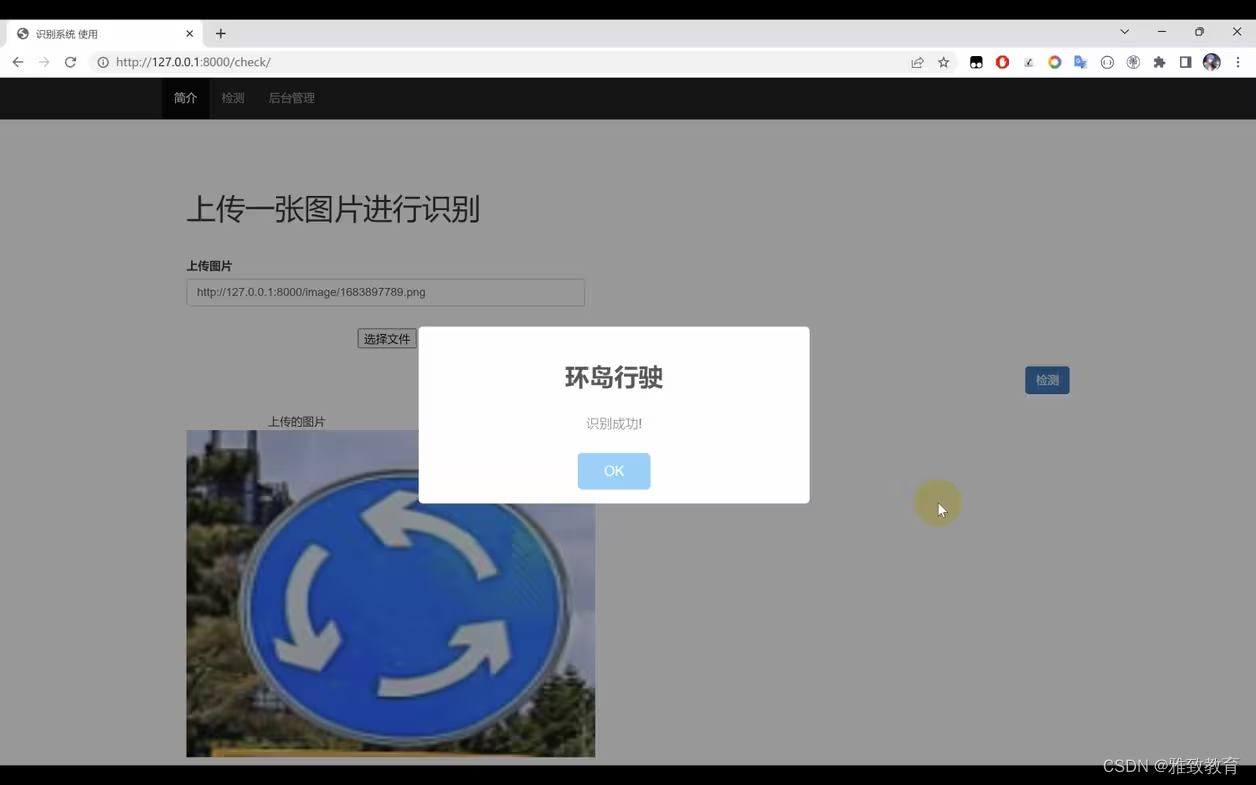
Mybatis Plus分页实现逻辑整理(结合芋道整合进行解析)

我希望如春天般的你,身着白色的婚纱,向我奔赴而来,我愿意用全世界最温情的目光,朝着你的方向望去——姗姗来迟。
1.背景介绍
https://baomidou.com/pages/2976a3/#mybatisplusinterceptor 官方文档
首先,我们都知道Mybatis Plus是Mybatis 的升级版,只做了功能增强,不做代码变动,现在我们就对于Mybatis Plus的分页实现做一个介绍概括!
