(1)小白建议学习青岛大学王卓老师的数据结构视频,或者购买程杰老师的大话数据结构。
(2)邀请加入嵌入式社区,您可以在上面发布问题,博客链接,公众号分享,行业消息,招聘信息等。
目录
算法的概念
算法的定义
两种算法比较
算法与数据结构的关系
算法的特性
输入
输出
有穷性
确定性
可行性
算法设计要求
正确性
可读性
健壮性
高效性
算法效率度量
事后统计法
事前分析估算法
函数的渐近增长
算法的时间复杂度
最好,最坏和平均时间复杂度
算法空间复杂度
算法的概念
算法的定义
算法就是为了解决某一类问题而规定的有限长的操作序列。
两种算法比较
(1)可能上面这个算法的定义很多人看不懂。没关系,看了下面这两个例子就明白了。
(2)看完下面这两个算法比较,我们发现,算法其实就是对一个问题的计算方式而已。比如算法1采用的是将100个数依次加起来,而算法2就是采用小学所学的,首项加尾项乘以项数除以二来计算。
(3)我们对比这两个算法,能够发现什么,第一个算法很花费时间。如果是人进行计算,还很有可能计算出现问题。但是第二个算法就有很高的优越性,计算速度快。算法2就是大佬高斯先生所创造。
(4)虽然说算法2比算法1有很高的优越性,但是不知道各位有没有发现一个问题。就是,假如我只要计算1+2怎么办呢?这个时候,如果还采用算法2,就显得非常愚蠢了,因为算法2需要加乘除三步操作,而算法1只需要一次加即可(注意,从数据结构的角度,算法1执行了5步,算法2执行了3步,后面会讲)。这表明,算法是没有通用的,没有绝对好的算法,就好像世界上没有治疗百病的药物一样。
/*
计算1+2+3+...+100的两种算法
*/
/******算法1*******/
int i, sum = 0, n = 100;
for(i = 1; i <= n; i++)
{
sum = sum + i;
}
printf("%d", sum);
/******算法2*******/
int sum = 0, n = 100;
sum = (1 + n) * n / 2;
printf("%d", sum);算法与数据结构的关系
我们很多时候,听到数据结构与算法,将数据结构和算法放在一起说。他们直接有什么联系呢?
其实只有通过对特定算法的使用,才能真正清楚理解数据结构的作用。在涉及到算法运算的时候,总是要联系到算法处理的对象和结果的数据,而这些数据如何存储与操作就需要设计到数据结果的内容了。
算法的特性
算法具有五大基本特性:输入,输出,有穷性,确定性和可行性。
输入
一个算法有零个或多个输入。
/*
有多个输入的算法
*/
int Algorithm(int sum, int n)
{
sum = (1 + n) * n / 2;
return sum;
}
int main()
{
printf("%d\n", Algorithm(0, 100));
return 0;
}
/*
零个输入的算法
*/
int Algorithm()
{
int sum = 0, n = 100;
sum = (1 + n) * n / 2;
return sum;
}
int main()
{
printf("%d\n", Algorithm());
return 0;
}输出
(1)算法至少有一个或多个输出。
(2)算法没有输出要它干嘛?输出方式有多种,比如return返回一个值,比如printf打印出数据,或者通过指针的方式,将数据进行更改。
/*
return返回值的方式输出
*/
int Algorithm()
{
int sum = 0, n = 100;
sum = (1 + n) * n / 2;
return sum;
}
int main()
{
printf("%d\n", Algorithm());
return 0;
}
/*
printf的方式输出
*/
void Algorithm()
{
int sum = 0, n = 100;
sum = (1 + n) * n / 2;
printf("%d\n", sum);
}
int main()
{
Algorithm();
return 0;
}
/*
通过修改指针内数据形式输出
*/
void Algorithm(int* sum,int* n)
{
*sum = (1 + *n) * (*n) / 2;
}
int main()
{
int sum = 0, n = 100;
Algorithm(&sum, &n);
printf("%d\n",sum);
return 0;
}有穷性
(1)有穷性:算法执行必须是有限步骤之后结束,而且每一步都是必须在有限时间内完成。
(2)一个算法如果进入了死循环,那么它就没有存在的意义。同理,假如一个数据,利用这个算法需要计算100年,人都没了,还算什么?所以这种需要计算过长时间的算法也是没有存在意义的。
