文章目录
- 虚拟内存
- 物理内存、物理地址、虚拟地址
- 虚拟地址空间
- 虚拟内存
- 缓存
- 页表
- 分配页面
- 页命中
- 缺页
- 虚拟内存的好处
- 简化链接
- mmap
- 虚拟内存的私有性
- 地址翻译
- 我们先看一下使用页表进行地址翻译有哪些东西:
- 虚拟地址到物理地址处理过程
- 页面大小和虚拟地址物理地址关系
- TLB翻译后备缓冲器
- 多级页表
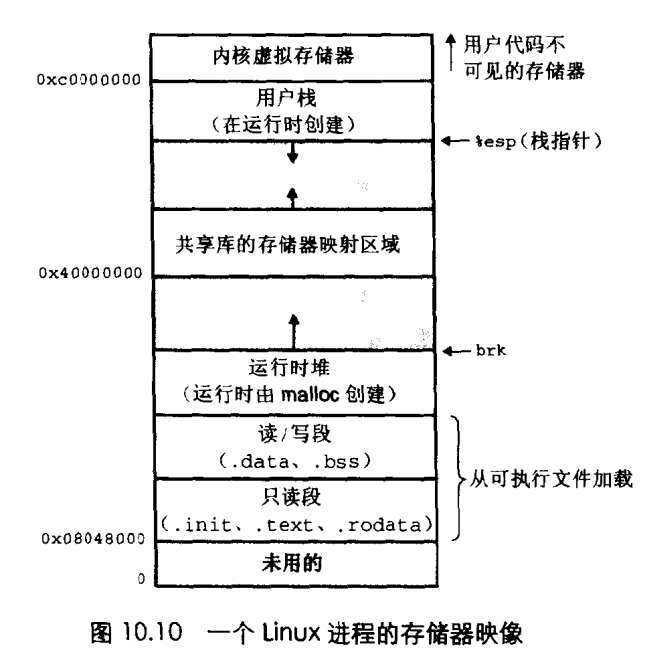
虚拟内存
虚拟内存是一种主存的抽象概念。
他为每个进程提供了一个大的,一致的,私有的地址空间。
三个重要能力:
- 更高效的使用主存。
- 为每个进程提供了一个一致的私有空间,简化内存管理。
- 保护进程的地址空间不被其他进程破坏。
物理内存、物理地址、虚拟地址
物理内存被组织成一个由M个连续字节大小的单元组成的数组。
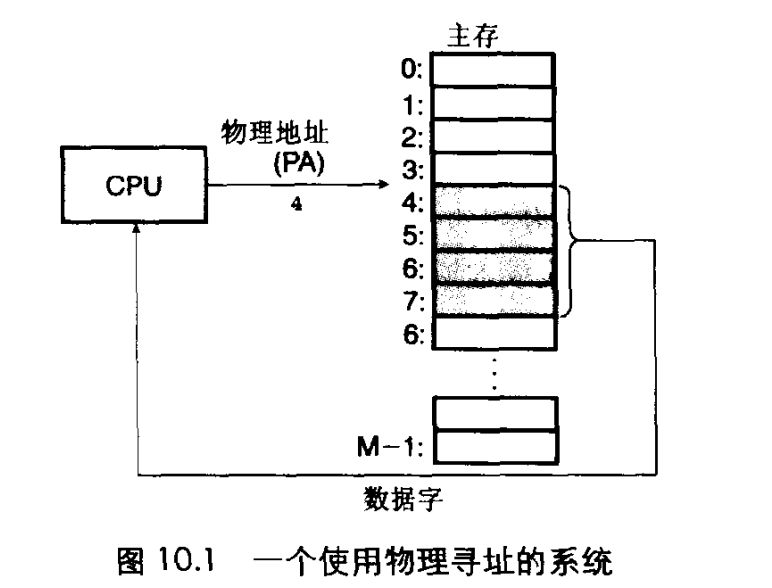
每个字节都有一个唯一的物理地址,用来定位这个字节的数据叫做PA。
CPU访问内存最自然的方式就是使用PA,这种方式我们叫做物理寻址。
比如上图CPU通过PA然后定位到主存中某个字节然后读取4字节的数据,放到CPU的寄存器中。
早期的PC都是使用物理寻址,现在一些嵌入式微控制器也使用这种方式。
现代处理器则使用虚拟寻址方式。
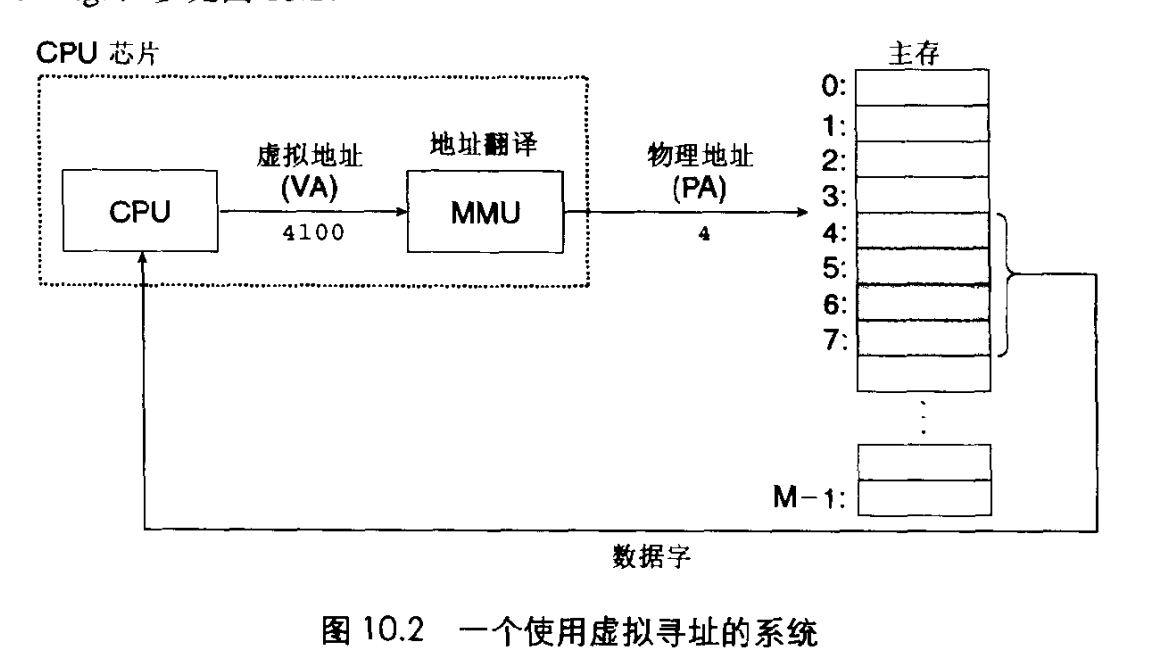
CPU通过生成的虚拟地址,然后将该虚拟地址通过MMU地址翻译系统翻译成PA,通过PA来定位主存中位置获取数据。
