一、Telemetry的背景
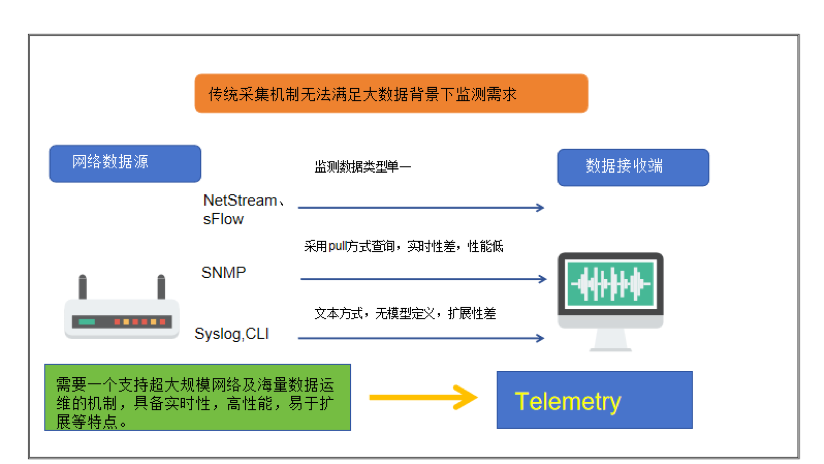
传统的网络设备监控方式有SNMP、CLI、Syslog、NetStream、sFlow,其中SNMP为主流的监控数据方式。而随着网络系统规模的扩大,网络设备数量的增多,网络结构的复杂,相应监控要求也不断提升,如今这些传统监控方式体现出了许多不足之处,比如:
-
NetStream、sFlow主要针对流量进行监测,而缺少对于其他数据平面如CPU信息、内存、网络拥塞信息、网络事件的日志信息等的相关监测。
-
Syslog和CLI都缺少统一的结构化的数据,不利于维护和扩展。
-
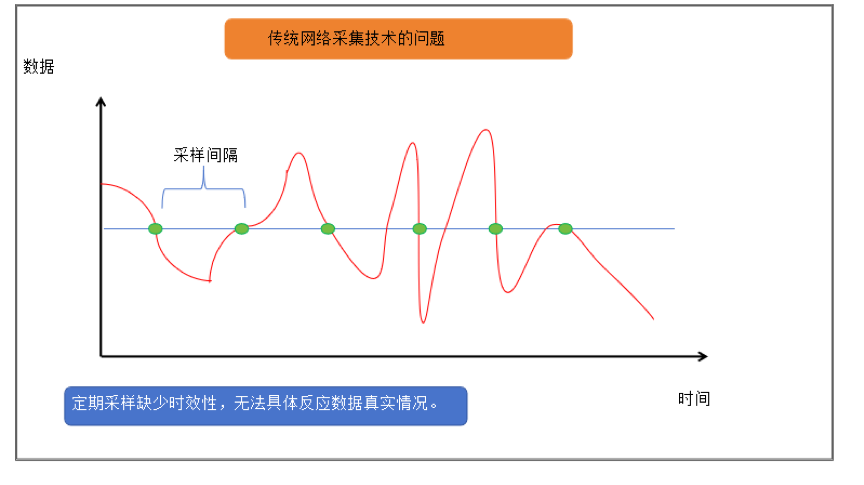
SNMP虽然监测范围较广,但是在监测频率和方式上存在着不足。SNMP的主要监测方式为传统的拉模式(Pull Mode),这种方式是由监测端轮询式地主动向节点发起请求,等待响应的一问一答的模式。这种方式时效性较差,也难以监测突发性事件。如果采样周期过长,实时性下降;采样周期过短,则会增大被检测设备压力。
-
虽然SNMP发展出了SNMP Trap的推送方式,但是这种方式只能够推送事件和告警信息,类似接口流量等的监控数据不能采集上送。
因此,大型数据网络的监控技术应具备实时性、高性能、高扩展性等特点,包括监控数据拥有更高的精度以便及时检测和快速调整微突发流量,同时监控过程要对设备自身功能和性能影响小以便提高设备和网络的利用率,更好的实现运维可视化,如监测时延,转发路径,缓存和丢包等。如果使用外部应用发起的请求获取网络状态信息的SNMP协议,就无法实时反映网络的状态。
传统监测方式存在的缺陷 :
SNMP的时效性较差:
Telemetry就是在这种需求下诞生的技术。业界也有将SNMP认为是传统的Telemetry技术,把当前Telemetry叫做Streaming Telemetry的说法,本文用Telemetry代指Streaming Telemetry。Telemetry 是新一代从设备上远程高速采集数据的网络监控技术,设备通过“推模式(Push Mode)”周期性地主动向采集器上送设备信息,提供更实时、更高速、更精确的网络监控功能。相比于SNMP,Telemetry实现了网络设备主动推送状态信息的能力,具有更强的时效性。
二、Telemetry的特点
Telemetry采集数据的类型丰富,可以充分反映网络状况。
其按照统一的YANG数据模型组织数据,可利用谷歌的GPB(Google Protocol Buffers)、XML、JSON等多种方式进行编码和解码,并通过gRPC(Google Procedure Call Protocol)等协议传输数据,使得数据的获取更高效,智能对接更便捷。Telemetry可监测的数据类型有:
-
网络接口数据:包括网络接口的流量、错误率、丢包率等。
-
网络设备状态:包括CPU利用率、内存利用率、温度、风扇转速等。
