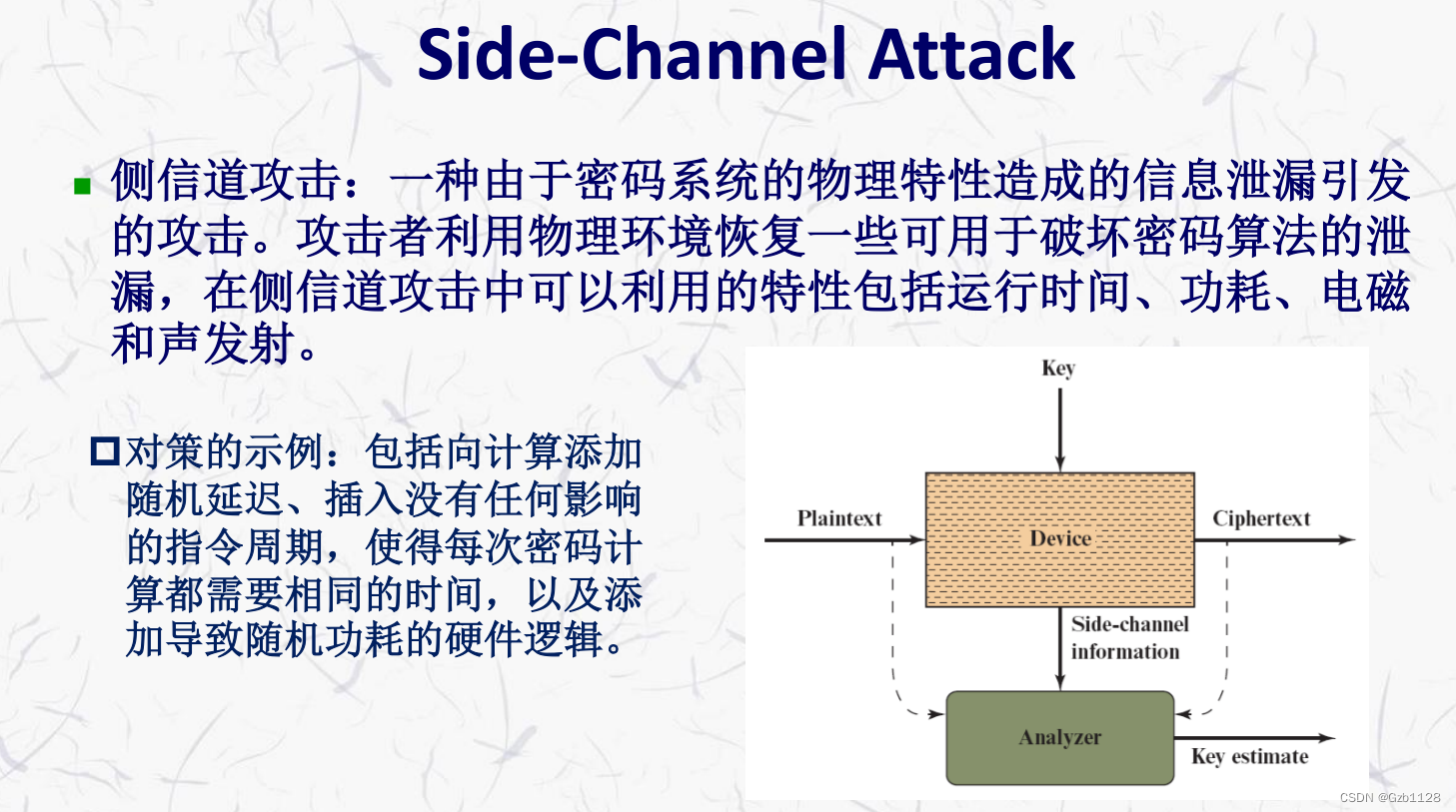
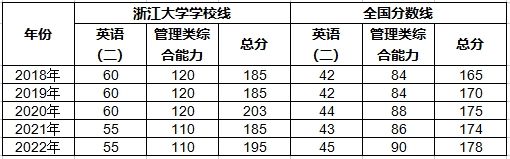
ABSTRACT
任意风格转换是一个具有研究价值和应用前景的重要课题。给定一个内容图像和引用的风格绘画,一个所需的风格转换将使用风格绘画的色彩色调和生动的笔画模式渲染内容图像,同时保持详细的内容结构信息。风格迁移方法首先学习内容和内容和风格引用的风格表示,然后生成由这些表示指导的程式化图像。
本文提出了包含两个自适应(SA)模块和一个自适应(CA)模块的多自适应网络:SA模块自适应地分离内容和风格表征,即内容SA模块使用位置自注意增强内容表征,风格SA模块使用通道自注意增强风格表征;CA模块通过非局部方式计算解纠缠的内容与样式特征之间的局部相似度,根据内容表示分布重新排列样式表示分布。
此外,一种新的解纠缠损失函数(a new disentanglement loss function) 使我们的网络能够分别提取主要样式模式和精确的内容结构来适应不同的输入图像。
各种定性和定量实验表明,所提出的多适应网络比最先进的风格迁移方法带来更好的结果。
INTRODUCTION
艺术风格转换是一种以艺术风格模式渲染自然图像,同时保持自然图像内容结构的重要技术。
1、近年来,研究人员应用卷积神经网络(convolutional neural networks, CNNs)进行图像翻译和风格化[3,31]。
2、Gatys等[3]创新地使用从VGG16中提取的深度特征来表示图像内容结构,并计算激活图的相关性来获得图像风格模式。然而,这种基于优化的方法也很耗时。
3、基于[3],许多工作要么加快了传输过程,要么提高了生成质量[3,10,12,22,24,27,30]。
4、Johnson等[10]使用前馈神经网络来实现实时风格渲染的目的。
5、Gatys等[4]对[3]的基本模型进行了改进,得到了更高质量的结果,拓宽了应用领域。
6、为了进一步扩展风格迁移的应用,很多著作都集中在任意风格迁移方法上[6,9,16,17,20,23,25,28]。
7、AdaIN[8]和WCT[17]将风格图像的二阶统计量与内容图像对齐。然而,整体的风格转换过程使得生成的质量令人失望。
8、基于Patch-swap的方法[1,28]的目的是根据patch对之间的相似性将style image patch转移到content image。但是,当内容分布和样式结构变化较大时,很少有样式模式通过样式交换[1]转移到内容图像中。
9、Yao等[28]对风格交换[1]方法进行了改进,增加了多行程控制和自注意机制。
10、Park等[20]受自注意机制的启发,提出了风格注意,将风格特征匹配到内容特征上,但可能会遇到内容语义结构图像失真的问题。
11、此外,大多数风格传输方法使用一个通用的编码器来提取内容和风格图像的特征,这忽略了有助于改进生成的领域特定特征。
12、近年来,一些研究人员[5,7,11,13,14,19,26,29,31,32]已经使用生成对抗网络(GANs)进行高质量的图像到图像的翻译。基于gan的方法可以生成高质量的艺术作品,可以被认为是真实的。
13、风格和内容表示对于翻译模型是必不可少的。许多著作[5,13,29,32]都专注于对风格和内容的分离,以便让模型意识到深层特征的孤立因素。然而,图像间翻译虽然可以实现多模态风格引导的翻译结果,但由于其在不可见域的局限性,难以适应任意风格迁移。
