又到一年大促时刻,今天我们一起探讨下JVM垃圾回收的问题,写代码的时候想一想如何减少FullGC问题的出现,因为一旦出现频繁FullGC,短时间内没有太好的解决办法,很有可能重启后服务接着FullGC,导致服务可用率降低,只能改代码,走上线流程,这个过程很耗时。
首先我们来看一个经典问题,下图中这个sleep(0)有什么作用?
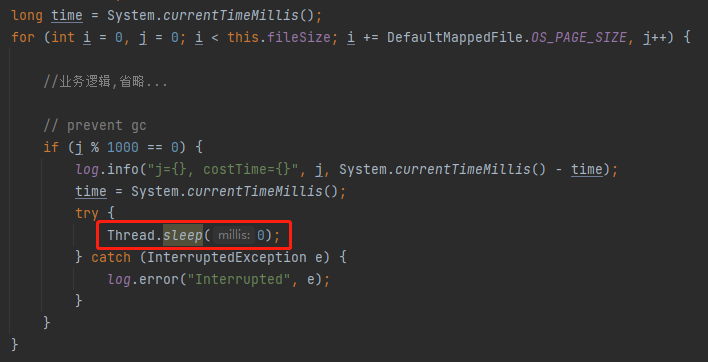
注释里面有一个prevent gc, 是想要阻止jvm gc执行吗? 下面我们一起来进入jvm gc知识的探索之旅
一、前言
目前JVM主流的GC收集器有 Serial、Parallel 、CMS、G1,以及比较新的 ZGC和 Shenandoah, ZGC是 jdk 11中推出的垃圾回收器, 以及jdk17中的仙纳度Shenandoah 回收器。
具体又分为分代收集器和跨代收集器, 传统的收集器都是基于分代收集的,一般又被分为新生代和老年代收集器
新生代有:
1、Serial
2、ParNew
3、Parallel Scavenge
老年代有:
1、Serial Old
2、CMS
3、Parallel Old
G1属于跨代收集,既可以回收新生代、又可以回收老年代,这种一般称为Mixed GC
各种回收器需要搭配使用新生和老年代GC具体使用哪种组合可以参考如下图
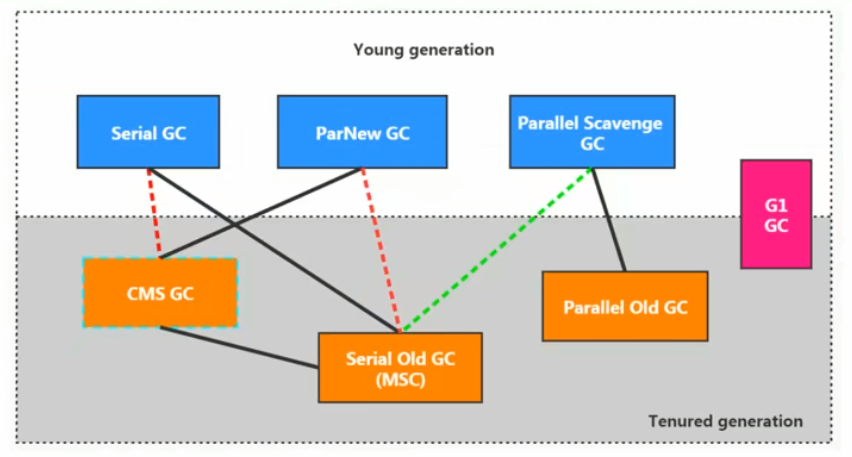
其中用的比较多的是Parallel Scavenge + Parallel Old 和 ParNew + CMS的组合。
我们评判GC收集器好坏的指标主要有吞吐量(Throughout)、延迟(Latency)、以及内存占用(FootPrint)
CMS 更注重低延迟、Parallell更注重吞吐量,一般互联网企业为了更好的用户体验、减少页面停顿、延迟等情况,所以大多数采用CMS,后台定时任务类的、批处理类的可以采用Parallel,上面提到的仙纳度的延迟是目前最低的,官方预期是10ms以内,实际并未达成这个指标,但是已经远远低于目前所有的GC回收器了,其缺点是吞吐量变的较差。
至于G1和CMS 选哪一个?Oracle官方没有特别说明,一般G1适合大内存的场景,以6G~8G为界限, G1至少需要8G(注:数据来源周志明深入理解java虚拟机)以上的内存空间,8G以内使用CMS有更好的性能,因为G1是分布式回收,需要更多的额外空间去追踪和记录跨代引用,而CMS只需要一份卡表记录新生代和老年代的跨代引用,所需空间较少。
总结一下第一段文章概要: 面向用户类的应用使用ParNew +CMS, 纯后台类的应用可采用 Parallel scavenge + Parallel Old,如果内存比较大的应用可以采用G1,但由于这些年互联网发展的原因,所以CMS这种低延迟的收集器更加出名
二、GC 算法
目前主流的垃圾回收器,主要有三种GC算法,万变不离宗。
1、标记清理mark-sweep
标记清理算法,首先从GC Roots开始遍历标记哪些对象是可达对象,哪些是不可达对象,对于不可达的对象进行清理,此过程由于不需要整理碎片,相对较快,但是缺点也很明显就是多次GC后会产生大量的内存碎片,可能导致后续无连续的、满足新对象大小要求的内存空间。
2、标记复制mark-copy
复制算法,将内存空间分为两半,每次只使用其中一半。第一步与mark-sweep算法一样,都是标记出可达的对象,第二步将存活的对象copy到另一半空间中,由于新生代大多数都是早生夕灭的(标价线上数据为1%),所以只需要将极少量的存活对象拷贝到另一块规整的空间,速度极快,同时也没有碎片的产生。缺点是内存使用率太低了,只有一半空间被使用。所以在实际工程实现时,一般是 Eden+两个Survivor,每次GC时将存活对象以及其中一个Survivor的对象复制到另一个里面。
