背景
以 ES 存储日志,且需要对日志进行分页检索,当数据量过大时,就面临 ES 万条以外的数据检索问题,如何利用滚动检索实现这个需求呢?本文介绍 ES 分页检索万条以外的数据实现方法及注意事项。
需求分析
用 ES 存储数据,分页检索,当 ES 数据量过大时,在页面上直接点击最后一页时,怎么保证请求能正常返回?
常规思路就是,超过万条以后,使用滚动检索,但需要注意:编写滚动检索的分页查询时,滚动请求的 size 一定不能用页面分页参数的 pageSize ,要能快速滚动到目标页所在的数据,最好以 ES 最大检索窗口值。
算法要点
第一,滚动检索的 Request 请求不能包含 from 属性, 且设置了 size 参数后,以后的每次滚动返回的数据量都以 size 为主。
第二,滚动获取数据的 size 选取。 滚动分页检索高效的关键是不能以页面分页参数 pageSize 作为滚动请求的 size ,而是以一个较大的数,或者直接以 ES 默认的滚动窗口最大值 10000 作为每批次获取的数据量。
第三,计算目标页的数据所在的位置。
- 根据分页参数计算出目标数据的位置是
[(pageSize-1)*pageSize, pageSize * pageNo],为了拿到目标页的数据,总共的数据量total = pageNo * pageSize。 - 目标数据在最终数据中的真正范围决定因素:
mode = total % 10000。 - 计算滚动请求几次能拿到目标数据。实际需要滚动请求的次数
scrollCount = mode == 0 ? total/ esWindowCount : (total/ esWindowCount + 1)。 - 目标页的数据有没有分布在两次请求中。当
10000 % pageSize !=0时,说明这一页的数据会横跨两次 ES 请求。例如pageSize =15,pageNo = 2667,total = 40005,目标页的数据包含在最后两次请求中,倒数第二次请求中有 10 条数据,最后一次请求中有 5 条数据,合起来才是一整页的 15 条数据。 - 最后一页数据不足 pageSize 时,最后一页数据真正的长度。
第四,分页数据所在范围处理。 当最后一批次获取到数据后,从中摘出目标页的数据时,需要考虑的四种情况,主要是 mode 和最终获取的数据总长度直接的关系:
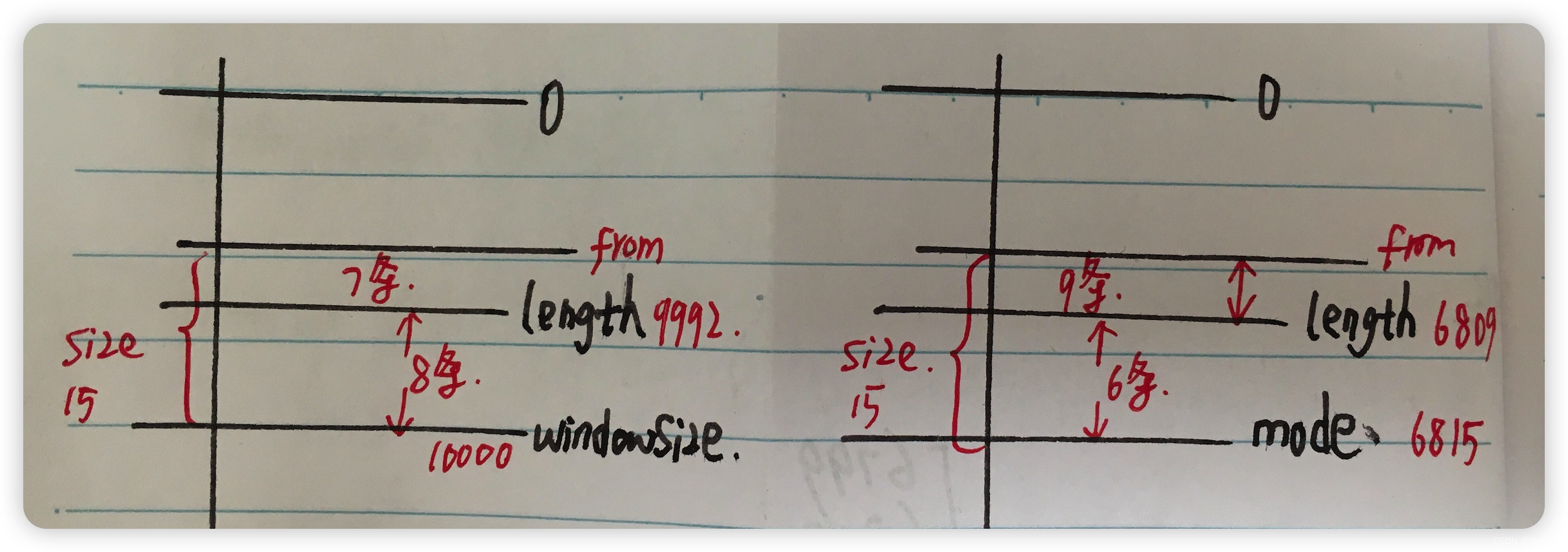
case 1:上图左,mode=0 时存在最后一页不足 size 的情况,realSize = size - (windowSize-length) 。
case 2:上图右,length < mode 时,最后一页不足 size 的情况,realSize = size - (mode -length) 。
最终的数据区间是 [from,to ] = [ length -realSize,length -1 ]。
数据总长度 = end -start +1 = realSize 。
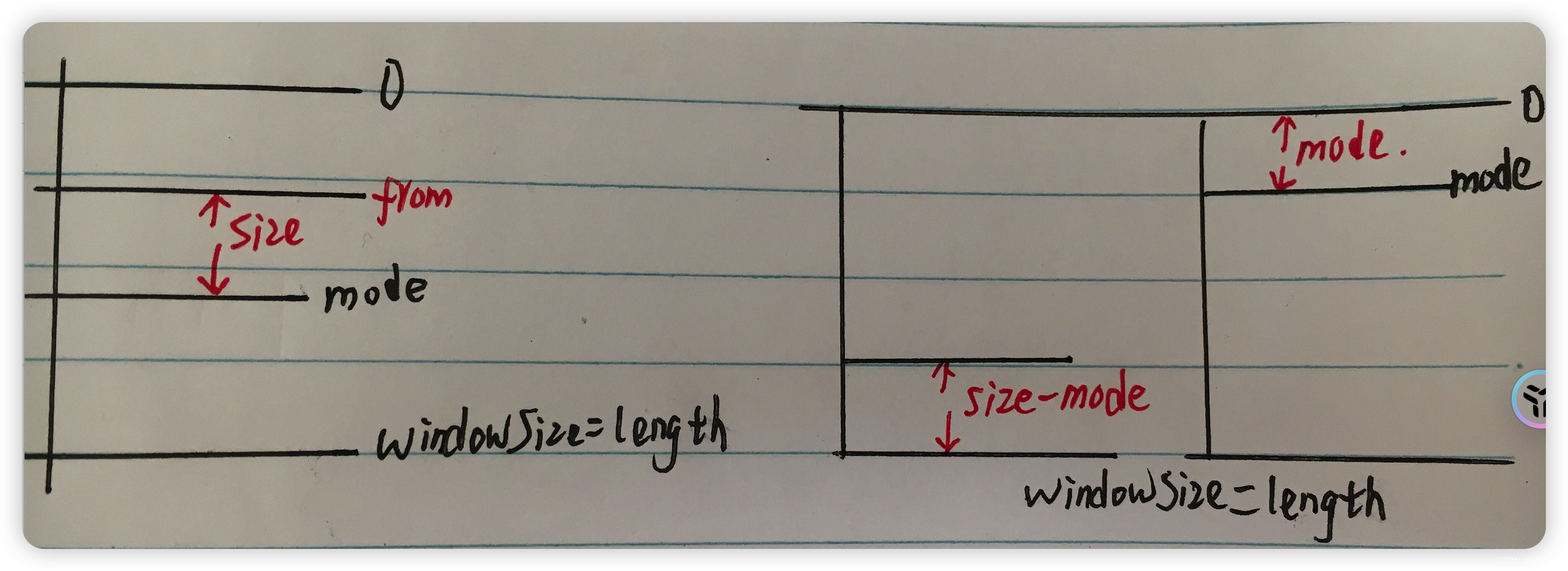
case 3 :上图左,分页数据在 mode 往前推 size 条。
case 4:上图右,分页数据横跨两次请求,两批数据组合成一页数据。
编码实现
编写 ES 滚动分页检索请求,处理超过万条之外的查询操作:
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.ClearScrollRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.*;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.SearchModule;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.*;
@Slf4j
public class EsPageUtil {
/**
* 真正的 ES 连接对象
*/
private RestHighLevelClient client;
public void initClient() {
// TODO 初始化 client 对象
}
/**
* 使用 DSL JSON 配置创建检索请求 Builder
* @param queryJson
* @return
*/
public SearchSourceBuilder createSearchSource(String queryJson) {