为了增强上述任意风格转移方法的生成效果,我们提出了一种灵活高效的带有解缠机制的任意风格转移模型,在保留内容图像细节结构的同时,将参考画作丰富的风格模式转移到生成结果中。如图1所示,最先进的方法可以将参考的色调和风格呈现到内容图像中。然而,内容结构(房屋轮廓)和笔画模式并没有很好地保存和转移。本文提出了由两个自适应(SA)模块和一个自适应(CA)模块组成的多适应网络。SA模块使用位置自注意增强内容表示,通道自注意增强样式表示,自适应地分离了内容和样式表示。
同时,CA模块调整样式分布以适应内容分布。我们的模型可以通过SA和CA之间的交互来学习有效的内容和风格特征,并根据内容特征重新排列风格特征。然后,我们合并重新排列的样式和内容特征,以获得生成的结果。该方法通过SA和CA过程,考虑了内容和样式图像中的全局信息以及图像补丁之间的局部相似性。此外,我们还引入了一种新的风格和内容表示的解纠缠损耗。内容解纠缠损失使得在使用共同内容图像和不同风格图像生成一系列风格化结果时,从风格化结果中提取的内容特征相似。风格解纠缠损失使得在使用共同风格图像和不同内容图像生成一系列风格化结果时,从风格化结果中提取的风格特征相似。解纠缠损失使网络能够提取出主要的风格模式和精确的内容特征,分别适应不同的内容和风格图像。
综上所述,我们的主要贡献如下:
1、涉及两个SA模块和一个CA模块的灵活高效的多自适应任意风格传输模型。
2、一种用于风格和内容解纠缠的新型解纠缠损失函数,以提取定向良好的风格和内容信息。
3、各种实验表明,我们的方法可以保留内容图像的详细结构,并将参考画作的丰富风格模式转移到生成的结果中。此外,我们分析了在计算解纠缠内容与风格特征之间的局部相似度时,不同卷积感受野大小对CA模块的影响。

图1:使用克劳德·莫奈的绘画作为风格参考的风格化结果。与一些最先进的算法相比,我们的结果可以保留详细的内容结构并保持生动的样式模式。例如,我们结果中的山和房屋结构被很好地保存了下来。
我们可以观察到,通过放大样式参考和我们的结果中的相似补丁,绘画笔触和颜色主题得到了很好的转移。
RELATED WORK
风格转移。
1、自从Gatys et al[3]提出了第一个使用cnn的风格传输方法后,很多工作都致力于提高传输效率和生成效果。
一些文献[10,15,24]提出了实时前馈式传输网络,通过训练一个独立的网络只能传输一种风格。任意风格迁移成为一个重要的研究课题,获得了广泛的应用。
2、Chen等[1]最初根据补丁相似度将样式图像补丁交换到内容图像上,实现了任意样式图像的快速样式迁移。
3、Huang等[8]提出了自适应实例归一化AdaIN,以整体方式调整内容图像的均值和方差以适应风格图像。
4、Li et al[17]利用WCT对样式和内容图像的协方差进行对齐,并将多层样式模式转移到内容图像中,以获得更好的程式化结果。
5、Avatar-Net[23]应用样式装饰器来保证语义对齐和整体匹配,将局部和全局样式模式组合到风格化的结果。
6、Park等[20]提出了一种风格注意网络SAnet,将风格特征匹配到内容特征上,以获得明显的风格模式的良好结果。
7、Yao等[28]利用自注意机制获得了多笔式结果。
然而,上述任意样式迁移方法不能有效地平衡内容结构的保存和样式模式的呈现。这些方法的缺点可以在4.2节中观察到。因此,我们的目标是提出一个任意的风格传输网络,有效地将风格模式传输到内容图像,同时保持详细的内容结构。
Feature Disentanglement.