-
网络流量统计:包括流量的源IP地址、目的IP地址、端口号等信息。
-
QoS(服务质量)指标:包括延迟、抖动、丢包率等。
-
链路状态:包括链路的带宽利用率、带宽利用率变化趋势等。
-
BGP(边界网关协议)信息:包括BGP路由表、AS(自治系统)路径等。
-
网络安全信息:包括DDoS攻击、端口扫描、异常流量等。
-
网络设备性能指标:包括各种硬件指标、资源利用率等。
设备采用推(push)的方式周期性的主动向采集器上送监测数据(精度可以达到亚秒级别,快速定位问题)。
传统的SNMP检测方式主要依靠网络设备的路由引擎来处理信息。而Telemetry可以借助厂商支持,硬件板卡ASIC层面植入代码,直接从板卡导出实时数据。而板卡导出的数据是按照线速发送,从而使得上层的路由引擎专注于处理协议和路由计算等。实时性的数据可以为机器学习和目的分析提供充分支持,对自动化、流量调优和微突发等应用具有很大帮助。
Telemetry实现了一次订阅,设备N次回复,可以一直监控设备,避免重复查询。
传统SNMP查询是一问一答的,假设1分钟内交互了1000次,就意味着SNMP解析了1000次查询请求报文,监控系统要为每一次查询请求保留会话信息,才能匹配返回的查询结果;同时被查询的设备端需要中断其他任务来执行查询命令。这种基于pull的方式的查询是双向传输的,不仅开销大而且实时性低。在大型网络中,路由器和交换机等设备往往有较大压力,无法支持短时间多次查询请求。Telemetry的push模式则只需要订阅一次,后续设备持续推送数据给监控系统,不需要维护会话关系,实现一次性传输,非常适合采集接口信息等高速的监控数据。
Telemetry和SNMP方式的对比:
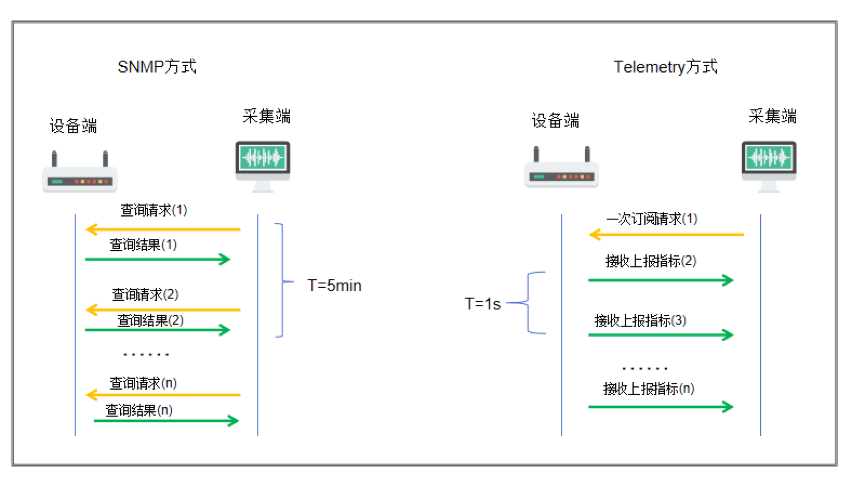
支持变频采样和抑制功能。
一般情况下,用户的分析器需要设置较小的采样周期来获取更精确的数据用于分析,但是较小的采样周期产生了大量冗余数据,不仅需要大量的存储空间,也不便于用户对数据进行管理。如果配置了变频采样,Telemetry将根据预制的条件动态(如CPU利用率)调整采集周期,在监控指标正常的情况下,降低采样时间间隔,当监控指标达到阈值时,按照配置自动调整采样周期,以更高的频率上报采集数据,从而减少分析器的数据量。
以华为NE40E-M型路由器为例,若当前主控板CPU利用率在90%以上,Telemetry 除了CPU和内存的采样任务之外,对其他采样任务暂停。此时Telemetry停止上送采集数据,进入抑制状态。占用率下降到阈值后抑制解除,恢复上送后可能会导致部分数据的上送周期被拉长。
三、Telemetry的工作原理
Telemetry工作原理:
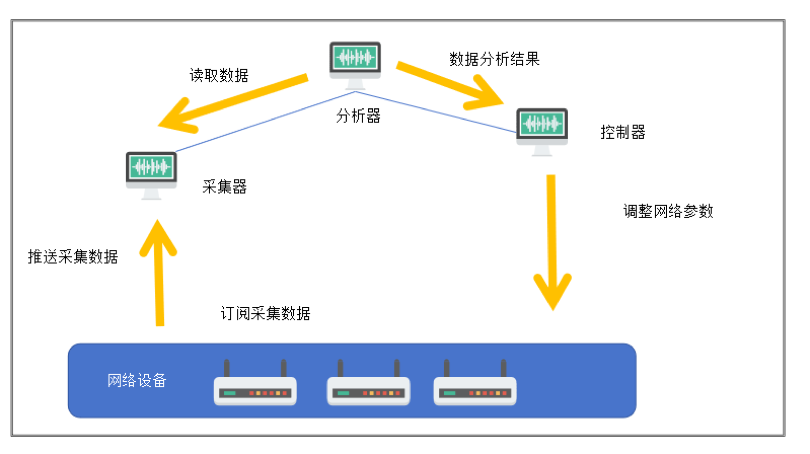
一个完整的telemetry系统可分为五个部分:
订阅采集数据
订阅数据的方式分为静态订阅和动态订阅:
静态订阅是指设备作为客户端,采集器作为服务端,由设备主动发起到采集器的连接,进行数据采集上送。多用于长期巡检。