3、标记整理mark-compact
标记整理算法,标记过程与标记清理算法一样,然后将存活对象移动到一端,形成比较规整的使用空间,然后将边界外的其他对象全部清理掉
上面解释标记过程时,提到了GC Roots,一般哪些对象可以作为GC Roots呢? 主要有四类
1、虚拟机栈中引用的对象
2、方法区中类静态属性引用的对象
3、方法区中常量引用的对象
4、本地方法栈中 Native 方法引用的对象
三、GC 分类
我们以目前业界用的比较多的 ParNew + CMS为例,介绍下具体的GC过程
要使用CMS,需在jvm 参数中配置 XX:+UseConcMarkSweepGC , 此时新生代会默认使用 ParNew回收器, 也可以通过-XX:+UseParNewGC设置,ParNew其实就是Serial的多线程版本,ParNew 从JDK8开始只能与CMS组合使用
1、Young GC
YGC是对新生代区域的垃圾回收,新生代一般被分为Eden + Survivor0 + Survivor1,用户程序申请内配一般在Eden区域中分配,所以Eden区域空间不足就会触发YGC
我们摘取一个线上的实际YoungGC日志,详细讲解:
GC (Allocation Failure )说明Eden空间不足,需要运行一次GC回收部分空间才能继续
2023-05-24T15:43:34.135+0800: 68146.524: [GC (Allocation Failure) 2023-05-24T15:43:34.135+0800: 68146.524: [ParNew: 1700513K->15245K(1887488K), 0.0319933 secs] 2103649K->420192K(3984640K), 0.0323417 secs] [Times: user=0.10 sys=0.00, real=0.03 secs]
可以看到新生代使用了ParNew 回收器,回收前占用空间 1700513K,大约是1.6GB,回收后使用15245KB, 大约是 14.8MB,即回收了超过99%的空间,这是因为新生代里面的对象绝大多数都是朝生夕灭,这时候使用复制算法效率更高,只需将小于1%的对象复制到 Survivor0即可,相比其他GC算法,其效率是最高的。
新生代的运行时长0.0319933秒,即31.9ms,这算一个比较中规中矩的耗时,时间越短延迟越低,对用户体验越好
日志详情:

2、FULL GC
Full GC是全堆GC,包含了对新生代、老年代、元空间(JDK 8)的回收
老年代不够用会触发FullGC,以CMS为例,一般有调用system.gc(), promotion failure 和 concurrent mode failure 、元空间耗尽等情况会触发FullGC,其中system.gc并不一定会执行gc,当然我们执行heapdump命令时也会触发FullGC,注意CMS 本身并不等于FullGC,只有Stop the world的阶段会被统计到FullGC里面
3.2.1大对象直接存放Old空间不足够
当我们创建一个大对象时,如果Young区放不下,会直接放入Old区, 若Old区也放不下,则会触发FullGC
3.2.2 promotion failure
是指新生代晋升到老年代时,发现老年代可用的空间不足,此时会触发FGC
3.2.3 concurrent mode failure
