摘要:OpenAI的GPT4o模型最近的突破在图像生成和编辑方面展现了令人惊讶的良好能力,引起了社区的极大兴奋。 本技术报告介绍了第一眼评估基准(名为GPT-ImgEval),定量和定性诊断GPT-4o在三个关键维度的性能:(1)生成质量,(2)编辑熟练程度,以及(3)世界知识信息语义合成。 在所有三项任务中,GPT-4o都表现出强劲的性能,在图像生成控制和输出质量上都显著超过了现有方法,同时也展示了出色的知识推理能力。 此外,基于GPT-4o生成的数据,我们提出了一种基于分类模型的方法来研究GPT-4o的底层架构,我们的实证结果表明,该模型由一个自动回归(AR)和一个基于扩散的图像解码头组成,而不是VAR类架构。 我们还对GPT-4o的整体架构进行了完整的推测。 此外,我们进行了一系列分析,以识别和可视化GPT-4o的特定局限性以及在其图像生成中常见的合成伪影。 我们还对GPT-4o和Gemini 2.0 Flash之间的多轮图像编辑进行了比较研究,并讨论了GPT-4o输出的安全影响,特别是现有图像取证模型对它们的可检测性。 我们希望我们的工作能够提供有价值的见解,并提供可靠的基准来指导未来的研究,促进可重复性,并加速图像生成等领域及其他领域的创新。 用于评估GPT-4o的代码和数据集可以在github.com。Huggingface链接:Paper page,论文链接:2504.02782
研究背景和目的
研究背景
随着人工智能技术的飞速发展,特别是在大型多模态语言模型(MLLMs)领域,图像生成和编辑技术取得了显著进展。OpenAI最新发布的GPT-4o模型在图像生成和编辑方面展现出了令人瞩目的能力,其性能远远超出了以往的方法。GPT-4o不仅能够根据文本提示生成高质量的图像,还能对图像进行精细的编辑,如修改对象属性、添加或删除对象等。这些能力使得GPT-4o在数字内容创作、交互式助手等领域具有广泛的应用前景。
然而,尽管GPT-4o在图像生成和编辑方面取得了显著成果,但其性能如何、存在哪些局限性、以及未来如何进一步改进等问题仍然需要进一步研究和探索。为了系统地评估GPT-4o在图像生成方面的能力,并为其未来的改进提供指导,本研究提出了GPT-ImgEval基准测试框架。该框架旨在通过定量和定性的方式,全面诊断GPT-4o在图像生成质量、编辑熟练程度以及世界知识信息语义合成等关键维度的性能。
研究目的
- 定量和定性评估GPT-4o的性能:通过设计一系列基准测试任务,全面评估GPT-4o在图像生成质量、编辑熟练程度以及世界知识信息语义合成等方面的表现。
- 揭示GPT-4o的底层架构:基于GPT-4o生成的数据,提出一种基于分类模型的方法来推测GPT-4o的底层架构,为理解其工作原理提供线索。
- 识别和分析GPT-4o的局限性:通过详细的错误分析和案例研究,识别GPT-4o在图像生成和编辑过程中存在的具体局限性,为未来模型的改进提供指导。
- 比较不同模型在图像编辑任务上的性能:将GPT-4o与其他先进的图像编辑模型进行比较,评估其在多轮图像编辑任务上的表现。
- 探讨GPT-4o输出的安全性:讨论GPT-4o生成的图像在现有图像取证模型下的可检测性,为生成对抗网络(GANs)和其他生成模型的安全性研究提供参考。
研究方法
基准测试框架设计
GPT-ImgEval基准测试框架涵盖了三个核心图像生成任务:文本到图像生成(Text-to-Image Generation)、基于指令的图像编辑(Instruction-based Image Editing)和世界知识信息语义合成(World Knowledge-Informed Semantic Synthesis)。