if (StringUtils.isEmpty(queryJson)) {
log.error("ElasticSearch dsl config is empty.");
return null;
}
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
try {
SearchModule searchModule = new SearchModule(Settings.EMPTY, false, Collections.emptyList());
NamedXContentRegistry registry = new NamedXContentRegistry(searchModule.getNamedXContents());
XContentParser parser = XContentFactory.xContent(XContentType.JSON).createParser(registry, LoggingDeprecationHandler.INSTANCE, queryJson);
searchSourceBuilder.parseXContent(parser);
return searchSourceBuilder;
} catch (Exception e) {
log.error("Parse dsl error.", e);
return null;
}
}
/**
* ES 分页查询:区分万条以内还是万条以外
* @param pageSize 分页size
* @param pageNo 查询页数
* @param indices 目标索引
* @param queryJson 查询 DSL JSON 格式字符串
* @return
*/
public Map<String, Object> queryByPage(int pageSize, int pageNo, String[] indices, String queryJson) {
SearchSourceBuilder searchSourceBuilder = createSearchSource(queryJson);
if (searchSourceBuilder == null) {
return null;
}
// 创建请求对象
SearchRequest searchRequest = new SearchRequest(indices).source(searchSourceBuilder);
Map<String, Object> result = new HashMap<>();
List<Map<String, Object>> data = null;
int total = pageSize * pageNo ;
int maxEsWindow = 10000;
try {
if (total <= 10000) {
// 万条以内,直接查询:设置 from , size 属性
searchSourceBuilder .from((pageNo - 1) * pageSize) .size(pageSize);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
data = parseResponseToListData(response);
} else {
// 万条以外,以 ES 最大窗口值查询:只设置size 属性
searchSourceBuilder.size(maxEsWindow);
data = scrollQuery(maxEsWindow, pageSize, total, searchRequest);
}
} catch (IOException e) {
log.error("ElasticSearch query error.", e);
}
result.put("total" , 0);
result.put("data" , data);
return result;
}
/**
* 滚动查询
*
* @param esWindowCount
* @param pageSize
* @param total
* @param searchRequest
* @return
*/
private List scrollQuery(int esWindowCount, int pageSize, int total , SearchRequest searchRequest) {
List pageData = new ArrayList(pageSize);