虚拟地址空间
有了虚拟地址,我们再介绍一下地址空间。
地址空间就是一块非负整数地址的有序集合。
比如在一个带虚拟内存的系统中,CPU从一个有2^N个的地址空间中生成虚拟地址。这块空间我们叫虚拟地址空间VAS。比如有2的32次方个地址的虚拟空间,我们叫32位地址空间,这个空间可以存放2的32次方个虚拟地址,每个地址表示一个byte,那么32位地址空间就能表示4G大小的内存空间。 64位的地址空间能表示的内存大小为16EB,这个空间是非常大的。
所以主存中的每个字节都有一个选自虚拟地址空间的VA和一个选自物理地址空间的PA。
虚拟内存
那么我们为何不直接使用PA,而是使用VA,还要做个翻译来获取数据呢。因为我们要使用虚拟内存。
虚拟内存是如何体现的呢?他被组织为一个由存放再磁盘上的N个连续的字节大小的单元组成的数组。注意他在磁盘上,而不是在主存中。磁盘上的内容一部分被缓存在主存中。
磁盘上和主存之间以一个块作为传输单元,这个块在磁盘上称为虚拟页,虚拟页大小为2的N次方个字节,一般是4K。主存页需要被分割成同样大小的块,这个块叫物理页或页帧,大小和虚拟页相同,一般也是4K。
虚拟内存在任意时刻都有三部分,每部分都由很多个虚拟页组成:
- 未分配的:没有在磁盘上分配空间的页。
- 未缓存的:已在磁盘上分配空间,但是没有在主存上缓存对应的页。
- 已分配的:已在主存中缓存的页。
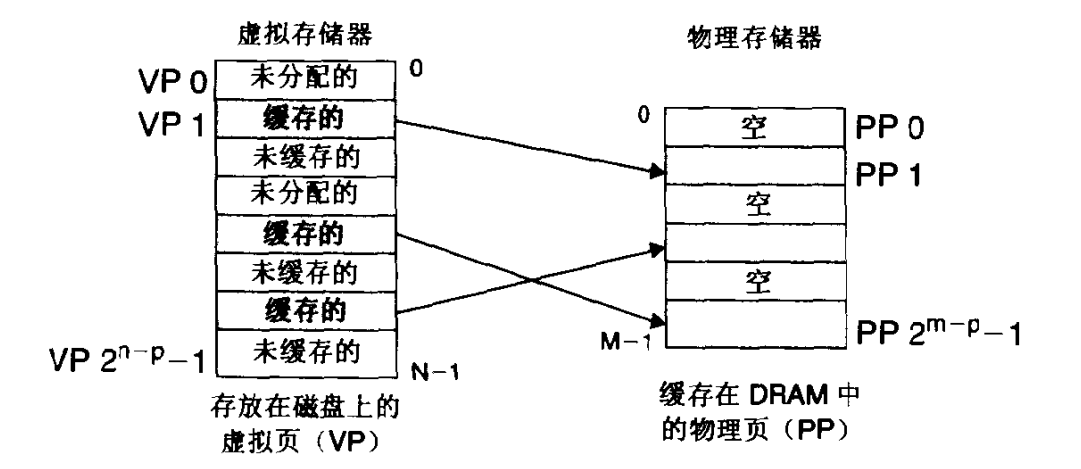
