1 ( 2 ) ⇒ P ( h j + 1 ( 2 ) ∣ h i ( 1 ) , h i + 1 ( 1 ) ) \begin{aligned} \mathcal S = \{v^{(1)},h^{(1)},h^{(2)}\} & = \{v_i^{(1)},v_{i+1}^{(1)},h_{i}^{(1)},h_{i+1}^{(1)},h_{i+2}^{(1)},\cdots\} \\ h^{(1)} & :\begin{cases} h_i^{(1)} \Rightarrow \mathcal P(h_i^{(1)} \mid v_i^{(1)}) \\ h_{i+1}^{(1)} \Rightarrow \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) \\ h_{i+2}^{(1)} \Rightarrow \mathcal P(h_{i+2}^{(1)} \mid v_{i+1}^{(1)}) \end{cases} \\ h^{(2)} &: \begin{cases} h_j^{(2)} \Rightarrow \mathcal P(h_j^{(2)} \mid h_{i}^{(1)},h_{i+1}^{(1)}) \\ h_{j+1}^{(2)} \Rightarrow \mathcal P(h_{j+1}^{(2)} \mid h_{i}^{(1)},h_{i+1}^{(1)}) \end{cases} \end{aligned} S={v(1),h(1),h(2)}h(1)h(2)={vi(1),vi+1(1),hi(1),hi+1(1),hi+2(1),⋯}:⎩ ⎨ ⎧hi(1)⇒P(hi(1)∣vi(1))hi+1(1)⇒P(hi+1(1)∣vi(1),vi+1(1))hi+2(1)⇒P(hi+2(1)∣vi+1(1)):{hj(2)⇒P(hj(2)∣hi(1),hi+1(1))hj+1(2)⇒P(hj+1(2)∣hi(1),hi+1(1))
关于隐变量的后验具体如何求解呢?通过采样的方式。以 h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)的后验概率示例。由于 h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)同样服从伯努利分布,它的后验概率分布表示如下:
P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) = { P ( h i + 1 ( 1 ) = 1 ∣ v i ( 1 ) , v i + 1 ( 1 ) ) P ( h i + 1 ( 1 ) = 0 ∣ v i ( 1 ) , v i + 1 ( 1 ) ) \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) = \begin{cases} \mathcal P(h_{i+1}^{(1)} =1\mid v_i^{(1)},v_{i+1}^{(1)}) \\ \mathcal P(h_{i+1}^{(1)} = 0\mid v_i^{(1)},v_{i+1}^{(1)}) \end{cases} P(hi+1(1)∣vi(1),vi+1(1))={P(hi+1(1)=1∣vi(1),vi+1(1))P(hi+1(1)=0∣vi(1),vi+1(1))
由于是迭代算法,因此,在初始状态下,给对应识别过程的模型参数 r v i ( 1 ) → h i + 1 ( 1 ) , r v i + 1 ( 1 ) → h i + 1 ( 1 ) r_{v_i^{(1)} \to h_{i+1}^{(1)}},r_{v_{i+1}^{(1)} \to h_{i+1}^{(1)}} rvi(1)→hi+1(1),rvi+1(1)→hi+1(1)随机初始值,对应 P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) P(hi+1(1)∣vi(1),vi+1(1))表示如下:
识别过程同样使用Sigmoid \text{Sigmoid} Sigmoid函数~
得到的结果就是一个关于h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)后验的伯努利分布。
P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) = { σ ( v i ( 1 ) ⋅ r v i ( 1 ) → h i + 1 ( 1 ) + v i + 1 ( 1 ) ⋅ r v i + 1 ( 1 ) → h i + 1 ( 1 ) ) h i + 1 ( 1 ) = 1 1 − σ ( v i ( 1 ) ⋅ r v i ( 1 ) → h i + 1 ( 1 ) + v i + 1 ( 1 ) ⋅ r v i + 1 ( 1 ) → h i + 1 ( 1 ) ) h i + 1 ( 1 ) = 0 \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) = \begin{cases} \sigma \left(v_i^{(1)} \cdot r_{v_i^{(1)} \to h_{i+1}^{(1)}} + v_{i+1}^{(1)} \cdot