动态订阅是指设备作为服务端,采集器作为客户端发起到设备的连接,由设备进行数据采集上送。多用于短期监控。
推送采集数据
Telemetry通过数据推送将经过编码格式封装的数据上报给采集器进行接收和存储;Telemetry的数据推送有两种方式:基于gRPC方式和基于UDP方式。
读取数据
被检测设备和采集器均通过GPB结合.proto文件进行编码/解码。
以gRPC订阅推送为例子:
设备通过Yang模型捕获可获取的数据信息(数据源)
然后将这些数据通过GPB结合.proto文件进行编码(数据生成)
采集器通过gRPC进行数据订阅(数据订阅)
设备通过gRPC将编码数据推送到订阅的采集器中(数据推送)
采集器再根据通过GPB结合.proto文件进行解码(此文件要和GPB的.proto文件一致)
分析数据
分析器分析读取到的采集数据,并将分析结果发给控制器,便于控制器对网络进行配置管理,及时调优网络。
调整网络参数
控制器将网络需要调整的配置下发给设备,配置下发生效后,新的采集数据又会上报到采集器,此时分析器可以分析调优后的网络效果是否符合预期,直到调优完成后,整个业务流程形成闭环。
四、Telemetry的应用场景
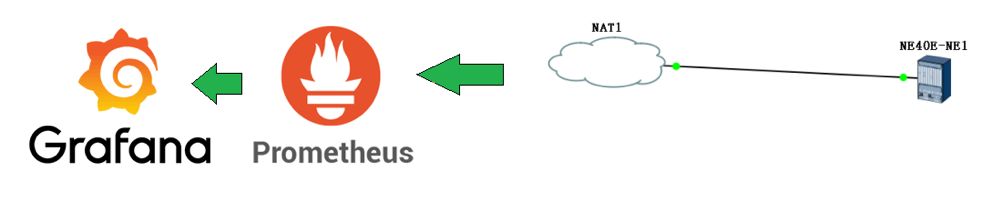
1、以华为NE40E路由器的静态订阅为例,采集cpu和内存信息,最终推送至prometheus中并用Grafana展示:
网络结构:
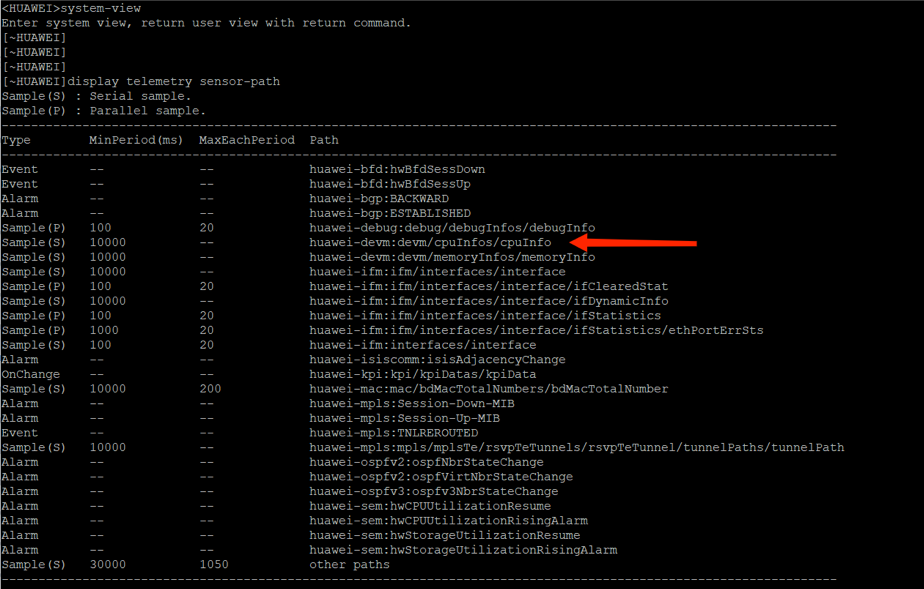
2、在路由器上使用system-view命令进入视图,再使用display telemetry sensor-path查看本设备支持的采样路径,确定对应指标的sensor-path:
不同的sensor-path代表了不同的指标:
3、使用telemetry命令进入telemetry视图,按如下命令配置静态订阅:
配置静态订阅:

4、在设备端,配置telemetry服务器。首先需要华为官方提供的proto文件作为解码的工具,链接附在本文文末。使用命令行或是开源的run_codegen.py脚本利用proto文件生成python代码。
所需对应的proto文件以及run_codegen脚本:

huawei-devm.proto(部分):

动态加载来解析数据:
5、服务器代码
from concurrent import futures
import time
import grpc
from proto_file import huawei_grpc_dialout_pb2_grpc
from proto_file import huawei_telemetry_pb2
import prometheus_client
from prometheus_client import Gauge
from prometheus_client.core import CollectorRegistry
