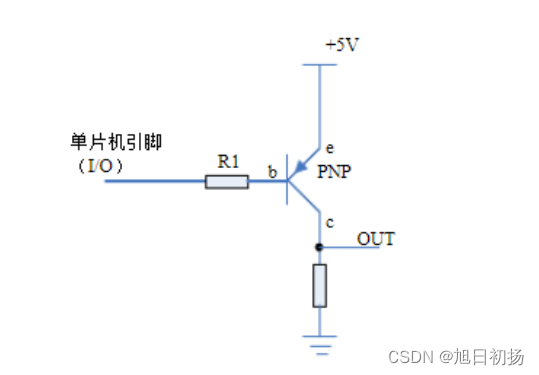
摘要:本文整理自满帮实时数据团队 TL 欧锐,在 FFA 2022 行业案例专场的分享。本篇内容主要分为四个部分:
满帮业务及平台架构介绍
实时数据
实时产品
未来计划
Tips:点击「阅读原文」查看原文视频&演讲 ppt
01
满帮业务及平台架构介绍
满帮集团全心全意帮助司机和货主,助力物流降本增效,利用移动互联网、大数据、人工智能等新技术,打造智慧物流生态平台,提升“车找货、货找车”的智能化和标准化,改变传统物流行业“小、乱、散、弱”的状况。旗下运满满货运平台一站式解决货运全链路问题,百万司机一秒响应。
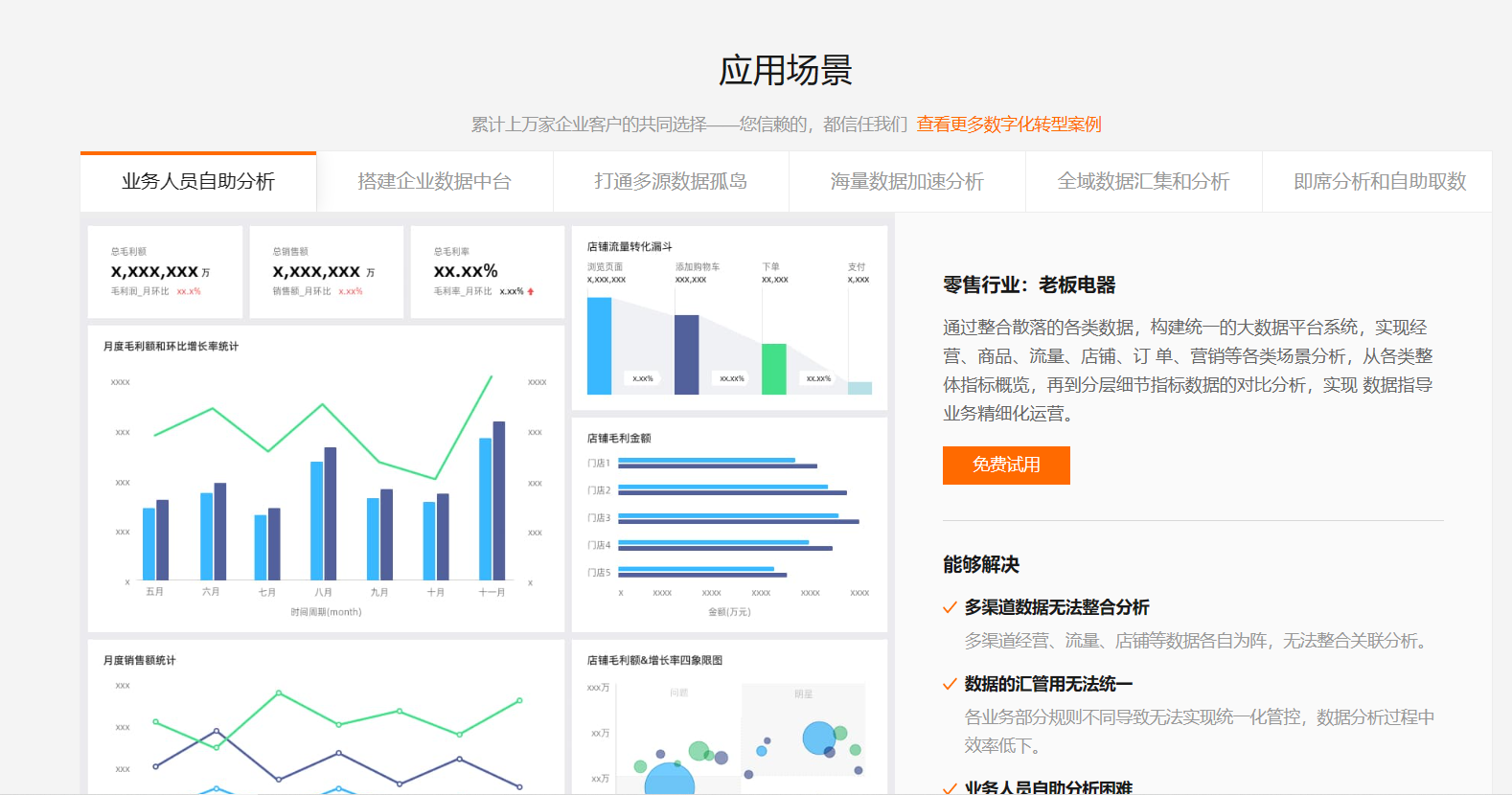
满帮实时数据矩阵图
满帮的实时数据矩阵图主要采用了云原生和 OLAP 平台的架构,主要采用了阿里云 Flink+Hologres 的应用架构。在实时数仓层面,建设了用户、货源、流量、支付、交易、营销以及 CRM 基础层,同时还建设了我们特有的数仓分层,叫实时供需层,相当于传统公司的 ADM 层。在这一层我们建设了线路司机分布情况、沿途货源分布情况、二级货类分布情况、实时离线供需融合情况以及每个出发城市或者线路沿途的疫情和天气情况。
在数仓上我们还往前更近了一层,做了实时特征。基于分钟级或者秒级的实时数仓去做数据,快速高效的赋能给算法和运营业务。包括司机和货主的行为特征、司机行为概率分布、货源行为状态分布、路线货源价格分布。同时,我们团队在实时策略上也做了相应开发,比如说司机有拼单的意愿,或者说司机有漫游行为、人群流量实时预测、Push 流量实时预测和分配。