MyBatis-Plus分页实现主要通过Page对象来实现,该对象封装了分页相关的信息,例如当前页码、每页记录数等。以下是MyBatis-Plus分页实现的概述:
-
Page对象: MyBatis-Plus使用
Page对象来表示分页信息。这个对象包含了当前页码、每页记录数、总记录数等信息。 -
分页查询方法: 在进行查询时,你可以通过传递
Page对象来告诉MyBatis-Plus你需要进行分页查询。MyBatis-Plus会在执行查询语句时,根据Page对象的信息生成对应的分页SQL语句。 -
分页插件: MyBatis-Plus提供了分页插件,可以在项目配置中进行配置。这个插件会在执行SQL前自动拦截,根据
Page对象的信息生成对应的分页SQL,并在查询结果中封装到Page对象中。 -
返回结果: 分页查询的结果将被封装到
Page对象中,你可以通过该对象获取分页相关的信息,例如总记录数、总页数等,以及实际的查询结果列表。
总体而言,MyBatis-Plus分页实现简化了分页查询的操作,通过传递Page对象即可轻松实现分页查询,无需手动编写复杂的分页SQL语句。这使得分页操作更加方便,同时也提高了代码的可维护性。
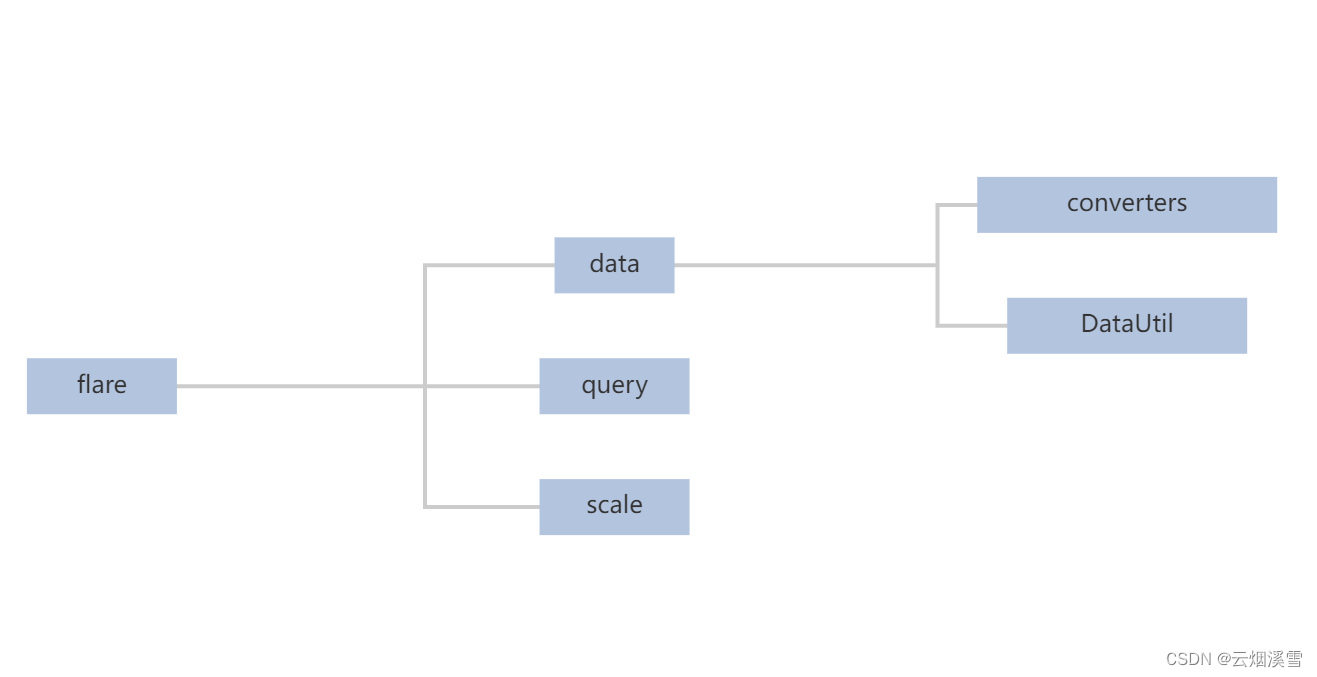
2.代码结构
3.依赖导入和相关配置
依赖导入
首先,要想完成代码演示和功能实现,我们需要再pom文件中加入如下依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.20</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>jakarta.validation</groupId>
<artifactId>jakarta.validation-api</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.22</version>
</dependency>
<dependency>
<groupId>com.github.yulichang</groupId>
<artifactId>mybatis-plus-join-core</artifactId>
<version>1.4.7</version>
</dependency>
</dependencies>
当然,让我们逐个介绍这些依赖项:
-
org.springframework.boot:spring-boot-starter-web:
- 描述: 提供了构建基于Spring Boot的Web应用程序所需的基本依赖项。包括处理HTTP请求、管理会话和提供静态资源等功能。
- 用途: 通常用于开发Spring Boot Web应用程序。
-
org.springframework.boot:spring-boot-starter-test:
- 描述: 包含用于测试Spring Boot应用程序的依赖项。提供对单元测试、集成测试等测试相关功能的支持。
- 用途: 用于编写Spring Boot应用程序的测试。
-
com.mysql:mysql-connector-j:
- 描述: MySQL官方的JDBC驱动程序,用于将Java应用程序连接到MySQL数据库。
- 用途: 当Spring Boot应用程序需要与MySQL数据库进行连接时使用。
-
com.alibaba:druid-spring-boot-starter:1.2.20:
- 描述: 集成了Druid连接池,它是一个高性能的开源JDBC连接池,还提供了监控和管理功能。
- 用途: 当你想要使用Druid作为数据库连接池并享受其监控和管理功能时使用。
-
com.baomidou:mybatis-plus-boot-starter:3.5.3.1:
- 描述: MyBatis-Plus是MyBatis的增强工具包,简化了MyBatis的使用,提供了许多便利功能,包括分页查询。
- 用途: 用于简化MyBatis的使用,包括分页查询等功能。
-
org.projectlombok:lombok:
- 描述: Lombok是一个Java库,通过注解消除了样板代码,提高了开发效率。
- 用途: 简化Java代码,减少样板代码的编写。
-
jakarta.validation:jakarta.validation-api:2.0.2:
- 描述: Jakarta Bean Validation API,提供了一套用于声明性数据验证的API。
- 用途: 用于在应用程序中执行数据验证。
-
cn.hutool:hutool-all:5.8.22:
- 描述: Hutool是一个Java工具包,提供了许多实用的工具方法,简化了Java开发。
- 用途: 提供各种实用工具,简化Java开发中的常见任务。
-
com.github.yulichang:mybatis-plus-join-core:1.4.7:
- 描述: 一个用于MyBatis-Plus的插件,简化了多表关联查询的操作。
- 用途: 简化MyBatis-Plus中多表关联查询的实现。
基础配置
server: port: 8181 spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/yudao?useUnicode=true&characterEncoding=UTF-8 username: root password: root mybatis-plus: mapper-locations: classpath:/mapper/**/*.xml typeAliasesPackage: com.cnbai.*.* global-config: db-config: id-type: AUTO # 数据库字段驼峰下划线转换 db-column-underline: true refresh-mapper: true configuration: # 自动驼峰命名 map-underscore-to-camel-case: true # 查询结果中包含空值的列,在映射的时候,不会映射这个字段 call-setters-on-nulls: true # 开启 sql 日志 log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 关闭 sql 日志 # log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpl
这是一个Spring Boot项目的配置文件,主要包含了服务器端口、数据库连接信息以及MyBatis-Plus的配置。下面是对其中的关键配置项的解读:
-
server.port: 配置了应用的端口号,这里设置为8181。 -
spring.datasource: 配置了数据源相关信息。driver-class-name: 指定了数据库驱动的类名。url: 指定了数据库连接的URL,包括数据库类型、主机地址、端口号以及数据库名称等。username和password: 指定了数据库的用户名和密码。
-