import requests
import importlib
SERVER_ADDRESS=" "
PUSHGATEWAY_ADDRESS=" "
_ONE_DAY_IN_SECONDS = 60 * 60 * 24
registry = CollectorRegistry(auto_describe=False)
gaugeMap={}
def serve():
# 创建一个grpc server对象
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
# 注册huawei的telemetry数据监听服务
huawei_grpc_dialout_pb2_grpc.add_gRPCDataserviceServicer_to_server(
TelemetryCpuInfo(), server)
server.add_insecure_port(SERVER_ADDRESS)
# 启动grpc server
server.start()
# 死循环监听
try:
while True:
print("running------")
time.sleep(_ONE_DAY_IN_SECONDS)
except KeyboardInterrupt:
server.stop(0)
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError,ValueError):
pass
return False
def toPushgateway(labelValue,parseData,count):
labels = ["product_name","subscription_id_str","sensor_path","node_id_str"]
jobName = "pushgateway"
url=PUSHGATEWAY_ADDRESS
param=""
for i in str(parseData).split("\n"):
if '{' in i :
string = "".join(i.replace('{','_').split())
param+=string
continue
if ':' in i:
save=param
key = param+i.split(':')[0].strip()
value = i.split(':')[1].strip()
if is_number(value):
key+=str(count)
print("keys:"+key)
if key in gaugeMap.keys():
g=gaugeMap.get(key)
else:
g = Gauge(key,"",labels,registry=registry)
gaugeMap[key]=g
g.labels(product_name=labelValue[0],
