前言
栈和队列都是重要的线性结构,即在使用层面上收到限制而发挥特殊作用的线性表。掌握这两种结构在不同情景下亦会发挥重要作用。
栈
定义
栈保持着后进先出的原则,正因如此在插入数据的时候要求只能从一段插入,称为栈顶;相反另一端就被称为栈底。而插入数据叫做进栈,删除数据叫做出栈,并且都只能在栈顶进行操作。

了解了栈的定义,现在就应着手于如何实现。应考虑清楚根据其性质我们要构造出一个怎样的结构来实现栈。
我们需要在一端插入或删除数据并及时对其访问,因此我们这里使用动态顺序表来实现。在这个结构中 top 由于初始值设定为 0 所以代表的是栈顶下一位的下标,也可以设置为-1,则代表的是栈顶的下标。使用capacity是为了时刻检测内存的大小便于及时开辟。

实现
这次要实现的就是下面几个函数,对应了该数据结构时经常使用的操作。

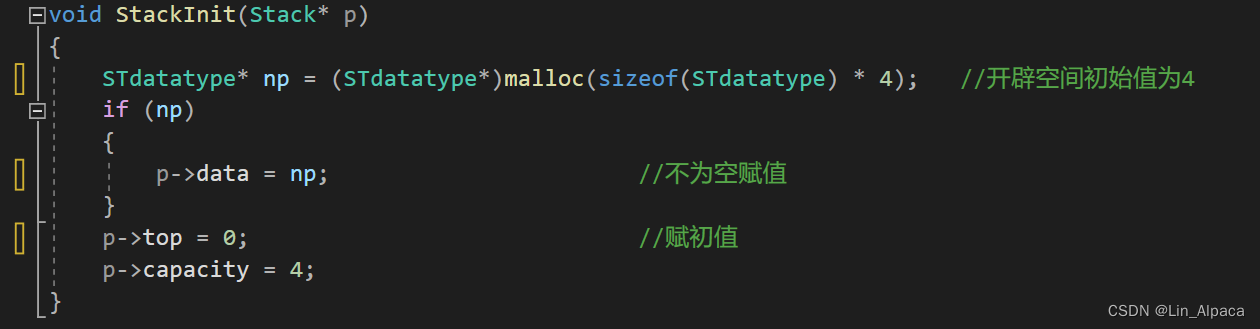
初始化
首先为内部储存的数据开辟一段空间,(这里我设置的初始值是4根据需要可以进行调整),开辟成功后,用结构体内的指针指向这片空间,同时为 top 与 capacity 赋上初始值。这样便完成了栈的初始化。
增删查改
入栈
一切开始前首先应该判断传入的指针是否为空指针,避免出现对空指针解引用的情况。后判断这个空间是否已满,不然增大空间的容量。之前说过 top 指向的是栈顶的下一位,因此直接赋值后再对 top ++ 就可以了。

这里对容量的判定是分解到另一个函数内去的,其实直接写这个函数里面也是可以的毕竟只有这里需要判断容量是否满了。
从下标的角度上来说,top 是比栈顶多 1 的,由于下标的从 0 开始因此 top 正好可以表达此刻数据的数量。当 top 与 capacity 相等时,即开辟的空间已满。所以使用 realloc 调整新空间的大小(我把默认设为每次增加都是原来的两倍)。开辟成功后把新的地址给 data ,调整 capacity 为新容量的大小。