[Full GC (Allocation Failure) 146457.242: [CMS146458.731: [CMS-concurrent-mark: 1.994/2.013 secs] [Times: user=3.08 sys=0.21, real=2.02 secs]
(concurrent mode failure): 2048000K->2047999K(2048000K), 7.7277036 secs] 4351992K->4185797K(4352000K), [Metaspace: 219216K->219216K(1263616K)], 7.7287222 secs] [Times: user=7.71 sys=0.03, real=7.73 secs]
CMS 回收老年代时,GC线程和用户线程是并行执行的,在并发过程中产生的新生代晋升至Old区对象没有足够Old空间,这部分对象叫做浮动垃圾,然后GC将启用备用的Serial Old回收器回收,至于为什么使用Serial Old呢? 是因为他是串行的,全过程都会Stop The World,在GC过程中不会再生成新的晋升对象,但是也意味着将迎来更大的停顿时间,延迟更高,用户体验更差。
针对上面两种场景有,CMS有几个常用参数可以进行调优
-XX:CMSInitiatingOccupancyFraction,该阈值控制老年代达到多少使用率时开始FULLGC, JDK6默认92%, 一般设置成80%左右比较合理,否则一是延迟可能较高,二是浮动垃圾可能空间不足
XX:+UseCMSInitiatingOccupancyOnly,指定用设定的回收阈值,和上面的参数一起使用
-XX:+UseCMSCompactAtFullCollection,在FULLGC前进行内存整理
XX:CMSFullGCBeforeCompaction=n,表示进行多少次FULLGC后,下一次FULLGC前需要整理碎片,默认0,也就是每次都整理碎片
上述参数只能减轻FullGC的频率,还是需要从根本上排查为何FullGC,一般大循环、打印大日志、无限递归、大文件导入等都可能产生FullGC
3.2.4 MetaSpace扩容引发的FULLGC
MetaSpace 在jdk 8中是元空间, Oracle 从jdk8开始引入元空间,并去掉永久代, 永久代和元空间都是对方法区的一种实现方式
MetaSpace空间不足一般会报: java.lang.OutOfMemoryError: Metaspace 异常
jvm中有两个参数,分别代表了MetaSpace 的初始大小和最大大小, 当元空间的使用空间超过了MetaSpaceSize就会触发FULLGC,此时并非空间真的不够用了(见下图2)
一个比较常见的导致MetaSpace扩容的场景是代码中使用了大量反射、字节码增加、动态脚本(如 Groovy)等技术,可以Dump 下内存文件,使用MAT工具分析下具体是什么原因导致的
-XX:MetaspaceSize=256m ,默认大小21M
-XX:MaxMetaspaceSize=512m,默认无穷大


图2. metaspace扩容FGC
针对MetaSpace扩容导致的FULLGC,我们可以通过合理设置MetaspaceSize大小来降低扩容频率,但是如果代码中使用了大量的动态脚本(如groovy)、反射、字节码增强(Cglib
)技术,系统运行时间一长必然会导致出现元空间扩容的问题,这个短时间不太好解决,也只能调调jvm参数,治标不治本,这也是为什么大促前夕我们都会组织大家重启应用,平时每周上线掩盖了问题,大促期间长时间不上线,导致大量问题涌现。
具体设置多大,需要根据业务场景不停调整,可以通过jstat -gc pid查看目前使用大小,UMP的jvm监控也可以直接查看

MC: 是元空间capacity
