本学习内容总结于莫烦python:5.正则表达式
https://mofanpy.com/tutorials/python-basic/interactive-python/regex
5.正则表达式
本章较为重要,单独拿出来成章了
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 比如我要批量修改很多文件中出现某种固定模式的文字时。
re 模块使 Python 语言拥有全部的正则表达式功能
5.1 不用正则判断
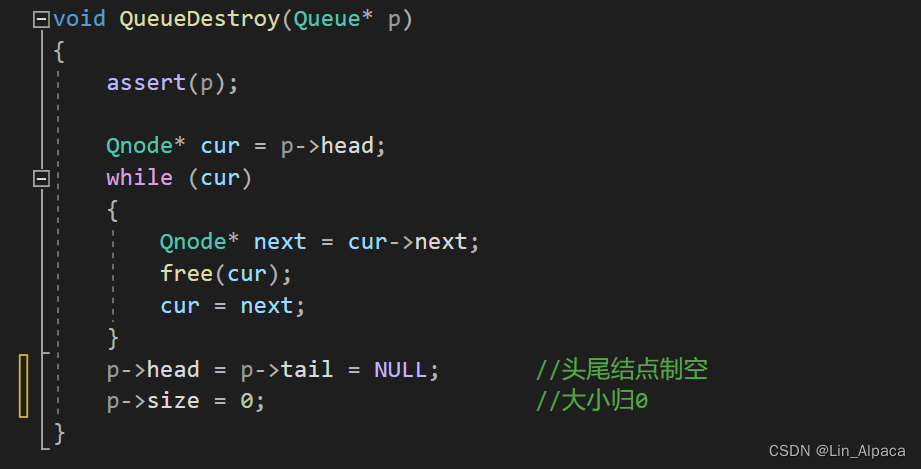
pattern1 = "file"
pattern2 = "files"
string = "the file is in the folder"
print("file in string", pattern1 in string)
print("files in string", pattern2 in string)
file in string True
files in string False
做了一个判断,看有没有包含这个词。不过种类变多了之后,总写这样的判断,处理的能力是十分有限的。
正则的方法:
① 方法一:规则用命名=re.compile(r);用命名.search("")比较
import re
# 命名=re.compile(r)
ptn = re.compile(r"\w+?@\w+?\.com")
#`命名.search()
matched = ptn.search("mofan@mofanpy.com")
print("mofan@mofanpy.com is a valid email:", matched)
matched = ptn.search("mofan@mofanpy+com")
print("mofan@mofanpy+com is a valid email:", matched)
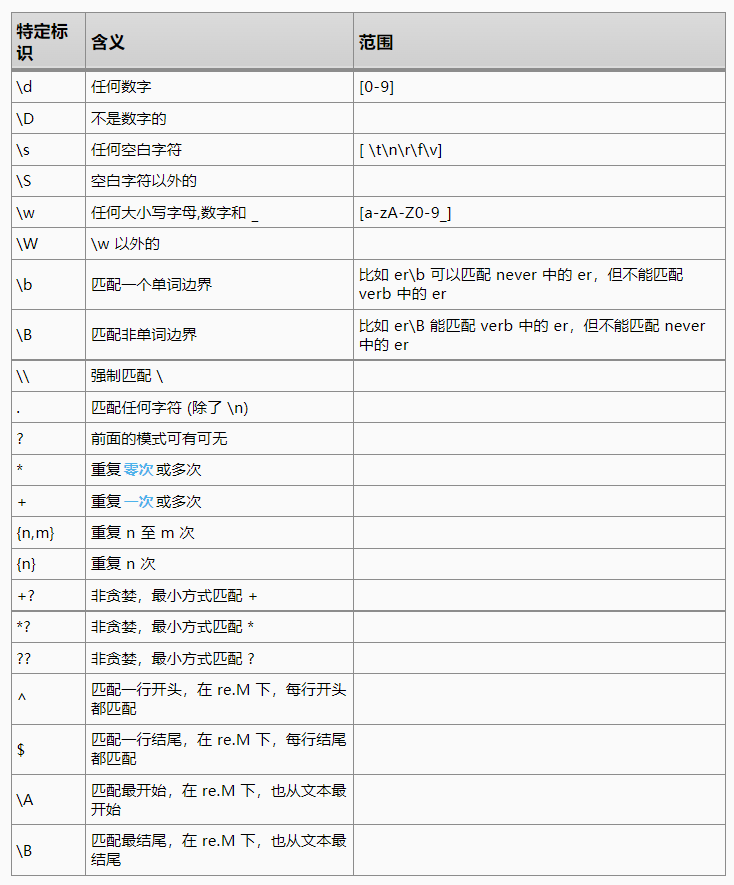
\w:匹配所有字母数字,等同于 [a-zA-Z0-9_]
+:+号之前的字符出现 >=1 次
?: 在符号前面的字符为可选,即出现 0 或 1 次
+?:则是惰性匹配,不加是尽可能多的配,先尽可能少的配,这里: \w 至少匹配 1 次
现在有个字符串
adsabopbc
- 正则是
a.+b,这种情况下这个正则表达式能匹配的就是adsabopb,因为中间的.+会保证在尽量能匹配成功的前提下尽量的多匹配字符;- 正则是
a.+?b,那么匹配的结果就是adsab了,因为他会保证在尽量能匹配的成功的情况下少的匹配字符。
我都是用 r"xxx" 来写一个 pattern:因为正则表达式很多时候都要包含\,r 代表原生字符串, 使用 r 开头的字符串是为了不让你混淆 pattern 字符串中到底要写几个 \,你只要当成一个规则来记住在写 pattern 的时候,都写上一个 r 在前面就好了。
mofan@mofanpy.com is a valid email: <re.Match object; span=(0, 17), match='mofan@mofanpy.com'>
mofan@mofanpy+com is a valid email: None
re.Match object这个意思应该是匹配了 ,匹配的范围是[0,17),匹配内容是:mofan@mofanpy.com
没匹配 返回没有None
- 方法二:
re.search(r"规则","对象")
matched = re.search(r"\w+?@\w+?\.com", "the email is mofan@mofanpy.com.")
print("the email is mofan@mofanpy.com:", matched)
the email is mofan@mofanpy.com: <re.Match object; span=(13, 30), match='mofan@mofanpy.com'>
5.2 正则给额外信息
- 提出匹配的内容