近年来,研究[5,7,11,13,14,19,29,31,32]使用生成对抗网络(GANs),哪些风格转换任务在某些情况下可以应用,实现图像翻译。适合于风格迁移任务的一个重要思想是风格和内容特征应该是一致的
解纠缠是因为畴偏移。
1、朱等[7]使用两个编码器,提取潜在代码,以理清风格和内容表示。
2、Kotovenko等人[13]提出了一种解纠缠风格和内容分离的损失。3、Kazemi et al.[11]描述了一个风格和内容解纠缠GAN (SC-GAN)来学习一种语义内容和文本样式的表示。
4、Yu等人[29]通过编码器-解码器将输入与潜在代码分离网络。
现有的解纠缠网络通常采用不同的编码器,通过一个训练过程来解耦特征。然而,编码器的结构相似,不太适合于风格和内容的分离。在本文中,我们设计了内容和风格的SA模块,通过考虑内容的结构和风格的纹理来具体地分解特征。
METHODOLOGY
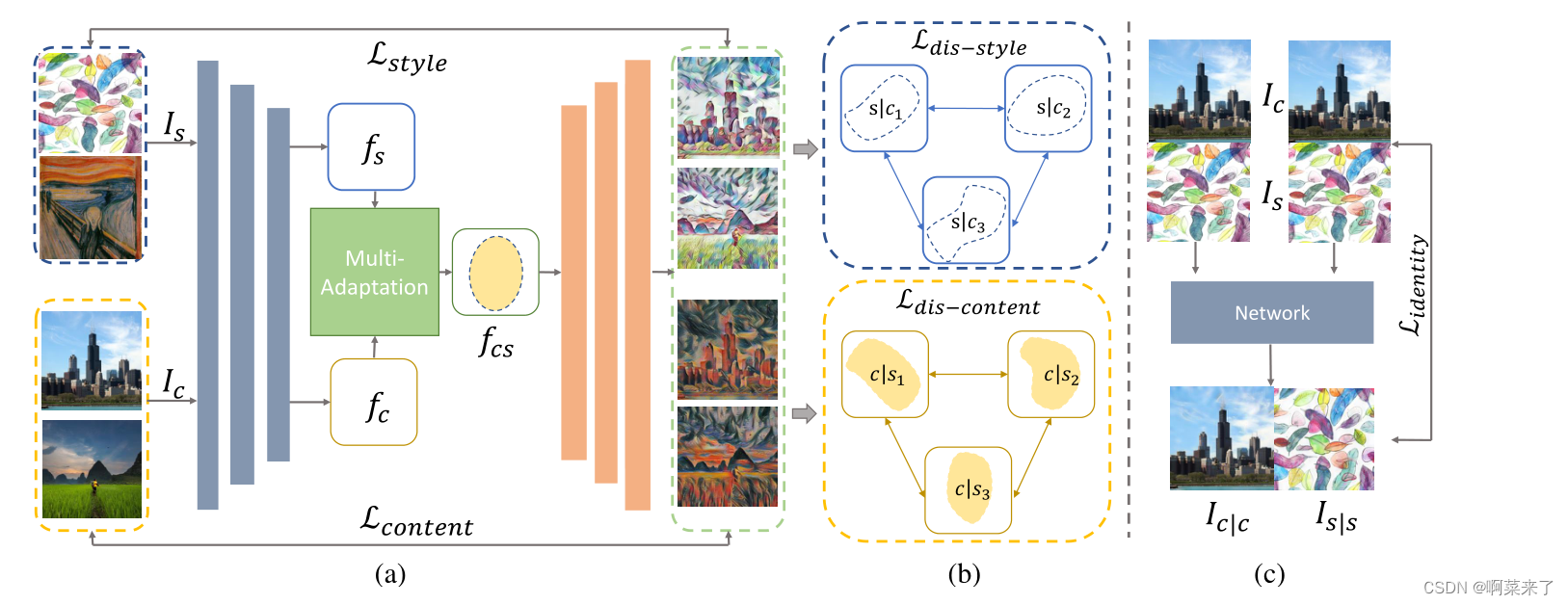
图2:(a)我们的网络结构。蓝色的块是编码器,橙色的块是解码器。给定输入的内容图像Ic和样式图像Is,我们可以通过编码器分别获得相应的特征fc和fs。然后将fc和fs输入到多适应模块中,得到生成的特征fcs。最后,我们通过解码器生成结果ic。此外,损耗是通过预先训练的VGG19来计算的。lcontent测量Ic和Ic之间的差异。Lstyl e计算ic和Is之间的差值。(b)解缠损失。Ldis - content决定了风格化结果之间的内容差异,这些结果是使用不同的风格图像和一个共同的内容图像生成的。
Ldis - style评估风格化结果之间的风格差异,这些结果是使用不同的内容图像和公共风格图像生成的。©身份丧失。Lident if y量化了Ic |c (Is |s)和Ic (Is)之间的差异,其中Ic |c (Is |s)是使用两张公共内容(样式)图像的风格化结果。
为了实现任意风格传输,我们提出了一种前馈网络,它包含一个编码器-解码器架构和一个多自适应模块。
图2显示了我们的网络结构。我们使用预训练的VGG19网络作为编码器来提取深度特征。给定一个内容图像Ic和风格图像Is,我们可以提取出对应的特征映射f Ic = E(Ic)和f Is = E(Is), i∈{1,…L}。然而,编码器是使用ImageNet数据集进行分类任务的预训练,这并不适合于风格传输任务。同时,考虑到艺术绘画和摄影图像之间的域偏差,使用通用编码器只能提取少量的域特定特征。因此,我们提出了一种多适应模块,通过自适应过程将风格和内容表示解纠缠,然后通过自适应过程根据内容分布重新排列解纠缠的风格分布。我们可以通过多自适应模块获得风格化的功能。
第3.1节详细描述了多适应模块。解码器是编码器的镜像版本,我们可以得到生成的结果Ics = D(fcs)。该模型通过最小化3.2节中描述的三种损失函数来训练。
Multi-adaptation Module
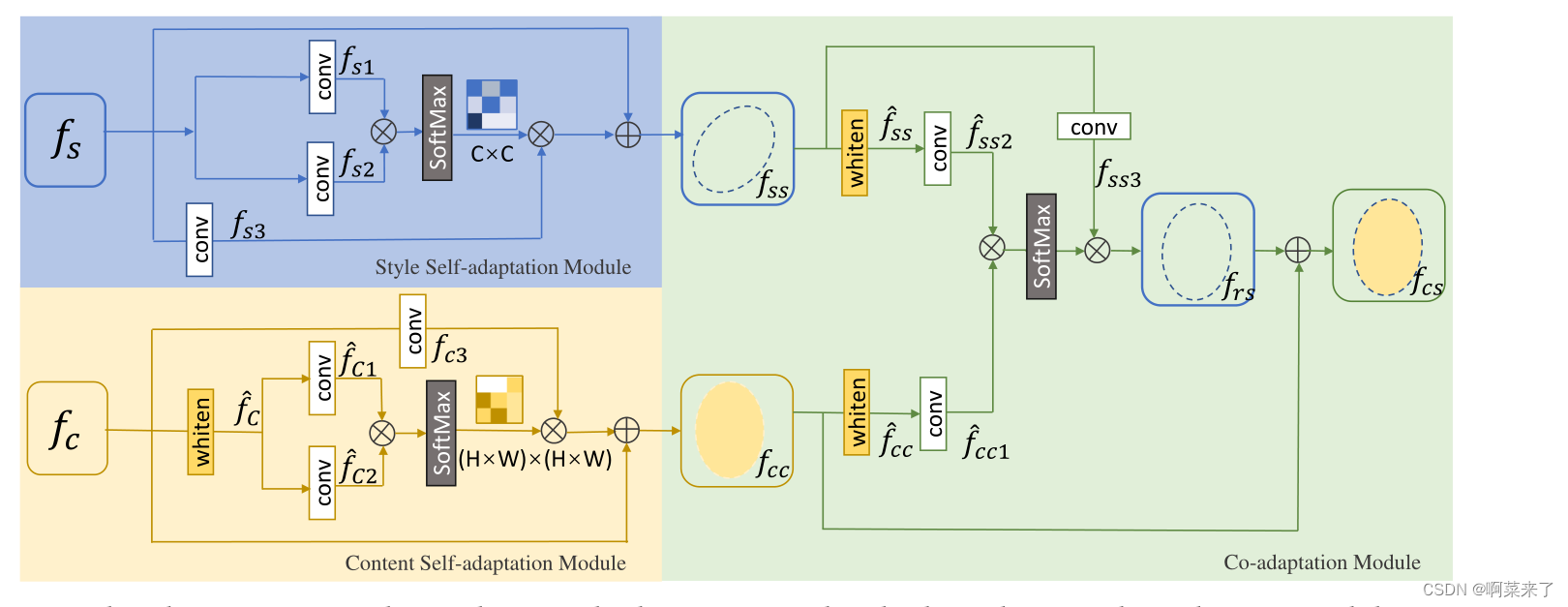
图3:多适应网络。我们通过两个独立的SA模块来理清内容和风格。我们可以通过内容/样式SA模块将相应的内容/样式表示fc (fs)分解为fcc (fss)。然后,CA模块根据内容分布对样式分布进行重新排列,生成重新排列的特征帧。最后,我们合并fcc和fr,得到风格化特征fcs。
图3显示了多自适应模块,该模块分为三个部分:按位置的内容SA模块、按通道的样式SA模块和CA模块。我们通过两个独立的位置式内容和通道式风格SA模块来分离内容和风格。我们可以通过内容/样式SA模块将相应的内容/样式表示fc (fs)分解为fcc (fss)。然后CA模块根据内容表示重新排列样式表示,生成风格化的特征fcs。
位置内容自适应模块。为了在风格化结果中保留内容图像的语义结构,在[2]中引入位置注意模块,自适应地捕获内容特征中的远程信息。给定一个内容特征映射fc∈RC×H ×W, fc表示经过漂白的内容特征映射,它通过[17]中的美白变换去除与风格相关的纹理信息。我们向两个卷积层馈入了我爸/我爸/我爸/我爸/我爸/我爸/我爸/我爸/我爸/我爸。与此同时,我们将fc输入到另一个卷积层以生成新的特征映射fc3。我们将fc1、fc2、fc3重塑为RC×N,其中N = H × W。