mybatis-plus.mapper-locations: 指定了MyBatis Mapper XML 文件的位置。 -
mybatis-plus.typeAliasesPackage: 指定了MyBatis扫描实体类别名的包路径。 -
mybatis-plus.global-config: 全局配置,包括数据库配置和刷新映射器。db-config.id-type: 设置主键生成策略,这里设定为自动增长。db-config.db-column-underline: 数据库字段驼峰下划线转换,设置为true表示启用。db-config.refresh-mapper: 刷新映射器,设置为true表示刷新XML中的缓存。
-
mybatis-plus.configuration: MyBatis 配置项。map-underscore-to-camel-case: 开启自动驼峰命名。call-setters-on-nulls: 查询结果中包含空值的列,在映射时不会映射这个字段,设置为true表示调用setter方法设置null值。log-impl: 开启 SQL 日志,这里设置为在控制台输出。
总体而言,这份配置文件包括了服务器端口、数据库连接信息,以及MyBatis-Plus的配置,其中包含了数据库驱动、URL、用户名、密码、Mapper XML 文件位置、实体类别名扫描包路径等。 MyBatis-Plus的配置包括了全局配置和MyBatis的一些常用配置,如主键生成策略、字段命名策略、映射器刷新等。
4.编写MybatisPlusConfig配置类
这是一个使用MyBatis-Plus的配置类,主要用于配置分页插件。让我对这段代码进行解读一下:
@Configuration
public class MybatisPlusConfig {
/**
* 添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); // 如果配置多个插件, 切记分页最后添加
return interceptor;
}
}
-
@Configuration: 这个注解表示这是一个配置类,会被Spring容器扫描并加载。 -
@Bean: 这个注解标志着这是一个Bean的定义方法,它将返回一个被Spring管理的对象。 -
MybatisPlusInterceptor: 这是MyBatis-Plus提供的插件拦截器,用于自定义MyBatis的行为。 -
mybatisPlusInterceptor(): 这个方法用于创建并配置MybatisPlusInterceptor的实例。 -
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)): 这行代码添加了一个内部插件,即PaginationInnerInterceptor,用于实现分页功能。DbType.MYSQL指定了数据库类型为MySQL。如果有多个插件,要确保分页插件是最后一个添加,以确保正确的执行顺序。
总体来说,这段配置代码的作用是创建一个MyBatis-Plus的拦截器,配置了分页插件,确保在进行数据库查询时自动添加分页的功能。这样,你在使用MyBatis-Plus进行分页查询时就无需手动编写分页SQL,而是通过配置实现了分页的自动化。
5.创建基础工具类
PageParam分页基础实体类
import lombok.Data;
import javax.validation.constraints.Min;
import javax.validation.constraints.Max;
import javax.validation.constraints.NotNull;
import java.io.Serializable;
@Data
public class PageParam implements Serializable {
private static final Integer PAGE_NO = 1;
private static final Integer PAGE_SIZE = 10;
/**
* 每页条数 - 不分页
*
* 例如说,导出接口,可以设置 {@link #pageSize} 为 -1 不分页,查询所有数据。
*/
public static final Integer PAGE_SIZE_NONE = -1;
@NotNull(message = "页码不能为空")
@Min(value = 1, message = "页码最小值为 1")
private Integer pageNo = PAGE_NO;
@NotNull(message = "每页条数不能为空")
@Min(value = 1, message = "每页条数最小值为 1")
@Max(value = 100, message = "每页条数最大值为 100")
private Integer pageSize = PAGE_SIZE;
}
这个类定义了用于分页查询的参数,通过 Lombok 注解减少了冗长的 getter 和 setter 方法的编写,而通过 Bean Validation 注解确保了参数的合法性。其中,通过静态常量和注释提供了对默认分页参数和不分页情况的解释
PageResult分页基础实体类
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
@Data
public final class PageResult<T> implements Serializable {
private List<T> list;
private Long total;
public PageResult() {
}
public PageResult(List<T> list, Long total) {
this.list = list;
this.total = total;
}
public PageResult(Long total) {
this.list = new ArrayList<>();
this.total = total;
}
public static <T> PageResult<T> empty() {
return new PageResult<>(0L);
}
public static <T> PageResult<T> empty(Long total) {
return new PageResult<>(total);
}
}
这是一个用于表示分页查询结果的 Java 类 PageResult<T>,使用 Lombok 的 @Data 注解简化了 getter、setter、toString 等方法的编写。下面是对该类的解读:
-
PageResult是一个泛型类,使用了<T>来表示泛型类型,用于表示分页查询的结果。 -
list属性:表示分页查询的结果列表,其中的泛型T表示每个元素的类型。 -
total属性:表示总记录数,即满足查询条件的所有记录的数量。 -
有多个构造方法:
- 无参构造方法:用于创建一个空的
PageResult对象。 - 带参构造方法(