r_{v_{i+1}^{(1)} \to h_{i+1}^{(1)}}\right) \quad h_{i+1}^{(1)} = 1\\ 1 - \sigma \left(v_i^{(1)} \cdot r_{v_i^{(1)} \to h_{i+1}^{(1)}} + v_{i+1}^{(1)} \cdot r_{v_{i+1}^{(1)} \to h_{i+1}^{(1)}}\right) \quad h_{i+1}^{(1)} = 0 \end{cases} P(hi+1(1)∣vi(1),vi+1(1))=⎩ ⎨ ⎧σ(vi(1)⋅rvi(1)→hi+1(1)+vi+1(1)⋅rvi+1(1)→hi+1(1))hi+1(1)=11−σ(vi(1)⋅rvi(1)→hi+1(1)+vi+1(1)⋅rvi+1(1)→hi+1(1))hi+1(1)=0
基于该分布进行采样,最终可以得到关于 h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)后验的具体样本。并以该样本为基础,继续向下延伸,最终直到得出所有隐变量后验的具体样本。 - 基于
Bottom-up Activate Neuron
\text{Bottom-up Activate Neuron}
Bottom-up Activate Neuron中产生的样本,去学习生成过程的模型参数
W
(
Learning Generative Connection
)
\mathcal W(\text{Learning Generative Connection})
W(Learning Generative Connection):
此时各个隐变量后验概率分布的样本都已经得到,自然可以求解模型参数W \mathcal W W的梯度。虽然Bottom-up \text{Bottom-up} Bottom-up过程中各层之间的结构中有‘同父结构’和V \mathcal V V型结构,但并不影响P ( h ( k ) ∣ v ( k ) ) \mathcal P(h^{(k)} \mid v^{(k)}) P(h(k)∣v(k))的近似计算。
依然以上图为例:
将‘同父结构’的部分进行展开。同父结构考古概率图模型——贝叶斯网络的结构表示
这里仅介绍了一项P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) P(hi+1(1)∣vi(1),vi+1(1)),其余项大家自行脑补~
P ( h ( k ) ∣ v ( k ) ) = P ( h i ( 1 ) , h i + 1 ( 1 ) , h i + 2 ( 1 ) , h j ( 2 ) , h j + 1 ( 2 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) = P ( h i ( 1 ) , h i + 1 ( 1 ) ∣ v i ( 1 ) ) ⋅ P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) ⋅ P ( h i + 1 ( 1 ) , h i + 2 ( 1 ) ∣ v i + 1 ( 1 ) ) ⏟ L a y e r − 1 ⋅ P ( h j ( 2 ) , h j + 1 ( 2 ) ∣ h i ( 1 ) ) ⋅ P ( h j ( 2 ) , h j + 1 ( 2 ) ∣ h i + 1 ( 1 ) ) ⏟ L a y e r − 2 = { Layer-1: [ P ( h i ( 1 ) ∣ v i ( 1 ) ) ⋅ P ( h i + 1 ( 1 ) ∣ v i ( 1 ) , v i + 1 ( 1 ) ) ⋅ P ( h i + 2 ( 1 ) ∣ v i + 1 ( 1 ) ) ] Layer-2: [ P ( h j ( 2 ) ∣ h i ( 1 ) , h i + 1 ( 1 ) ) ⋅ P ( h j + 1 ( 2 ) ∣ h i ( 1 ) , h i + 1 ( 1 ) ) ] \begin{aligned} \mathcal P(h^{(k)} \mid v^{(k)}) & = \mathcal P (h_i^{(1)},h_{i+1}^{(1)},h_{i+2}^{(1)},h_{j}^{(2)},h_{j+1}^{(2)} \mid v_i^{(1)},v_{i+1}^{(1)}) \\ & = \underbrace{\mathcal P(h_i^{(1)},h_{i+1}^{(1)}\mid v_i^{(1)}) \cdot \mathcal P(h_{i+1}^{(1)} \mid v_i^{(1)},v_{i+1}^{(1)}) \cdot \mathcal P(h_{i+1}^{(1)},h_{i+2}^{(1)}\mid v_{i+1}^{(1)})}_{Layer-1} \cdot \underbrace{\mathcal P(h_{j}^{(2)},h_{j+1}^{(2)}\mid h_{i}^{(1)}) \cdot \mathcal P(h_{j}^{(2)},h_{j+1}^{(2)} \mid h_{i+1}^{(1)})}_{Layer-2} \\ & = \begin{cases} \text{Layer-1: } \left[\mathcal P(h_i^{(1)} \mid v_i^{(1)}) \cdot \mathcal