可以看到虽然虚拟内存在磁盘上是一整块空间,但是实际上映射到主存上的页可以是不连续的并且相隔可能很远。比如一个程序我们给他虚拟内存了,那么他可能在物理内存中占用非常小,极大减少主存的消耗。
缓存
SRAM表示CPU和主存之间的L1,L2,L3高速缓存。
DRAM表示虚拟内存系统的缓存也就是主存,他在主存中缓存虚拟页。
DRAM比SRAM慢10倍,而磁盘比DRAM慢100000倍。因此DRAM中的缓存不命中要比SRAM缓存不命中对系统影响更大。因为不命中处罚很大,所以虚拟页往往较大4K~2M。而且DRAM使用了更复杂精密的替换此算法。
页表
系统需要判定虚拟页存放在DRAM(主存)中的哪个物理页上,如果缓存中没有需要的页,也就是不命中,那么我们还需要知道该虚拟页在磁盘中的位置,取出来并替换掉当前缓存中的一个页。
这些功能是软硬件联合提供的,包括操作系统,MMU和一个存放在主存中的一个叫做页表的数据结构。
页表的作用就是:将虚拟页映射到物理页。
每次地址翻译硬件将一个虚拟地址转换成物理地址的时候,都需要去读取页表来查找。OS负责维护页表。
页表是由页表条目组成的数组。其中每个页表条目叫做PTE(page table entry)。
PTE由两部分组成
- 有效位,表示改虚拟页是否被缓存在主存中
- 地址位置,如果有效位表示在主存中,则存储的就是物理地址(注意这里存储的是该物理页的起始地址),如果不在主存中,则存储的是磁盘中的地址。如果是NULL则表示未在磁盘中分配空间。
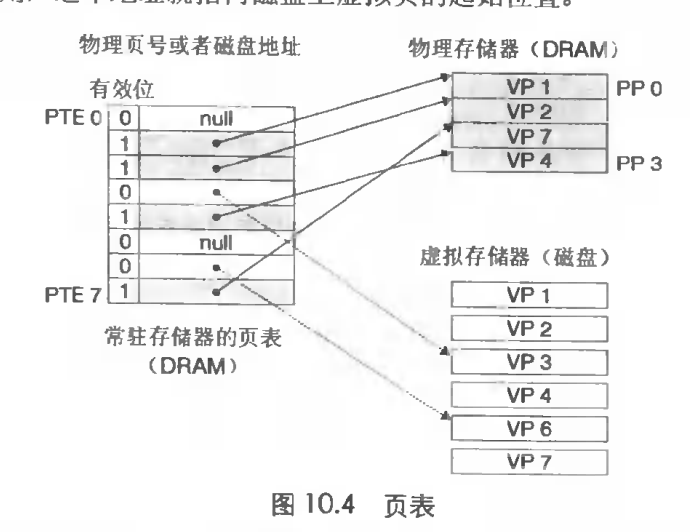