关于为了满足实时业务的实时数据产品,它和离线数仓有一个本质区别,就是实时数据需要更多直接触达业务。那么我们怎么去定义实时数据产品呢?我们想把它变成一个实时的决策平台,包含如下几个环节:
第一步是数据洞察;
第二步是智能归因;
第三步是实时预警,指标归因出来后把数据告警给相关的业务方;
第四步是人群画像,指在告警时,需要把相关人群的画像主动勾勒出来;
第五步通过高效的 OLAP 和 Flink 计算开发一条简单的策略;
然后导入到规则引擎,让算法和运营来调取;
最后通过 A/B 效果完成整个决策平台的产品构建。
线上实时决策平台和底层数仓,主要的服务对象包含页面排序、搜索排序、智能召回、Push 收归、司机会员、委托定价等权益或价格的策略,实时决策基本上都用到了实时特征和实时数据。
在做实时数据的时候,我们思考了三个维度。第一是价值。我们需要去理解和洞察业务,然后通过实时决策平台赋能业务。第二是闭环,我们不仅只是把数据做到位,还需要考虑整个业务的闭环效果。第三是成本,主要是基于价值去衡量 ROI,如果投入与产出不成正比,我们就需要在成本上相对收敛一些。
满帮实时计算平台架构
接下来分享一下满帮实时计算平台的架构。满帮的数据分布在不同的机房,当然也分布在不同的云厂商。从下图可以看到 A 机房主要是生产系统和实时计算,B 机房主要是离线机房,即离线集群。

