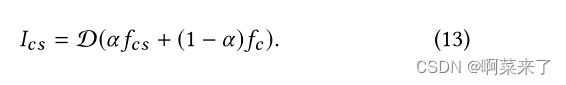基础概念回顾
前面几节我们分别详细分析了分区,索引,数据存储相关原理,这些组件配合在一起给Clickhouse数据库带来非常高效的查询性能。前面的文章也单独介绍了这几个组件。接下来,就分别从写入过程、查询过程,以及数据标记与压缩数据块的三种对应关系的角度展开介绍,我们首先回顾一下这些概念:
- 分区: 在MergeTree中,数据是以分区目录的形式进行组织的,每个分区独立分开存储,借助这种形式,数据查询时可以有效跳过无用的数据文件,只使用最小的分区目录子集;
- 一级索引使用二进制格式存储,用于存储稀疏索引,一张 MergeTree 表只能通过 ORDER BY 或 PRIMARY KEY声明一次一级索引。借助稀疏索引,在查询数据时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度;
- 二级索引又称为跳数索引,由数据的聚合信息构建而成,根据索引类型的不同,其聚合信息的内容也不同,跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围;
- 数据bin文件是由1至多个压缩数据块组成的,每个压缩块大小在64KB~1MB之间,多个压缩数据块之间,按照写入顺序首尾相接,紧密地排列在一起;
- 数据标记使用二进制格式存储,标记文件中保存了 data.bin 文件中数据的偏移量信息,并且标记文件与稀疏索引对齐,因此 MergeTree 通过标记文件建立了稀疏索引(primary.idx)与数据文件(data.bin)之间的映射关系。而在读取数据的时候,首先会通过稀疏索引(primary.idx)找到对应数据的偏移量信息(data.mrk),因为两者是对齐的,然后再根据偏移量信息直接从 data.bin 文件中读取数据。
写入&查询流程分析
写入流程
- 数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录,在后续的某一时刻,属于相同分区的分区目录会被合并到一起;
- 按照index_granularity索引粒度,会分别生成 primary.idx 一级索引(如果声明了二级索引,还会创建二级索引文件);
- 按照index_granularity索引粒度,生成每一个列字段的压缩数据文件(.bin)和数据标记文件(.mrk),如果数据量不大,则是 data.bin 和 data.mrk 文件。
下图所示是一张MergeTree表在写入数据时,它的分区目录、索引、标记和压缩数据的生成过程。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LL7RvgZ7-1672192978184)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227190119500.png)]](https://img-blog.csdnimg.cn/ef32548e5e574555979e8905d030d91f.png)
从分区目录 202006_1_34_3 能够得知,该分区数据总共分 34 批写入,期间发生过 3 次合并。在数据写入的过程中,依据 index_granularity 的粒度,依次为每个区间的数据生成索引、标记和压缩数据块。其中索引和标记区间是对齐的,而标记与压缩块则是根据区间大小的不同,会生成多对一、一对一、一对多的关系。
查询流程
数据查询的本质,可以看作一个不断减小数据范围的过程。在最理想的情况下,MergeTree 首先可以依次借助分区索引、一级索引和二级索引,将数据 扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sFCl96q4-1672192978185)(/Users/lidongmeng/Library/Application Support/typora-user-images/image-20221227190143652.png)]](https://img-blog.csdnimg.cn/1ceeafbce8d049f09e378e532aa1f3e8.png)
如果一条查询语句没有指定任何 WHERE 条件,或者指定了 WHERE 条件、但是没有匹配到任何的索引(分区索引、一级索引、二级索引),那么 MergeTree 就不能预先减少数据范围。在后续进行数据查询时,它会扫描所有分区目录,以及目录内索引段的最大区间。不过虽然不能减少数据范围,但 MergeTree 仍然能够借助数据标记,以多线程的形式同时读取多个压缩数据块,以提升性能。
参考
- https://www.cnblogs.com/traditional/p/15218743.html
- https://mp.weixin.qq.com/s/VTTYMdY5A2SZNQdkZoXuhw
- Clickhouse原理解析与应用实践 朱凯