如上图所示,如果磁盘中有8个虚拟页,则对应的页表有8个PTE,其中有4个缓存在主存中,所以有4个PTE的地址存储的是主存的物理地址,其中两个并未分配存储null,两外两个存储的是磁盘中的虚拟页地址。
如果我们的虚拟地址空间为32位,也就是可以表示4G的虚拟内存,把这个4G内存分为很多个页,假设每个页大小为4K,那么就会分成1M个页,那么我们使用页表所需要的PTE数量也就需要是1M个。
分配页面
当我们使用malloc分配空间时,实际上会在磁盘上创建空间,比如一个页4K。此时会在页表上新建一个PTE映射该VP,但是实际上还没有缓存在DRAM上。
页命中
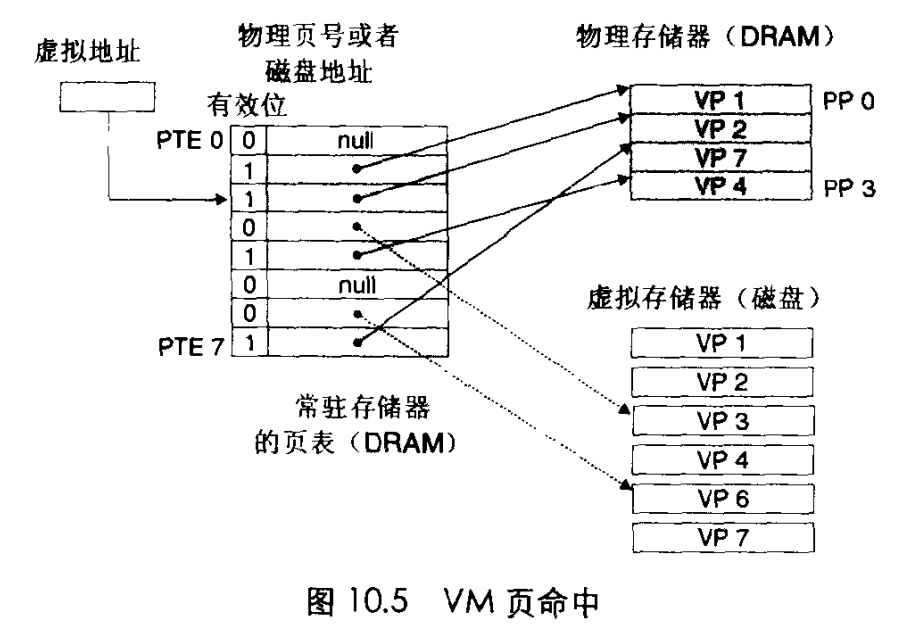
当CPU要读取虚拟内存中的一个字节的数据时,如果页命中,说明VP缓存在DRAM中,CPU拿到虚拟地址,通过MMU转换器得到定位页表中某个PTE的位置,然后通过获取PTE中的数据得到VP是在DRAM中,然后就可以得到该物理地址指向的页帧。
缺页
如果CPU要访问的数据,这个虚拟页不在DRAM中,那么叫做缺页。
- 此时通过虚拟地址定位到页表中的某个PTE,发现此VP的数据并不在DRAM中,比如VP3,此时触发缺页异常。
- 通过缺页异常,OS会调用一个异常处理程序来处理,该程序会使用替换算法,比如要牺牲某个页比如VP4,这个页之前被修改过,那么需要先将该页拷贝到磁盘中。
- 然后将VP3从磁盘中拷贝到DRAM,并修改页表的该PTE项。
- 此时缺页异常程序重启刚才的指令,CPU再次使用虚拟地址定位PTE,发现该PTE在DRAM中,那么就可以取出来使用,也就是页命中。
上面替换页的过程叫做页面调度或者叫做页交换。
虚拟内存的好处
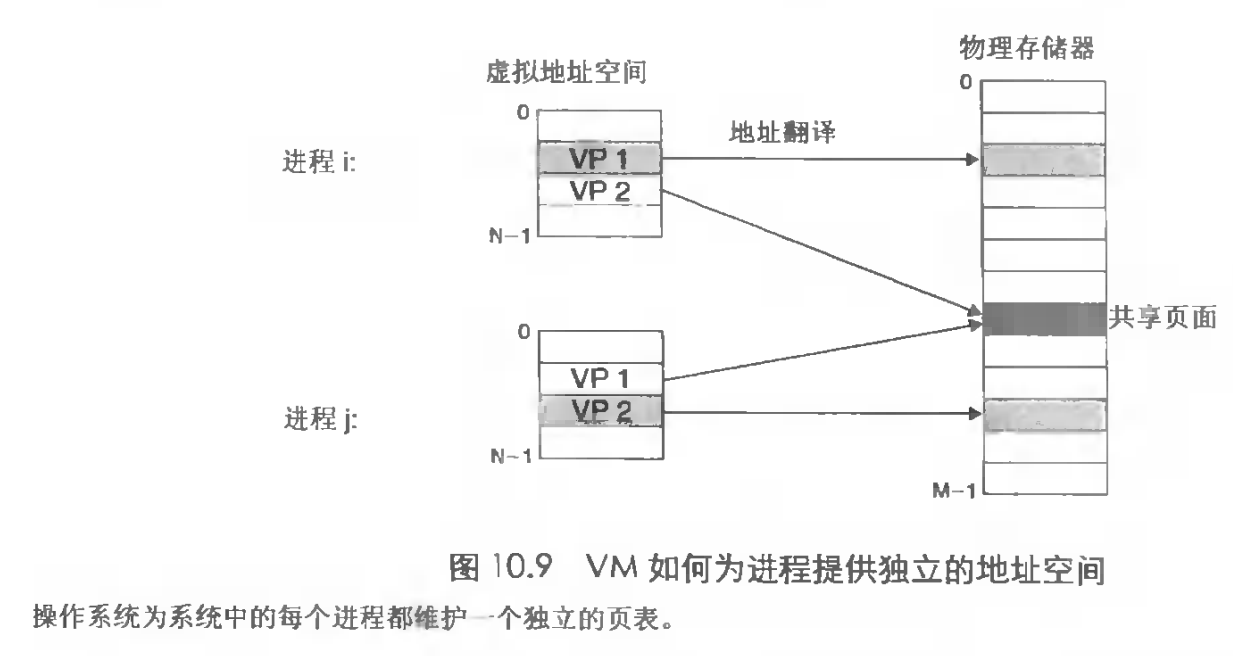
操作系统为每个进程都提供了一个独立页表,也就是一个独立的虚拟地址空间。并且多个VP可以同时映射到一个PP。
简化链接
每个进程都可以使用相同的存储基本格式。而不需要管数据实际存储在主存中的哪里。

共享代码区,比如每个C程序都要调用printf函数,那么不同程序可以使用共享代码和数据。操作系统通过将不同程序虚拟页面都映射到相同物理页面来共享这些代码,而不是在每个进程中都使用单独的一份存储在主存。
mmap
虚拟内存并不总是存在到磁盘上,我们也可以将他映射到一个文件或者另一个存储位置中,这个过程就叫做mmap,memory mapping。
虚拟内存的私有性
操作系统提供手段控制内存系统访问。
- 不允许用户进程修改只读代码段
- 不允许读或修改任何内核中代码和数据
- 不允许他读或写其他进程私有内存
- 不允许修改其他进程共享内存页,除非有显示允许。
所以PTE上不只有标识是否缓存到物理内存,而且还带额外的许可位来控制队一个虚拟页面内容的访问。
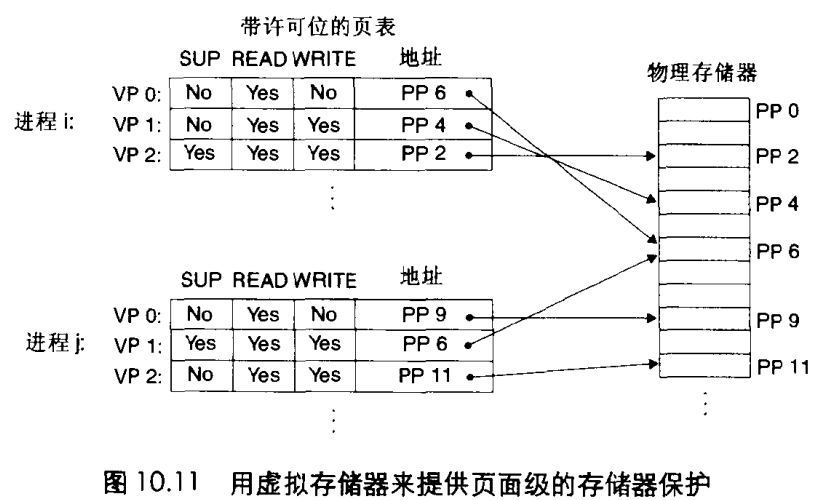
比如这几个许可位,sup表示进程是否必须运行在内核态才能访问该页,no表示程序可以访问,READ和Write就是读写访问权限。
比如进程i,在用户模式下可以读VP0和读写VP1,但是无VP2的访问权限。