在这种数据架构下做实时数据的全链路能力,我们做了如下几件事:
我们做了全链路稳定性建设。数据源到最上游的数据消费做到分钟级,即一分钟、十几秒甚至几秒钟,业务系统就要消费到底层传来的数据。
我们在实时计算数据源上进行了稳定性治理。在前端埋点采用了业内比较领先的架构,后端埋点在一些关键的业务点上进行了一些打点,让数据可以做到秒级到达实时数据仓库。
我们统一了数据标准。在数据源治理完后,把所有的实时数据放到一个数据总线里,保证实时数据的消费是统一数据标准。
我们曾经采用过传统的 Doris 和自建的一些架构,但发现运维成本都相对比较高,所以最终采用了阿里的 Hologres 集群。
我们要做一个完整的数据服务生态圈。在把数据赋能到业务方和调用方的时候,我们需要提供一些 API 和消息队列。这里我们吸收了阿里云 OneService 的建设思路,构建了一个统一数据服务。
我们和算法平台一起做了实时样本归因平台,同时配合他们做了一个实时训练的框架,保证算法和运营的实时决策。
从自建 Flink 到迁移云原生的阿里云实时计算 Flink 版平台降本增效
以上是实时计算平台架构的分享,接下来分享一下,我们从自建的 Flink 迁移到云原生的阿里云实时计算 Flink 版平台的原因。原有自建集群上运行实时作业稳定性差,严重影响业务,自建整体运维成本较高,需要将重心从平台建设向业务优化倾斜,技术发展路线从开源自建向托管云服务迁移。具体如下:
第一点,阿里云实时计算 Flink 版平台采用了云原生全托管架构,部署、资源隔离在上面都具有天然的架构先进性,CU 级别智能弹性扩缩容有效提升性价比。
第二点,我们在自己搭建 Flink on Yarn 的时候,发现底层的资源隔离和资源之间的影响有很大的波动性,阿里云实时计算 Flink 版平台的云原生资源隔离能力可以实现作业级和代码级的隔离,减少互相影响,技术领先性创造平台稳定性。
第三点,阿里云实时计算 Flink 版开发平台,它的 metrics 采集系统、SQL 开发、资源调优明显改善开发效率,运维工作量和成本显著降低。
下面我们来看一下,下半年把运满满的整个实时计算 Flink 任务全部迁移到阿里云,收益是怎么样的?

我们迁移的 Flink 任务有 560 个,迁移时间仅需 1.5 个月。迁移过后,经过一段时间的观察,我们发现 SLA 的指标从 95%提升到了 99%。另外在运维人效方面,从原来的三个人到现在的一个人,全年节约了 420 人天。
在开发的效率方面,每个任务的开发、调优、上线可以提前两天。如果按照每年 300 个任务,就是节省了 600 人天。最后基于阿里云对 Flink SQL 和底层 state 状态的深度优化,我们发现平均一个 Flink SQL 任务消耗 6.67CU 的资源,而上了阿里云过后,可以节省 40%的资源。这样算下来,整体可以达到 35%的资源节省。
02
实时数据
目前我们使用阿里云 Flink+Hologres 这套架构来基于分钟级或者秒级的实时数仓去做数据,快速高效的赋能给算法和运营业务。包括司机和货主的行为特征、司机行为概率分布、货源行为状态分布、路线货源价格分布等。应用场景主要分成两个部分。第一部分是特征计算,第二部分是样本归因。样本归因即把用户的行为数据、特征数据、回流数据关联起来。
我们采用这套架构的原因是,Hologres 支持读写分离和实时数仓,其中读写分离的性能给我们带来很大的收益。另外我们在做特征的二次计算时,也采用了阿里云 Flink+Hologres 的最佳实践,实时计算 Flink 版在实时作业的稳定性上给了我们很大的惊喜,同时定时调优的策略使得资源效率显著提高,很好的为实时决策提供了数据支撑。