确定性
(1)确定性:算法的每一步都是有确定意义的,不会产生二义性,使算法的执行者或阅读者都能明确其含义及如何执行。
(2)如果一个算法出现了歧义,就会产生不一样的结果最终导致程序出问题,比如下面这一段算法。明明是同一个算数方式,而且符合操作符的优先级,但会产生不一样的结果。
/*** 算法 ***/
c + --c;
假设c=1
/*** 理解1 ***/
因为操作符--优先级在+之前,所以先--,再+
--c 此时c=0
0+0=0
/*** 理解2 ***/
1+ --c 先将c放入算法
1+0=1 因为操作符--优先级在+之前
可行性
(1)可行性:算法的每一步都必须是可行的,能够通过已经实现的基本操作运算执行有限次来完成。
(2)因为当前存在一些极其复杂的算法,受限于编程方法、工具和大脑限制了这个工作。不过这个属于理论研究的范围,不属于我们当前需要讨论的问题。
算法设计要求
我们判断一个算法的时候,不仅仅只是通过计算速度这一个方面来判断。还需要从其他几个角度来思考,总结起来就是四点:正确性,可读性,健壮性,高效性。
正确性
(1)正确性:是指算法应该具有输入,输出和加工处理没有歧义,能正确反映问题的需求,能够得到问题的正确答案。
(2)算法的正确通常有很大的区别,大体可以分为以下四类:
1,算法程序没有语法错误
2,算法程序对合法的输入数据能够产生满足要求的输出结果
3,算法程序对非法的输入数据能够产生满足要求的输出结果
4,算法程序对于精心选择的,甚至刁难的测试数据都有满足要求的输出结果
可读性
(1)可读性:一个优秀的算法程序设计,首先要便于他人理解。可读性强的算法有助于人们对于算法的理解,而难懂的算法容易隐藏漏洞,难于调试与修改。
(2)虽然我常常能够在某音上看到很多人说,程序写的羞涩难懂能够让老板以为自己是大佬。而程序写的太易懂,老板很容易以为自己没有竞争力,容易被替代。虽然这么说有那么一点点道理,但是我还是建议代码写的易懂一些,如果出了问题自己也好处理。
健壮性
(1)健壮性:当输入的数据非法时,好的算法能够适当的做出处理,而不是产生莫名奇妙的输出结果。
(2)像我专栏OpenMV的教程里面,在做颜色识别的时候,需要输入RBG的最大和最小阈值。当你的最大和最小阈值写反了,也能在算法里面进行交换,输出正确的结果。
高效性
(1)高效性:高效性包含时间与空间两个方面。
(2)时间高效是指算法设计合理,执行效率高,可以用时间复杂度来度量。
(3)空间高效是指算法占用存储容量合理,可以用空间复杂度来度量。
(4)以我数据结构(1)前言中的链式存储结构部分例子说明,虽然链式存储结构进行插队这一操作方便了许多,但是它需要腾出空间进行记录号码牌的顺序。时间和空间上要做抉择了,这也就是我们常说了,利用空间换取时间。
算法效率度量
事后统计法
(1)事后统计法:事后统计法就是利用设计好的程序和数据,利用计算机对不同算法程序进行编译比较,最后看哪一个程序跑最快。
(2)这种方法毫无疑问是很麻烦的。
第一,花费时间。你为了找出一个好的算法,需要编写出很多套不同的算法程序,最终选取其中一个,比较消耗时间。
第二,测试数据麻烦。如果需要测试算法,想必需要很多数据才能看到他们的差异。就拿我上面说的1+2+..+100哪个为例子,如果只需要计算1+2,无法看出两个算法的差异。必须要比较多的数据,比如100个。但是有一些算法,可能他们的差异并不只有100个数据才能看出,他们会需要1000个,1W个甚至更多。这一就导致测试数据比较麻烦。
第三,依赖硬件和编译环境。相同的程序放在不同的计算机上面跑可能会因为硬件的差异,导致运算速度不同。因为编译器的不同,它最后的执行速度也不同。就算是同一台机器,由于CPU的使用率和内存占用情况不同,也会造成细微差别。
事前分析估算法
(1)事前分析估计法:在计算机程序编译前,依据统计的方法对算法进行估计。
(2)一个算法的运行时间大致可以等于计算机执行一种简单的操作(如赋值、比较,移动)所需的时间与算法中进行的简单操作次数乘积。
算法运行时间=
每条语句的执行次数(又称为语句频度)X该语句执行一次所需的时间。
(3) 我们看之前上面所说的两种算法。如果是n=2,也就是只需要计算1+2,如果是让人来计算,显然算法1比较方便。但是对于计算机而言,因为每一条语句所执行的时间是由机器所异,即使是相同的计算机也会因为CPU占用率而导致不同,所以我们会将每一条语句默认执行时间是相同的。这也解释了,为什么我上面说,从数据结构的角度,算法1执行了5步,算法2执行了3步。
/*** 算法1 ***/
int i, sum = 0, n = 100; /* 执行1次 */
for(i = 1; i <= n; i++) /* 执行了n+1次,为什么后面需要+1,是因为当i=101的时候,需要判断101<=100这一步,所以需要+1 */
