Stable Video Diffusion(SVD)安装和测试
官网
- github | https://github.com/Stability-AI/generative-models
- Hugging Face | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- Paper | https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
准备工作
我的系统环境
- 内存 64G
- 显存3090,24G显存
下载
git clone https://github.com/Stability-AI/generative-models
cd generative-models
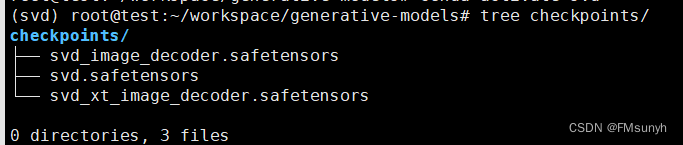
下载模型
- SVD | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
模型有4个,任意一个都可以使用,存放目录:
generative-models/checkpoints/
python环境配置
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .
运行
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 7862
启动时,还会下载两个模型,可以手动去下载,放到以下目录:
- /root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
- /root/.cache/clip/ViT-L-14.pt
如果报错
from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'
添加环境变量
RUN echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
source /root/.bashrc
再次启动

Okay, 没有问题了
测试
访问: 0.0.0.0:7862, 页面可以正常打开了。
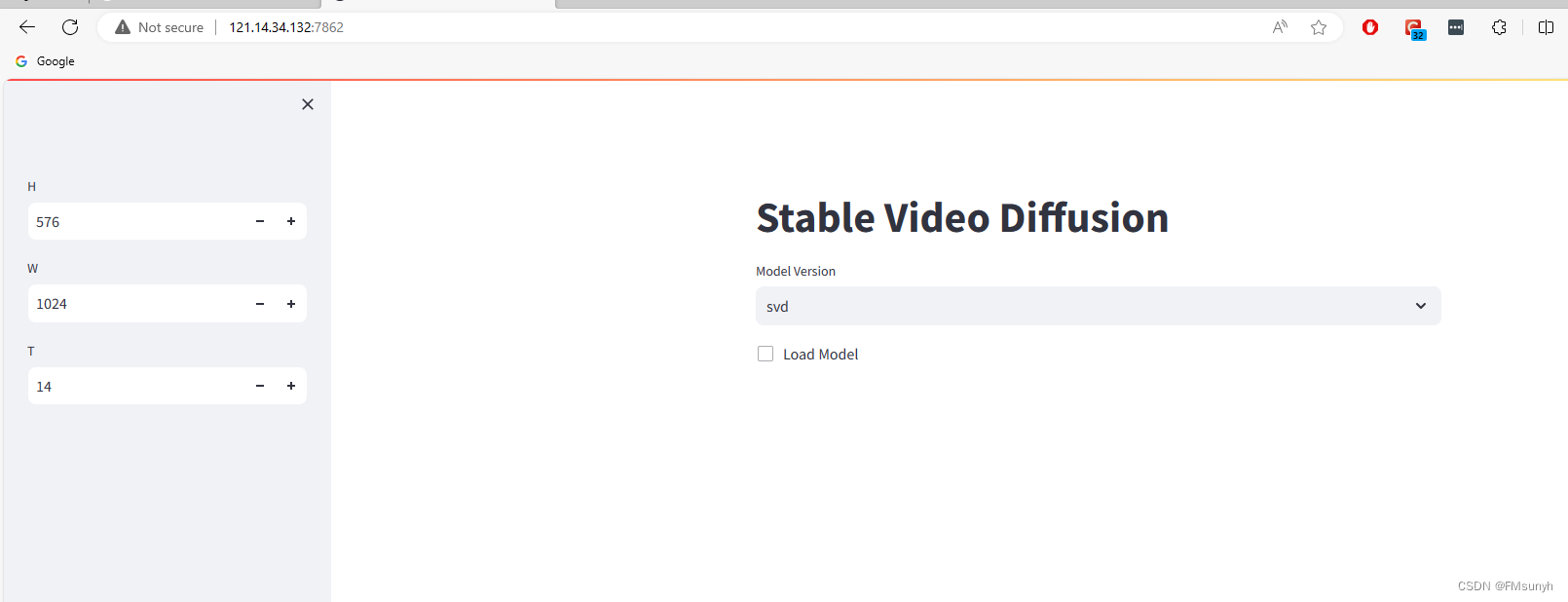
开始操作,选择模型版本,然后打钩,速度看机器配置,在我们的电脑需要2-3分钟。
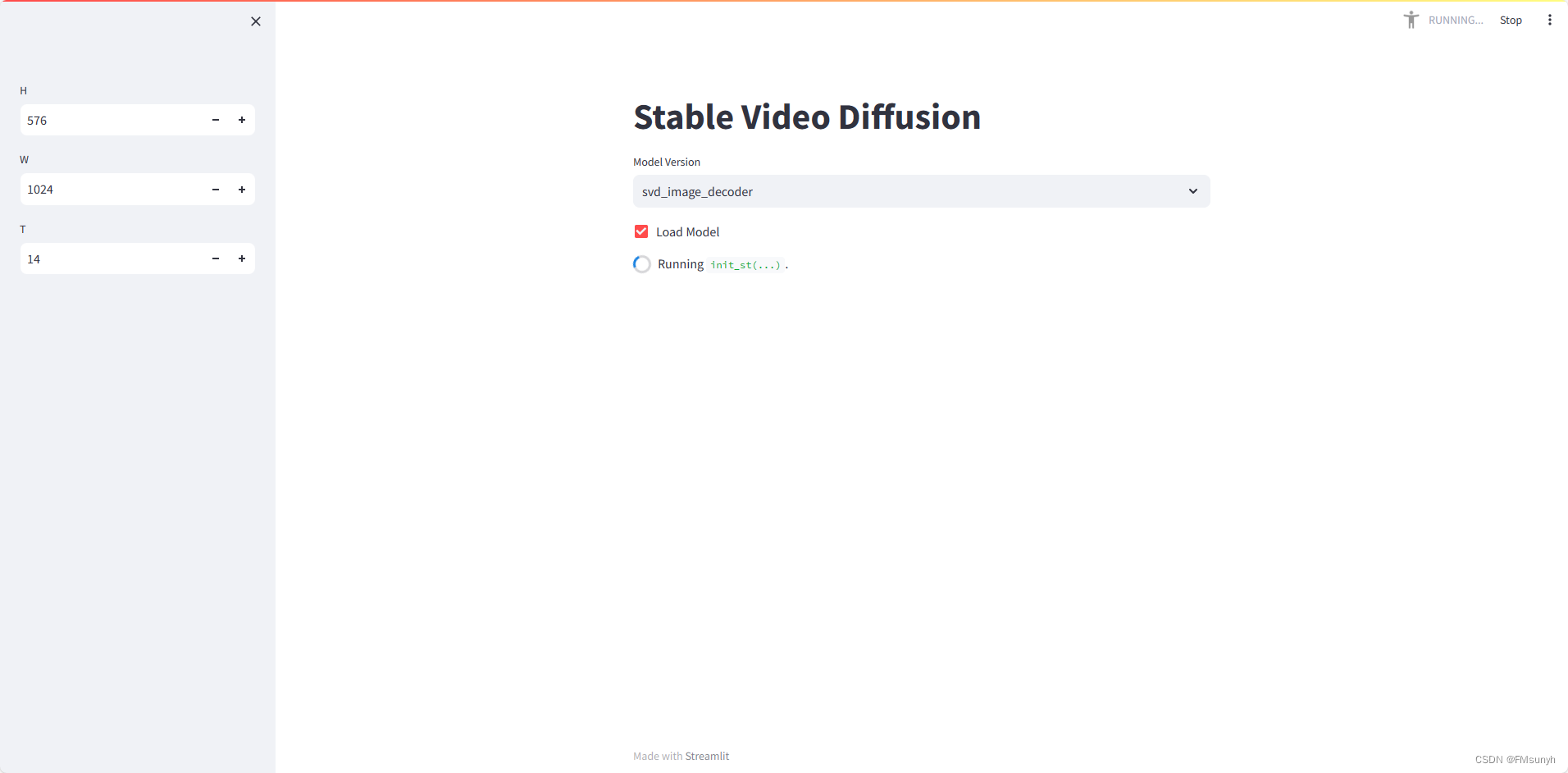
查看一下后台的情况
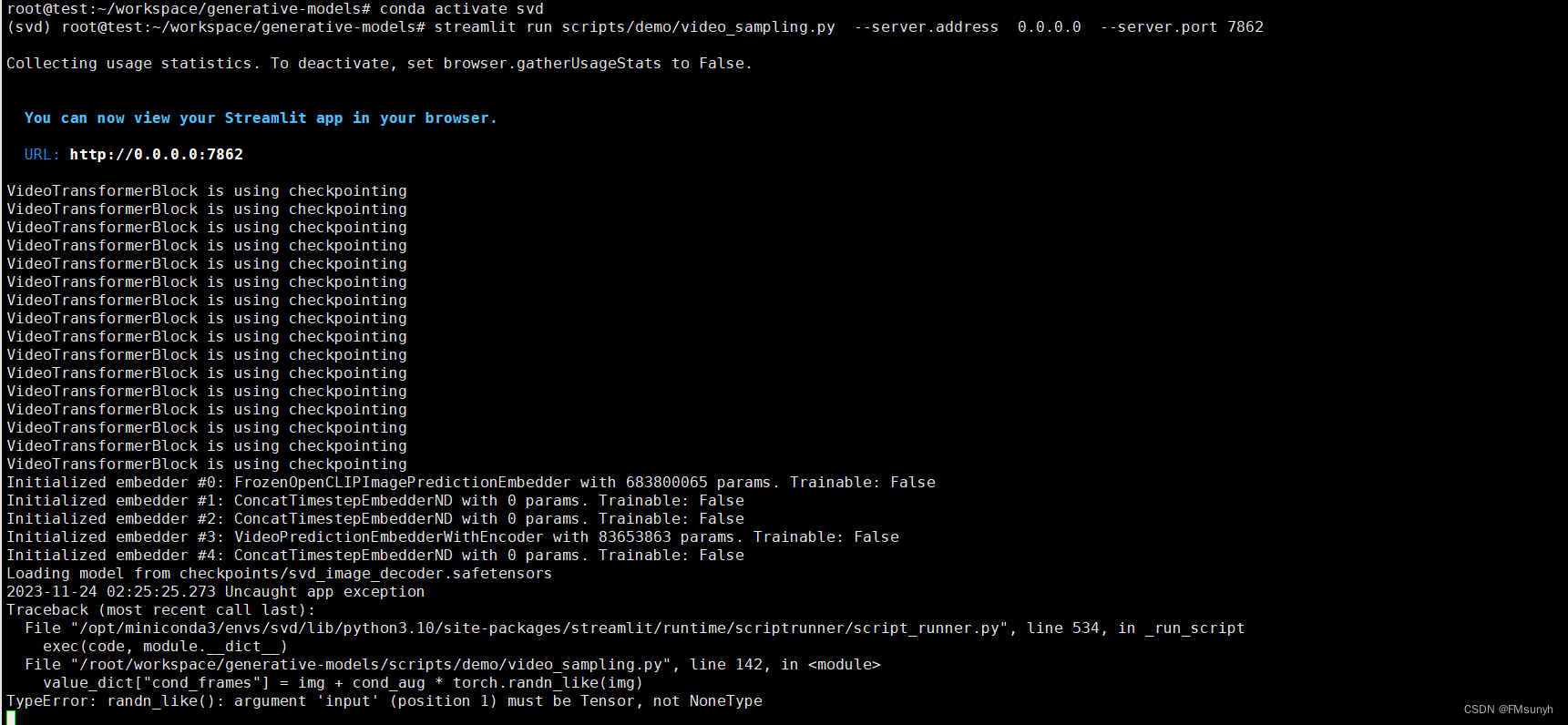
报错
File "/opt/miniconda3/envs/svd/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.__dict__)
File "/root/workspace/generative-models/scripts/demo/video_sampling.py", line 142, in <module>
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_like(): argument 'input' (position 1) must be Tensor, not NoneType
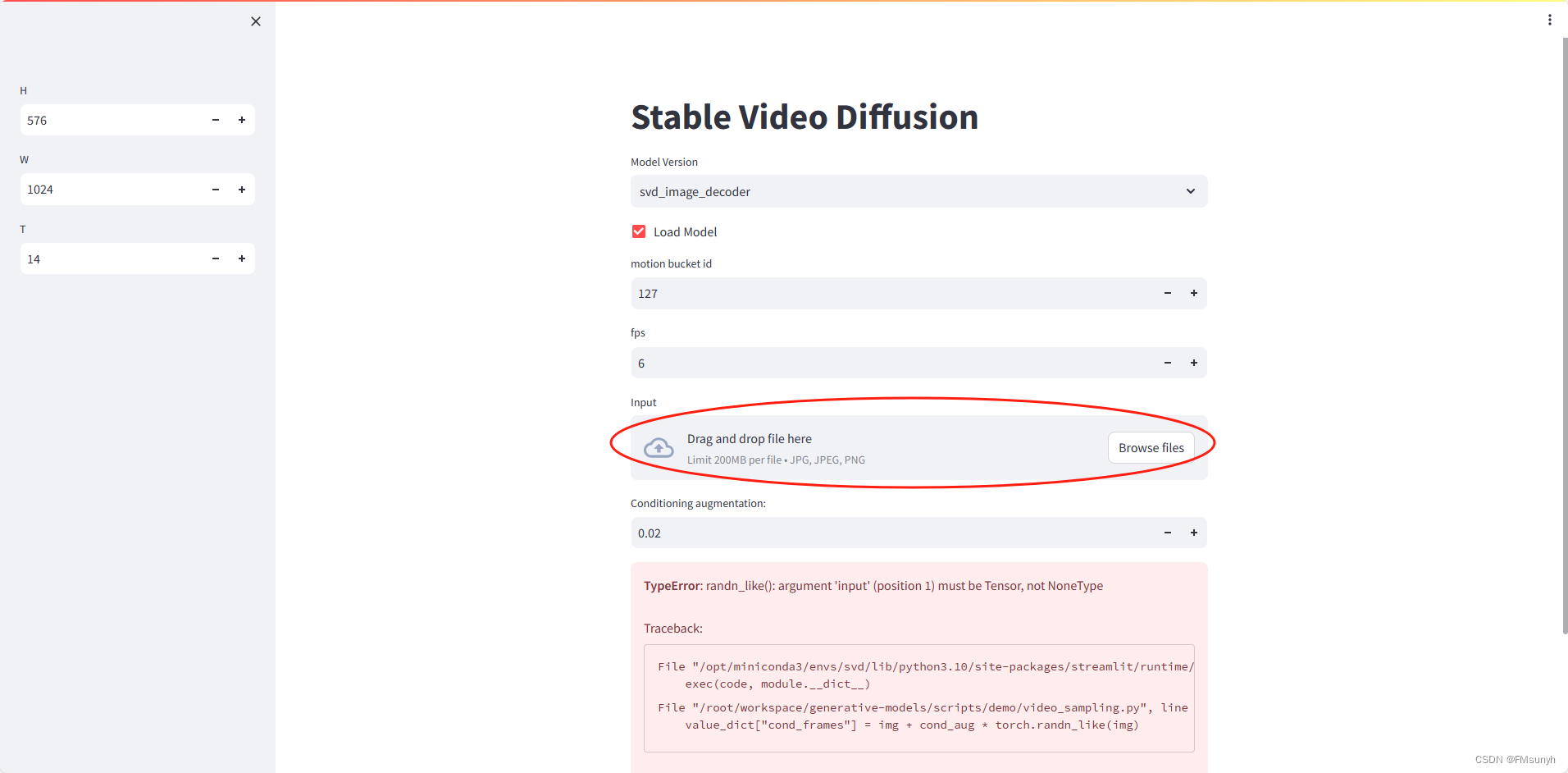
这是因为我们没有选择图片的缘故,上传图片