List<T> list, Long total):用于接收查询结果列表和总记录数。 - 带参构造方法(
Long total):用于接收总记录数,结果列表初始化为空列表。
- 无参构造方法:用于创建一个空的
-
静态方法:
empty(): 返回一个空的PageResult,总记录数为 0。empty(Long total): 返回一个空的PageResult,可以指定总记录数。
这个类的设计主要是用于封装分页查询的结果,提供了一些方便的构造方法和静态方法,使得在业务代码中使用起来更加简洁。
BaseMapperX 工具类
在MyBatis Plus 的 BaseMapper 的基础上拓展
import cn.hutool.core.collection.CollUtil;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.core.toolkit.support.SFunction;
import com.baomidou.mybatisplus.extension.toolkit.Db;
import com.github.yulichang.base.MPJBaseMapper;
import com.github.yulichang.interfaces.MPJBaseJoin;
import com.page.demo.common.mybatis.core.query.MyBatisUtils;
import com.page.demo.common.pojo.PageParam;
import com.page.demo.common.pojo.PageResult;
import org.apache.ibatis.annotations.Param;
import java.util.Collection;
import java.util.List;
/**
* 在 MyBatis Plus 的 BaseMapper 的基础上拓展,提供更多的能力
*
* 1. {@link BaseMapper} 为 MyBatis Plus 的基础接口,提供基础的 CRUD 能力
* 2. {@link MPJBaseMapper} 为 MyBatis Plus Join 的基础接口,提供连表 Join 能力
*/
public interface BaseMapperX<T> extends MPJBaseMapper<T> {
default PageResult<T> selectPage(PageParam pageParam, @Param("ew") Wrapper<T> queryWrapper) {
// 特殊:不分页,直接查询全部
if (PageParam.PAGE_SIZE_NONE.equals(pageParam.getPageNo())) {
List<T> list = selectList(queryWrapper);
return new PageResult<>(list, (long) list.size());
}
// MyBatis Plus 查询
IPage<T> mpPage = MyBatisUtils.buildPage(pageParam);
selectPage(mpPage, queryWrapper);
// 转换返回
return new PageResult<>(mpPage.getRecords(), mpPage.getTotal());
}
default <DTO> PageResult<DTO> selectJoinPage(PageParam pageParam, Class<DTO> resultTypeClass, MPJBaseJoin<T> joinQueryWrapper) {
IPage<DTO> mpPage = MyBatisUtils.buildPage(pageParam);
selectJoinPage(mpPage, resultTypeClass, joinQueryWrapper);
// 转换返回
return new PageResult<>(mpPage.getRecords(), mpPage.getTotal());
}
default T selectOne(String field, Object value) {
return selectOne(new QueryWrapper<T>().eq(field, value));
}
default T selectOne(SFunction<T, ?> field, Object value) {
return selectOne(new LambdaQueryWrapper<T>().eq(field, value));
}
default T selectOne(String field1, Object value1, String field2, Object value2) {
return selectOne(new QueryWrapper<T>().eq(field1, value1).eq(field2, value2));
}
default T selectOne(SFunction<T, ?> field1, Object value1, SFunction<T, ?> field2, Object value2) {
return selectOne(new LambdaQueryWrapper<T>().eq(field1, value1).eq(field2, value2));
}
default T selectOne(SFunction<T, ?> field1, Object value1, SFunction<T, ?> field2, Object value2,
SFunction<T, ?> field3, Object value3) {
return selectOne(new LambdaQueryWrapper<T>().eq(field1, value1).eq(field2, value2)
.eq(field3, value3));
}
default Long selectCount() {
return selectCount(new QueryWrapper<>());
}
default Long selectCount(String field, Object value) {
return selectCount(new QueryWrapper<T>().eq(field, value));
}
default Long selectCount(SFunction<T, ?> field, Object value) {
return selectCount(new LambdaQueryWrapper<T>().eq(field, value));
}
default List<T> selectList() {
return selectList(new QueryWrapper<>());
}
default List<T> selectList(String field, Object value) {