-
文本到图像生成:使用GenEval数据集评估GPT-4o将文本描述转换为图像的能力。该任务要求模型准确理解文本中的语义信息,并生成与之对应的高质量图像。
-
基于指令的图像编辑:通过Reason-Edit数据集评估GPT-4o根据用户指令对图像进行编辑的能力。该任务要求模型精确理解指令的意图,并对图像进行相应的修改,同时保持非编辑区域的一致性。
-
世界知识信息语义合成:利用WISE数据集评估GPT-4o在生成图像时融入世界知识的能力。该任务要求模型不仅理解文本描述,还能结合自身的世界知识生成具有丰富语义信息的图像。
模型架构推测
为了揭示GPT-4o的底层架构,本研究提出了一种基于分类模型的方法。具体步骤如下:
- 生成图像数据集:使用扩散模型和自动回归模型分别生成大量图像,作为训练分类模型的数据集。
- 训练分类模型:利用预训练的CLIP模型作为特征提取器,训练一个二分类器来区分由扩散模型和自动回归模型生成的图像。
- 测试GPT-4o生成的图像:将GPT-4o生成的图像输入到训练好的分类器中,根据其输出判断GPT-4o使用的图像解码头类型。
错误分析和案例研究
为了识别和分析GPT-4o的局限性,本研究对GPT-4o生成的图像进行了详细的错误分析和案例研究。具体方法包括:
- 错误分类:将GPT-4o生成的错误图像根据错误类型进行分类,如不一致性、高分辨率过细化限制、画笔工具限制等。
- 案例研究:选取具有代表性的错误案例进行深入分析,探讨错误产生的原因以及可能的改进方法。
多轮图像编辑比较
为了比较GPT-4o与其他先进图像编辑模型在多轮图像编辑任务上的性能,本研究选取了Gemini 2.0 Flash作为对比模型。具体方法如下:
- 设计多轮编辑任务:设计一系列需要多轮编辑的图像任务,如连续修改对象的颜色、形状等属性。
- 执行编辑操作:分别使用GPT-4o和Gemini 2.0 Flash对图像进行编辑,并记录每次编辑的结果。
- 性能评估:根据编辑结果的一致性、指令理解能力和多轮编辑交互支持等方面对两个模型进行比较评估。
安全性讨论
为了探讨GPT-4o输出的安全性,本研究使用现有图像取证模型对GPT-4o生成的图像进行了检测。具体方法如下:
- 选取图像取证模型:选取多个先进的图像取证模型,如Effort和FakeVLM等。
- 生成测试图像:使用GPT-4o生成一批测试图像,并确保这些图像具有代表性。
- 模型检测:将测试图像输入到选取的图像取证模型中,评估其对GPT-4o生成图像的检测能力。
研究结果
定量评估结果
-
文本到图像生成:在GenEval数据集上的评估结果显示,GPT-4o在整体得分、单个对象、两个对象、计数、颜色、位置和属性绑定等任务上均取得了显著优于其他方法的成绩。特别是在计数和颜色识别任务上,GPT-4o的得分分别达到了0.85和0.92。
-
基于指令的图像编辑:在Reason-Edit数据集上的评估结果显示,GPT-4o在指令遵循度和非编辑区域一致性等方面均表现出色,其GPT评分达到了0.929,显著优于其他先进的图像编辑模型。
-
世界知识信息语义合成:在WISE数据集上的评估结果显示,GPT-4o在整体WiScore以及文化、时间、空间、生物学、物理学和化学等子域上均取得了最高的得分,展示了其在世界知识信息语义合成方面的强大能力。
定性评估结果