match.group()
match = re.search(r"\w+?@\w+?\.com", "the email is mofan@mofanpy.com.")
print(match)
print(match.group())
<re.Match object; span=(13, 30), match='mofan@mofanpy.com'>
mofan@mofanpy.com
【此处内容看视频】:https://www.bilibili.com/video/BV1ef4y1U7V4/
|:或 字符串[au]:相当于字母间的a|u
re.search(r"ran|run", "I run to you") # match='run'
re.search(r"ra|un", "I run to you") # match='un'
re.search(r"r[au]n", "I run to you") # match='run'
(|):多字符串匹配
print(re.search(r"f(ou|i)nd", "I find you"))
print(re.search(r"f(ou|i)nd", "I found you"))
<re.Match object; span=(2, 6), match='find'>
<re.Match object; span=(2, 7), match='found'>
5.3 按类型匹配
https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md#232–%E5%8F%B7
5.4 中文
和英文一样用
print(re.search(r"不?爱", "我爱你"))
print(re.search(r"不?爱", "我不爱你"))
print(re.search(r"不.*?爱", "我不是很爱你"))
<re.Match object; span=(1, 2), match='爱'>
<re.Match object; span=(1, 3), match='不爱'>
<re.Match object; span=(1, 5), match='不是很爱'>
5.5 查找替换等更多功能

print("search:", re.search(r"run", "I run to you"))
print("match:", re.match(r"run", "I run to you"))
print("findall:", re.findall(r"r[ua]n", "I run to you. you ran to him"))
for i in re.finditer(r"r[ua]n", "I run to you. you ran to him"):
print("finditer:", i)
print("split:", re.split(r"r[ua]n", "I run to you. you ran to him"))
print("sub:", re.sub(r"r[ua]n", "jump", "I run to you. you ran to him"))
print("subn:", re.subn(r"r[ua]n", "jump", "I run to you. you ran to him"))
search: <re.Match object; span=(2, 5), match='run'>
match: None
findall: ['run', 'ran']
finditer: <re.Match object; span=(2, 5), match='run'>
finditer: <re.Match object; span=(18, 21), match='ran'>
split: ['I ', ' to you. you ', ' to him']
sub: I jump to you. you jump to him
subn: ('I jump to you. you jump to him', 2)
5.6 在模式中获取特定信息