P(h_{i+1}^{(1)} \mid v_{i}^{(1)},v_{i+1}^{(1)}) \cdot \mathcal P(h_{i+2}^{(1)} \mid v_{i+1}^{(1)})\right] \\ \text{Layer-2: } \left[\mathcal P(h_j^{(2)}\mid h_i^{(1)},h_{i+1}^{(1)}) \cdot \mathcal P(h_{j+1}^{(2)}\mid h_i^{(1)},h_{i+1}^{(1)})\right] \end{cases} \end{aligned} P(h(k)∣v(k))=P(hi(1),hi+1(1),hi+2(1),hj(2),hj+1(2)∣vi(1),vi+1(1))=Layer−1 P(hi(1),hi+1(1)∣vi(1))⋅P(hi+1(1)∣vi(1),vi+1(1))⋅P(hi+1(1),hi+2(1)∣vi+1(1))⋅Layer−2 P(hj(2),hj+1(2)∣hi(1))⋅P(hj(2),hj+1(2)∣hi+1(1))=⎩ ⎨ ⎧Layer-1: [P(hi(1)∣vi(1))⋅P(hi+1(1)∣vi(1),vi+1(1))⋅P(hi+2(1)∣vi+1(1))]Layer-2: [P(hj(2)∣hi(1),hi+1(1))⋅P(hj+1(2)∣hi(1),hi+1(1))]
此时, P ( h ( k ) ∣ v ( k ) ) \mathcal P(h^{(k)} \mid v^{(k)}) P(h(k)∣v(k))求解结束后,继续求解模型参数 W \mathcal W W的梯度:
∇ W j → i [ ∑ v ( k ) ∈ V log P ( v ( k ) ) ] = ∑ v ( k ) ∈ V ∑ h ( k ) P ( h ( k ) ∣ v ( k ) ) ⋅ σ [ − ( 2 h i ( k ) − 1 ) ⋅ ∑ j → i W j → i ( k ) ⋅ h j ( k ) ] ⋅ ( 2 h i ( k ) − 1 ) ⋅ h j ( k ) \begin{aligned} \nabla_{\mathcal W_{j \to i}} \left[\sum_{v^{(k)} \in \mathcal V}\log \mathcal P(v^{(k)})\right] & = \sum_{v^{(k)} \in \mathcal V} \sum_{h^{(k)}}\mathcal P(h^{(k)} \mid v^{(k)}) \cdot \sigma \left[- (2h_i^{(k)} - 1)\cdot \sum_{j \to i} \mathcal W_{j \to i}^{(k)} \cdot h_j^{(k)}\right] \cdot (2h_i^{(k)} - 1) \cdot h_j^{(k)} \\ \end{aligned} ∇Wj→i v(k)∈V∑logP(v(k)) =v(k)∈V∑h(k)∑P(h(k)∣v(k))⋅σ[−(2hi(k)−1)⋅j→i∑Wj→i(k)⋅hj(k)]⋅(2hi(k)−1)⋅hj(k)
最终使用梯度上升法,近似求解当前迭代步骤的最优模型参数 W ^ \hat {\mathcal W} W^:
W j → i ( t + 1 ) = W j → i ( t ) + η ∇ w j → i ( t ) [ ∑ v ( k ) ∈ V log P ( v ( k ) ) ] \mathcal W_{j \to i}^{(t+1)} = \mathcal W_{j \to i}^{(t)} + \eta \nabla_{w_{j \to i}^{(t)}} \left[\sum_{v^{(k)}\in \mathcal V} \log \mathcal P(v^{(k)})\right] Wj→i(t+1)=Wj→i(t)+η∇wj→i(t) v(k)∈V∑logP(v(k))
-
Bottom-up Activate Neuron
\text{Bottom-up Activate Neuron}
Bottom-up Activate Neuron目标是获取各层隐变量的后验样本:以随机变量
v
1
(
i
)
,
⋯
,
v
P
(
i
)
v_1^{(i)},\cdots,v_{\mathcal P}^{(i)}
v1(i),⋯,vP(i)为起点,对与其相关联的隐变量结点逐层进行激活:
-
Sleep Phase: \text{Sleep Phase: } Sleep Phase: 在 Weak Phase \text{Weak Phase} Weak Phase基础上,我们得到了关于隐变量后验分布的样本,执行如下操作:
-
Top-Down Activate Neuron:
\text{Top-Down Activate Neuron: }
Top-Down Activate Neuron: 从入度为零的隐变量结点开始,按照拓扑排序的顺序进行采样:
其采样操作和Bottom-up Activate Neuron \text{Bottom-up Activate Neuron} Bottom-up Activate Neuron步骤基本相同,正常按照‘祖先采样方法’进行采样。这里同样使用h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)为例,进行采样.