MU: 是元空间Used大小
你也可以使用jmap 查看内存的占用大小 jmap -histo pid
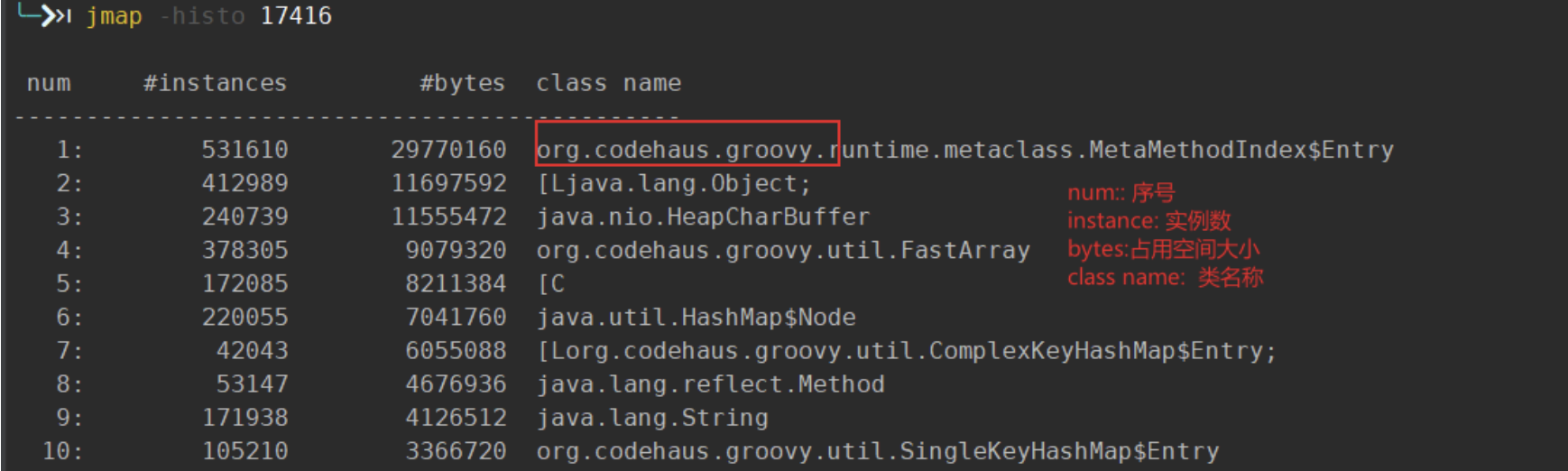
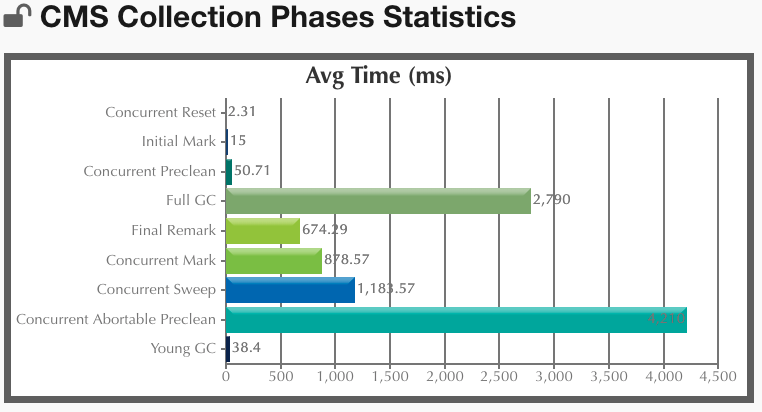
CMS GC的日志,可以看到大体有7个阶段,一般我们记住下面标红的四个阶段即可
1.Initial Mark--第一次STW
2.Concurrent Mark
3.Concurrent Preclean--并发预清理
4.Concurrent Abortable Preclean--可中止的并发预清理
5.Final Remark -- 第二次STW
6.Concurrent Sweep
7.Concurrent Reset
下图对比了线上环境一次 FullGC各个阶段的的平均耗时对比
2023-05-24T15:45:38.743+0800: 68271.132: [GC (CMS Initial Mark) [1 CMS-initial-mark: 196063K(2097152K)] 198799K(3984640K), 0.0044817 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
2023-05-24T15:45:38.748+0800: 68271.137: [CMS-concurrent-mark-start]
2023-05-24T15:45:38.955+0800: 68271.344: [CMS-concurrent-mark: 0.204/0.207 secs] [Times: user=0.46 sys=0.02, real=0.21 secs]
2023-05-24T15:45:38.956+0800: 68271.345: [CMS-concurrent-preclean-start]
2023-05-24T15:45:38.964+0800: 68271.353: [CMS-concurrent-preclean: 0.008/0.009 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2023-05-24T15:45:38.965+0800: 68271.353: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2023-05-24T15:45:44.057+0800: 68276.446: [CMS-concurrent-abortable-preclean: 0.462/5.092 secs] [Times: user=1.35 sys=0.13, real=5.09 secs]
2023-05-24T15:45:44.059+0800: 68276.448: [GC (CMS Final Remark) [YG occupancy: 294214 K (1887488 K)]2023-05-24T15:45:44.059+0800: 68276.448: [GC (CMS Final Remark) 2023-05-24T15:45:44.059+0800: 68276.448: [ParNew: 294214K->6800K(1887488K), 0.0135495 secs] 490278K->202863K(3984640K), 0.0137981 secs] [Times: user=0.04 sys=0.00, real=0.02 secs]
