Kafka系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Kafka系列
#博学谷IT学习技术支持
文章目录
- Kafka系列
- 前言
- 一、Topic的分片与副本机制
- 1.什么是分片呢
- 2.什么是副本呢
- 二、kafka如何保证数据不丢失
- 1.生产者如何保证数据不丢失
- 1.ACK机制:
- 2.相关思考点:
- 3.相关的配置:
- 4.模拟同步发送数据:
- 5.模拟异步缓冲池发送数据:
- 2.Broker端如何保证数据不丢失
- 3.消费端如何保证数据不丢失
- 1使用手动的方式提交偏移量信息:
- 三、kafka的消息存储和查询机制
- 四、kafka中生产者的数据分发策略
- 五、kafka的消费者负载均衡的机制
- 1点对点消费模式:
- 2发布订阅消费模式:
- 六、通过命令的方式查看数据积压问题
- 总结
前言
Kafka是Apache旗下的一款开源免费的消息队列的中间件产品,最早是由领英公司开发的, 后期共享给Apache, 目前已经是Apache旗下的顶级开源的项目, 采用语言为Scala

适用场景: 数据传递工作, 需要将数据从一端传递到另一端, 此时可以通过Kafka来实现, 不局限两端的程序
在实时领域中, 主要是用于流式的数据处理工作
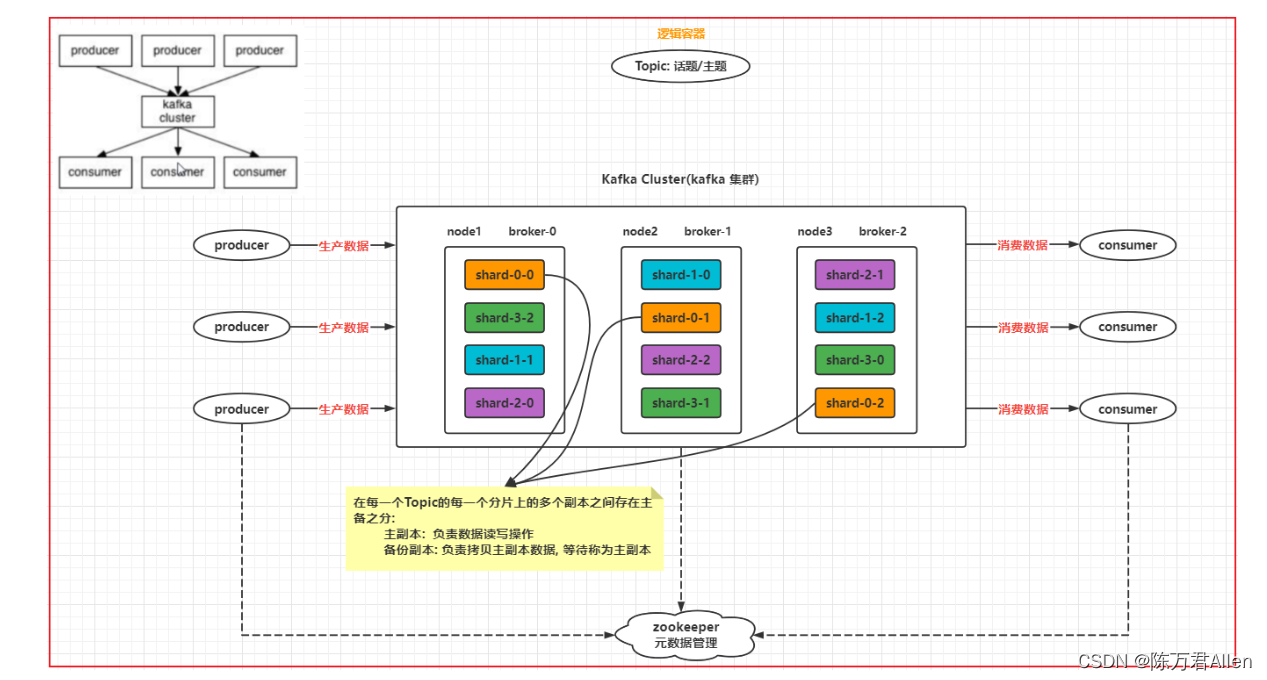
一、Topic的分片与副本机制
1.什么是分片呢
分片: 逻辑概念
