最近几年,Presto这个大数据组件越来越多地出现在程序员的岗位需求中,很多应届同学一番自我检查后发现,在学校都没怎么接触过,更不用说了解了。
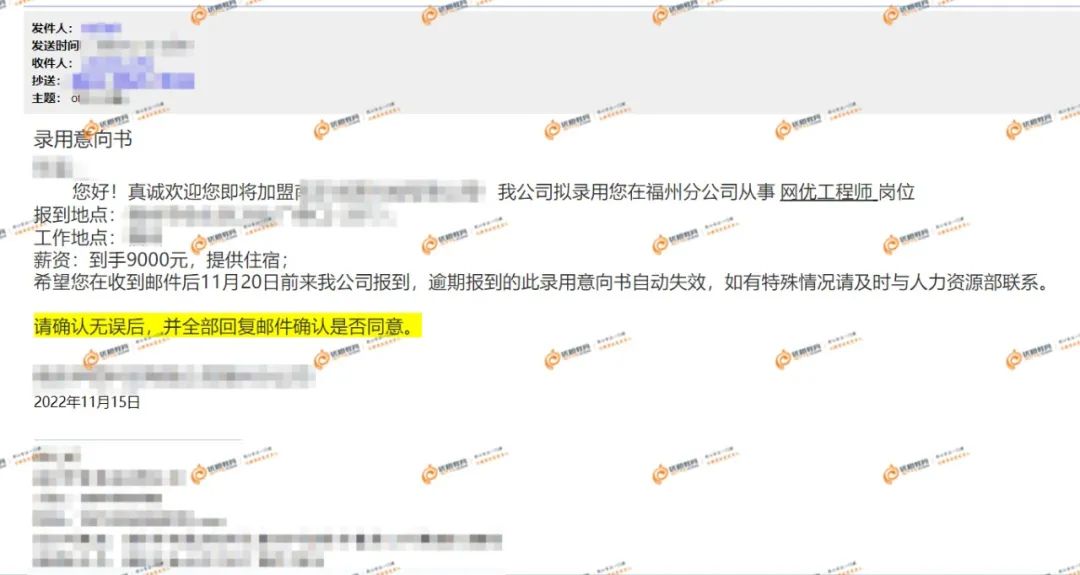
某游戏公司岗位需求
Presto到底是个啥? 有什么用? 适合哪些业务场景?本文带你了解入门。
01
Presto的出现
在2012年以前,Facebook依赖Hive做数据分析,而Hive底层依赖MapReduce,随着数据量越来越大,使用Hive进行数据分析的时间可能需要到分钟甚至小时级别,不能满足交互式查询的数据分析场景。
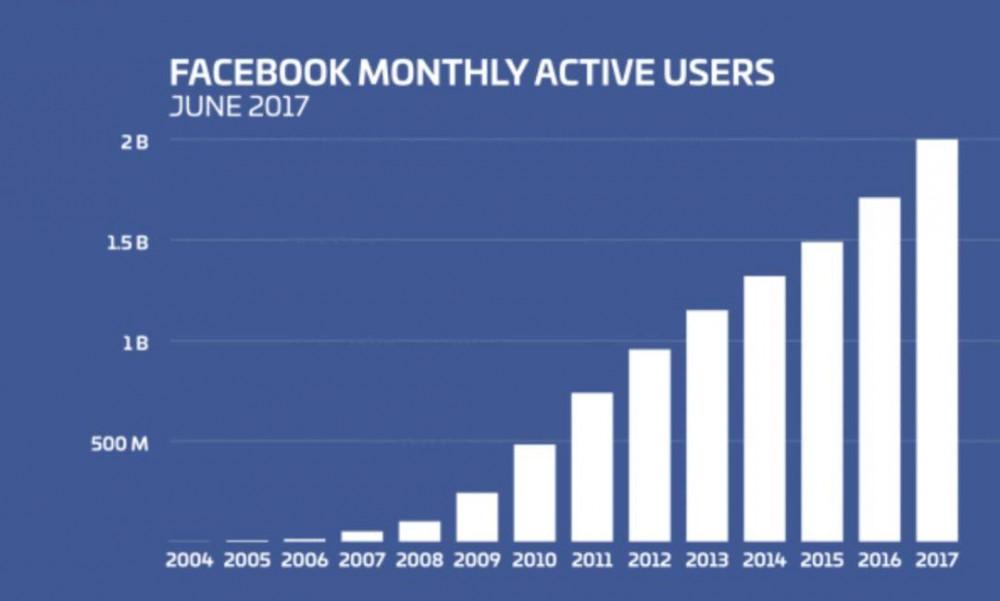
Facebook迎来用户增长后迫切需要解决数据量大带来的问题
于是Facebook研发了这款专为Hadoop打造的工具,适用于交互式分析查询,可支持众多的数据源,包括HDFS,RDBMS,KAFKA等,而且提供了非常友好的接口开发数据源连接器。针对GB-PB量级数据查询返回结果的速度可以达到秒级。
一句话:Presto是由 Facebook开源的大数据分布式SQL查询引擎,专为大规模商业数据仓库的交互式分析和秒级查询所设计。
我们需要注意的是:虽然Presto可以解析SQL,但它不是一个标准的数据库,不是MySQL、Oracle的代替品。
02
Presto的特点
多数据源
Presto可以支持MySQL、PostgreSQL、cassandra、Hive、Kafka等多种数据源查询。
支持SQL
Presto支持部分标准SQL对数据进行查询,并提供SQL shell进行SQL查询。但是Presto不支持存储过程,不适合大表Join操作,因为Presto是基于内存的,多张大表关联可能给内存带来压力。
扩展性
Presto有很好的扩展向,可以自定义开发特定数据源的Connector,使用SQL分析指定Connector中的数据。
混合计算
在Presto中可以根据业务需要使用特定类型的Connector来读取不同数据源的数据,进行join关联计算。
基于内存计算,高性能
Presto是基于内存计算的,减少磁盘IO,计算更快。Presto性能是Hive的10倍以上。Presto能够处理PB级别的数据,但Presto并不是把PB级别的数据一次性加载到内存中计算,而是根据处理方式,例如:聚合场景,边读取数据,聚合,再清空内存,再去读取数据加载内存,再聚合计算,再清空内存… 这种方式。如果使用Join查询,那么就会产生大量的中间数据,速度会变慢。
流水线
由于Presto是基于PipeLine进行设计的,因此在进行海量数据处理过程中,终端用户不用等到所有的数据都处理完成才能看到结果,而是可以向自来水管一样,一旦计算开始,就可以产生一部分结果数据,并且结果数据会一部分接一部分的返回到客户端。
应用场景
Presto 支持在线数据查询,包括 Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条 Presto 查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