return selectList(new QueryWrapper<T>().eq(field, value));
}
default List<T> selectList(SFunction<T, ?> field, Object value) {
return selectList(new LambdaQueryWrapper<T>().eq(field, value));
}
default List<T> selectList(String field, Collection<?> values) {
if (CollUtil.isEmpty(values)) {
return CollUtil.newArrayList();
}
return selectList(new QueryWrapper<T>().in(field, values));
}
default List<T> selectList(SFunction<T, ?> field, Collection<?> values) {
if (CollUtil.isEmpty(values)) {
return CollUtil.newArrayList();
}
return selectList(new LambdaQueryWrapper<T>().in(field, values));
}
@Deprecated
default List<T> selectList(SFunction<T, ?> leField, SFunction<T, ?> geField, Object value) {
return selectList(new LambdaQueryWrapper<T>().le(leField, value).ge(geField, value));
}
default List<T> selectList(SFunction<T, ?> field1, Object value1, SFunction<T, ?> field2, Object value2) {
return selectList(new LambdaQueryWrapper<T>().eq(field1, value1).eq(field2, value2));
}
/**
* 批量插入,适合大量数据插入
*
* @param entities 实体们
*/
default void insertBatch(Collection<T> entities) {
Db.saveBatch(entities);
}
/**
* 批量插入,适合大量数据插入
*
* @param entities 实体们
* @param size 插入数量 Db.saveBatch 默认为 1000
*/
default void insertBatch(Collection<T> entities, int size) {
Db.saveBatch(entities, size);
}
default void updateBatch(T update) {
update(update, new QueryWrapper<>());
}
default void updateBatch(Collection<T> entities) {
Db.updateBatchById(entities);
}
default void updateBatch(Collection<T> entities, int size) {
Db.updateBatchById(entities, size);
}
default void insertOrUpdate(T entity) {
Db.saveOrUpdate(entity);
}
default void insertOrUpdateBatch(Collection<T> collection) {
Db.saveOrUpdateBatch(collection);
}
default int delete(String field, String value) {
return delete(new QueryWrapper<T>().eq(field, value));
}
default int delete(SFunction<T, ?> field, Object value) {
return delete(new LambdaQueryWrapper<T>().eq(field, value));
}
}
这是一个自定义的 MyBatis Plus 的 Mapper 接口 BaseMapperX<T>,该接口继承了 MPJBaseMapper<T>。下面是对该接口的主要内容进行解读:
-
BaseMapperX<T>继承了MPJBaseMapper<T>,这表示该 Mapper 接口扩展了 MyBatis Plus 的基础 Mapper 接口,并具有更多的能力。 -
接口中包含了一系列的默认方法,这些方法提供了更方便的数据库操作。以下是其中的几个方法的说明:
-
selectPage: 根据传入的分页参数和查询条件,进行分页查询并返回PageResult<T>。 -
selectJoinPage: 进行关联查询,支持连表 Join 操作,返回PageResult<DTO>,其中 DTO 是关联查询结果的数据传输对象。 -
selectOne系列方法:根据传入的条件查询单个对象。 -
selectCount系列方法:根据条件查询符合条件的记录数量。 -
selectList系列方法:根据条件查询符合条件的记录列表。 -
insertBatch系列方法:批量插入数据。 -
updateBatch系列方法:批量更新数据。 -
insertOrUpdate和insertOrUpdateBatch:插入或更新数据。 -
delete系列方法:根据条件删除数据。
-
-
该接口中使用了一些 MyBatis Plus 的条件构造器,如
QueryWrapper和LambdaQueryWrapper,用于构建查询条件。 -
在一些批量操作方法中,使用了
Db类提供的方法,该类提供了一些数据库操作的工具方法,例如批量插入、批量更新等。
总体而言,BaseMapperX<T> 接口提供了一组扩展的数据库操作方法,使得在使用 MyBatis Plus 进行数据库操作时更加方便和灵活。
LambdaQueryWrapperX 优化构建器
import cn.hutool.core.util.ArrayUtil;
import cn.hutool.core.util.ObjectUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.support.SFunction;
import org.springframework.util.StringUtils;
import java.util.Collection;
/**
* 拓展 MyBatis Plus QueryWrapper 类,主要增加如下功能:
* <p>