相当于将一个topic(大容器)拆分为N多个小的容器, 多个小的容器构建为一个Topic(大容器)
目的:
1- 提高读写的效率: 分片可以分布在不同节点上, 在进行读写的时候, 可以让多个节点一起负责
2- 分布式存储: 解决单台节点存储容量有限的问题
分片的数量: 分片是可以创建N多个, 理论上没有任何的限制
2.什么是副本呢
副本: 物理概念
针对每个分片的数据, 可以设置备份, 可以将其备份多个
目的:
提高数据的可靠性, 防止数据丢失
副本的数量: 副本的数量最多与节点的数量保持一致, 但是一般设置2个 或者 3个最多了
二、kafka如何保证数据不丢失
1.生产者如何保证数据不丢失
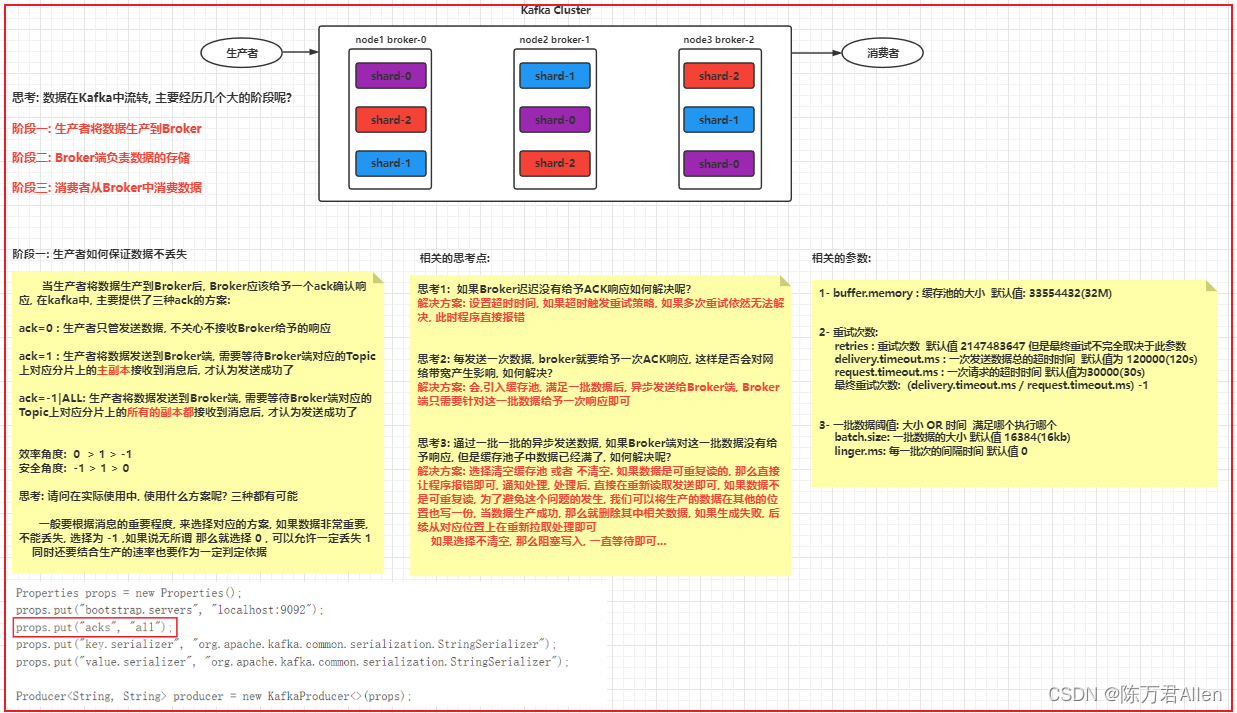
1.ACK机制:
当生产者将数据生产到Broker后, Broker应该给予一个ack确认响应, 在kafka中, 主要提供了三种ack的方案:
ack=0 : 生产者只管发送数据, 不关心不接收Broker给予的响应
ack=1 : 生产者将数据发送到Broker端, 需要等待Broker端对应的Topic上对应分片上的主副本接收到消息后, 才认为发送成功了
ack=-1|ALL: 生产者将数据发送到Broker端, 需要等待Broker端对应的Topic上对应分片上的所有的副本都接收到消息后, 才认为发送成功了
效率角度: 0 > 1 > -1
安全角度: -1 > 1 > 0
2.相关思考点:
思考1: 如果Broker迟迟没有给予ACK响应如何解决呢?