那么,内容空间注意图Ac∈RN ×N则公式为:
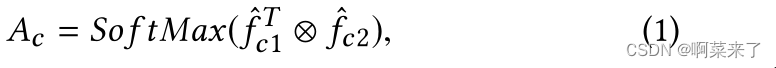
其中⊗表示矩阵乘法;和f Tc1⊗fc2表示特征映射fc1和fc2之间的位置乘法。然后,我们通过矩阵乘法和元素加法得到增强的内容特征映射fc:

通道样式自适应模块。学习风格图像的风格模式(例如,纹理和笔画)对风格迁移很重要。受[3]的启发,矢量化特征图之间的通道内积可以表示风格,因此我们在[2]中引入通道注意模块来增强风格图像中的风格模式。输入样式特性不需要加白,这与内容SA模块不同。我们将样式特征映射fs∈RC×H ×W馈送给两个卷积层,生成两个新的特征映射fs1和fs2。同时,我们将fs输入到另一个卷积层,生成新的特征图fs3。我们将fs1, fs2, fs3重塑为RC×N,其中N = H × W。那么,风格空间注意图As∈RC×C则公式为:
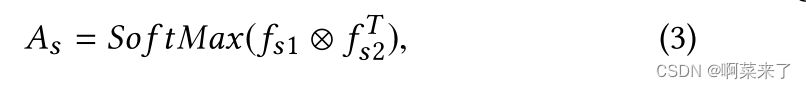
其中fs1⊗f Ts2表示特征映射fs1和fs2之间的通道乘。然后,我们通过矩阵乘法和元素相加来调整样式特征映射fs:

互相适应模块。通过SA模块,我们得到了解纠缠的风格和内容特征。然后,我们提出了CA模块来计算解纠缠特征之间的相关性,并自适应地将它们重新组合到输出特征图上。
生成的结果既能保留突出的内容结构,又能根据相关性对语义内容进行适当的风格模式调整。图3显示了CA流程。首先,将解纠缠的样式特征图fss和内容特征图fcc分别白为需求方和需求方。然后,我们向两个卷积层馈入fcc和fss,生成fcc1和fss2两个新的特征映射。同时,我们将特征图fss馈送到另一个卷积层,生成新的特征图fss3。
我们重塑fcc1、fss2、fss3为RC×N,其中N = H ×W。那么,相关图Acs∈RN ×N则表示为:
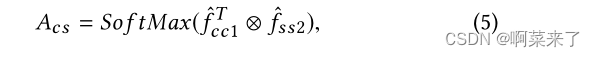
其中,位置(i, j)中的Acs值分别度量第i个位置与第j个位置在内容特征和风格特征上的相关性。然后,将重新排列的样式特征映射fr s映射为:

最后得到CA结果:

Loss Function
我们的网络在训练过程中包含三个损失函数。
知觉的损失。与AdaIN[8]类似,我们使用一个预先训练好的VGG19来计算内容和风格的感知损失。内容感知损失lcontent用于最小化生成图像与内容图像之间的内容差异,其中
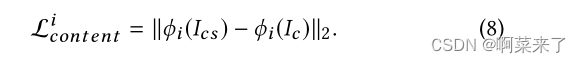
使用风格感知损失Lstyl e来最小化生成图像和风格图像之间的风格差异:
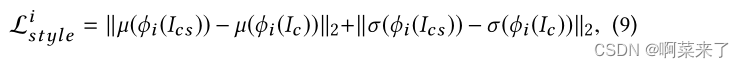
其中,ϕi(·)表示从预训练的VGG19的第i层提取的特征,µ(·)表示特征的均值,σ(·)为特征的方差。
身份的损失。受[20]的启发,我们引入了身份损失,为风格和内容特征之间的映射关系提供了一个软约束。识别损失公式如下:
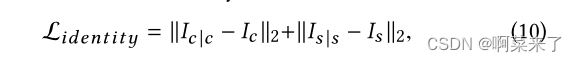
其中Ic |c表示同时使用一幅自然图像作为内容和风格图像生成的结果,Is |s表示同时使用一幅绘画作为内容和风格图像生成的结果。
解开纠结的损失。样式特性应该独立于目标内容,以分离样式和内容表示。即使用相同内容图像和不同风格图像生成一系列风格化结果时,内容解纠缠损失使得从风格化结果中提取的内容特征相似。当使用相同样式图像和不同内容图像生成一系列程式化结果时,样式解纠缠损失使得从程式化结果中提取的样式特征相似。因此,我们提出了一种新的解缠损耗:
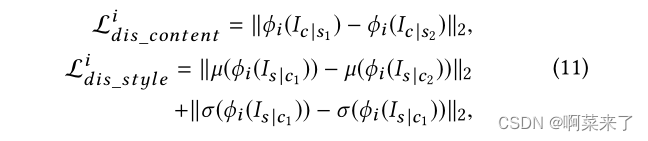
其中Ic |s1和Ic |s2是使用相同内容图像和不同风格图像生成的结果,Is |c1和Is |c2是使用相同风格图像和不同内容图像生成的结果。总损失函数公式如下:
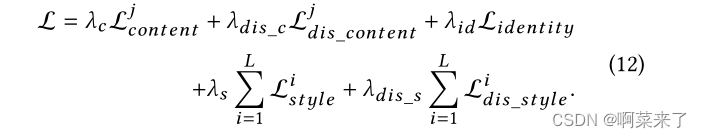
一般来说,损失函数限制了生成的结果和内容/样式图像之间的全局相似性。这两个SA模块通过计算输入特征的长范围自相似度来分解全局的内容/风格表示。CA模块通过非局部方式计算解纠缠的内容与样式特征之间的局部相似度,根据内容分布重新排列样式分布。因此,我们的网络可以考虑全局的内容结构和本地的风格模式,从而产生迷人的结果。

图4:程式化结果与SOTA方法的比较。第一列显示样式图像,第二列显示内容图像。其余的列是我们的方法AdaIN [8], WCT [17], SANet[20]和AAMS[28]的风格化结果。
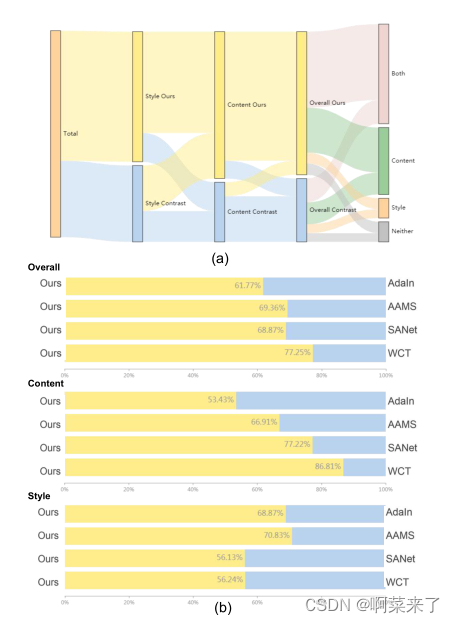
图5:用户研究结果:(a)桑基图显示了我们的结果和对比结果之间用户偏好的总体结果,(b)每种对比方法的详细结果。

图6:有/没有解纠缠损失的程式化结果的比较。(a)通过风格与内容的分离,不同的内容形象具有统一的风格模式,这是风格形象的关键组成部分(紫羽毛)。(b)随着风格和内容的分离,内容结构更加明显。
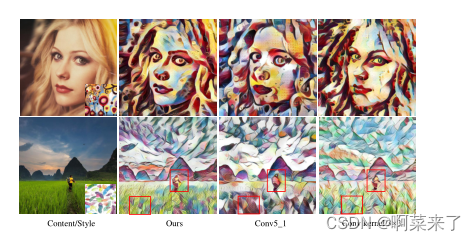
图7:不同感受野大小的程式化结果的比较。与我们的结果相比,第3列和第4列结果的精细结构没有得到很好的保存(详见红框)
EXPERIMENTS
Implementation Details
我们使用MS-COCO[18]作为内容数据集,使用WikiArt[21]作为样式数据集。在训练阶段,将样式和内容图像随机裁剪为256 × 256像素。在测试阶段支持所有图像大小。我们在编码器(预先训练的VGG19)中使用conv1_1, conv2_1, conv3_1和conv4_1层来提取图像特征。
将conv4_1层的特征输入多自适应模块,生成特征fcs。此外,我们使用conv4_1层计算内容感知损失和解纠缠损失,使用conv1_1、conv2_1、conv3_1和conv4_1层计算风格感知损失和解纠缠损失。多适应模块中使用的卷积核大小均设置为1 × 1。λc、λs、λid、λdis_c、λdis_s的权重分别为1、5、50、1、1。

图8:内容和风格之间的权衡。

图9:样式插值。
Comparison with Prior Work
定性评估。我们将我们的方法与AdaIN [8], WCT [17], SANet[20]和AAMS[28]这四种最先进的方法进行比较。
图4显示了程式化的结果。AdaIN[8]和WCT[17]根据风格图像的二阶统计量对内容图像进行全局调整,但忽略了内容与风格之间的局部相关性。它们的风格化结果在不同的图像位置有相似的重复纹理。AdaIN[8]调整内容图像的均值和方差,以适应全局风格图像。
虽然风类化图像的内容结构得到了很好的保留(图4中的第3行和第7行),但仍然会有不充分的文本模式被转移到风类化图像中(图4中的第1行、第4行、第5行和第8行)。WCT[17]通过美白和着色变换操作调整内容图像的协方差,提高了AdaIN的风格性能。但是,WCT会引入内容失真(第2、4、6、7和8行)。SANet[20]使用风格注意将风格特征与内容特征进行匹配,可以生成具有独特风格纹理的有吸引力的风格化结果。然而,如果不进行特征解缠,风格化结果中的内容结构是不清晰的(图4中的第2、4和8行)。
此外,多层特征的使用导致结果中出现重复的样式补丁(图4中第3行是眼睛)。AAMS[28]也采用了自注意机制,但自注意的使用效果不够。结果显示,内容图像的主要结构清晰,但其他结构受损,生成图像中的样式模式不明显(图4中的第2、3、4、5、8行)。
与上述方法不同的是,在多自适应网络中解纠缠的内容和风格特征可以很好地表现出特定领域的特征。因此,我们的方法生成的结果可以进一步保留内容和样式信息。此外,我们的方法通过自适应调整解纠缠的内容和风格特征,可以得到内容结构清晰、风格模式丰富的好结果。内容图像可以由基于语义结构的相应样式模式呈现(图4中的第一行)。
用户研究。我们进行用户研究,以进一步比较我们的视觉性能和前面提到的SOTA方法。
我们选择20个样式图像和15个内容图像,为每种方法生成300个结果。最初,我们向参与者显示每个内容样式对。然后我们向他们展示两个结果(一个是我们的方法,另一个是从SOTA方法之一中随机选择的)。我们问参与者四个问题:(1)哪种风格化结果进一步保留了内容结构,(2)哪种风格化结果进一步转移了风格模式,(3)哪种风格化结果整体提高了视觉质量,(4)在选择问题中的图像时,(3)主要考虑的因素是内容、风格、两者都有,还是都没有?我们要求30名参与者进行50轮比较,每个问题获得1500票。图5显示了统计结果。图5(a)给出了一个桑基图,即用于显示数据流的方向。例如,在风格上选择我们方法的用户中,大多数人也选择我们的内容,少数人选择对比方法的内容。从图5(a)可以看出,无论是内容、风格还是整体效果,我们的方法都获得了大多数人的支持。在选择整体视觉效果改善的结果时,参与者更容易受到内容而不是风格的影响。
随后,我们在图5(b)中分别将我们的方法与各个比较方法在内容、风格和整体上进行比较。该方法的总体性能优于各种比较方法。我们的结果与AdaIN[8]相比,在风格上有明显的优势,内容保存能力相当。我们的结果与WCT[17]]相比,在内容和可比较的风格模式上有明显的优势。我们的结果与AAMS[28]相比,在内容和风格上都有明显的优势。
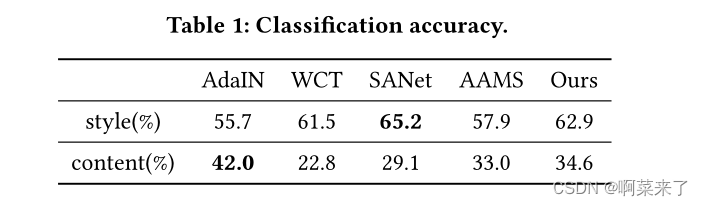
定量评价。为了量化我们的方法的风格转移和内容保存能力,我们首先引入了一个艺术家分类模型来评估每个艺术家的风格对风格化结果的渲染效果。我们选择5位艺术家,每人1000幅画,按照8:2的比例分成训练集和测试集。然后利用训练集对预训练的VGG19模型进行微调。我们为每个方法生成1000个程式化图像。
我们将程式化的图像输入到艺术家分类模型中来计算精度。其次,我们使用内容分类模型来量化不同方法的内容保存效果。
我们从ImageNet数据集中随机选择5个类。然后利用ImageNet的训练集对预训练的VGG19模型进行微调。我们使用相应的验证集(5个类,每个类包括50个内容图像)为每个方法生成1000个程式化图像。将经过风格化处理的图像输入到内容分类模型中,计算分类精度。
分类结果见表1。我们的方法的风格和内容分类准确率值都比较高,说明我们的方法可以在内容和风格之间进行权衡。虽然SANet实现了最高的风格分类精度,但内容分类精度太低,无法获得有吸引力的结果。AdaIN内容分类准确率的分类精度较高,但样式分类精度较低。总体而言,每种方法的内容/风格分类结果与用户研究结果一致。统计上的小差异是因为参与者在选择改进的内容/风格结果时可能会受到生成结果的影响
Ablation Study
验证解缠损耗的效果。我们比较了有解纠缠损失和没有解纠缠损失的结果来验证解纠缠损失的效果。如图6所示,与没有解纠缠损失的程式化结果相比,使用解纠缠损失可以生成带有风格图像的关键样式模式(紫色羽毛,图6(a))或更可见的内容结构(图6(b))的结果。有解纠缠损失后,风格化结果能保持统一的风格模式和突出的内容结构。
卷积感受野大小的影响。在CA模块中计算解纠缠内容与风格特征之间的局部相似度时,卷积运算的感受域大小会影响生成的结果。有两个因素可以改变感受野的大小。首先,在编码器中将卷积核大小固定为3 × 3;模型越深,我们得到的接受野越大。因此,我们用conv5_1代替编码器层的conv4_1来获得较大的接受场。其次,我们将内容和样式特征提供给CA模块中的两个卷积层,并计算它们之间的相关性。
此模块中使用的卷积核大小与接受域相关,这影响用于计算相关性的区域的大小。因此,我们改变卷积核的大小从1 × 1到3 × 3,以获得一个大的接受场。
如图7所示,使用conv5_1或内核大小为3 × 3的风式化结果被转换为更局部的样式模式(例如,第一行的圆形模式和第二行的羽毛模式),内容结构高度扭曲。结果表明,较大的接受野会进一步关注局部结构,并在空间上扭曲全局结构。