从实时数据到实时决策
实时决策包含两部分,分别是在算法场景的实时决策、在运营场景的实时决策。下面先分享一些我们怎么用实时数据决策算法场景。
在一个传统的推荐算法链路上,它的链条是相对比较长的。司机从 APP 进行搜索,然后经过 AB 流、子场景、召回、粗排、截断、精排,最后到实时策略。其中召回的环节,可能会带来千条的数据,所以要通过后边的环节逐步减少数据量。
从下图可以看到,AB 分流到实时策略的过程需要实时指标把它们串联起来,实时指标的数据在 AB 分流、召回、粗排、截断、精排等环节都会被用到。另外在精排的时候,用分钟级模型也要用到实时指标的数据。所以要理解实时数据的决策,首先要理解实时数据对每一个算法子模块的作用。

接下来我们思考一个问题,要怎么去推导实时数据问题定义、目标、策略和价值呢?
首先,如果我们在算法场景用实时数据赋能业务,需要考虑以下三个方面:
系统实时性,需要实时获取最新的模型和数据。
特征实时性,需要实时获取数据的分布。
模型实时性,需要保证实时拟合数据的分布。

然后我们需要确定子目标,确保特征的更实时、模型的更实时、样本的更实时。我们给自己定义的目标是,第一计算延迟全链路小于 3 分钟,关键点链路要做到 10 秒甚至 20 秒;第二整体数据延迟小于 5 分钟;第三样本准确率大于 97%。
接下来制定策略。在计算延迟方面,我们采用 阿里云 Flink+OLAP。在数据低延方面,需要考虑样本延迟、特征延迟、全链路延迟监控、数据治理、链路优化。在样本准确率方面,除了使用传统的一些样本技术,我们还需要注意样本数据质量监控和模型效果在线监控。我们采用了阿里云 Flink+Hologres 这套架构。
最后明确价值。在业务价值方面,基于搜索天模型基础,有 3%业务的提升。技术价值方面,积累沉淀实时特征模型,提升算法模型更新时效性,赋能算法业务,服务不同特色算法场景;打通增量学习全链路,为增量学习平台打下技术基础。
具备实时特征计算的实时数仓建设
下面分享基于阿里云 Flink+Hologres 实现的实时数仓的建设。我们的数仓是以位置关系、运力、供需三个维度为核心,进行双向推导和抽象。和一般的物流公司差不多,我们的实时基础数据也都包含用户、货源、车辆、流量、交易、车油、金融、风控。但我们更关注的其实是司机和货主的位置状态,因为这决定了我们的匹配效率,所以我们的实时数仓和传统的离线数仓有很大不一样。
我们基于位置构建了一套实时数仓,由于业务决策的实时必要性,产生了对数据的实时性要求,因此我们在构建数仓时,数据一部分通过 Flink CDC 同步到 Hologres,实时入仓,一部分经过实时计算后落到数仓中,形成一体化分析服务。通过位置把货源、车辆、用户、交易、流量、营销等数据关联起来。另外我们还需要深入业务,在车货匹配、定价决策、调度决策、供需监控、客服决策等方面,实时做决策。
但在这一过程中,业务使用还是会和数仓之间有一层 Gap。
实时数仓对业务的抽象度不够,要怎么办?
实时数仓到底能给业务带来什么价值?怎么度量?
实时数据怎么挖掘特有业务的指标和特征?所以我们抽象了一个实时供需引擎。
换句话来说就是在业务和实时数仓上,抽象了一个虚拟的产品层供业务使用。我们在数仓建设的时候进行了两次抽象。第一次抽象是自下而上,抽象出一个实时数仓。第二次抽象是也是自下而上,抽象出一个供需引擎。