我们用官方提供的图片,先做测试
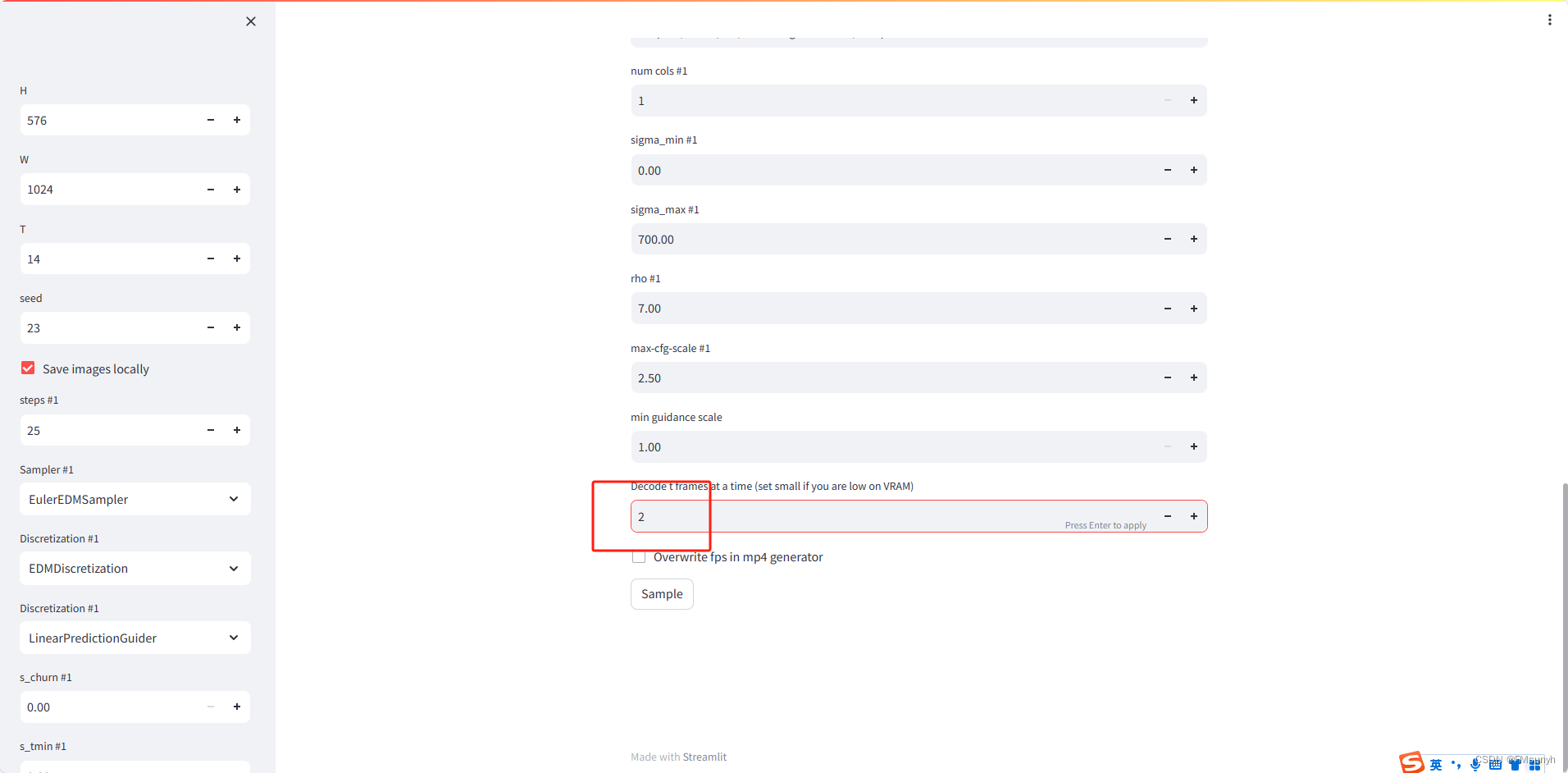
红色框的帧数改为 2,太大了,容易报显存错误,其他参数保持不变。点击 ‘Sample’,然后看一下后台
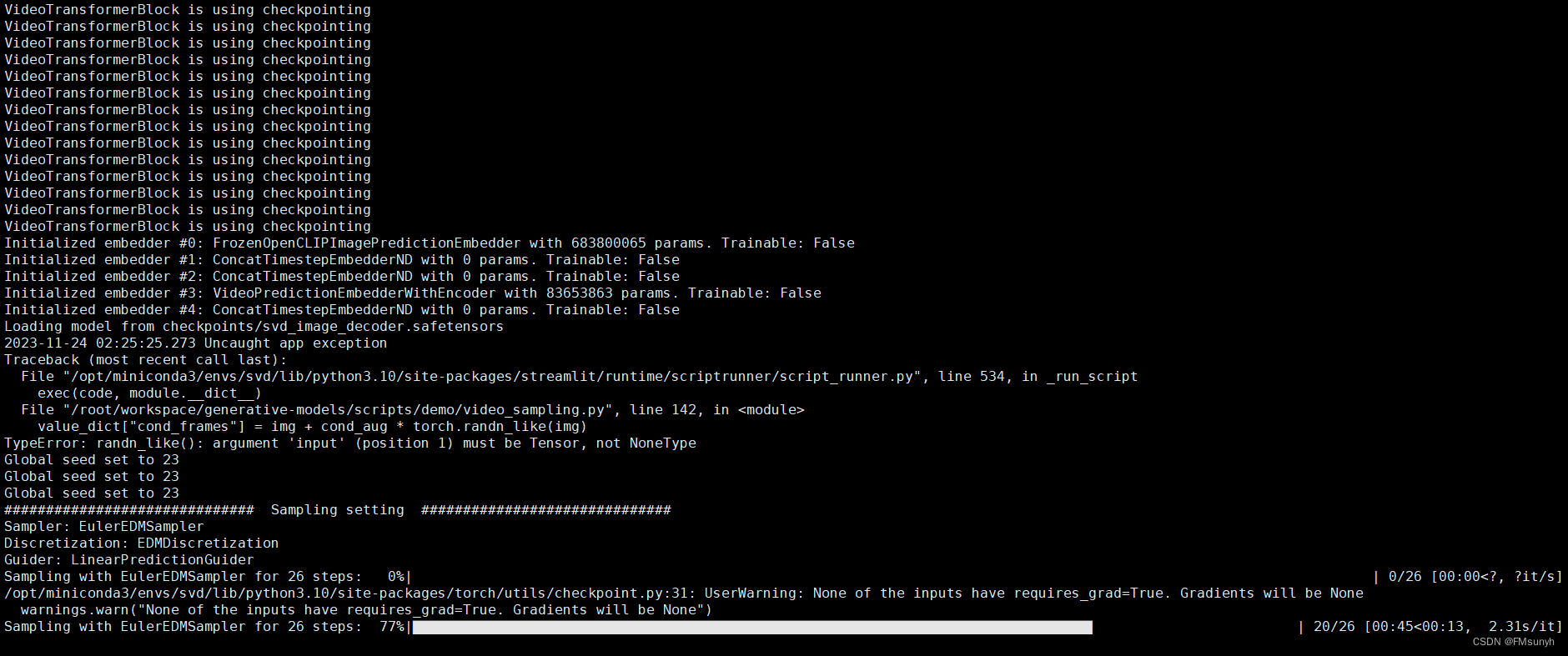
Okay,处理完之后,可以看一下视频,视频保存在:
generative-models/outputs/demo/vid/svd_image_decoder/samples
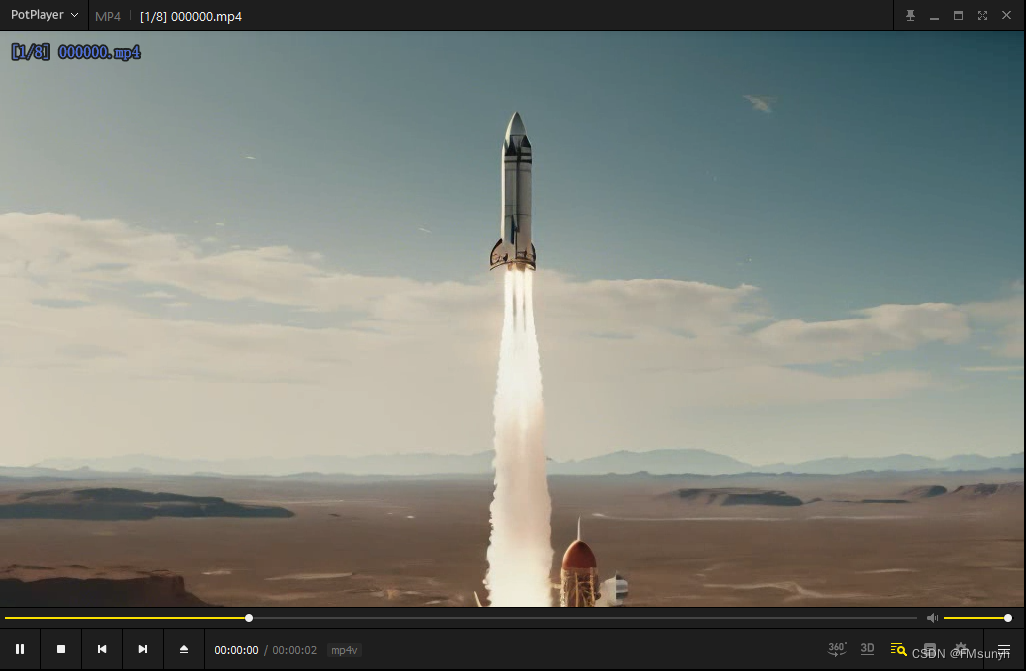
可以看到一个2秒的视频,已经生成了
AIGC群交流