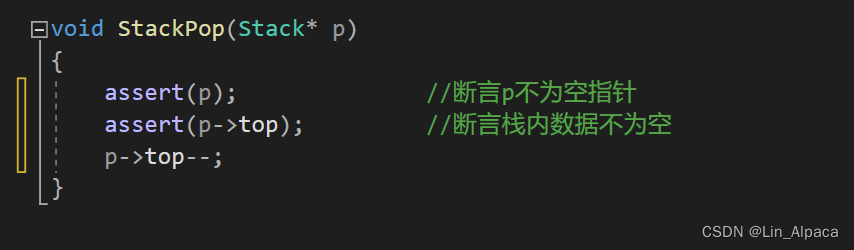
出栈
出栈的操作相当的简便,只要 top-- 这样未来访问的时候就不会再访问到,也没有必要再对其进行赋值,因为下次插入的时候就会用新值覆盖原来的值。但是断言还是要记得断言的。
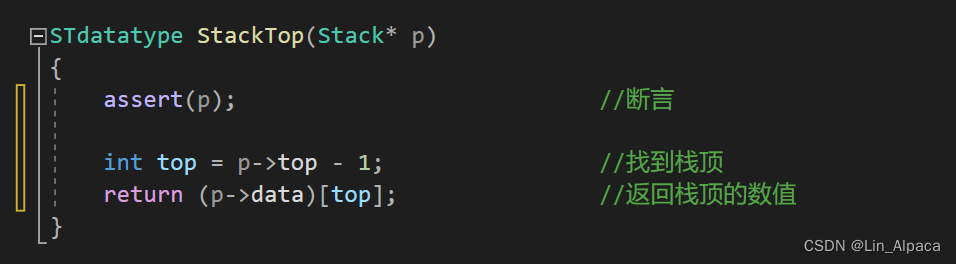
获取栈顶元素
这里我们通过top访问到栈顶的元素之后并将其返回,就完成了栈顶元素的获取。
判空
这里使用了 bool 值要引用头文件 stdboo.h ,前面讲到 top 在栈中的意义就相当于内置数据的数量,即 top 不等于 0 则栈里就是还有数据的,所以返回false。

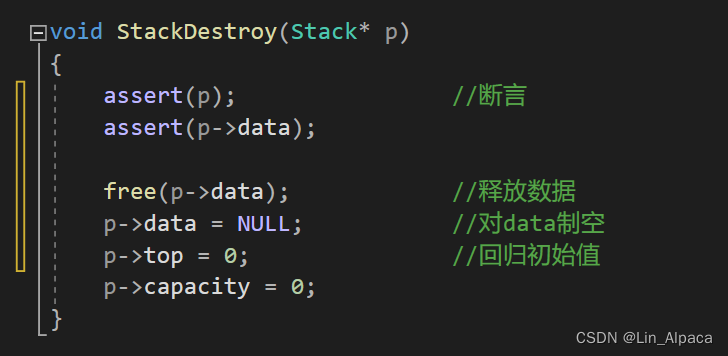
销毁
栈结束使用后,要进行销毁避免内存泄漏。断言后释放data 后再将top跟capacity赋值为初始值,由于前面没有对结构体进行动态开辟,所以这里就不用释放。
队列
定义
队列与栈相反,栈是先进后出,而队列是先进先出,即从队头入队(插入数据)到队尾出队(删除数据),这个规则无法改变。

实现
在这里关于结构的选择就不是双选题了,因为无论选左边还是右边作为队尾,数组总是逃不过需要挪动数据的结果。反观链表就显得相对自由。

但只使用链表结构也不够完善,对于链表来说最痛苦的莫非是尾结点的访问了,但这里要频繁地对尾节点进行访问,不妨再使用一个结构体存储头尾结点,来表示一整个队列。这样处理后,若我们要对头结点进行更改也不需要使用到二级指针了,因为只是对结构体内的数据进行更改因此只需要结构体指针。为了统计大小更加方便也需要一个 size 表示大小。