* 1. 拼接条件的方法,增加 xxxIfPresent 方法,用于判断值不存在的时候,不要拼接到条件中。
*
* @param <T> 数据类型
*/
public class LambdaQueryWrapperX<T> extends LambdaQueryWrapper<T> {
public LambdaQueryWrapperX<T> likeIfPresent(SFunction<T, ?> column, String val) {
if (StringUtils.hasText(val)) {
return (LambdaQueryWrapperX<T>) super.like(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> inIfPresent(SFunction<T, ?> column, Collection<?> values) {
if (ObjectUtil.isAllNotEmpty(values) && !ArrayUtil.isEmpty(values)) {
return (LambdaQueryWrapperX<T>) super.in(column, values);
}
return this;
}
public LambdaQueryWrapperX<T> inIfPresent(SFunction<T, ?> column, Object... values) {
if (ObjectUtil.isAllNotEmpty(values) && !ArrayUtil.isEmpty(values)) {
return (LambdaQueryWrapperX<T>) super.in(column, values);
}
return this;
}
public LambdaQueryWrapperX<T> eqIfPresent(SFunction<T, ?> column, Object val) {
if (ObjectUtil.isNotEmpty(val)) {
return (LambdaQueryWrapperX<T>) super.eq(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> neIfPresent(SFunction<T, ?> column, Object val) {
if (ObjectUtil.isNotEmpty(val)) {
return (LambdaQueryWrapperX<T>) super.ne(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> gtIfPresent(SFunction<T, ?> column, Object val) {
if (val != null) {
return (LambdaQueryWrapperX<T>) super.gt(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> geIfPresent(SFunction<T, ?> column, Object val) {
if (val != null) {
return (LambdaQueryWrapperX<T>) super.ge(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> ltIfPresent(SFunction<T, ?> column, Object val) {
if (val != null) {
return (LambdaQueryWrapperX<T>) super.lt(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> leIfPresent(SFunction<T, ?> column, Object val) {
if (val != null) {
return (LambdaQueryWrapperX<T>) super.le(column, val);
}
return this;
}
public LambdaQueryWrapperX<T> betweenIfPresent(SFunction<T, ?> column, Object val1, Object val2) {
if (val1 != null && val2 != null) {
return (LambdaQueryWrapperX<T>) super.between(column, val1, val2);
}
if (val1 != null) {
return (LambdaQueryWrapperX<T>) ge(column, val1);
}
if (val2 != null) {
return (LambdaQueryWrapperX<T>) le(column, val2);
}
return this;
}
// ========== 重写父类方法,方便链式调用 ==========
@Override
public LambdaQueryWrapperX<T> eq(boolean condition, SFunction<T, ?> column, Object val) {
super.eq(condition, column, val);
return this;
}
@Override
public LambdaQueryWrapperX<T> eq(SFunction<T, ?> column, Object val) {
super.eq(column, val);
return this;
}
@Override
public LambdaQueryWrapperX<T> orderByDesc(SFunction<T, ?> column) {
super.orderByDesc(true, column);
return this;
}
@Override
public LambdaQueryWrapperX<T> last(String lastSql) {
super.last(lastSql);
return this;
}
@Override
public LambdaQueryWrapperX<T> in(SFunction<T, ?> column, Collection<?> coll) {
super.in(column, coll);
return this;
}
}
这是一个拓展了 MyBatis Plus 的 LambdaQueryWrapper<T> 类的 LambdaQueryWrapperX<T> 类。主要增加了一些方法,用于在条件拼接时判断值是否存在,从而决定是否拼接到条件中。以下是对该类的解读:
-
LambdaQueryWrapperX<T>继承了LambdaQueryWrapper<T>,表示该类是对LambdaQueryWrapper<T>的拓展。 -
该类提供了一系列的拓展方法,如