{
sum = sum + i; /* 执行n次 */
}
printf("%d", sum); /* 执行1次 */
/*** 算法2 ***/
int sum = 0,n = 100; /* 执行一次 */
sum = (1 + n) * n / 2; /* 执行一次 */
printf("%d", sum); /* 执行一次 */函数的渐近增长
(1)现在我们知道了,比较算法的好坏采用事前分析估计方法比较好。那么看一下下面这个代码,看看它的算法运行时间是多少。
(2)
1,首先for (i = 1; i <= n; i++) 为什么是n+1次上面已经解释,不多说了。
2,for (j = 1; j <= n; j++) 因为是在for (i = 1; i <= n; i++)里面,所以它会被执行n次,然后自身又有n+1次,所以最终是n*(n+1)次。
3,c[i][j] = 0;是因为在两个for语句里面,所以是n*n次。
4,for (k = 0; k < n; k++)因为在两个for语句里面,所以前面需要乘n*n。最后因为自身有一个n+1次,所以最终是n*n*(n+1)。
5,因为c[i][j] = c[i][j] + a[i][j] * b[k][j];在三个for语句里面,所以是n*n*n次。
6,最终结果就是,执行时间为
。
(3)当n=1的时候,执行时间为8。n=10的时候,执行时间为2321。n=100,执行时间为2030201。我们会发现,随着n的增加,最小项的权重越大,其他项可以逐渐被忽略。所以,与我们只会保留最高项!我们将
与
比较,会发现随着n的增大,前者会远大于后者。此时我们将
与
for (i = 1; i <= n; i++) //n+1
{
for (j = 1; j <= n; j++) //n*(n+1)
{
c[i][j] = 0; //n*n
for (k = 0; k < n; k++) //n*n*(n+1)
c[i][j] = c[i][j] + a[i][j] * b[k][j];//n*n*n
}算法的时间复杂度
(1)若有某个辅助函数f(n),使得当n趋近无穷大时,
的极限值不为0的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐近时间复杂度,简称时间复杂度。其中f(n)是问题规模n的某个函数。
(2)想必绝大多数人看到上面这段话是一脸懵的。没错,我也是绝大多数人。我举个例子讲一下我简单理解。
首先,T(n)是我们的算法耗费时间,例如上面的代码T(n)为
,2为常数,所以T(n)的时间复杂度为O(
(3)现在我们知道了大O计法了,那么有多数种呢?这些时间复杂度耗费的时间大小关系如何呢?如下
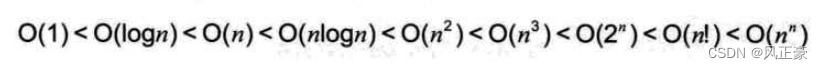
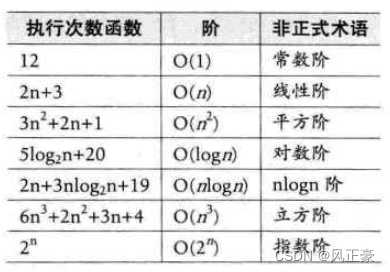
这些阶有一些非官方术语
最好,最坏和平均时间复杂度
(1)将算法在最好情况下的时间复杂度为最好时间复杂度,即算法计算量可能达到的最小值;
(2)将算法在最坏情况下的时间复杂度为最坏时间复杂度,即算法计算量可能达到的最大值;
(3)将算法在所有可能情况下,按照输入实例以等概率出现时,算法计算的加权平均值称为平均时间复杂度;
算法空间复杂度
(1)与时间复杂度类似,我们采用渐近空间复杂度。一般情况下,一个程序在机器上执行时,除了需要存储程序本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单元。若输入数据所占空间只取决于问题本身,和算法无关,这样只需要分析该算法在实现时所需的辅助单元即可。若算法执行时所需的辅助空间相对于输入数据量而言是个常数,则称此算法为原地工作,空间复杂度为O(1)。
(2)看完上面这段话,相信百分之九十九的人是不明白的。我们只需要知道,空间复杂度与辅助单元有关。那么辅助单元又是啥呢?看下面两个代码。
第一个代码,辅助单元是t,与问题规模n无关,是一个常量,所以空间复杂度为O(1)。
第二个代码,辅助单元是数组b[n],所以空间复杂度为O(n)。
(3)一般情况下,我们是不会考虑空间复杂度的。
/*** 将一维数组a中的n个数逆序存放到原数组中。 ***/
//空间复杂度为O(1)
for (i = 0; i < n / 2; i++)
{
t = a[i];
a[i] = a[n - i - 1];
a[n - i - 1] = t;
}
//空间复杂度为O(n)
for (i = 0; i < n; i++)
b[i] = a[n - i - 1];
for (i = 0; i < n; i++)
a[i] = b[i];