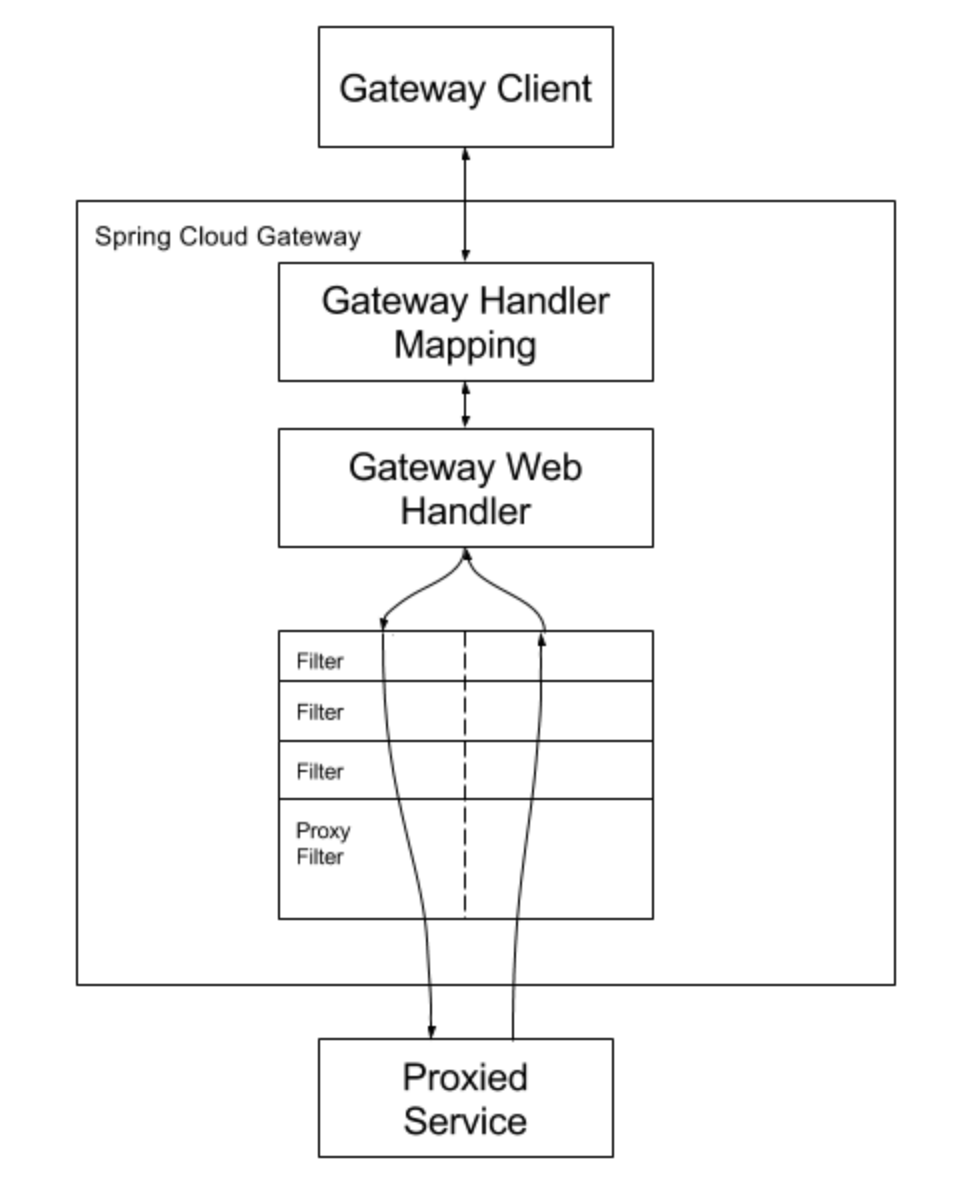
Python语言提供的wordcloud词云功能,使文本数据的可视化,简单而美丽。但网上的大多数词云生成功能,多半没有可交互的GUI界面,使用起来稍觉不便。笔者结合网上的中文词云功能,以唐诗三百首,宋词三百首,宋诗三百首和元曲三百首为数据源,把展示的词云整合到Python语言的Tkinter GUI界面中,可以随时在唐诗宋词元曲间切换词云的数据来源,也可选择某一个作者的作品生成词云,为古诗词的文本分析,提供了方便的可视化工具。
如下是应用的界面,缺省显示唐诗三百首的词云:

切换作品,选择宋词三百首,点击生成词云:

从词云可以明显看出,唐诗和宋词的风格不一,主要的语词也不尽相同,但也有一定的相同之处,比如月,比如人,都是比较重要的词语。
也可以切换不同的作者,查看生成的词云。唐诗三百首,选李白:

李白喜欢月亮,经常邀月同饮;李白也自许甚高,所有我字也比较突出。
看看杜甫:
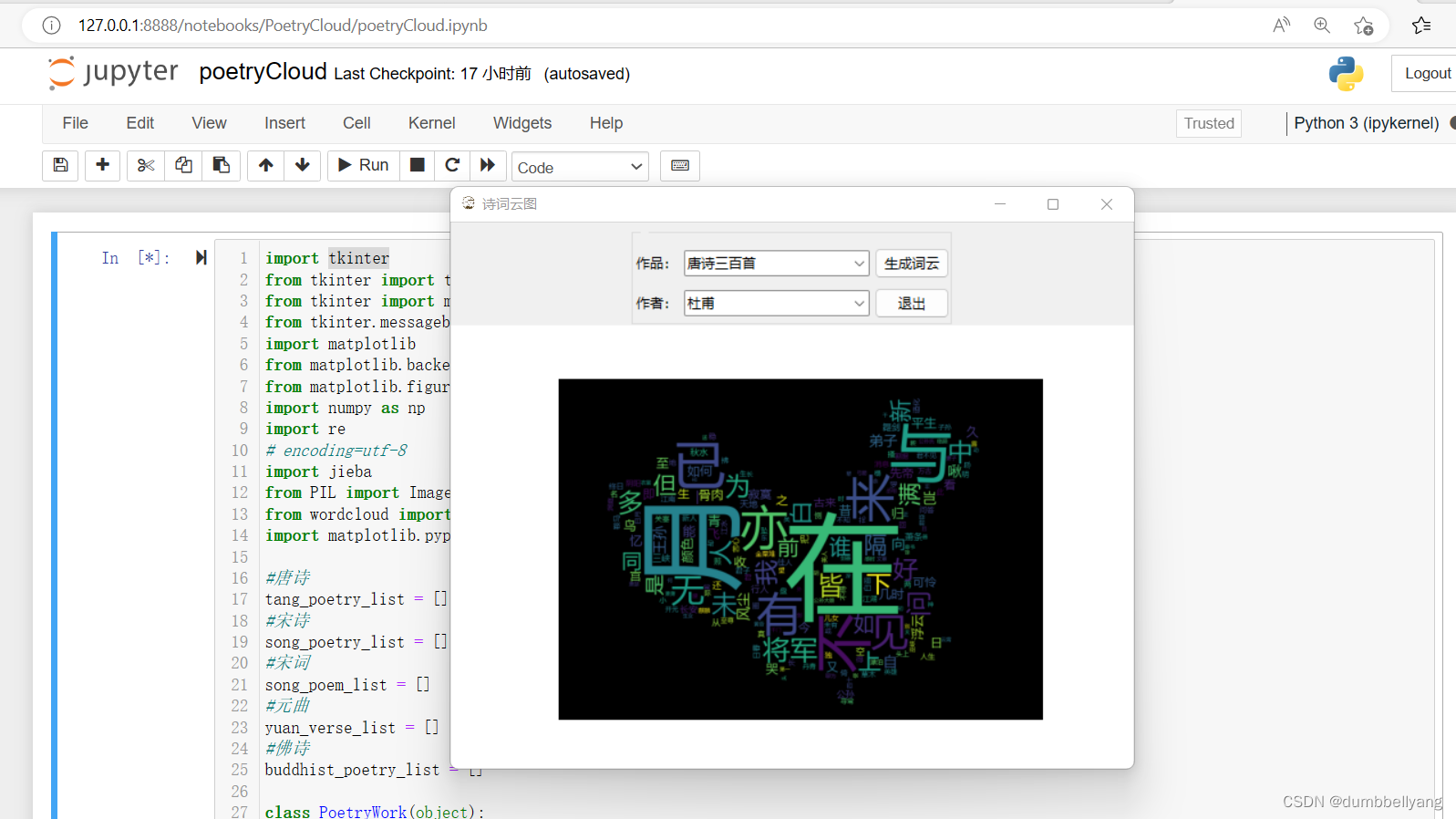
虽然也经常有月入诗,但已经没有李白那么突出了;而杜甫心忧天下,浑然忘我,词云中看不到我字。
上面演示了功能, 下面讲一下代码如何实现的。从网上找到唐诗三百首,宋词三百首,宋诗三百首及元曲三百首的文本,然后读入到Python的list中,list中的元素为自定义PoetryWork类:
class PoetryWork(object):
def __init__(self, num, title, author, content):
self.num = num
self.title = title
self.author = author
self.content = content
def get_num(self):
return self.num
def get_author(self):
return self.author
def get_title(self):
return self.title
def get_content(self):
return self.content
如下为加载唐诗三百首的代码:
#加载唐诗三百首
def load_tang_shi():
tang_poet_list = {}
num = ''
title = ''
author = ''
content = []
pattern = r'\d{3}'
with open('唐诗三百首.txt', 'r', encoding= 'utf-8') as f:
for line in f.readlines():
if line:
if re.match(pattern, line):
#内容不空
if content:
tang_poetry_list.append(PoetryWork(num, title, author, content))
pos = line.index(':')
num = line[:3]
author = line[3:pos]
if author in tang_poet_list:
tang_poet_list[author] += 1
else:
tang_poet_list[author] = 1
title = line[pos+1:]
content = []
#print('num:{},author:{},title:{}'.format(num, author, title))
else:
if line.strip():
content.append(line.strip())
tang_poetry_list.append(PoetryWork(num, title, author, content))
tang_poet_list = dict(sorted(tang_poet_list.items(),key=lambda x:x[1], reverse=True))
poet_list = [x for x in tang_poet_list.keys()]
poet_list.insert(0,'all')
return poet_list
在加载过程中对唐诗按作者进行了统计,最后按作品数量倒序输出返回作者列表,填充界面上作者的下拉框。
加载宋词宋诗和元曲的代码大体类似。
通常的词云展示都是用Matplotlib的控件方法,那样的化就没法整合到Tkinter的GUI界面中了,也不方便与用户进行交互。笔者参考网上代码,采用matplotlib的FigureCanvasTkAgg canvas画布功能,把生成的云图嵌入。
首先是声明matplotlib绘图的Figure和canvas画布对象:
curRow = 2
fig = Figure(figsize=(5, 4), dpi=100)
canvas = FigureCanvasTkAgg(fig, master=win) # A tk.DrawingArea.
canvas.get_tk_widget().pack(side=tkinter.BOTTOM, fill=tkinter.BOTH, expand=1)
然后在生成词云后,把词云嵌入进去:
def generateCloud(*args):
"""清除原有图表,生成新的图表"""
global fig,canvas
fig.clear()
ax = fig.add_subplot(111)
content = []
cur_author = poetList.get()
if workList.get() == '唐诗三百首':
for work in tang_poetry_list:
if cur_author == 'all' or cur_author == work.get_author():
content.extend(work.get_content())
elif workList.get() == '宋诗三百首':
for work in song_poetry_list:
if cur_author == 'all' or cur_author == work.get_author():
content.extend(work.get_content())