Applications
内容和风格之间的权衡。我们可以通过改变下面函数中的α来调整风格化结果中的样式模式权重:
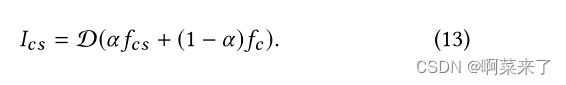
当α = 0时,我们得到原始内容图像。当α = 1时,我们得到完全程式化的图像。我们把α从0变为1。图8显示了结果。
风格插值。对于更灵活的应用程序,我们可以将多个风格的图像合并到一个生成的结果中。图9给出了这些示例。我们也可以改变不同风格的权重。
CONCLUSIONS AND FUTURE WORK
在本文中,我们提出了一种多自适应网络,通过考虑解缠的内容和风格特征之间的长范围局部相似性,将全局内容和风格表示解缠,并将风格分布调整为内容分布。
此外,我们提出了一种解纠缠损失,使风格特征独立于目标内容特征,以限制风格和内容特征的分离。我们的方法可以实现内容结构保存和样式模式呈现之间的平衡。充分的实验表明,我们的网络可以考虑全局内容结构和局部风格模式,从而产生令人着迷的结果。我们还分析了cnn中接受域大小对生成结果的影响。
在未来的工作中,我们的目标是开发一种风格图像选择方法,基于内容和风格的全局语义相似性为给定的内容图像推荐合适的风格图像,以用于额外的实际应用。
REFERENCES
[1] Tian Qi Chen and Mark Schmidt. 2016. Fast patch-based style transfer of arbitrary
style. In Constructive Machine Learning Workshop, NIPS.
[2] Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, and Hanqing Lu.
2019. Dual attention network for scene segmentation. In IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR). IEEE, 3146–3154.
[3] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. 2016. Image style transfer
using convolutional neural networks. In IEEE Conference on Computer Vision and
Pattern Recognition (CVPR). IEEE, 2414–2423.
[4] Leon A Gatys, Alexander S Ecker, Matthias Bethge, Aaron Hertzmann, and Eli
Shechtman. 2017. Controlling perceptual factors in neural style transfer. In IEEE
Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 3985–3993.
[5] Abel Gonzalez-Garcia, Joost Van De Weijer, and Yoshua Bengio. 2018. Image-
to-image translation for cross-domain disentanglement. In Advances in Neural
Information Processing Systems (NeurIPS). 1287–1298.
[6] Shuyang Gu, Congliang Chen, Jing Liao, and Lu Yuan. 2018. Arbitrary style
transfer with deep feature reshuffle. In IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR). IEEE, 8222–8231.