2023-05-24T15:45:44.073+0800: 68276.462: [Rescan (parallel) , 0.0073520 secs]2023-05-24T15:45:44.080+0800: 68276.469: [weak refs processing, 0.0027962 secs]2023-05-24T15:45:44.083+0800: 68276.472: [class unloading, 0.0558081 secs]2023-05-24T15:45:44.139+0800: 68276.528: [scrub symbol table, 0.0672720 secs]2023-05-24T15:45:44.206+0800: 68276.595: [scrub string table, 0.0026745 secs][1 CMS-remark: 196063K(2097152K)] 202863K(3984640K), 0.1500836 secs] [Times: user=0.20 sys=0.00, real=0.15 secs]
2023-05-24T15:45:44.210+0800: 68276.598: [CMS-concurrent-sweep-start]
2023-05-24T15:45:44.275+0800: 68276.664: [CMS-concurrent-sweep: 0.061/0.066 secs] [Times: user=0.18 sys=0.03, real=0.07 secs]
2023-05-24T15:45:44.276+0800: 68276.665: [CMS-concurrent-reset-start]
2023-05-24T15:45:44.279+0800: 68276.668: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
四、GC 调优
JVM GC回收器调优的目的是找出和解决Java程序中内存使用方面的问题,以提高程序的性能和稳定性。GC调优可以通过以下方式达到目的:
a、减少GC的发生次数,减少GC暂停时间
b、控制堆的大小,避免OOM错误
c、平衡新生代和老年代之间的内存分配,避免不必要的复制或移动
d、选择合适的GC算法和回收器,以满足程序的需求。
本章只做调优的一些基础知识介绍,我们将在系列(二)中详细教大家如何使用各类工具进行调优。
1 、调优工具
基本的一些GC调优工具如下:
•jstat:查看GC信息
•jmap:导出堆转储快照
•jvisualvm:可视化分析工具
•GC日志:分析GC过程
还有一些在线的分析工具如gceasy.io,也可以导入gc日志进行分析,上面的CMS各阶段耗时对比就是用该工具生成的
示例,我们可以通过如下命令查看 jvm 当前堆的使用情况
jstat -gc 进程ID interval
也可以使用此命令
jstat -gcutil 进程ID interval
2、堆大小设置
分析JVM设置前,我们需要通过设置启动参数开启GC日志记录。以下为常用的开启GC日志的参数:
•-XX:+PrintGC:打印GC日志
•-XX:+PrintGCDetails:打印详细的GC日志
•-XX:+PrintGCDateStamps:打印GC发生的时间戳
•-Xloggc:<file>:将GC日志输出到指定文件
一般会在指定目录下生成一个gc.log的文件
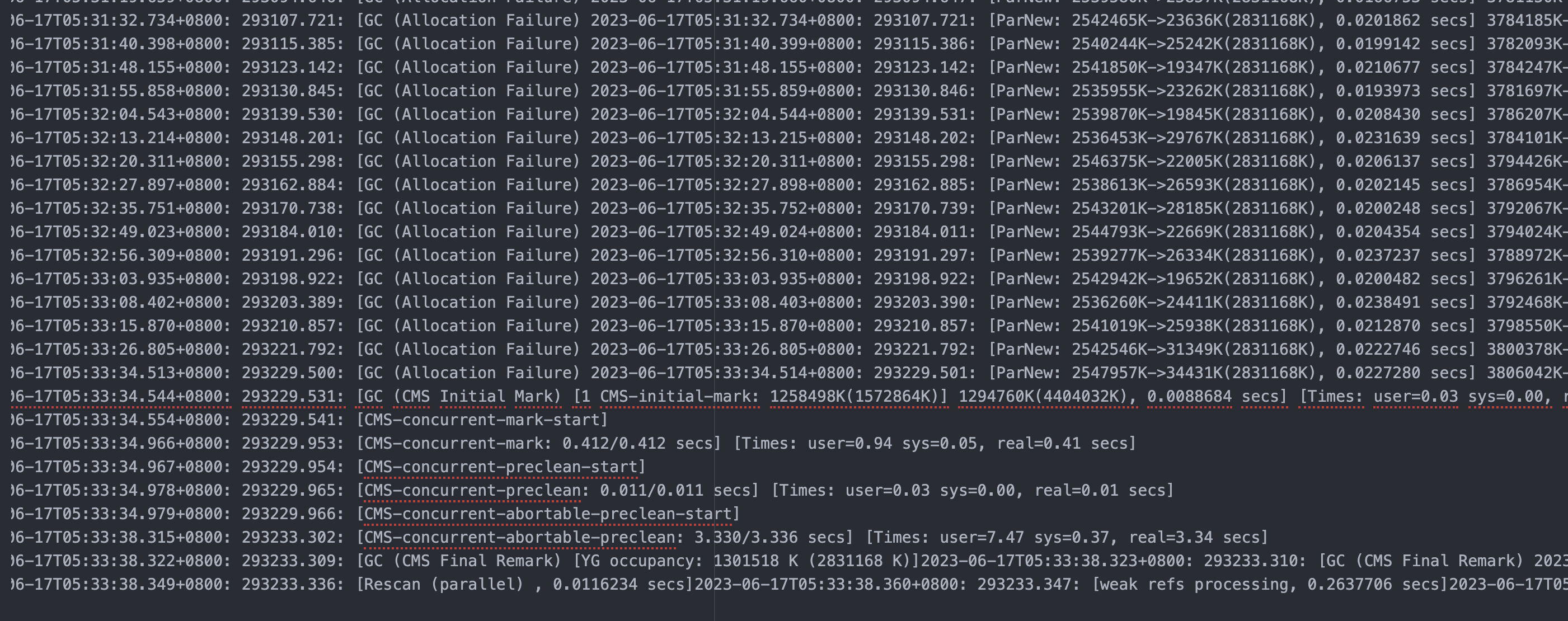
3、GC日志分析
如下是从线上抓取的一个GC日志格式