通过定性分析GPT-4o生成的图像,研究发现GPT-4o能够准确理解文本描述中的语义信息,并生成与之对应的高质量图像。在基于指令的图像编辑任务中,GPT-4o能够精确理解指令的意图,并对图像进行相应的修改,同时保持非编辑区域的一致性。此外,GPT-4o在生成图像时还能够融入丰富的世界知识,生成具有复杂语义信息的图像。
模型架构推测结果
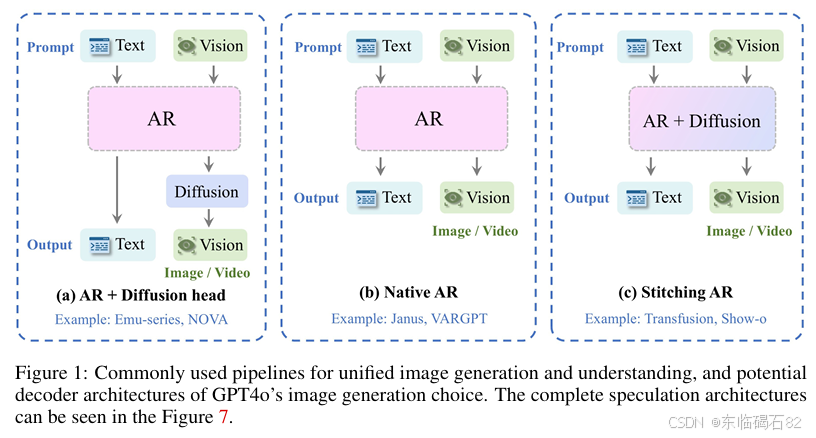
基于分类模型的实验结果表明,GPT-4o使用的图像解码头类型为基于扩散的解码头,而不是自动回归或VAR类架构。这一发现为理解GPT-4o的工作原理提供了重要线索。
错误分析和案例研究结果
通过错误分析和案例研究,研究发现GPT-4o在图像生成和编辑过程中存在一些局限性,如不一致性、高分辨率过细化限制、画笔工具限制等。这些局限性为未来模型的改进提供了指导。
多轮图像编辑比较结果
在多轮图像编辑任务上的比较结果显示,GPT-4o在指令理解能力、编辑一致性和多轮编辑交互支持等方面均优于Gemini 2.0 Flash。特别是在编辑一致性方面,GPT-4o在多轮编辑过程中能够更好地保持图像的一致性。
安全性讨论结果
安全性讨论结果表明,尽管GPT-4o生成的图像在视觉上与真实图像非常相似,但现有图像取证模型仍然能够检测到其中的伪影。这一发现为生成对抗网络和其他生成模型的安全性研究提供了参考。
研究局限
尽管本研究在评估GPT-4o的图像生成能力方面取得了显著成果,但仍存在一些局限性:
-
数据集限制:由于GPT-4o的发布时间较短,本研究使用的数据集可能无法全面覆盖GPT-4o的所有能力。未来需要收集更多样化的数据集来进一步评估GPT-4o的性能。
-
评估方法限制:本研究采用的评估方法主要基于定量和定性分析,可能无法完全揭示GPT-4o的所有局限性。未来需要探索更多元化的评估方法来全面诊断GPT-4o的性能。
-
模型架构推测限制:尽管本研究提出了一种基于分类模型的方法来推测GPT-4o的底层架构,但该方法仍存在一定的不确定性。未来需要收集更多关于GPT-4o内部机制的信息来进一步验证推测结果。
-
安全性讨论限制:本研究仅探讨了GPT-4o生成的图像在现有图像取证模型下的可检测性,未涉及其他安全性问题。未来需要更全面地评估GPT-4o的安全性风险。
未来研究方向
基于本研究的结果和局限性,未来可以在以下几个方面展开进一步研究:
-
扩展数据集:收集更多样化的数据集来全面评估GPT-4o的图像生成能力,特别是针对复杂场景和长文本描述的评估。
-
改进评估方法:探索更多元化的评估方法来全面诊断GPT-4o的性能,如用户研究、对抗性测试等。
-
深入研究模型架构:进一步收集关于GPT-4o内部机制的信息来验证推测结果,并探索其他可能的模型架构。
-
加强安全性研究:更全面地评估GPT-4o的安全性风险,特别是针对恶意使用和隐私泄露等方面的研究。
-
推动技术创新:基于GPT-4o的评估结果和局限性,推动图像生成和编辑技术的创新和发展,提高生成图像的质量和多样性。
综上所述,本研究通过提出GPT-ImgEval基准测试框架,对GPT-4o在图像生成方面的能力进行了全面评估。未来需要在数据集、评估方法、模型架构和安全性等方面展开进一步研究,以推动图像生成和编辑技术的持续发展。






![[ctfshow web入门] web4](https://i-blog.csdnimg.cn/direct/59f50dae2a7446419257ae805ac5bd25.png)