subscription_id_str=labelValue[1],
sensor_path=labelValue[2],
node_id_str=labelValue[3]).set(float(value))
requests.post("%s/job/%s" %(url,jobName),
data=prometheus_client.generate_latest(registry))
param=save
continue
# 创建类继承huawei_grpc_dialout_pb2_grpc中Servicer方法
class TelemetryCpuInfo(huawei_grpc_dialout_pb2_grpc.gRPCDataserviceServicer):
def __init__(self):
return
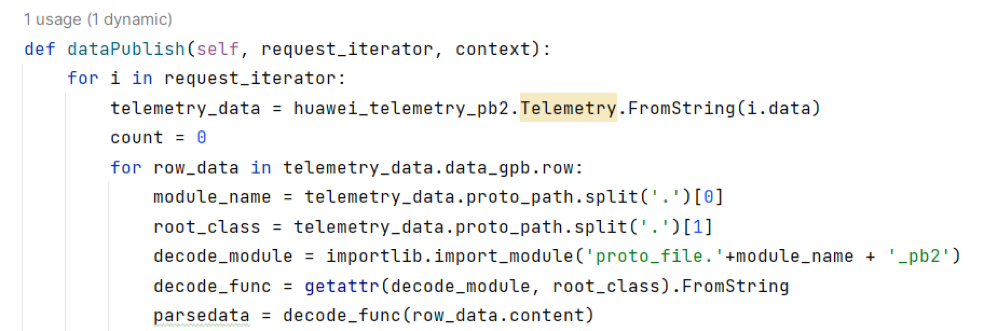
def dataPublish(self, request_iterator, context):
for i in request_iterator:
print('############ start ############\n')
telemetry_data = huawei_telemetry_pb2.Telemetry.FromString(i.data)
print(telemetry_data)
labels = [telemetry_data.product_name,
telemetry_data.subscription_id_str,
telemetry_data.sensor_path,
telemetry_data.node_id_str]
count = 0
for row_data in telemetry_data.data_gpb.row:
print('-----------------')
print('The proto path is :' + telemetry_data.proto_path)
print('-----------------')
module_name = telemetry_data.proto_path.split('.')[0]
root_class = telemetry_data.proto_path.split('.')[1]
decode_module = importlib.import_module('proto_file.'+module_name + '_pb2')
# 定义解码方法:getattr获取动态加载的模块中的属性值,调用此属性的解码方法FromString
decode_func = getattr(decode_module, root_class).FromString
parsedata = decode_func(row_data.content)