5.6.1 获取单一信息
想要提取出匹配模式当中的一些字段,而不是全字段。举个例子, 我的文件名千奇百怪,我就想找到 *.jpg 图片文件,而且只返回给我去掉 .jpg 之后的纯文件名。
found = []
for i in re.finditer(r"[\w-]+?\.jpg", "I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"):
found.append(re.sub(r".jpg", "", i.group()))
print(found)
['2021-02-01', '2021-02-02', '2021-02-03']
[\w-]要么是数字字母,要么是-,二者选一;至少一个re.sub(r"规则",“替换的内容”,“查找的语句”):这里规则就是.jpg,用空替换,那么i.group()提取出来"I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"中符合[\w-]+?\.jpg·规则的
上面这种做法虽然可行,但是还不够简单利索,因为同时用到了两个功能 finditer 和 sub.改进:
string = "I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"
print("without ():", re.findall(r"[\w-]+?\.jpg", string))
print("with ():", re.findall(r"([\w-]+?)\.jpg", string))
without (): ['2021-02-01.jpg', '2021-02-02.jpg', '2021-02-03.jpg']
with (): ['2021-02-01', '2021-02-02', '2021-02-03']
re.findall:返回不重复。且符合规则的列表- 加入一个
():选定要截取返回的位置, 他就直接返回括号里的内容
5.6.2 获取多个信息
- 方法一:
re.finditer():去的还是字符串结构:"(\d+?)-(\d+?)-(\d+?)\.jpg"因为用了(),规则就知道group分别指的什么了
string = "I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"
match = re.finditer(r"(\d+?)-(\d+?)-(\d+?)\.jpg", string)
for file in match:
print("matched string:", file.group(0), ",year:", file.group(1), ", month:", file.group(2), ", day:", file.group(3))
matched string: 2021-02-01.jpg ,year: 2021 , month: 02 , day: 01
matched string: 2021-02-02.jpg ,year: 2021 , month: 02 , day: 02
matched string: 2021-02-03.jpg ,year: 2021 , month: 02 , day: 03
- 方法二:
re.findall()去的直接是个列表,所以用【】
string = "I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"
match = re.findall(r"(\d+?)-(\d+?)-(\d+?)\.jpg", string)
for file in match:
print("year:", file[0], ", month:", file[1], ", day:", file[2])
- 变形,更便于编程:
?P<索引名>来进行对group标号
string = "I have 2021-02-01.jpg, 2021-02-02.jpg, 2021-02-03.jpg"