建设实时数仓过后,我们还在进行了实时特征和实时指标的开发。在这一过程中我们发现,对接业务的时候,我们往往很被动。客户提出一个需求,我们就逐步去开发,这样往往会花费大量的时间。
比如业务提出了一个需求,数据的同学就需要大概 8 天的时间去做架构设计和数据开发。等把特征开发完后,算法同学还要进行数据的回流和模型训练及验证,这个过程又需要大概 10 天左右。整个过程需要 20 天甚至一个月才能全链路上线。

那么怎样才能提高整个链路的开发和迭代效率呢?
我们做了一个批量实时特征计算框架。举个例子,在我们的环境中,有一个点击数据需要根据算法不同的时间时间维度去看。有的算法要求 5 分钟,有的算法要求 1 个小时,有的算法要求 10 秒,这个时间是无法预估的,在算法上线之前我们无法知道哪一个时间纬度对它最有效。
除此之外,还需要看每次点击次数的分位数、近 5 分钟的分布、排名、近 5 分钟排名 log、group by 的状态、daytime 分桶特征等等。在前面基础上我们还会做一些交叉特征,比如减去常有的平均次数,当天天气情况和当前疫情情况等。所以用户提出一个数据的背后其实隐含了很多特征。

我们采用了一套阿里云实时计算Flink 版架构,来确保用户提出数据后,能尽最大可能满足业务需求。用 Window 的滑动窗口、滚动窗口保证可以做到时间上的切片和滑动。sum 代表计算,我们可以做 5 分钟、10 分钟、30 分钟的开发计算。然后通过 function 调用计算函数,自动计算出实时特征。function 定义的函数包括 log、ration、cnt、dayCategory 等。
在做了这套计算框架后,我们在研发效率上有明显提升,支撑特征批量开发,开发周期从 3 天降低到 2 天,目前还在大规模的推广,我们目标是从 3 天降低到 0.5 天。资源利用方面,我们把 120 个任务合并成 16 个,资源消耗减少 200 Core 资源。在性能和稳定性方面,我们每分钟计算出 1000+特征,且任务保持稳定运行。值得一提的是,如此庞大的计算得益于阿里云实时计算Flink版云上能力的不断更新,比如将类似 Window table-valued 函数增强、CAST 和类型系统增强、双流 Join 算子支持自动推导开启 KV 分离优化等,能力完善的同时作业运行性能显著提高,对业务决策进行了有力的支撑。
03
实时产品
解决了实时数据的问题,我们在实时数仓的基础之上,构建了以实时线上决策系统为核心定位的产品,以实时预警作为出发点开始,目前我们做了以下这些事。
第一个是实时指标告警平台烽火台,它的作用是解决实时指标的展示和告警。从下图中右边的窗口可以看到,我们可以通过实时指标烽火台把用户关心的指标展示出来;从右边的窗口可以看到,还可以对指标进行配置告警,主动触达业务告警。

第二个是实时数据服务平台,它的作用是解决实时数据服务能力。当业务方需要调用数据时,我们不能直接吐到它的消息队列里,所以希望有一套 API 接口或者一套服务来解决它调用我们数据的问题。因此我们和离线数仓共用一套 OneService,然后把我们提供的数据服务展示在一个数据超市里。业务方只需要通过一些简单的配置,就能生成 API,供用户直接调用,最后进行计费。

04
未来计划
2006 年我们上了 Hadoop;2018-2019 主要以 Spark Streaming 为主;2020 年上了 Flink DataStream;2021 年上了实时数仓和 Flink SQL;2022 年,我们搭建了实时特征、实时服务、烽火台;2022 年 Q4 我们将 Flink 迁移到了阿里云上,升级了特征平台,还对实时决策平台进行了初步构造。
2023 年,我们将把实时数据和业务进行更深度的融合,做实时决策平台 2.0;探索 Flink on AI 并大规模使用。除此之外,我们还会基于阿里云 Hologres 和别的云厂商产品,去构建我们自己的跨云 OLAP 引擎平台。

往期精选





▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT