1.产生一个等差数列(1,3,5,7,……,99)赋值给向量x
x <- array(seq(from=1, to=99, by=2))

seq函数解析
seq(from,to,length)该函数的意思是生成一组数字,从from开始,到to结束,每两个数间的间隔是length,如:
seq(2,10,2),会生成一组数:2 4 6 8 10
seq(from,to,length.out=by)表示生成一组从from到to的数量为num的数
by = ((to - from)/(length.out - 1))
附seq的其它用法:
seq(from, to)
seq(from, to, by= )
seq(from, to, length.out= )
seq(along.with= )
seq(from)
seq(length.out= )
2.产生一个内容重复的数列(1,2,3,4,5……,1,2,3,4,5),重复次数为10,并将其赋值给向量y。
z<-rep(c(1:5),10)

rep函数解析
函数形式:rep(x, time = , length = , each = ,)
参数说明:
x:代表的是你要进行复制的对象,可以是一个向量或者是一个因子。
times:代表的是复制的次数,只能为正数。负数以及NA值都会为错误值。复制是指的是对整个向量进行复制。
each:代表的是对向量中的每个元素进行复制的次数。
length.out:代表的是最终输出向量的长度。
示例:
rep(1:4, 2) #对向量(1,2,3,4)复制两次 [1] 1 2 3 4 1 2 3 4 rep(1:4, each = 2) #对向量(1,2,3,4)中的每个元素复制两次 [1] 1 1 2 2 3 3 4 4 rep(1:4, each = 2, length.out = 4) #最后输出向量的长度为4 [1] 1 1 2 2
rep(x, …):将vector x的值循环n遍
rep(1:4, 2) [1] 1 2 3 4 1 2 3 4
…: 除了x的其他参数,可以通过…传到其他方法里
times:整个数组循环几遍
rep(1:4, each = 2, times = 3) [1] 1 1 2 2 3 3 4 4 1 1 2 2 3 3 4 4 1 1 2 2 3 3 4 4
each:每个element循环几遍
rep(1:4, each = 2) [1] 1 1 2 2 3 3 4 4 rep(1:4, c(2,2,2,2)) [1] 1 1 2 2 3 3 4 4 rep(1:4, c(2,1,2,1)) [1] 1 1 2 3 3 4
length.out 输出长度为多少
rep(1:4, each = 2, len = 4) [1] 1 1 2 2 长了会被截掉 rep(1:4, each = 2, len = 13) [1] 1 1 2 2 3 3 4 4 1 1 2 2 3 短了会根据前面规则补上
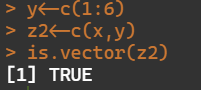
3.向量z由x和y组成。请判断x、y、z的属性是否为向量
is.vector(z2)
4.请删除x中第个1数值
x[-1] #这里实际上并没有对x进行改变

x <- x[-1] #这样的话就修改了向量x

5.请删除y中所有的取值1。
如何删除指定数据-subset or which()
讲一下利用索引的手法删除数据集合。
数据如下
> Data
英雄 职业 熟练等级 使用频次 胜率
1 后裔 射手 5 856 0.64
2 孙尚香 射手 5 211 0.10
3 狄仁杰 射手 5 324 0.20
4 李元芳 射手 4 75 0.30
5 安琪拉 法师 5 2324 0.40
6 张良 法师 4 755 0.50
7 不知火舞 法师 4 644 0.60
8 貂蝉 法师 3 982 0.70
9 <NA> <NA> NA NA NA
法一:互斥法
> # 提取法师职业
> subset(Data, 职业 != "法师")
英雄 职业 熟练等级 使用频次 胜率
1 后裔 射手 5 856 0.64
2 孙尚香 射手 5 211 0.10
3 狄仁杰 射手 5 324 0.20
4 李元芳 射手 4 75 0.30
> # 提取非法师职业
> subset(Data, 职业 != "法师")
英雄 职业 熟练等级 使用频次 胜率
1 后裔 射手 5 856 0.64
2 孙尚香 射手 5 211 0.10
3 狄仁杰 射手 5 324 0.20
4 李元芳 射手 4 75 0.30
> # 提取胜率大于等于50%
> subset(Data, 胜率 >= 0.5)
英雄 职业 熟练等级 使用频次 胜率
1 后裔 射手 5 856 0.64
6 张良 法师 4 755 0.50
7 不知火舞 法师 4 644 0.60
8 貂蝉 法师 3 982 0.70
> # 提取胜率小于50%
> subset(Data, 胜率 < 0.5)
英雄 职业 熟练等级 使用频次 胜率
2 孙尚香 射手 5 211 0.1
3 狄仁杰 射手 5 324 0.2
4 李元芳 射手 4 75 0.3
5 安琪拉 法师 5 2324 0.4
方案一可以解决一部分的这类问题,但是这种方案需要你的全集不会有缺失值非数这样的其他不在全集里的事件。所以有下面第二种补充方法。
法二:位置法
> n = which(Data$胜率 >= 0.5)
> Data[-n,]
英雄 职业 熟练等级 使用频次 胜率
2 孙尚香 射手 5 211 0.1
3 狄仁杰 射手 5 324 0.2
4 李元芳 射手 4 75 0.3
5 安琪拉 法师 5 2324 0.4
9 <NA> <NA> NA NA NA
可以看到这种删除只删除了胜率大于等于50%,保留了缺失值。
那么回归到我们这里的问题
如何删除向量y中所有的1
方法1👇
y<-subset(y,y != 1)

方法2👇
n <- which(y == 1) y[-n]

6.请选择出x中第2个数值,以及>90的数值,结果存放在同一个向量中
x <- c(1:100) y <- c(x[2],subset(x,x>90)) print(y)

7.请选择出x中分别处于偶数位置和奇数位置的数值。
> x<-c(1:100) > max(x) [1] 100 > jswz<-seq(from=1,to=max(x),by=2) > oswz<-seq(from=2,to=max(x),by=2) > jswz [1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 [19] 37 39 41 43 45 47 49 51 53 55 57 59 61 63 65 67 69 71 [37] 73 75 77 79 81 83 85 87 89 91 93 95 97 99 > oswz [1] 2 4 6 8 10 12 14 16 18 20 22 24 26 [14] 28 30 32 34 36 38 40 42 44 46 48 50 52 [27] 54 56 58 60 62 64 66 68 70 72 74 76 78 [40] 80 82 84 86 88 90 92 94 96 98 100