目录
前言
题外话
什么是索引
索引的使用场景
索引的失效瞬间
索引的数据结构
Tree
BTree
B+Tree
索引提高查询效率的原因
索引的分类
innodb的特点
聚簇索引
非聚簇索引
索引操作
创建索引
查询索引
删除索引
外键
结语
前言
上一章中讲解了慢sql优化的方式,其中索引并没有着重去说,那是因为索引内容特殊,它的数据结构复杂,足够我们单独开一篇来着重讲讲,这一篇将带领大家补齐上一章中关于索引优化的部分,也将对索引的底层数据结构做一个深度的剖析,希望大家喜欢。
题外话
之所以拖了这么久才开更是因为前几天🐑了,躲得过初一,躲不过十五,到今天才多少缓过来点劲,又重感冒加身,这哪是普通的发烧?简直是脱层皮啊。实际上我只烧了一天两夜,也就第一天不太起得来,第二天之后就是虚弱,时刻都能睡着,嗓子不怎么痛,就是咳嗽,到今天已经好很多了,一直出虚汗导致着凉又重感冒,999伺候吧。大家还是要照顾好自己。
什么是索引
索引是作用在数据库表的列上,用于对该列的数据进行排序,形成一个目录,从而提高查询效率的东西,索引比较适合数据量比较大的表中。
索引的使用场景
- 大数据量使用,因为索引的创建也需要一定的时间;
- 给需要作为查询条件的字段设置索引;
- 给不需要频繁修改的字段设置索引,若是经常修改,会导致索引重建,也会浪费时间;
- 索引不是越多越好,一般我们建议最多也就五六个吧。
索引的失效瞬间
索引的存在是为了帮助我们快速查询到数据,如果由于操作不当导致了全表扫描,那么索引就失去了其作用。接上一篇,所以我们使用sql的时候要避免这么做:
- 避免在where子句中对数据进行判null操作,这将导致引擎放弃使用索引而转而使用全表扫描,比如:where name is null 或者is not null;
- 避免在where子句中使用!=操作;
- 避免在where子句中使用or作为连接条件,比如where name=xxx or age=xxx,这会导致如果其中一个字段没有索引,其他有索引的字段也不会使用索引;
- 谨慎使用not in,in不会导致索引失效,not in(xxx,xxx,xxx,......)因为范围太大,索引就会失效,进行全表扫描;
- 避免在where子句当中使用like模糊查询,这里仅限左模糊(like '_%');
- 避免在where子句中使用表达式,比如:select ...... from table where age+4>20;
- 避免在where子句中使用函数表达式,比如:select ...... from ...... where round(money)=....
索引可以提高select的效率,但也会拉低insert和update的效率,因为insert和update可能导致索引重建。
索引的数据结构
索引的底层采用的是B+Tree
B+Tree又是基于BTree的
Tree
Tree就是树,顾名思义,像树一样的结构,只要是树,就一定拥有四个属性:
- 根结点:位于顶端且仅有一个
- 高度:整个树的层次
- 度:树中最大子节点树
- 叶子结点:位于最底层且没有子节点,或者说度为0的节点
BTree
我不能告诉你什么是BTree,因为其本质上就是一个Tree,BTree有如下特点:
- 以数据块来保存元素,并实现排序;
- 每个数据块中保存的最大数据量为(度-1),如果数据量达到度值,进行分裂提取,将中间值进行提取,原数据块分裂为左右两个数据块;
- 每次比较可通过中间值排除相当一部分的数据,树有几层,则排除几次,查询效率大大提高。
我们可以通过下图来查看BTree的数据结构大概长什么样:

指的注意的是,提取时,被提取的元素是中间值,且不会再存在于原数据块中(和B+Tree有区别),这些关键点要牢记。
B+Tree
和BTree相比,B+Tree的查询效率要更高,我们不妨来看看B+Tree和BTree有哪些不同吧:
- 叶子数据块之间通过单向链表进行连接,目的是为了提高区域查询效率(举个例子,比如查询相近的数据,比如查询0007和0011,查到0007之后,可以直接通过链表查询到下一个叶子结点找到0011,比重新中根结点开始查0011的效率要更高);