如果一条指令违反了许可条件,比如这个指令要进程i去读VP2,但是读VP2是不被允许的,那么CPU就会触发一个保护,产生异常,Linux一般将这种异常报告为段错误。也就是程序访问的虚拟地址有问题,这个地址实际上是不允许被访问的。
地址翻译
形式上来说:地址翻译就是虚拟地址空间VAS中的元素和物理地址空间PAS中元素的映射。
也就是通过虚拟地址找到物理地址。
我们先看一下使用页表进行地址翻译有哪些东西:
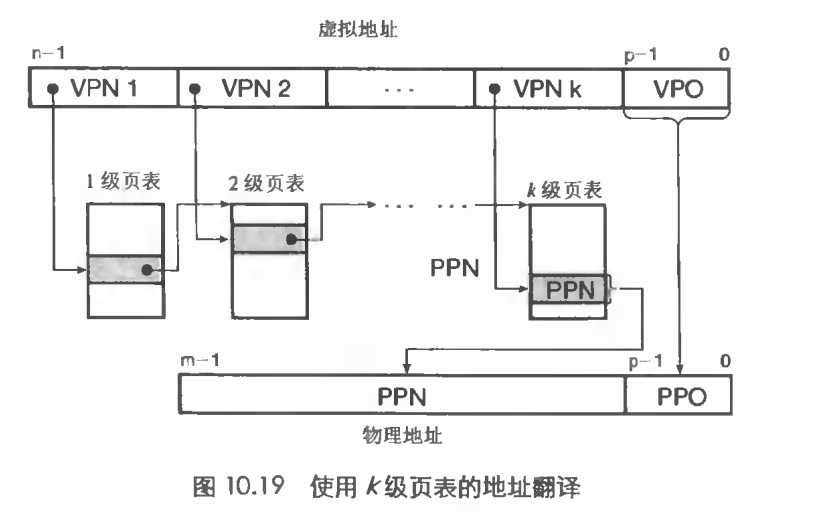
- n位虚拟地址包含两个部分:p位虚拟页面偏移VPO和n-p位的虚拟页号VPN
- 页表基址寄存器指向当前页表
- MMU利用VPN虚拟页号来选择页表中的PTE
- 将PTE中保存的物理页号PPN和VPO串联起来就可以计算得到物理地址。
- m位的物理地址也包含两部分类似于虚拟地址,PPO和PPN。这里的PPO和VPO实际上是完全相同的。
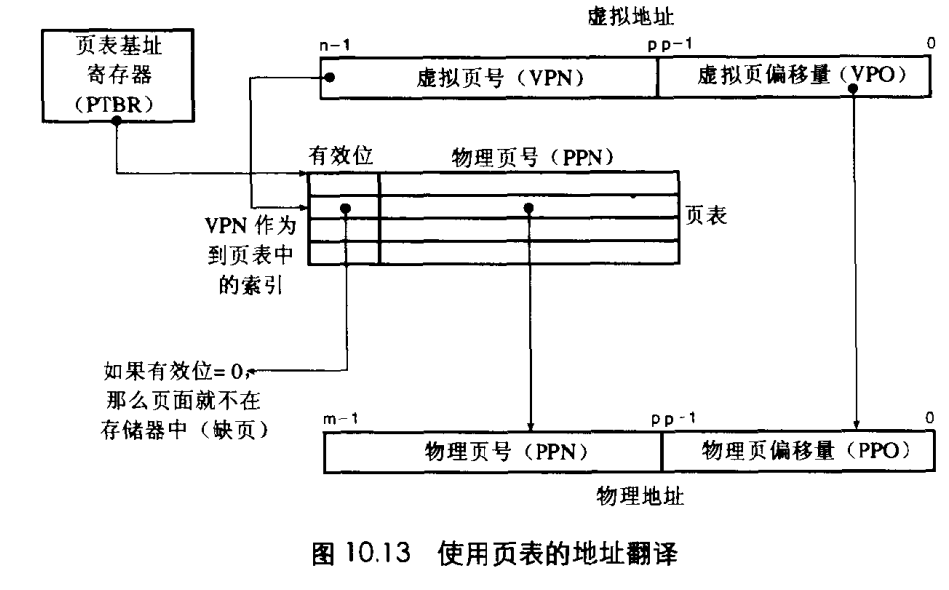
虚拟地址到物理地址处理过程
- 处理器生成VA,并传送给MMU
- MMU找到该页表并找到PTE的地址PTEA,向高速缓存请求这个PTE(主存只接收地址并返回数据)
- 主存将PTE返回给MMU。
- MMU通过PTE构造物理地址PA并向主存请求数据。
- 主存返回数据给CPU
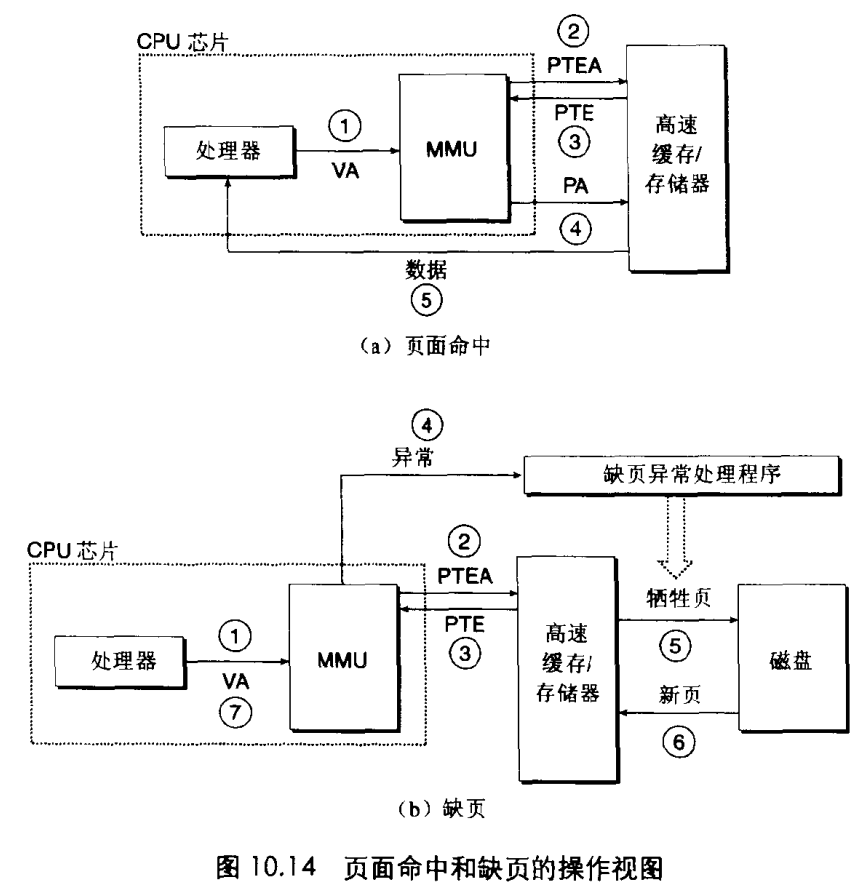
如果页面不命中,那么我们看处理步骤:
3. 1~3步和上面处理相同
4. MMU拿到的PTE发现这个数据并不在主存中,这是MMU触发一次异常传递给异常处理程序
5. 异常处理程序会确定牺牲页并把它换给磁盘中
6. 从磁盘中拿到新页也就是要查找的页拷贝给主存,并更新主存中的PTE
7. 缺页处理程序完成,回到原进程再次执行VA查找指令,重复上面过程。
所以可以发现如果不命中,整个系统的耗时要增加很多。
页面大小和虚拟地址物理地址关系
如果我们有一个n=32位的VA和一个m=24的PA,那么我们如何设定VPO及PPO呢?
如果页面大小为4K:那么意味着对于VPO我们需要12位,也就是2的12次方个数,才能确定4K页面的每一个byte的数据,那么PPO也是12位。所以对于VA,VPN的位数就位20位,PPN的位数九尾12位。
如果页面大小位8K:那么VPO和PPO我们就需要13位,VPN就19位,PPN就剩11位。
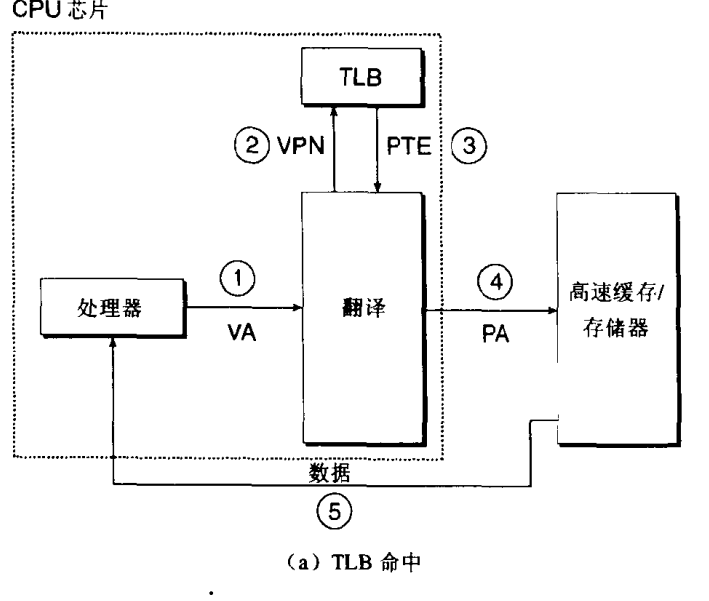
TLB翻译后备缓冲器
我们通过上面两种虚拟地址到物理地址转换的过程,发现,如果是每次MMU都要从主存中去请求PTE,而CPU和主存之间的速度差是很大的。所以这个速度将被拖慢。
所以我们加入一个机制叫做TLB,他的作用就是缓存PTE数据,TLB是用SRAM来存储的,来加快地址翻译。
下面我们看加入TLB的流程:
- 处理器生成VA
- MMU通过VPN去TLB中查到PTE。VA中的VPN部分就是保存TLB索引的。
- 从TLB获取到PTE
- 直接翻译成PA然后从主存中取出数据.