如下为要实现的函数。

初始化
一开始的队列本为空,只需要将头尾结点制空, size 归零。就完成了插入数据前的准备。

为空的判定
为空的判定就相对简单,头尾结点正常情况下是同时为空的,也为了避免特殊情况即二者其中一个为空就可以判断整个队列是空的。

增删查改
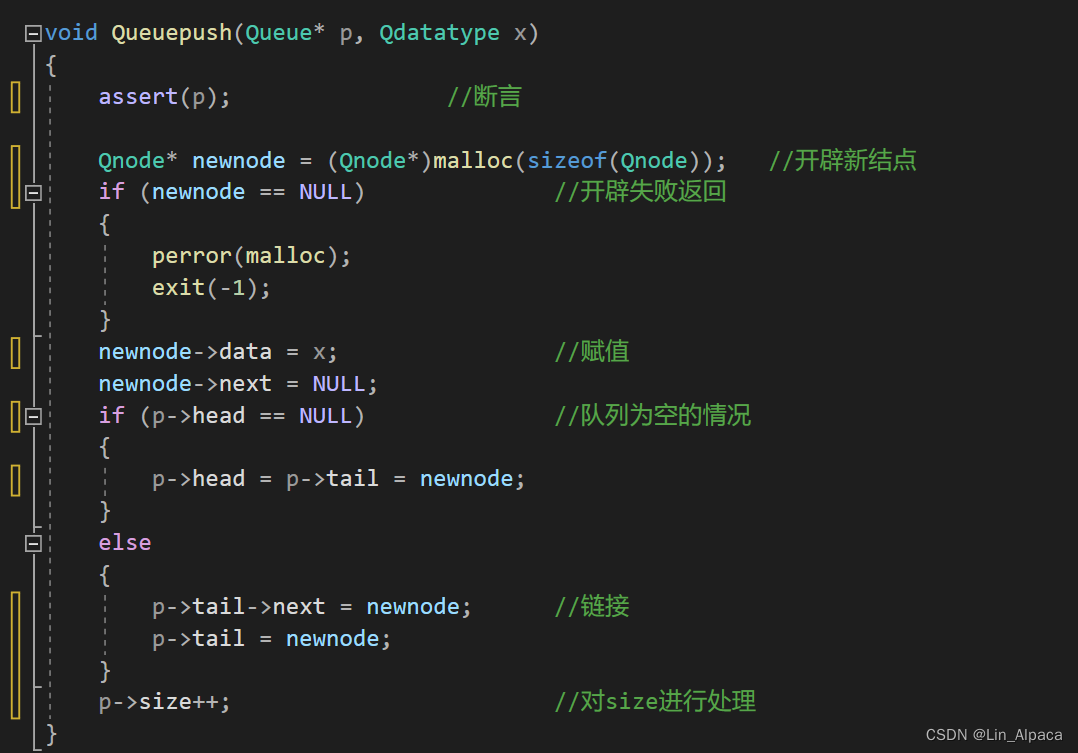
入队
传入数值前先断言(养成好习惯),之后像链表那样开辟一个新节点并对其赋值。之后就要面临一个分岔口,队列是否为空,贸然地对头结点解引用就会出现错误,若为空则新节点就变成头结点,非空就链接在尾结点后,这之后自身成为尾结点。