//创建滚动,指定滚动查询保持的时间
final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(10L));
//添加滚动
searchRequest.scroll(scroll);
//提交第一次请求
SearchResponse searchResponse = null;
String scrollId = null;
try {
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取滚动查询id
scrollId = searchResponse.getScrollId();
} catch (IOException e) {
log.error("Elasticsearch request error.", e);
return pageData;
}
int counter = 2;
int mode = total % esWindowCount;
int realPageCount = mode == 0 ? total/ esWindowCount : (total/ esWindowCount + 1);
while (counter <= realPageCount) {
// 设置滚动查询id,从id开始继续向下查询
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
// 重置查询时间,若不进行重置,则在提交的第一次请求中设置的时间结束,滚动查询将失效
scrollRequest.scroll(scroll);
// 提交请求,获取结果
try {
searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("Elasticsearch scroll request error.", e);
}
// size 非 10 的整数,则当前页数据横跨两个 Scroll 请求
if (mode != 0 && mode < pageSize && counter == (realPageCount -1)) {
collectFirstPart(searchResponse, pageData, mode, pageSize);
}
// 更新滚动查询id
scrollId = searchResponse.getScrollId();
counter++;
}
// 收集最后一次响应结果中的数据
collectPageData(searchResponse, pageData, mode, pageSize, esWindowCount);
// 滚动查询结束时,清除滚动
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
try {
client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("Elasticsearch clear scroll info error.", e);
}
return pageData;
}
/**
* @param searchResponse
* @param mode
* @param size
* @return
*/
public void collectFirstPart(SearchResponse searchResponse, List<Map<String, Object>> firstPartData, int mode, int size) {
int firstPartCount = size - mode;
// 只截取响应结果中的 结尾 size - mode 部分的内容
SearchHits hits = searchResponse.getHits();
SearchHit[] dataList = hits.getHits();
int from = dataList.length - firstPartCount;
for (int i = from; i < dataList.length; i++) {
firstPartData.add(dataList[i].getSourceAsMap());
}
log.info("Mode less than size, first part data is here {} .", firstPartCount);
}
/**
* 滚动到最后一组数据中包含目标页的数据,从中摘出来