2023-06-17T12:27:54.052+0800: 318089.039: [GC (Allocation Failure) 2023-06-17T12:27:54.053+0800: 318089.040: [ParNew: 2613613K->82309K(2831168K), 0.0510894 secs] 3856214K->1358604K(4404032K), 0.0522928 secs] [Times: user=0.17 sys=0.00, real=0.05 secs]
其中,日志包括以下几个部分:
•时间戳:表示GC发生的时间
•GC类型:表示GC的类型,如Allocation Failure、Full GC等
•垃圾回收器和内存区域:表示哪种垃圾回收器和哪个内存区域被使用
•内存变化情况:表示GC前后堆和各个内存区域的大小变化
•耗时统计:包括用户态、系统态和实际耗时
如下日志中我们看到有promotion failed,说明是Old区空间不足导致的晋升失败,Old区回收后没有释放空间说明对象还在使用中,这种一般是超大对象(比如大List、文件导入等),大循环内部生成的对象,在循环没有结束前,reference还指向了对象,导致无法回收
[ParNew (promotion failed): 123896K->78505K(2831168K), 0.0604966 secs] 1400191K->1370332K(4404032K), 0.0612673 secs] [Times: user=0.17 sys=0.00, real=0.06 secs]
下面这是一个元空间使用达到MetaSpaceSize阈值,而触发的回收,这种一般就是动态加载的脚本或者增强的类过多导致,平时频繁上线容易掩盖问题,大促期间长时间不上线就容易曝出来
2023-06-06T17:45:14.132+0800: 12629.279: [Full GC (Metadata GC Threshold) 2023-06-06T17:45:14.132+0800: 12629.280: [CMS: 445957K->190564K(2097152K), 1.4345090 secs] 1855530K->190564K(3984640K), [Metaspace: 307068K->307068K(1437696K)], 1.5444585 secs] [Times: user=1.54 sys=0.00, real=1.55 secs]
元空间不足一定要关注,因为重启后一定会再次出现,Old区的FullGC很可能是临时的,一个大的循环执行完后,很可能短期内不再出现,但是元空间的不足却可能是长期的。对于Groovy这种脚本每次运行时GroovyClassLoader都会创建一个新的ScriptXXX类,并load它,字节码会一直停留在Method Area中,所以一定会出现内存泄漏、进而引发OOM。
解决方案也很简单,使用缓存机制,script编译后在本地缓存中缓存起来,当然你也可以用局部变量和弱引用解决,但这样每次还是会创建新的类,高并发场景下代价较大。
return concurrentHashMap.computeIfAbsent(scriptName, new Function<String, CompiledScript>() {
@SneakyThrows
@Override
public CompiledScript apply(String s) {
return ((Compilable) groovyEngine).compile(logicRule);
}
});
4、GC参数调整
一般我们会根据系统或项目的特性来调整如下的一些GC参数
•堆参数:包括堆大小、新生代和老年代比例等