print('----------- content is -----------\n')
print(parsedata)
print(type(parsedata))
toPushgateway(labelValue=labels,parseData=parsedata,count=count)
count+=1
print('----------- done -----------------')
if __name__ == '__main__':
serve()6、运行结果,可以实现对telemetry数据的解析和输出。
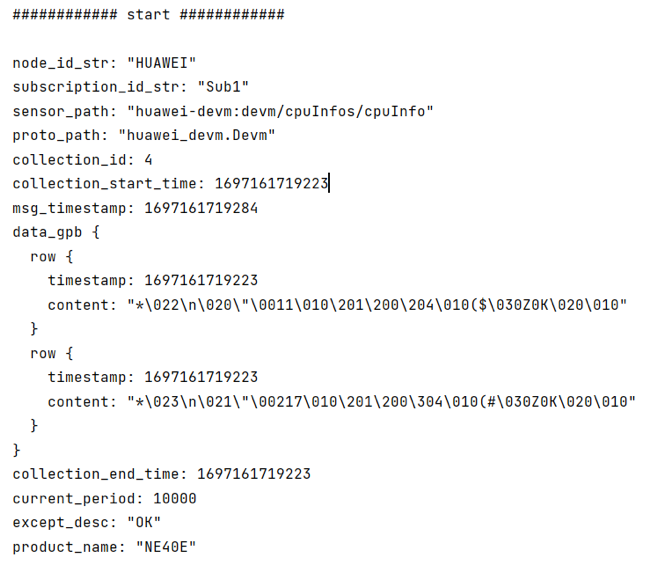
收集的数据-1:
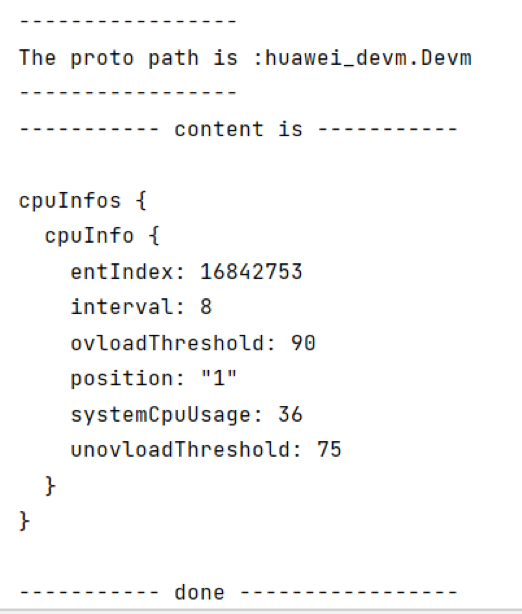
收集的数据--2:
收集的数据-3:
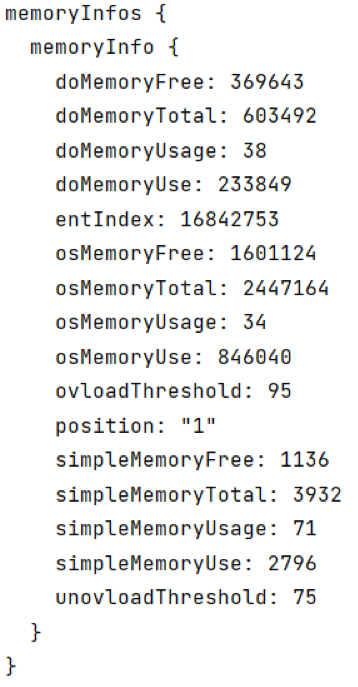
7、在路由器端可以通过display telemetry subscription + 订阅名称的命令查看订阅状态。
静态订阅相关信息:
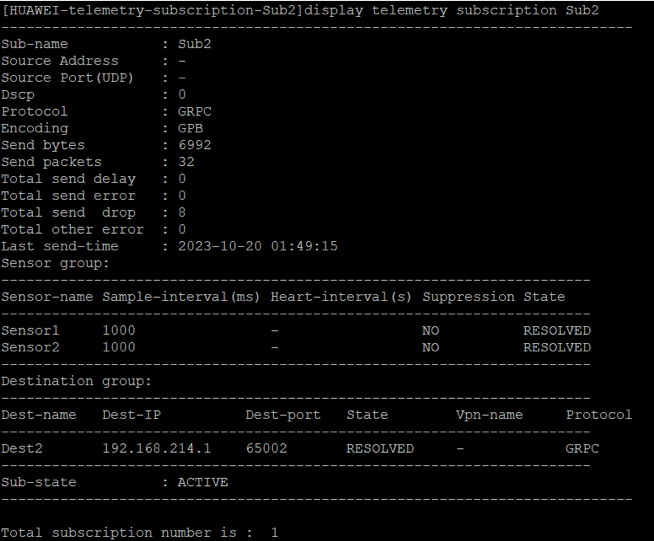
Grafana展示界面:
五、总结
作为新一代监控技术, Telemetry技术凭借其高扩展性和高实时性可以实现业务端到端的网络流量可视化,打破“网络黑盒”,为精细化网络运维提供整体的解决方案和必要的技术支撑,符合大型数据网络所的监控要求。但目前Telemetry技术仍存在一些局限,如:
-
不适合在中小型网络上使用,对庞大的数据流的处理需要更多的资源。
-
目前SNMP仍被许多种类型的网络设备支持:如打印机,路由器和服务器等,范围十分广泛;而不少在网络中旧设备和程序则不支持Telemetry技术。因统计原理存在差异,接口Telemetry统计和通过命令、MIB、PM查询到的统计数据可能不一致。
-
目前多个厂商之间也没有达成一致的指标路径和协议栈,如编码层面存在着XML、JSON和GPB;通信层面有gRPC、RestConf和Netconf等方式。
但面对大规模、高性能的网络监控需求,用户需要一种新的网络监控方式。Telemetry技术可以满足用户要求,支持智能运维系统管理更多的设备、监控数据拥有更高精度和更加实时、监控过程对设备自身功能和性能影响小,为网络问题的快速定位、网络质量优化调整提供了最重要的大数据基础,将网络质量分析转换为大数据分析,有力的支撑了智能运维的需要。可以预见的是,在未来的一段时间内,会出现多种新型的以Telemetry技术为核心的网络监控系统,其具有的细颗粒度和高精度的特点将为大数据网络环境下的监控提供新思路。





![[23] 4K4D: Real-Time 4D View Synthesis at 4K Resolution](https://img-blog.csdnimg.cn/2fe2494acd46467b84c20b186df5f5a1.png)