* @param searchResponse
* @param mode
* @param size
* @param esWindowCount
* @return
*/
public void collectPageData(SearchResponse searchResponse, List<Map<String, Object>> pageData, int mode, int size, int esWindowCount) {
SearchHits hits = searchResponse.getHits();
SearchHit[] dataList = hits.getHits();
int from = 0;
int length = dataList.length;
if (mode == 0) { // 刚好在万条结尾
// 不够一页
if (length < esWindowCount) {
int realSize = size - (esWindowCount - length);
from = (length - realSize ) >= 0 ? (length - realSize ) : 0;
} else {// 总长够一页
from = length == esWindowCount ? (length - size) : 0;
}
} else if (length < mode){ // 最后一页且总长不足 size
int realSize = size - (mode - length);
from = (length - realSize) >= 0 ? (length - realSize) : 0;
} else if (mode > size){ // 中间部分
from = (mode - size) >= 0 ? (mode -size) : 0;
} else { // mode < size ,说明是一页数据的下半部分
from = 0;
size = mode;
log.info("Page data is across two request ,this response has {} .", mode);
}
// 收集目标数据
for (int i = from; i< from + size && i < length; i++) {
pageData.add(dataList[i].getSourceAsMap());
}
}
/**
* 解析 ES 响应结果为数据集合
* @param response
* @return
*/
public static List<Map<String, Object>> parseResponseToListData(SearchResponse response){
List<Map<String, Object>> listData = new ArrayList<>();
if (response == null) {
return listData;
}
// 遍历响应结果
SearchHits hits = response.getHits();
SearchHit[] hitArray = hits.getHits();
listData = new ArrayList<>(hitArray.length);
for (SearchHit hit : hitArray) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
listData.add(sourceAsMap);
}
// 返回结果
return listData;
}
}
启示录
滚动查询时优化了 size 用一万,相比用页面的分页参数 pageSize ,可以解决数据量过大时,直接从页面点击最后一页导致页面卡死长时间无响应的问题。
页面分页参数最大不过 100,当总数量几百万、pageSize=10,分页跳转查询后面某页 如 3000 时,ES 的滚动请求次数 是 3000 次,而优化后滚动请求 3次,第三次中的一万条数据的最后10条即本页的数据。
话说回来,ES 数据量过大时,用分页查询靠后的数据时,也没多大的价值了,列表宽泛条件查询结果过大时,谁看得过来呢?



![[23] 4K4D: Real-Time 4D View Synthesis at 4K Resolution](https://img-blog.csdnimg.cn/2fe2494acd46467b84c20b186df5f5a1.png)