8G内存的主机,堆大小可以设置成4G~5.5G,堆大小比如NewRatio默认=2,代表着新生代:老年代=1:2,也即新生代占堆区1/3,老年代占比2/3, 一般来说如果web端应用或者并发不是很高的应用,短时间不会产生大量新对象,这个参数是比较合理的,但是如果是worker类的应用,并发很高,大部分对象朝生夕灭,这些对象大部分不会进入到Old区,此时新生代可以调大一些,老年代调低些。另一个就是MetaSpace的调整,默认是21M,这个上面描述过了,这个值对于企业级的应用相对较小,可以调整到256MB或者512MB,另外MaxMetaSpaceSize默认无穷大,这个值也需要调整,设置512M即可。
•回收策略参数:包括串行回收器、并行回收器、并发标记清除回收器、G1回收器等;
对于小型应用,可以选择串行回收器(Serial GC),其优点是实现简单、CPU资源消耗低、停顿时间短,适合单核或者低配置的系统。
对于中大型应用,可以选择并行回收器(Parallel GC),其优点是可以利用多核CPU的资源、垃圾回收速度较快,适合高并发、大规模的系统。
对于需要低延迟、高并发的应用,可以选择并发标记清除回收器(CMS GC),其优点是停顿时间短、GC线程和内存占用较少,适合大型互联网系统。
•GC调优参数:包括执行垃圾回收的阈值、对象晋升的阈值、并发GC周期的触发条件等。
调整GC参数需要根据具体情况进行试验和验证,以达到最优状态。以下是一些常见的GC调优参数:
-XX:MaxTenuringThreshold:设置晋升年龄的阈值,默认15,一般不用动;
-XX:+UseConcMarkSweepGC:打开CMS垃圾回收器,适用于需要低延迟的场景;
-XX:CMSInitiatingOccupancyFraction:设置CMS回收的触发阈值,jdk8默认68%,jdk6默认92%,可以设置成80%左右;
-XX:G1HeapRegionSize:设置G1回收器中每个region的大小等。
-XX:+CMSScavengeBeforeRemark: 在Remark之前再进行一次YoungGC,减少OLD区的GC Roots对象数量
五、未来趋势
未来GC的发展趋势,一定是朝着更低的延迟这个目标进行,但是要通过什么样的手段实现低延迟呢?
1、并发收集
并发收集这个是从Parallel就开始采用的手段,包括后来的CMS、G1、ZGC等,目的就是降低STW的停顿时间,避免给用户体验造成影响
2、局部收集
未来技术实现上一定是朝着局部收集努力,例如G1、仙纳度的Region内存划分,因为随着技术的普惠、硬件成本的降低,你很难想象一个800G内存的机器,要怎么实现全堆扫描和回收,目前8G内存的机器,一次FullGC就会导致应用程序明显的停顿,造成接口的tp99严重飚高,用户会很明显地感觉到页面出现卡顿的现象。所以最新的Shenandoah和ZGC回收器的项目目标是实现10ms以内的停顿,虽然最终没能实现,但是已经远远低于常见的CMS、G1等常规低延迟的收集器了。
最后,我们来看一看前面的问题为什么要sleep(0)?
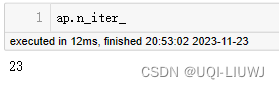
sleep(0)的作用,是GC有关, 真正的目的是让for循环中的代码进入SafePoint,只有到达安全点后GC进程才会开始执行,而int是可数循环,JVM做了一个特殊优化,整个可数循环范围内不会GC,这样便可能导致OOM,其实这里直接把 i 改成long型也能实现, 因为long是不可数循环,也会进入gc。
所以真正的目的不Prevent GC, 而是Prevent long time GC,让程序提前进入GC,这样每一次的GC pause time 会比较短,延迟较低, 用户不会感受到明显的卡顿现象,没有十年以上功底是写不出这样高深的代码的。