[7] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. 2018. Multimodal
unsupervised image-to-image translation. In European Conference on Computer
Vision (ECCV). Springer, 172–189.
[8] Xun Huang and Belongie Serge. 2017. Arbitrary style transfer in real-time with
adaptive instance normalization. In IEEE International Conference on Computer
Vision (ICCV). IEEE, 1501–1510.
[9] Yongcheng Jing, Xiao Liu, Yukang Ding, Xinchao Wang, Errui Ding, Mingli
Song, and Shilei Wen. 2020. Dynamic Instance Normalization for Arbitrary Style
Transfer. In Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI). AAAI
Press.
[10] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-
time style transfer and super-resolution. In European Conference on Computer
Vision (ECCV). Springer, 694–711.
[11] Hadi Kazemi, Seyed Mehdi Iranmanesh, and Nasser Nasrabadi. 2019. Style and
content disentanglement in generative adversarial networks. In IEEE Winter
Conference on Applications of Computer Vision (W ACV). IEEE, 848–856.
[12] Nicholas Kolkin, Jason Salavon, and Gregory Shakhnarovich. 2019. Style Transfer
by Relaxed Optimal Transport and Self-Similarity. In IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR). IEEE, 10051–10060.
[13] Dmytro Kotovenko, Artsiom Sanakoyeu, Sabine Lang, and Bjorn Ommer. 2019.
Content and style disentanglement for artistic style transfer. In Proceedings of
the IEEE International Conference on Computer Vision (ICCV). IEEE, 4422–4431.
[14] Dmytro Kotovenko, Artsiom Sanakoyeu, Pingchuan Ma, Sabine Lang, and Bjorn
Ommer. 2019. A Content Transformation Block for Image Style Transfer. In
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,
10032–10041.
[15] Chuan Li and Michael Wand. 2016. Precomputed real-time texture synthesis with
markovian generative adversarial networks. In European Conference on Computer
Vision (ECCV). Springer, 702–716.
[16] Xueting Li, Sifei Liu, Jan Kautz, and Ming-Hsuan Yang. 2019. Learning linear
transformations for fast image and video style transfer. In IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR). IEEE, 3809–3817.
[17] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang.
2017. Universal style transfer via feature transforms. In Advances in Neural
Information Processing Systems (NeurIPS). 386–396.
[18] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva
Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft COCO: Common
objects in context. In European Conference on Computer Vision (ECCV). Springer,
740–755.
[19] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. 2017. Unsupervised image-to-
image translation networks. In Advances in Neural Information Processing Systems
(NeurIPS). 700–708.
[20] Dae Young Park and Kwang Hee Lee. 2019. Arbitrary Style Transfer With Style-
Attentional Networks. In IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPR). IEEE, 5880–5888.
[21] Fred Phillips and Brandy Mackintosh. 2011. Wiki Art Gallery, Inc.: A case for
critical thinking. Issues in Accounting Education 26, 3 (2011), 593–608.
[22] Falong Shen, Shuicheng Yan, and Gang Zeng. 2018. Neural style transfer via
meta networks. In IEEE Conference on Computer Vision and Pattern Recognition
(CVPR). IEEE, 8061–8069.
[23] Lu Sheng, Ziyi Lin, Jing Shao, and Xiaogang Wang. 2018. Avatar-net: Multi-
scale zero-shot style transfer by feature decoration. In IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR). IEEE, 8242–8250.
[24] Dmitry Ulyanov, Vadim Lebedev, Andrea Vedaldi, and Victor Lempitsky. 2016.
Texture Networks: Feed-Forward Synthesis of Textures and Stylized Images. In
International Conference on International Conference on Machine Learning (ICML)
(New York, NY, USA). JMLR.org, 1349âĂŞ1357.
[25] Hao Wang, Xiaodan Liang, Hao Zhang, Dit-Yan Yeung, and Eric P Xing. 2017.
ZM-NET: Real-time zero-shot image manipulation network. (2017). arXiv:arXiv
preprint arXiv:1703.07255
[26] Miao Wang, Xu-Quan Lyu, Yi-Jun Li, and Fang-Lue Zhang. 2020. VR content
creation and exploration with deep learning: A survey. Computational Visual
Media 6, 1 (2020), 3–28.
[27] Hao Wu, Zhengxing Sun, and Weihang Yuan. 2018. Direction-Aware Neural Style
Transfer. In Proceedings of the 26th ACM International Conference on Multimedia
(Seoul, Republic of Korea). Association for Computing Machinery, New York, NY,
USA, 1163–1171.
[28] Yuan Yao, Jianqiang Ren, Xuansong Xie, Weidong Liu, Yong-Jin Liu, and Jun
Wang. 2019. Attention-aware multi-stroke style transfer. In IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR). IEEE, 1467–1475.
[29] Xiaoming Yu, Yuanqi Chen, Shan Liu, Thomas Li, and Ge Li. 2019. Multi-mapping
Image-to-Image Translation via Learning Disentanglement. In Advances in Neural
Information Processing Systems (NeurIPS). 2990–2999.
[30] Yuheng Zhi, Huawei Wei, and Bingbing Ni. 2018. Structure Guided Photoreal-
istic Style Transfer. In Proceedings of the 26th ACM International Conference on
Multimedia. Association for Computing Machinery, 365–373.
[31] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. 2017. Unpaired
image-to-image translation using cycle-consistent adversarial networks. In IEEE
International Conference on Computer Vision (CVPR). IEEE, 2223–2232.
[32] Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A Efros,
Oliver Wang, and Eli Shechtman. 2017. Toward multimodal image-to-image
translation. In Advances in Neural Information Processing Systems (NeurIPS). 465–
476.