03
Presto架构
Presto是一个运行在多台服务器上的分布式系统,完整安装包括一个 Coordinator 和多个 Worker。
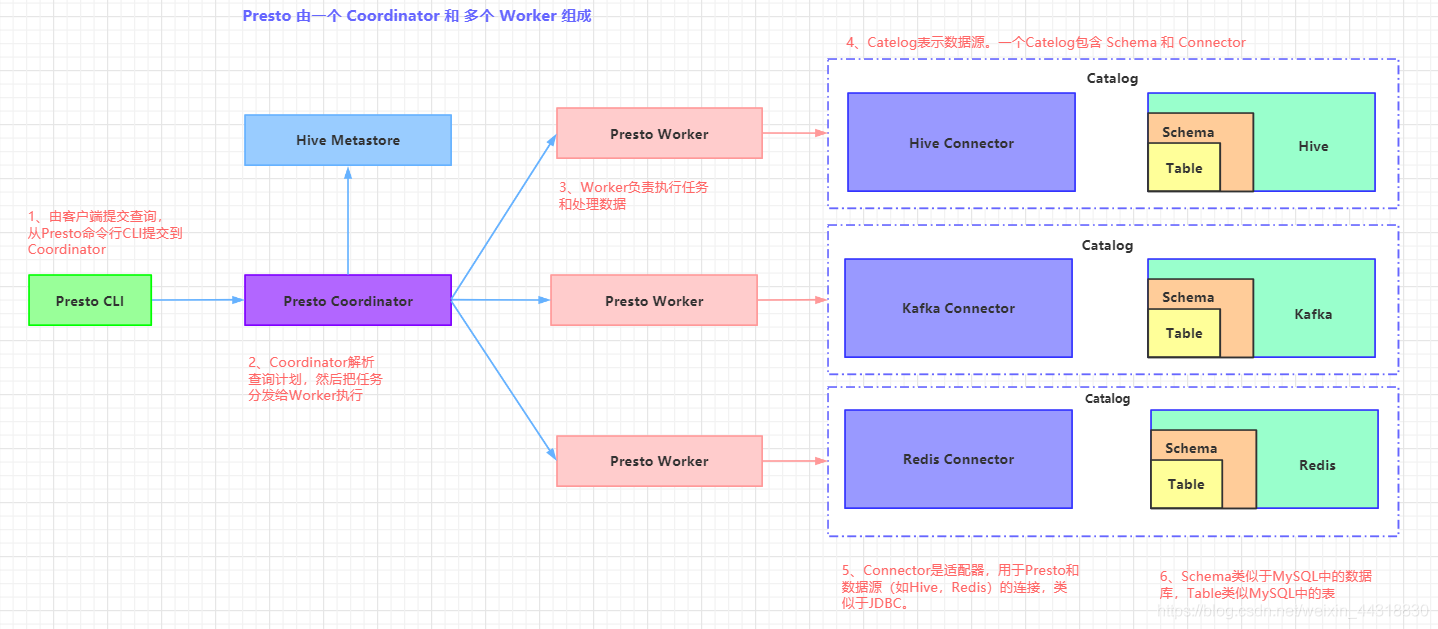
图片来源于:大数据梦想家
由客户端提交查询,从Presto命令行CLI提交到Coordinator,Coordinator进行解析,分析并执行查询计划,然后分发处理队列到Worker 。
Presto有两类服务器:Coordinator和Worker。
- Coordinator:
Coordinator服务器是用来解析语句,执行计划分析和管理Presto的Worker节点。Presto安装必须有一个Coordinator和多个Worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个Work的活动情况并协调查询语句的执行。Coordinator为每个查询建立模型,模型包含多个Stage,每个Stage再转为Task分发到不同的Worker上执行。
Coordinator与Worker、Client通信是通过 REST API。
2)Worker
Worker是负责执行任务和处理数据,Worker从Connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给Client。
当Worker启动时,会广播自己去发现Coordinator,并告知Coordinator它是可用,随时可以接受Task。
Worker与Coordinator、Worker通信是通过REST API。
3)数据源
贯穿下文,你会看到一些术语:Connector、Catelog、Schema 和 Table,这些是 Presto 特定的数据源。
Connector是适配器,用于Presto和数据源(如 Hive、RDBMS)的连接。你可以认为类似 JDBC那样,但却是Presto的SPI的实现,使用标准的API来与不同的数据源交互。
Presto有几个内建Connector:JMX的Connector、System Connector(用于访问内建的System table)、Hive的Connector、TPCH(用于TPC-H 基准数据),还有很多第三方的 Connector,所以Presto可以访问不同数据源的数据。
每个Catalog都有一个特定的Connector。如果你使用catelog 配置文件,你会发现每个文件都必须包含 connector.name 属性,用于指定catelog管理器(创建特定Connector使用)。
一个或多个catelog用同样的connector是访问同样的数据库。例如,你有两个Hive集群。 你可以在一个Presto集群上配置两个catelog,两个catelog都是用Hive Connector,从而达到可以查询两个 Hive 集群。