多级页表
如果我们的虚拟地址空间为32位,也就是可以表示4G的虚拟内存,把这个4G内存分为很多个页,假设每个页大小为4K,那么就会分成1M个页,那么我们使用页表所需要的PTE数量也就需要是1M个。每个PTE是4byte,那么我们一个页表的大小就要有4M。
这一个进程的4M页表是要存储在主存中的,我们开启十多二十个进程其实也还好,大不了就占用个几百M。但是如果虚拟地址空间为64位呢,那这个页表可就太大了,主存可能装两个进程就占满了。
所以我们需要一种压缩页表的方法,这种方法就是使用多层次结构的页表,也就是多级页表。
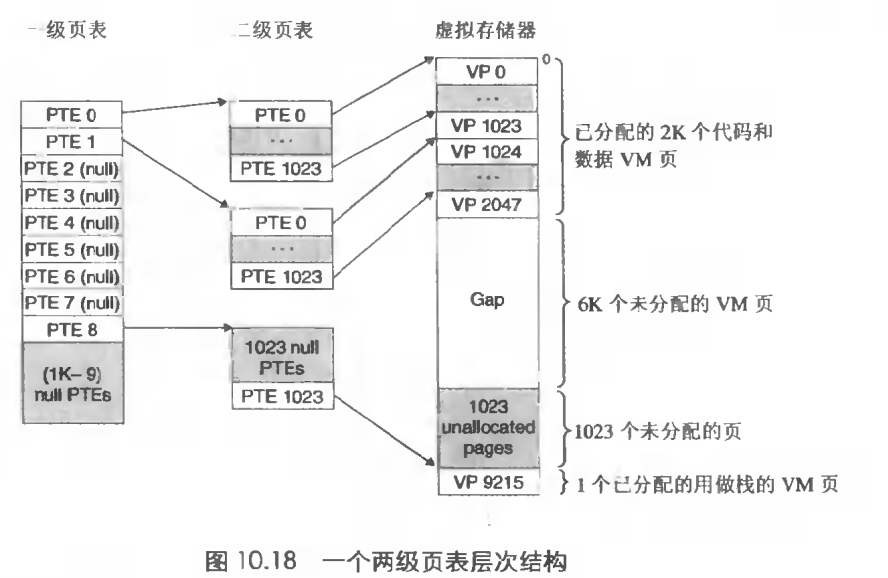
如果使用二级页表,我们看一下会有什么优势。
一级页表的一个PTE 4byte负责定位一个二级页表的4K页,然后这4K页可以映射虚拟内存中的4M块。那么一级页表用1024个PTE就可以映射虚拟内存的4G了。
如果虚拟内存中的一块内存是未分配的,那么假设这块连续内存大小为400M,那么二级页表的400K就可以不被分配到主存中,这是一个潜在的巨大节约。一级页表的PTE为空,那么二级页表的相应4K就不会存在。一个典型的4G程序,他的虚拟内存大部分空间都是未分配的。第二,只有一级页表存储在主存中,而二级页表可以放到硬盘中,经常需要使用的缓存在主存中。从而减少主存压力。
下面我们看一下多级页表
虚拟地址va被划分成很多部分,每一部分对应VPN的页表索引。
为了构造物理地址,需要访问K个PTE。
访问K个PTE,第一眼看上去好像及其昂贵且不可思议,但是可以使用TLB缓存不同级别的页表,这样在实际操作中,K级页表的访问并不比只有一级页表慢很多,但是节约的内存却是巨大的。