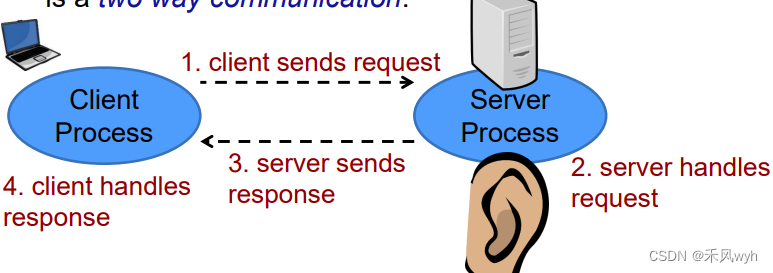
17. 天杀的http2.0
https://blog.csdn.net/weixin_44327634/article/details/123740008?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169949361816800180633940%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=169949361816800180633940&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~sobaiduend~default-2-123740008-null-null.nonecase&utm_term=%E7%8C%BF%E4%BA%BA%E5%AD%A6%E7%AC%AC%E5%8D%81%E4%B8%83%E9%A2%98&spm=1018.2226.3001.4450
import httpx
cookies = {
'sessionid': 'yyob4izkbkm2s0qj7as20dfog3n105ff',
}
headers = {
'user-agent': 'yuanrenxue.project',
}
sum = 0
for i in range(1, 6):
url = f'https://match.yuanrenxue.cn/api/match/17?page={i}'
with httpx.Client(http2=True) as client:
response = client.get(url, cookies=cookies, headers=headers).json()
datas = response.get('data')
for data in datas:
sum += data.get('value')
print(sum)
12. 入门级js
import requests
import base64
cookies = {'sessionid': 'yyob4izkbkm2s0qj7as20dfog3n105ff'}
headers = {'user-agent': 'yuanrenxue.project'}
sum = 0
for i in range(1, 6):
params = {
'page': str(i),
'm': base64.b64encode(('yuanrenxue' + str(i)).encode('utf-8')).decode('utf-8'),
}
response = requests.get('https://match.yuanrenxue.cn/api/match/12', params=params, cookies=cookies, headers=headers).json()
datas = response.get('data')
for data in datas:
sum += data.get('value')
print(sum)
13. 入门级cookie
搜索页面数字,发现数据所在,找到加密cookie
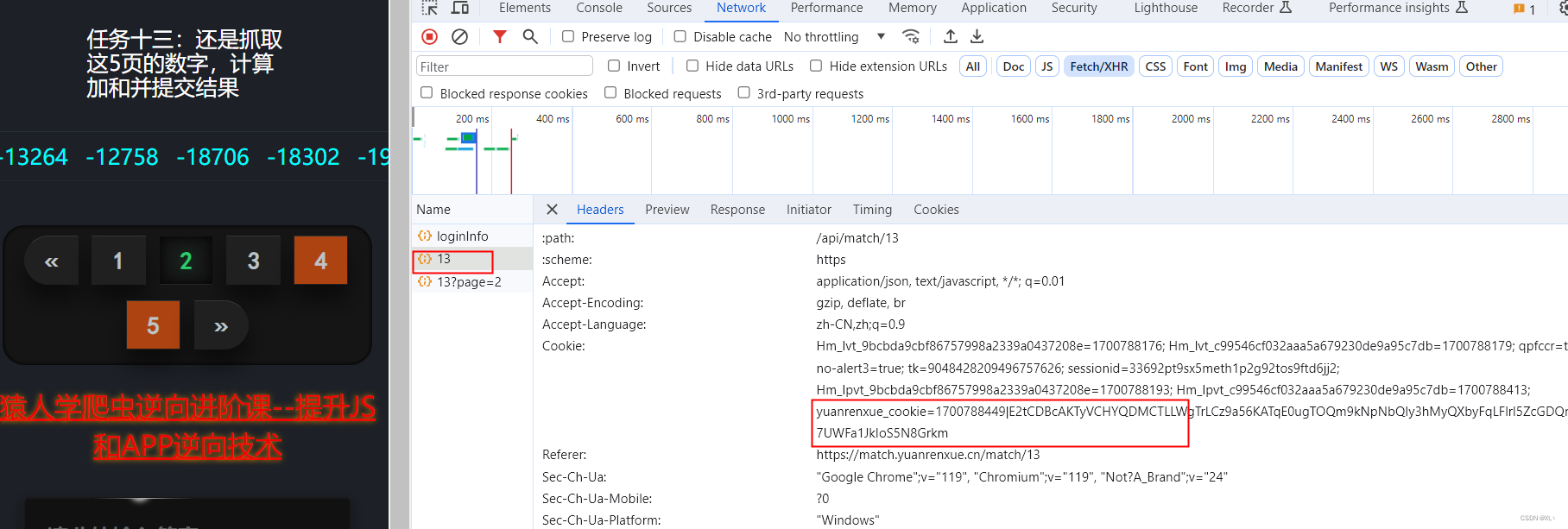
经对比发现此cookie与原网页返回的cookie相同
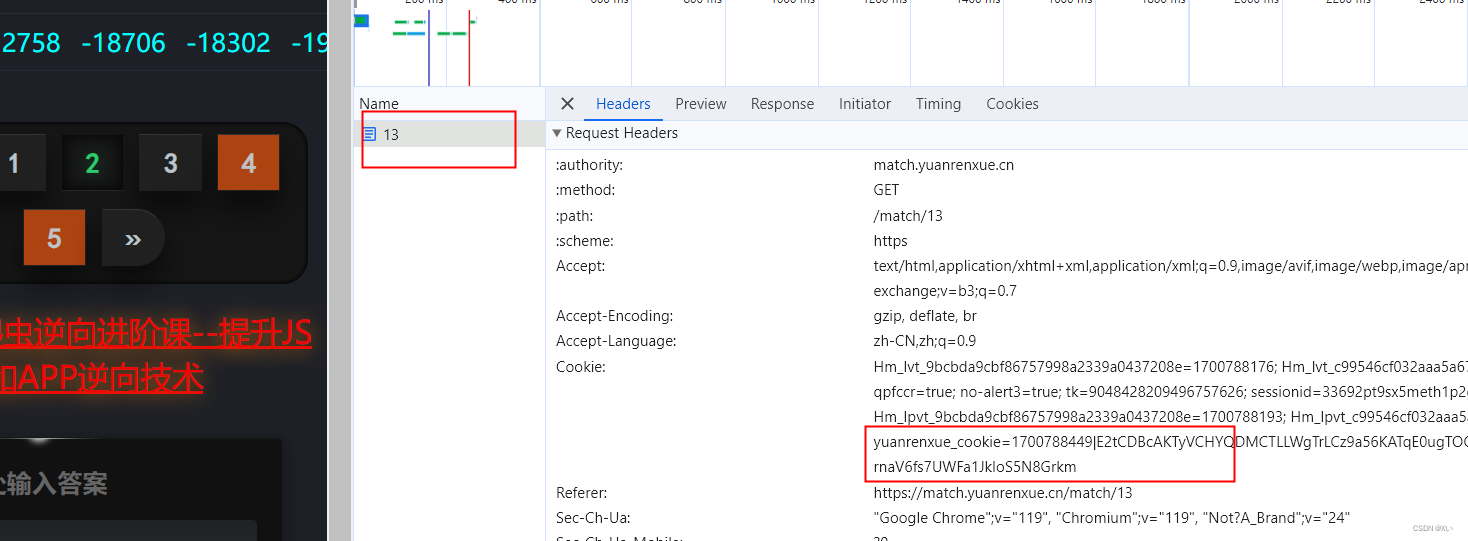
当代码请求此页时发现返回cookie
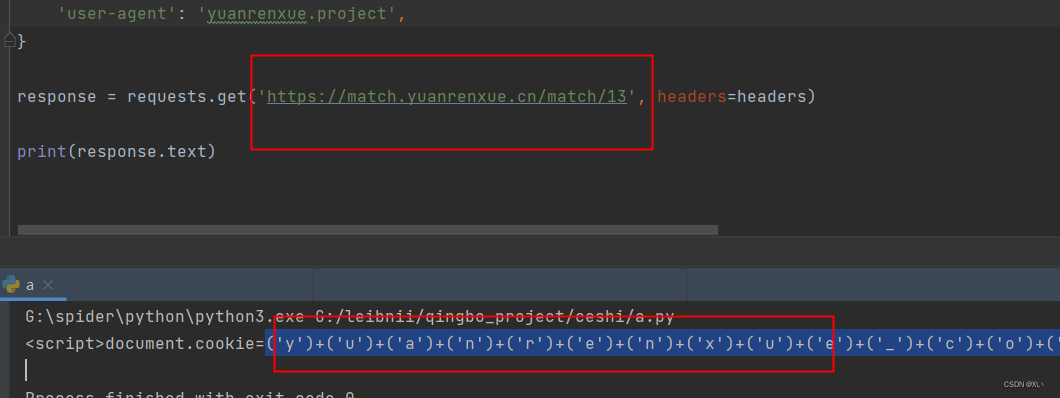

需用requets.sessions保持会话,requests不能保持会话,会出现错误(page no found)代码如下:
import requests
import re
import execjs
s = requests.session()
s.cookies.update({"sessionid": "33692pt9sx5meth1p2g92tos9ftd6jj2"})
s.headers = {'user-agent': 'yuanrenxue.project'}
response = s.get('https://match.yuanrenxue.cn/match/13')
js_code = re.findall('cookie=(.*?)\+\'\;path', response.text)[0]
yuanrenxue_cookie = execjs.eval(js_code)
y_cookie = re.findall('yuanrenxue_cookie=(.*?$)', yuanrenxue_cookie)[0]
cookie2 = {
'yuanrenxue_cookie': y_cookie,
}
s.cookies.update(cookie2)
sum = 0
for page in range(1, 6):
resp1 = s.get(f'https://match.yuanrenxue.cn/api/match/13?page={page}')
words = resp1.json()['data']
for word in words:
sum += word['value']
print(sum)