解决方案: 设置超时时间, 如果超时触发重试策略, 如果多次重试依然无法解决, 此时程序直接报错
思考2: 每发送一次数据, broker就要给予一次ACK响应, 这样是否会对网络带宽产生影响, 如何解决?
解决方案: 会,引入缓存池, 满足一批数据后, 异步发送给Broker端, Broker端只需要针对这一批数据给予一次响应即可
3.相关的配置:
1- buffer.memory : 缓存池的大小 默认值: 33554432(32M)
2- 重试次数:
retries : 重试次数 默认值 2147483647 但是最终重试不完全取决于此参数
delivery.timeout.ms : 一次发送数据总的超时时间 默认值为 120000(120s)
request.timeout.ms : 一次请求的超时时间 默认值为30000(30s)
最终重试次数: (delivery.timeout.ms / request.timeout.ms) -1
3- 一批数据阈值: 大小 OR 时间 满足哪个执行哪个
batch.size: 一批数据的大小 默认值 16384(16kb)
linger.ms: 每一批次的间隔时间 默认值 0
4.模拟同步发送数据:
package com.itheima.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaProducerSyncTest {
// 演示 如何同步发送数据
public static void main(String[] args) {
// 1. 创建Kafka的核心对象
Properties props = new Properties();
props.put("bootstrap.servers","node1:9092,node2:9092,node3:9092");
props.put("acks",-1);
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer kafkaProducer = new KafkaProducer<String,String>(props);
//2.执行发送数据 同步发送模式
try {
kafkaProducer.send(new ProducerRecord("test01","张三111")).get();
// 发送成功了 ....
} catch (Exception e) {
// 发送失败了: 一旦失败, 就会抛出异常
// 注意: 一旦有异常, 程序已经自动完成重试操作后, 依然无法发送成功的状态
// 在此处编写发送失败后, 解决方案....
e.printStackTrace();
}
}
}
5.模拟异步缓冲池发送数据:
package com.itheima.kafka.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class KafkaProducerASyncTest {
// 演示 如何异步发送数据
public static void main(String[] args) {
// 1. 创建Kafka的核心对象
Properties props = new Properties();
props.put("bootstrap.servers","node1:9092,node2:9092,node3:9092");
props.put("acks","-1");
props.put("batch.size",32768);
props.put("linger.ms",3000);
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer kafkaProducer = new KafkaProducer<String,String>(props);
//2.执行发送数据 异步发送模式
kafkaProducer.send(new ProducerRecord("test01", "张三111"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 回调函数: 底层在异步发送数据的时候, 发送一次, 就会调用一次回调函数, 如果exception不为null, 说明发送失败了
System.out.println(exception);
if(exception != null){
// 认为数据发送失败
// 在此处编写处理失败的逻辑代码
}
// 发送成功了....