elif workList.get() == '宋词三百首':
for work in song_poem_list:
if cur_author == 'all' or cur_author == work.get_author():
content.extend(work.get_content())
elif workList.get() == '元曲三百首':
for work in yuan_verse_list:
if cur_author == 'all' or cur_author == work.get_author():
content.extend(work.get_content())
else: #佛诗三百首
for work in buddhist_poetry_list:
if cur_author == 'all' or cur_author == work.get_author():
content.extend(work.get_content())
res = jieba.lcut(" ".join(content)) # 中文分词
text = " ".join(res) # 用空格连接所有的词
mask = np.array(Image.open("chinamap.png")) # 指定词云图效果
# 创建词云对象
wc = WordCloud(width=800, height=600, mask=mask).generate(text)
ax.imshow(wc) # 显示词云图
ax.axis("off")
wc.to_file("{}_{}_wordcloud.png".format(workList.get(), cur_author)) # 保存成图片
canvas.draw()
重点是这两行代码:
# 创建词云对象
wc = WordCloud(width=800, height=600, mask=mask).generate(text)
ax.imshow(wc) # 显示词云图
最后是canvas.draw().
要显示中文词云,还需要解决中文字体的问题。按网上的方法,可以在生成词云时,加入参数:font_path="simhei.ttf"。我这里使用的Miniconda3,加入字体路径报错,改成绝对路径还是报错。就采用了另一种方法,直接修改词云源码wordcloud.py里面的缺省字体设置:(全局搜wordcloud.py文件):
FONT_PATH = os.environ.get('FONT_PATH', os.path.join(FILE, 'DroidSansMono.ttf'))
将系统的缺省英文字体DroidSansMono.tff修改为别的中文字体即可。
我按照网上的建议先是改成simhei.ttf,乱码依旧。后来改成msyh.ttc微软雅黑字体,就好了。但是simhei.ttf这种字体在我的电脑上是正常安装了的,不知道为啥wordcloud找不着。
本文所有代码及资源文件都已上传github:GitHub - yangdanbo/PoetryCloud