likeIfPresent、inIfPresent、eqIfPresent等,这些方法都带有IfPresent后缀,表示当值存在时才进行条件拼接,避免了值为 null 或空时拼接条件。 -
这些拓展方法在条件拼接时先判断了值的存在性,如果值存在才进行条件拼接,否则不拼接。
-
重写了父类的一些方法,以方便链式调用,例如
eq、orderByDesc、last、in等。
总体而言,该类通过增加带有 IfPresent 后缀的拓展方法,使得在使用 LambdaQueryWrapper 进行条件拼接时更加方便,减少了空值或 null 值导致的冗余条件拼接。
6.创建实体类
@Data
@TableName(value = "test_student")
public class Student {
@TableId
private Long stuId;
private String stuName;
private Long stuAge;
private String className;
}
7.创建请求视图对象
@Data
@EqualsAndHashCode(callSuper = true)
public class StudentPageReqVO extends PageParam {
private String stuName;
private String className;
}
在这里有必要做一个解释,为什么创建一个请求视图对象
创建请求视图对象(Request View Object,简称Request VO)有几个主要原因,尤其在Web开发中:
-
封装请求参数: Request VO 提供了一种将请求参数封装到一个对象中的方式。这样做有助于减少控制器(Controller)层中的方法签名中的参数数量。在处理复杂的请求,特别是包含多个参数的请求时,将它们组织成一个对象可以提高代码的清晰度和可读性。
-
传递前端数据: 在Web应用中,前端通常以 JSON 或其他数据格式将数据传递给后端。Request VO 用于在前端和后端之间传递数据,尤其是在处理复杂的表单提交或查询条件时。通过使用 Request VO,可以更方便地将前端的数据映射到后端的处理逻辑中。
-
解耦前后端: Request VO 有助于解耦前端和后端的实现细节。前端可以更自由地修改请求参数的结构,而后端的处理逻辑不会受到太大影响,只需保证 Request VO 中的字段与后端期望的数据结构相匹配即可。
-
提高代码复用性: Request VO 可以作为方法参数,提高了代码的复用性。例如,多个控制器方法可能需要相似的请求参数,通过使用相同的 Request VO,可以减少重复的代码。
-
易于维护: 维护 Request VO 可以更方便地处理接口变更。如果请求参数的结构发生变化,只需更新 Request VO 中的字段,而无需修改控制器方法的签名。
总体而言,创建请求视图对象是一种良好的实践,有助于组织和管理请求参数,提高代码的可读性、可维护性,并支持前后端的解耦。
extends PageParam 表示一个类继承了 PageParam,这种情况通常发生在使用某个框架或库提供的分页功能时。
8.创建Mapper层
import com.page.demo.common.mybatis.core.query.LambdaQueryWrapperX;
import com.page.demo.common.mybatis.core.query.mapper.BaseMapperX;
import com.page.demo.common.pojo.PageResult;
import com.page.demo.domain.Student;
import com.page.demo.domain.StudentPageReqVO;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface StudentMapper extends BaseMapperX<Student> {
default PageResult<Student> getStudentList(StudentPageReqVO reqVO) {
return selectPage(reqVO, new LambdaQueryWrapperX<Student>()
.likeIfPresent(Student::getStuName, reqVO.getStuName())
.likeIfPresent(Student::getClassName, reqVO.getClassName())
.orderByDesc(Student::getStuId));
}
}
在这里我们可以看到,我们有三个自定义的基础工具类
com.page.demo.common.mybatis.core.query.LambdaQueryWrapperX; com.page.demo.common.mybatis.core.query.mapper.BaseMapperX; com.page.demo.common.pojo.PageResult;
就是我们首先创建的工具对象。
这是一个在 StudentMapper 接口中定义的默认方法,用于获取学生列表并返回分页结果 PageResult<Student>。以下是对该方法的解读:
-
方法签名:
default PageResult<Student> getStudentList(StudentPageReqVO reqVO)- 返回类型:
PageResult<Student>,表示分页查询的结果,其中Student是学生实体类。 - 方法名称:
getStudentList,用于获取学生列表。 - 参数:
StudentPageReqVO reqVO,是一个请求视图对象,用于传递查询条件。
- 返回类型:
-
方法实现:
return selectPage(reqVO, new LambdaQueryWrapperX<Student>() .likeIfPresent(Student::getStuName, reqVO.getStuName()) .likeIfPresent(Student::getClassName, reqVO.getClassName()) .orderByDesc(Student::getStuId));selectPage是在BaseMapperX接口中定义的方法,用于执行分页查询。reqVO作为查询条件传入。new LambdaQueryWrapperX<Student>()创建了一个带有条件判断的 LambdaQueryWrapper 实例,该实例是对 MyBatis Plus 的 LambdaQueryWrapper 进行了扩展,使得条件在值存在时才拼接到查询条件中。.likeIfPresent(Student::getStuName, reqVO.getStuName()):如果reqVO.getStuName()不为空,则添加一个类似于like的条件,即根据学生姓名模糊查询。.likeIfPresent(Student::getClassName, reqVO.getClassName()):如果reqVO.getClassName()不为空,则添加一个类似于like的条件,即根据班级名称模糊查询。.orderByDesc(Student::getStuId):按照学生编号降序排列结果。