}
});
//3 .释放资源
kafkaProducer.close();
}
}
2.Broker端如何保证数据不丢失
保证方案: 磁盘存储 + 多副本 + ack为-1
3.消费端如何保证数据不丢失
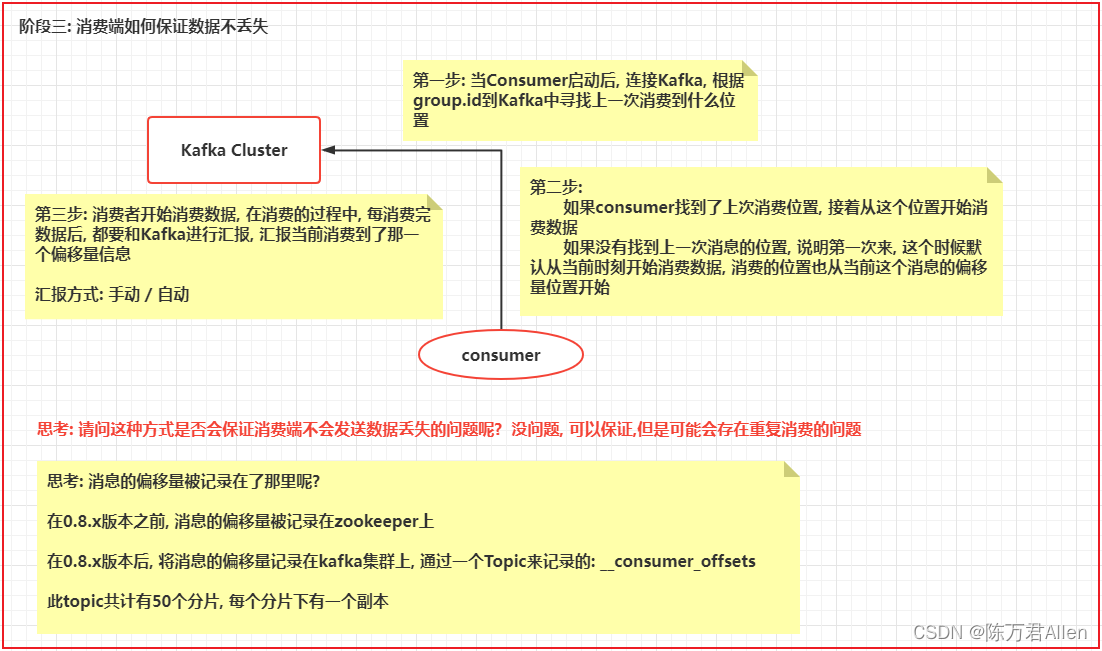
总结: 通过此种方式, 可以保证消费端不会将数据丢失, 但是存在重复消费的问题
1使用手动的方式提交偏移量信息:
package com.itheima.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumer2Test {
// 演示 手动提交偏移量
public static void main(String[] args) {
// 1- 创建Kafka的消费者的核心对象: KafkaConsumer
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.put("group.id", "t1"); // 消费者组的ID
props.put("enable.auto.commit", "false"); // 是否自动提交偏移量offset
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // key值的反序列化的类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // value的值反序列化的类
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2. 订阅topic: 表示消费者从那个topic来消费数据 可以指定多个
consumer.subscribe(Arrays.asList("test01"));
while (true) {
// 3. 从kafka中获取消息数据, 参数表示当kafka中没有消息的时候, 等待的超时时间, 如果过了等待的时间, 返回空对象(对象存在, 但是内部没有数据 相当于空容器)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long offset = record.offset();