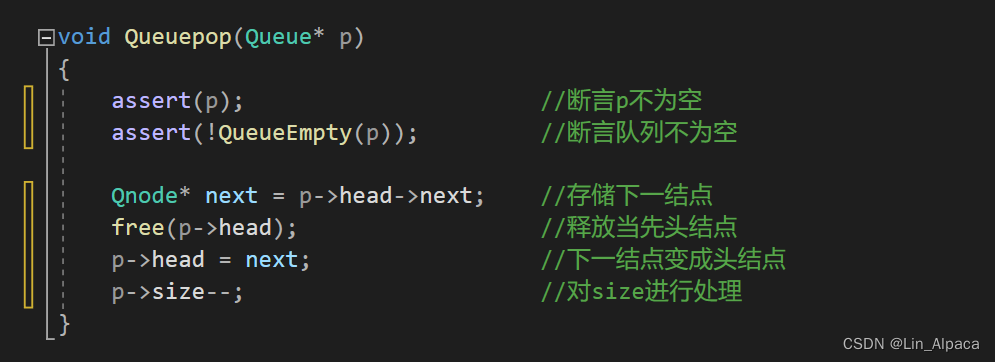
出队
断言后出队需要做到的是:事先将下一结点保存起来,不然当前头结点释放后便无法访问到下一结点了。之后释放头结点,下一结点就变成了头结点,同时 size-- ,保证空间数量的准确避免越界访问。
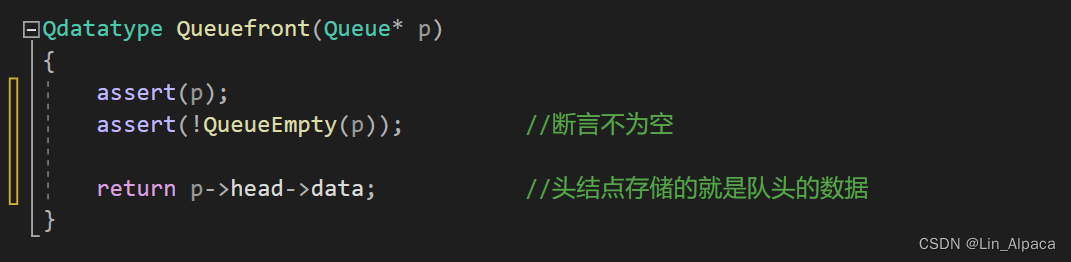
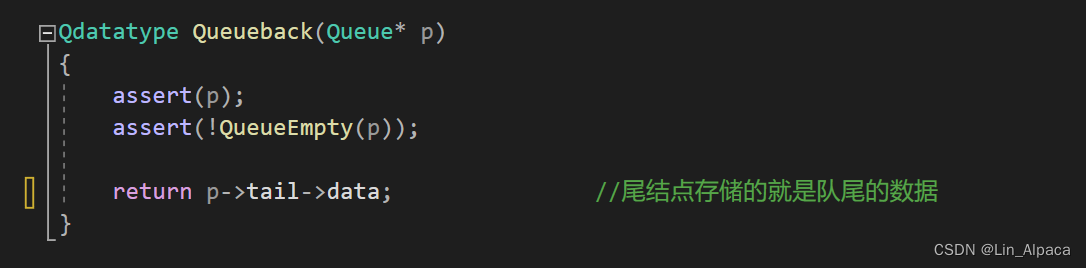
访问队头队尾
直接访问头(尾)结点便是队头(尾)。
求大小
这里需要感谢我们在前面在结构内就存储了大小,不然还需要遍历链表才能得到队列的大小。