需要注意的是,此时的采样起点是从隐变量开始的,从而采出的基于所有随机变量结点的样本点不同于Weak Phase \text{Weak Phase} Weak Phase,这些样本点没有真实样本做支撑,是虚拟出来的样本点。
虽然h j ( 2 ) , h j + 1 ( 2 ) , h i + 1 ( 1 ) h_{j}^{(2)},h_{j+1}^{(2)},h_{i+1}^{(1)} hj(2),hj+1(2),hi+1(1)之间属于V \mathcal V V型结构,但是h i + 1 ( 1 ) h_{i+1}^{(1)} hi+1(1)作为后验,是未知(未被观测)的,因此可以写成如下形式。
Q ( h i + 1 ( 1 ) ∣ h j ( 2 ) , h j + 1 ( 2 ) ) = Q ( h i + 1 ( 1 ) ∣ h j ( 2 ) ) ⋅ Q ( h i + 1 ( 1 ) ∣ h j + 1 ( 2 ) ) \mathcal Q(h_{i+1}^{(1)} \mid h_{j}^{(2)},h_{j+1}^{(2)}) = \mathcal Q(h_{i+1}^{(1)} \mid h_j^{(2)}) \cdot \mathcal Q(h_{i+1}^{(1)} \mid h_{j+1}^{(2)}) Q(hi+1(1)∣hj(2),hj+1(2))=Q(hi+1(1)∣hj(2))⋅Q(hi+1(1)∣hj+1(2))
对应的概率分布可表示为:
Q ( h i + 1 ( 1 ) ∣ h j ( 2 ) ) = { σ ( W h j ( 2 ) → h i + 1 ( 1 ) ⋅ h j ( 2 ) ) h i + 1 ( 1 ) = 1 1 − σ ( W h j ( 2 ) → h i + 1 ( 1 ) ⋅ h j ( 2 ) ) h i + 1 ( 1 ) = 0 Q ( h i + 1 ( 1 ) ∣ h j + 1 ( 2 ) ) = { σ ( W h j + 1 ( 2 ) → h i + 1 ( 1 ) ⋅ h j + 1 ( 2 ) ) h i + 1 ( 1 ) = 1 1 − σ ( W h j + 1 ( 2 ) → h i + 1 ( 1 ) ⋅ h j + 1 ( 2 ) ) h i + 1 ( 1 ) = 0 \begin{aligned} \mathcal Q(h_{i+1}^{(1)} \mid h_j^{(2)}) = \begin{cases} \sigma \left(\mathcal W_{h_{j}^{(2)} \to h_{i+1}^{(1)}} \cdot h_j^{(2)}\right) \quad h_{i+1}^{(1)} = 1 \\ 1 - \sigma \left(\mathcal W_{h_{j}^{(2)} \to h_{i+1}^{(1)}} \cdot h_j^{(2)}\right) \quad h_{i+1}^{(1)} = 0 \end{cases} \\ \mathcal Q(h_{i+1}^{(1)} \mid h_{j+1}^{(2)}) = \begin{cases} \sigma \left(\mathcal W_{h_{j+1}^{(2)} \to h_{i+1}^{(1)}} \cdot h_{j+1}^{(2)}\right) \quad h_{i+1}^{(1)} = 1 \\ 1 - \sigma \left(\mathcal W_{h_{j+1}^{(2)} \to h_{i+1}^{(1)}} \cdot h_{j+1}^{(2)}\right) \quad h_{i+1}^{(1)} = 0 \end{cases} \end{aligned} Q(hi+1(1)∣hj(2))=⎩ ⎨ ⎧σ(Whj(2)→hi+1(1)⋅hj(2))hi+1(1)=11−σ(Whj(2)→hi+1(1)⋅hj(2))hi+1(1)=0Q(hi+1(1)∣hj+1(2))=⎩ ⎨ ⎧σ(Whj+1(2)→hi+1(1)⋅hj+1(2))hi+1(1)=11−σ(Whj+1(2)→hi+1(1)⋅hj+1(2))hi+1(1)=0