- 叶子数据块进行分裂提取的时候,被提取的数据依然位于叶子数据块中,但如果是非叶子数据块,则向上提取时不会继续保留到原数据块中,这是因为所有的数据都已经存在于叶子数据块中,非叶子数据块这时候只是起到了目录的作用,保证要查询的数据位于叶子结点中,这一点和BTree不太一样,BTree不一定查询到叶子结点。
- 查询次数减少,B+Tree我只关心叶子结点的数据,其他结点都只作为目录使用。
来看看B+Tree的数据结构:
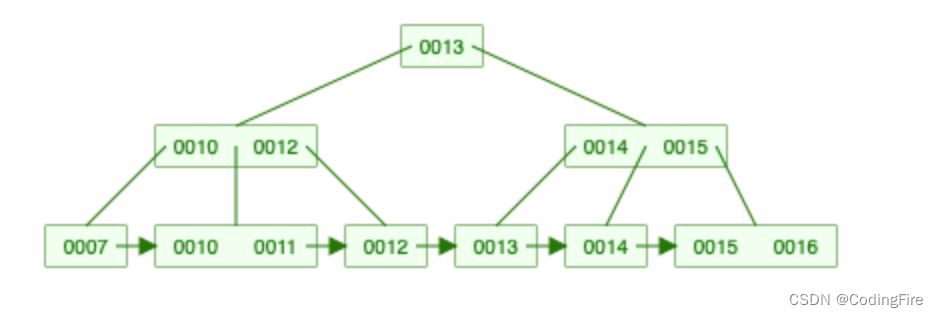
和BTree很相似,但是其叶子结点间互相通过单向链表进行连接, 原因上面已经给出,可以看到,被从叶子提取出去的元素依然位于原模块中,非叶子结点则不会,这些被提取出去的节点就成了目录的效果,最终查询一定会到叶子结点。
索引提高查询效率的原因
数据库的索引都是保存在磁盘中的,且默认高度为3,度根据数据的量进行调整。所以查询的过程是IO查询。
当给数据库中某列添加一个索引的时候,索引就会对该列的数据进行排序,创建B+Tree目录,查询时根据该列进行查询时会通过B+Tree进行查询。
因为树的默认高度为3,所以最终都会进行3次的IO查询,第一次对根结点,第二次对子节点,第三次对叶子结点。这里要注意一点,每一次查询完都会将查到的数据缓存内存中进行多次的IO操作,这是因为在内存中查询效率更高,而每一个结点存在的数据不止一条。第三次缓存后在内存中查找具体的数据将最终得到想要的值。
注意:在内存中进行查询时采用的是二分查找法,而不是遍历。
虽然索引的底层是B+Tree,但是索引对B+Tree进行了优化:在叶子数据块中保存的元素不是一个元素值,而是以key-value的形式存在。至于key和value分别保存什么,要看索引的分类。
索引的分类
- 聚簇索引/聚集索引:给主键id添加的索引
- 非聚簇索引/非聚集索引:给非主键字短添加的索引
在说这两个索引之前,需要先讲一下innodb的特点,方便理解。
innodb的特点
我们知道,从mysql5.5开始,引擎被替换成了innodb:
- innodb支持事务和行锁,上一篇有提到行锁;
- 默认给主键添加聚簇索引,如果没有设置主键,会自动添加隐藏主键,类行为long,长度为6,并添加聚簇索引;
- 除聚簇索引,innodb默认会给添加了unique约束以及外键约束的字段添加索引。
聚簇索引
聚簇索引由innodb默认添加,不需要开发者手动添加,这一点我们已经很清晰了。
聚簇索引中key和value分别是什么?
- key为主键id;
- value为id对应的整行数据。
这也是为什么通过id可以快速查找到整行数据的原因。
非聚簇索引
非聚簇索引需要开发者手动添加。
非聚簇索引中key和value分别是什么?
- key为那一列的值;
- value为该行数据对应的id的值
所以,非聚簇索引是先通过key找到主键的id的值,再通过id的聚簇索引找到整行数据,以达到快速查找数据的目的。我们把这一过程叫做“回表操作”。
索引操作
创建索引
create index index_name on table_name(col)
案例: 给字段添加unique约束,验证是否Innodb默认给添加了索引
添加unique约束:
已有表:alter table table_name add xxx type unique;
创建表:create table table_name(id int primary key,name varchar(50) unique)
对主键进行操作,可以尝试下,看是否会报错,报错则说明默认添加了索引,自行尝试。查询索引
show index from table
删除索引
drop index index_name on table外键
前面提到了外键,外键产生的原因是:一张表中的非主键字段来源于其他表中的主键字段的值,这就叫外键,是外键,就可以添加外键约束。
外键约束需要手动添加,被添加了外键约束的字段有个特点:这个被作为外键的主键字段原表中的那条数据不可被删除。
结语
这些东西没什么捷径可言,全凭经验。所以有时候你会看到工作好几年的人还是会犯同样的错误,这并不可怕,多练习,多总结,你现在踩过的坑终将成为你未来路上的垫脚石。