keys命令的用法:
keys pattern
查找符合正则匹配的key的列表。扫描对象是Redis服务中所有的key,想想都很慢对不对?
同时执行keys命令的同时,Redis进程将被阻塞,无法执行其他命令,假如超过了哨兵的down-after-milliseconds配置,还会进行主从切换,切换过程中,如果主节点恢复正常,还可能出现脑裂等一系列问题。
所以,生产环境中,建议直接禁用keys命令。
Keys命令的替代方案
- scan扫描,避免阻塞
- 将需要统计的数据放入一个set中 (但是这样可能出现Big Key问题,一般数据量大就不推荐)
Keys命令在Redis Cluster中是怎样执行的?
一般来说,keys命令对于集群节点来说,是不知道路由到哪个节点的,不像 get命令。在Java的Jedis客户端的JedisClusterKeyCommands类中,我们看到:
public Set<byte[]> keys(byte[] pattern) {
// 在每个节点执行keys命令
Collection<Set<byte[]>> keysPerNode = connection.getClusterCommandExecutor()
.executeCommandOnAllNodes((JedisClusterCommandCallback<Set<byte[]>>) client -> client.keys(pattern))
.resultsAsList();
// 合并成一个整体后返回
Set<byte[]> keys = new HashSet<>();
for (Set<byte[]> keySet : keysPerNode) {
keys.addAll(keySet);
}
return keys;
}
我们看到,Jedis是通过在每个节点上执行keys命令,并将结果合并返回的。
本文既然将keys命令的慢,那么他到底有多慢呢?
Keys命令到底有多慢?
这里主要是给大家一个基本的概念,并不是深入剖析。
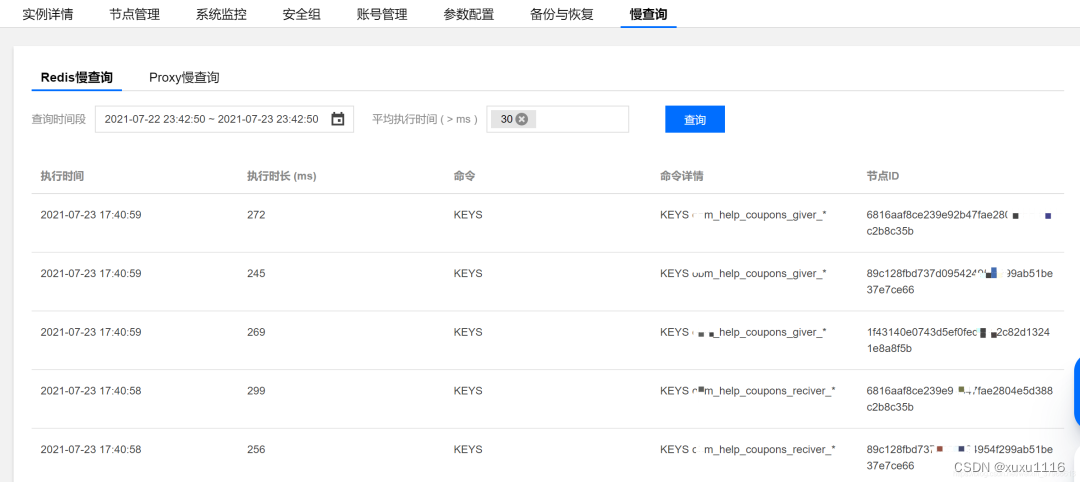
这是腾讯云上Redis集群服务中,慢查询的日志。我们看到,Keys命令大概执行了250ms ~ 300ms。
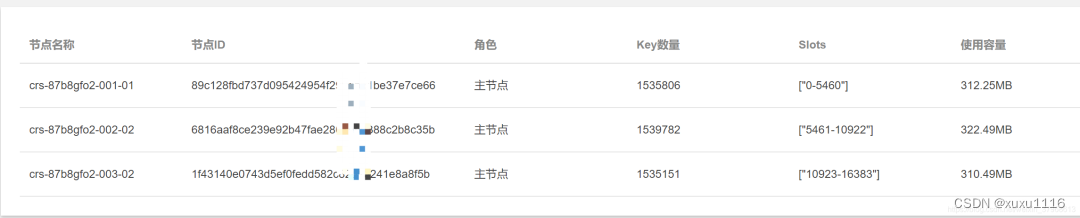
根据节点信息,我们看到,每个节点存储了大约153w的key,占用内存300M+,平均每个键值对占用内存0.208KB,合213个字节。
根据我的理解,既然keys命令返回的是key值,而集群中其实有一个结构slots_to_keys 记录着所有key 的, 这只与key的数量有关,与Big key的关系不大。
按照这种猜想,假如此时Redis节点占用内存为3G,且Key数量成比例,那么Keys命令执行时间因为3s左右,这段时间Redis节点是阻塞的。










![[BJDCTF2020]The mystery of ip1](https://img-blog.csdnimg.cn/655cfbc9a0c64a218102a0a0443e1565.png)