-
返回结果:
- 返回的是经过分页查询后的学生列表的分页结果,封装在
PageResult<Student>中。
- 返回的是经过分页查询后的学生列表的分页结果,封装在
总体而言,这个方法实现了根据给定的条件(从 reqVO 中获取)进行学生列表的分页查询,使用了 MyBatis Plus 提供的分页查询功能,并且在查询条件拼接时使用了自定义的 LambdaQueryWrapperX 类,确保只有在条件值存在的情况下才进行条件的拼接。
9.创建服务层接口
import com.baomidou.mybatisplus.extension.service.IService;
import com.page.demo.common.pojo.PageResult;
import com.page.demo.domain.Student;
import com.page.demo.domain.StudentPageReqVO;
public interface IStudentService extends IService<Student> {
PageResult<Student> getStudentList(StudentPageReqVO reqVO);
}
10.创建服务层接口实现类
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.page.demo.common.pojo.PageResult;
import com.page.demo.domain.Student;
import com.page.demo.domain.StudentPageReqVO;
import com.page.demo.mapper.StudentMapper;
import com.page.demo.service.IStudentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class StudentServiceImpl extends ServiceImpl<StudentMapper, Student> implements IStudentService {
@Resource
private StudentMapper studentMapper;
@Override
public PageResult<Student> getStudentList(StudentPageReqVO reqVO) {
return studentMapper.getStudentList(reqVO);
}
}
11.创建控制层
import cn.hutool.json.JSONObject;
import com.page.demo.common.pojo.PageResult;
import com.page.demo.domain.Student;
import com.page.demo.domain.StudentPageReqVO;
import com.page.demo.service.IStudentService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.List;
@RestController
@RequestMapping("/api/stu")
public class StudentController {
@Resource
private IStudentService studentService;
@GetMapping("/list")
public JSONObject getStudentList(StudentPageReqVO reqVO) {
PageResult<Student> pageResult = studentService.getStudentList(reqVO);
JSONObject jsonObject = new JSONObject();
jsonObject.set("data", pageResult);
jsonObject.set("status", 200);
return jsonObject;
}
}
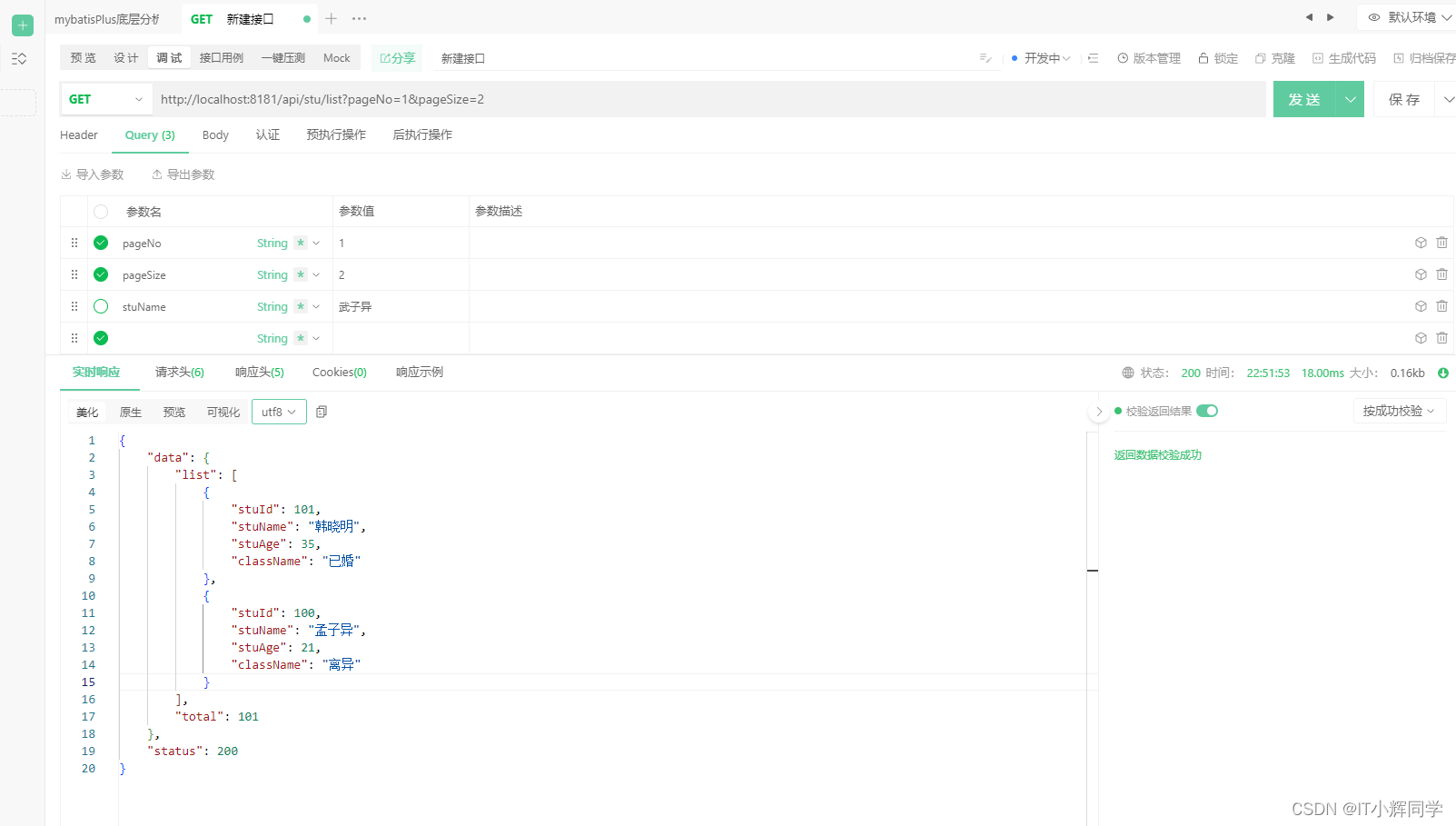
12.测试
13.总结
这段代码展示了一个基于Spring Boot和MyBatis Plus的后端服务的典型架构,主要涉及到以下方面:
1. 项目依赖及配置:
- 使用了Spring Boot框架,简化了项目的配置和搭建。
- 数据库连接使用了
mysql-connector-j,数据源使用了druid,MyBatis Plus作为持久层框架。 - 使用了
lombok简化实体类的代码。 - 引入了一些辅助工具库,如
hutool和mybatis-plus-join-core,用于增强开发效率和提供一些扩展功能。
2. MyBatis Plus分页实现:
- 配置了MyBatis Plus的分页插件,通过
PaginationInnerInterceptor实现分页功能。 - 自定义了
MybatisPlusConfig类,配置了分页插件,并将其注入到Spring容器中。
3. 数据库实体和分页请求视图对象:
- 存在
Student实体类,用于映射数据库中的学生表。 - 定义了
PageParam类,作为分页查询的请求参数对象,包含了页码、每页条数等信息。
4. 数据库操作接口和实现:
- 存在
BaseMapperX接口,继承了MyBatis Plus的BaseMapper和自定义的MPJBaseMapper,提供了一系列对数据库操作的方法,包括分页查询、条件查询等。 StudentMapper接口继承了BaseMapperX,用于学生表的数据库操作。StudentServiceImpl实现了IStudentService接口,提供了具体的业务逻辑,包括分页查询学生列表。
5. 自定义工具类和扩展:
- 存在
LambdaQueryWrapperX类,对MyBatis Plus的LambdaQueryWrapper进行了拓展,增加了一系列条件拼接的方法,根据条件值的存在性来动态拼接查询条件。
6. 分页查询方法:
- 在
IStudentService接口中定义了一个默认方法getStudentList,接受一个StudentPageReqVO对象作为查询条件,通过调用selectPage方法实现学生列表的分页查询。
总体评价:
- 代码结构清晰,遵循了一定的分层架构,将持久层、业务层和控制层分离。
- 使用了Spring Boot和MyBatis Plus等现代化框架,简化了开发流程,提高了开发效率。
- 引入了自定义工具类和扩展,使得代码更加灵活,可扩展性较好。
- 分页查询方法采用了默认方法的方式,提高了接口的兼容性。
总体而言,这个项目展示了一个典型的后端服务架构,具备良好的可读性、可维护性和可扩展性。