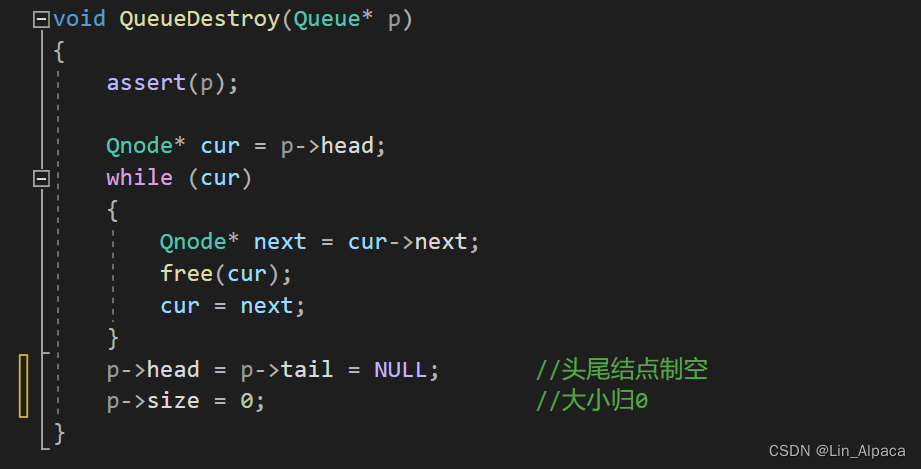
队列的销毁
同样有 malloc 就有 free ,在这里我们每个结点都是动态开辟出来的,所以都需要释放。就像链表释放那样,一边遍历一边释放。最后再把队列的结构体初始化就完成了。
好了,这次栈和队列的实现到这里就告一段落了。后面是这次的源码
源码
stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int STdatatype;
typedef struct Stack
{
STdatatype* data;
int top;
int capacity;
}Stack;
//初始化
void StackInit(Stack* p);
//入栈
void StackPush(Stack* p, STdatatype data);
//依次出栈打印
void Stackprint(Stack* p);
//出栈
void StackPop(Stack* p);
//获取顶端元素
STdatatype StackTop(Stack* p);
//有效数据的个数
int StackSize(Stack* p);
//检测栈是否为空,不为空则返回0
bool StackEmpty(Stack* p);
//销毁栈
void StackDestroy(Stack* p);stack.c
#include"stack.h"
void checkcapacity(Stack* p)
{
STdatatype* newp;
if (p->top == p->capacity)
{
newp = (STdatatype*)realloc(p->data, sizeof(Stack) * p->capacity * 2);
if (newp == NULL) //开辟失败返回
{
perror(realloc);
exit(-1);
}
p->data = newp; //把新开辟的空间给data
p->capacity *= 2; //调整capacity为新值
}
}
void StackInit(Stack* p)
{
STdatatype* np = (STdatatype*)malloc(sizeof(STdatatype) * 4); //开辟空间初始值为4
if (np)
{
p->data = np; //不为空赋值
}
p->top = 0; //赋初值
p->capacity = 4;
}
void StackPush(Stack* p, STdatatype x)
{
assert(p); //断言不为空
checkcapacity(p); //判断空间是否满了
(p->data)[p->top] = x; //赋值
p->top++;
}
void Stackprint(Stack* p)
{
int i = p->top - 1;
while (i >= 0)
{
printf("%d ", (p->data)[i--]);
}
printf("\n");
}
void StackPop(Stack* p)
{
assert(p); //断言p不为空指针
assert(p->top); //断言栈内数据不为空
p->top--;
}
STdatatype StackTop(Stack* p)
{
assert(p); //断言
int top = p->top - 1; //找到栈顶
return (p->data)[top]; //返回栈顶的数值
}
bool StackEmpty(Stack* p)
{
assert(p);
if (p->top != 0)
{
return false;
}
return true;
}
void StackDestroy(Stack* p)
{
assert(p); //断言
assert(p->data);
free(p->data); //释放数据
p->data = NULL; //对data制空
p->top = 0; //回归初始值
p->capacity = 0;
}queue.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
typedef int Qdatatype;
typedef struct Qnode
{
Qdatatype data; //数据
struct Queue* next; //指向下个结点
}Qnode;
typedef struct Queue
{
Qnode* head; //队列的头
Qnode* tail; //队列的尾
int size; //大小
}Queue;
void Queueinit(Queue* p); //初始化
void Queuepush(Queue* p, Qdatatype x); //入队
void Queuepop(Queue* p); //出队
bool QueueEmpty(Queue* p); //检测为空
Qdatatype Queuefront(Queue* p); //访问队头的数据
Qdatatype Queueback(Queue* p); //访问队尾的数据
int Queuesize(Queue* p); //求队列的大小queue.c
#include "queue.h"
void Queueinit(Queue* p)
{
p->head = NULL; //头尾结点制空
p->tail = NULL;
p->size = 0; //数据量为0
}
bool QueueEmpty(Queue* p)
{
assert(p);
return p->head == NULL || p->tail == NULL; //二者一个为空则队列为空
}
void Queuepush(Queue* p, Qdatatype x)
{
assert(p); //断言
Qnode* newnode = (Qnode*)malloc(sizeof(Qnode)); //开辟新结点
if (newnode == NULL) //开辟失败返回
{
perror(malloc);
exit(-1);
}
newnode->data = x; //赋值
newnode->next = NULL;
if (p->head == NULL) //队列为空的情况
{
p->head = p->tail = newnode;
}
else
{
p->tail->next = newnode; //链接
p->tail = newnode;
}
p->size++; //对size进行处理
}
void Queuepop(Queue* p)
{
assert(p); //断言p不为空
assert(!QueueEmpty(p)); //断言队列不为空
Qnode* next = p->head->next; //存储下一结点
free(p->head); //释放当先头结点
p->head = next; //下一结点变成头结点
p->size--; //对size进行处理
}
Qdatatype Queuefront(Queue* p)
{
assert(p);
assert(!QueueEmpty(p)); //断言不为空
return p->head->data; //头结点存储的就是队头的数据
}
void QueueDestroy(Queue* p)
{
assert(p);
Qnode* cur = p->head;
while (cur)
{
Qnode* next = cur->next;
free(cur);
cur = next;
}
p->head = p->tail = NULL; //头尾结点制空
p->size = 0; //大小归0
}
Qdatatype Queueback(Queue* p)
{
assert(p);
assert(!QueueEmpty(p));
return p->tail->data; //尾结点存储的就是队尾的数据
}
int Queuesize(Queue* p)
{
assert(p);
return p->size;
}