match = re.finditer(r"(?P<y>\d+?)-(?P<m>\d+?)-(?P<d>\d+?)\.jpg", string)
for file in match:
print("matched string:", file.group(0),
", year:", file.group("y"),
", month:", file.group("m"),
", day:", file.group("d"))
5.7 多模式匹配
讲解了两个:大小写和分行的处理
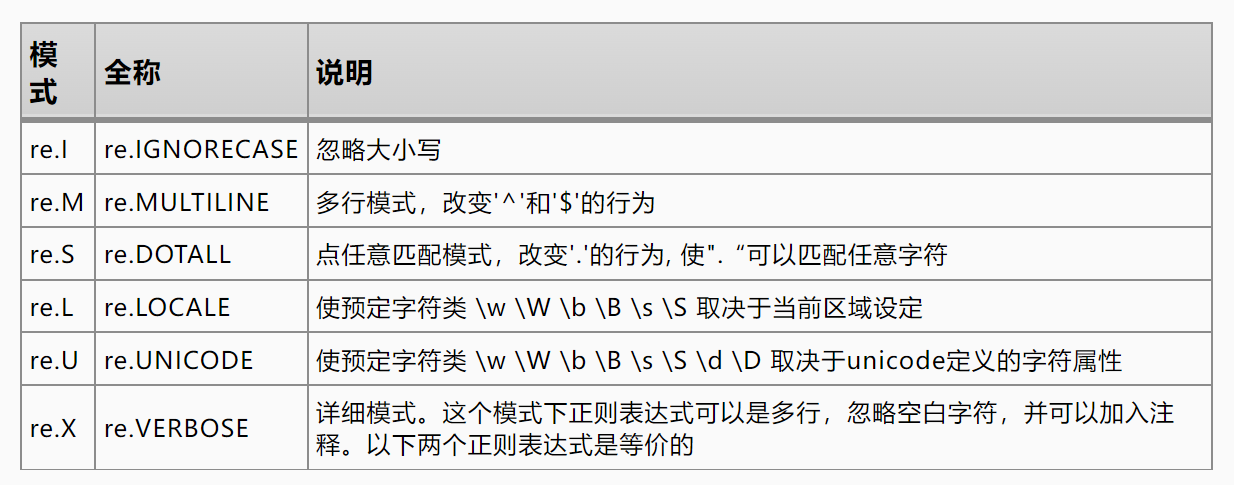
以上都是用flag=
re.I忽略大小写的例子
ptn, string = r"r[ua]n", "I Ran to you"
print("without re.I:", re.search(ptn, string))
print("with re.I:", re.search(ptn, string, flags=re.I))
without re.I: None
with re.I: <re.Match object; span=(2, 5), match='Ran'>
flags=re.I 用上这个就忽略了大小写
- 多行匹配:
re.M
ptn = r"^ran"
string = """I
ran to you"""
print("without re.M:", re.search(ptn, string))
print("with re.M:", re.search(ptn, string, flags=re.M))
print("with re.M and match:", re.match(ptn, string, flags=re.M))
without re.M: None
with re.M: <re.Match object; span=(2, 5), match='ran'>
with re.M and match: None
re.match() 是不管你有没有 re.M flag,我的匹配都是按照最头头上开始匹配的。 所以上面的实验中,re.match() 匹配不到任何东西。
第二个我们想在每行文字的开头匹配特定字符,如果用 ^ran 固定样式开头,匹配不到第二行的 ran to you 的,所以我们得加上一个 re.M flag
- 想同时用
re.M, re.I
ptn = r"^ran"
string = """I
Ran to you"""
print("with re.M and re.I:", re.search(ptn, string, flags=re.M|re.I))
with re.M and re.I: <re.Match object; span=(2, 5), match='Ran'>
- 还有一种写法可以直接在 ptn 里面定义这些 flags
string = """I
Ran to you"""
re.search(r"(?im)^ran", string)
<re.Match object; span=(2, 5), match='Ran'>
flags: (?im) 这就是说要用· re.I, re.M。
5.8 更快地执行
如果你要重复判断一个正则表达式.,5.1 的方法1 效率高于 方法2
import time
n = 1000000
# 不提前 compile
t0 = time.time()
for _ in range(n):
re.search(r"ran", "I ran to you")
t1 = time.time()
print("不提前 compile 运行时间:", t1-t0)
# 先做 compile
ptn = re.compile(r"ran")
for _ in range(n):
ptn.search("I ran to you")
print("提前 compile 运行时间:", time.time()-t1)
不提前 compile 运行时间: 1.9030001163482666
提前 compile 运行时间: 0.42299962043762207