String key = record.key();
String value = record.value();
// 偏移量: 每一条数据 其实就是一个偏移量 , 每个分片单独统计消息到达了第几个偏移量 偏移量从 0 开始的
System.out.println("消息的偏移量为:"+offset+"; key值为:"+key + "; value的值为:"+ value);
}
// 每消费完一批 提交一次偏移量
// 注意: 一旦使用手动提交偏移量, 千万要注意, 必须写提交偏移量代码, 否则会导致大量的数据重复消费
consumer.commitAsync(); // 异步提交方式
//consumer.commitSync();
}
}
}
三、kafka的消息存储和查询机制
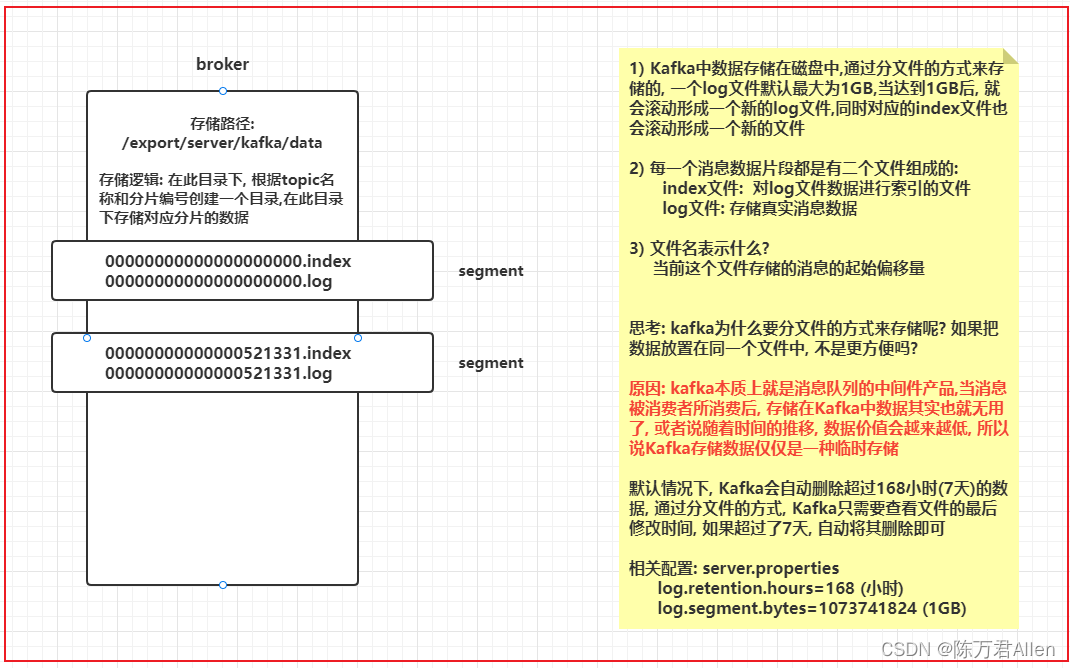
查询数据的步骤:
- 1- 确定消息被存储在那个segment片段中
- 2- 先去对应segment端中index文件, 从这个索引文件中, 查询对应偏移量, 在Log文件的什么位置上进行存储的
- 3- 根据返回的在log文件的具体的位置信息, 基于磁盘顺序查询方式查询Log文件, 找到对应位置上的数据即可
四、kafka中生产者的数据分发策略
生产者的数据分发策略: 生产者将数据生产到Kafka的某个Topic中, Topic可以被分为多个分片, 最终一条消息只能被其中一个分片所接收,那么最终是由哪个分区来接收数据呢? 这就是生产者的数据分发
Kafka所支持的分区策略:
1- 粘性分区策略(2.4版本下, 支持轮询策略) Java客户端支持, 但是Python客户端不支持
2- hash取模的策略
3- 指定分区策略
4- 随机分区策略: Python客户端是支持的 Java不支持
5- 自定义分区策略
五、kafka的消费者负载均衡的机制

1点对点消费模式:
让所有监听这个topic的消费者都 在 同一个消费者组
2发布订阅消费模式:
让所有监听这个topic的消费者都 不在 同一个消费者组
六、通过命令的方式查看数据积压问题

总结
以上就是今天要讲的内容,本文主要介绍了Kafka的基础和一些常规Java的操作。以后会有更多关于kafka的企业级综合案例。