最终,同样可以得到关于隐变量的虚拟的概率分布 Q ( h ( k ) ∣ v ( k ) ) \mathcal Q(h^{(k)} \mid v^{(k)}) Q(h(k)∣v(k))的样本。
个人疑问:Q ( h ( k ) ∣ v ( k ) ) \mathcal Q(h^{(k)} \mid v^{(k)}) Q(h(k)∣v(k))既然是关于隐变量h ( k ) h^{(k)} h(k)后验的一个概率分布,那么在Sleep Phase \text{Sleep Phase} Sleep Phase过程中是否采到结尾,也就是如Q ( v i ( 1 ) ∣ h i ( i ) ) \mathcal Q(v_i^{(1)} \mid h_i^{(i)}) Q(vi(1)∣hi(i)).虽然已经这道这里关于v i ( 1 ) v_i^{(1)} vi(1)的后验并不是基于真实样本产生的,是虚拟的,但它仍然是关于v i ( 1 ) v_i^{(1)} vi(1)的后验。这就不是隐变量的后验了,那么Q ( h ( k ) ∣ v ( k ) ) \mathcal Q(h^{(k)} \mid v^{(k)}) Q(h(k)∣v(k))要如何表示?
其次,如果不采到结尾,那么如上图中的h i + 2 ( 1 ) h_{i+2}^{(1)} hi+2(1)就没有机会采到了。因为它是入度为零的结点,并且它的后验就是观测变量。 - 基于求解的
Q
(
h
(
k
)
∣
v
(
k
)
)
\mathcal Q(h^{(k)} \mid v^{(k)})
Q(h(k)∣v(k))求解参数
r
r
r,首先,依然求解参数
r
r
r的梯度。
直接将Q ( h ( k ) ∣ v ( k ) ) \mathcal Q(h^{(k)} \mid v^{(k)}) Q(h(k)∣v(k))带回原式,替换P ( h ( k ) ∣ v ( k ) ) \mathcal P(h^{(k)} \mid v^{(k)}) P(h(k)∣v(k)).并且此时的V ′ \mathcal V' V′也不再是真实样本,而是经过后验采样出的样本结果。
∇ r j → i [ ∑ v ( k ) ∈ V ′ log P ( v ( k ) ) ] \nabla_{r_{j \to i}} \left[\sum_{v^{(k)} \in \mathcal V'} \log \mathcal P(v^{(k)})\right] ∇rj→i v(k)∈V′∑logP(v(k))
最终近似求解模型参数 r r r:
r j → i ( t + 1 ) = r j → i ( t ) + η ∇ r j → i ( t ) [ ∑ v ( k ) ∈ V ′ log P ( v ( k ) ) ] r_{j \to i}^{(t+1)} = r_{j \to i}^{(t)} + \eta \nabla_{r_{j \to i}^{(t)}} \left[\sum_{v^{(k)} \in \mathcal V'} \log \mathcal P(v^{(k)})\right] rj→i(t+1)=rj→i(t)+η∇rj→i(t) v(k)∈V′∑logP(v(k))
-
Top-Down Activate Neuron:
\text{Top-Down Activate Neuron: }
Top-Down Activate Neuron: 从入度为零的隐变量结点开始,按照拓扑排序的顺序进行采样:
下一节将介绍醒眠算法与 EM \text{EM} EM算法之间的比较。
相关参考:
(系列二十六)Sigmoid Belief Network4-睡眠算法-介绍