04
Presto和Spark SQL、Impala的比较
Presto作为SQL查询引擎,是一个纯内存的计算引擎,它对内存的优化近乎极致。
因为Presto的架构主要是主从式,主节点是coordinator——负责SQL的优化以及分配执行计划,同时还负责整个集群的内存管理,所以它的速度快。
例如:一个查询Query需要消耗12G的内存,你有三台work负责查询,每个work的内存都是32GB,coordinator经过计算后,得出每个节点有6G就差不多了(4G执行,2G备用)。
那么这个Query 即便重复执行5次约等于每个work付出30G内存,Presto照样敢一起执行,所以它快。
但是假如一个Query需要消耗100GB的内存,这就超过了整个集群的内存了,那么Presto的coordinator就直接卡掉这个查询,防止内存溢出,多个查询之和超出集群内存总量就排队。
反过来看Spark SQL:
它主要在集群中的每个计算节点的Executor进程中进行内存管理,它的内存管理主要还是为了优化当前计算节点的性能而设计的,不同于Presto搞了个主从架构专门控制集群内存。
Spark SQL的架构基于Spark,Spark的分布式架构又基于Hadoop Yarn(或者Mesos),作为Yarn不管你内部的内存效率,只关心将你的任务成功的分发到不同阶段的节点上去完成。
例如:Spark SQL生成优化后的物理计划若分成10个task去做,安排在3个Executor进程去创建task并管理,每台Executor在管理task的内存时,也许有的task比较费内存,有的task就不需要那么费,Executor发现自己内存不够,就缓冲到磁盘去做。
所以Spark也会出现内存与磁盘的I/O交换,那么这个速度就不明显了。
因此Presto的主从架构是从集群整体上的内存情况,对进行中的查询进行定时监控,优化调度,将最大将耗内存的查询,调度给work节点配置的最大内存量去使用,大概在堆内存的10%。但是Spark还是单靠每个节点自己的Executor进程来解决内存与磁盘的平衡问题。
但是数据量太大的查询尤其是还存在复杂的关联的全量数据集处理,Spark大多数情况还是比Presto快。
一方面因为Presto遇到这种情况,主要就是对查询的分解、分批、排队。但是Spark就能充分利用MPP架构的能力,多任务分配到切分后的多数据块,先调入计算处理,大不了内存和磁盘一起用。
另一方面Presto倾向于计算与存储分离的架构,每个work并不知道是不是从本地拿数据,只是根据查询要求来做,大多数情况都是远程调用数据。
但是Spark还是计算与存储结合的架构,每个task可以和rdd的一个分区做对应,那么spark对rdd的分布式数据节点分配也会尽量按照就近原则进行,作为复杂的连接操作,尽量多的在本地处理,速度肯定比远程读取或者混洗(shuffle)要快很多。
至于Presto和Impala,建议看下图一目了然。

Presto和Impala的对比