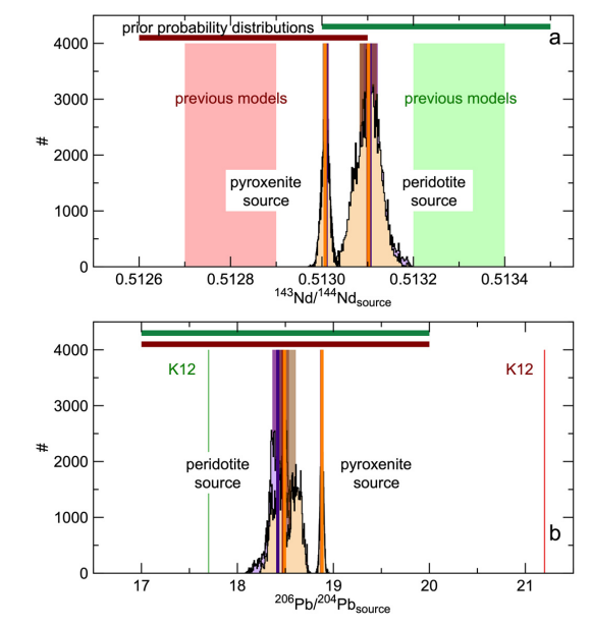
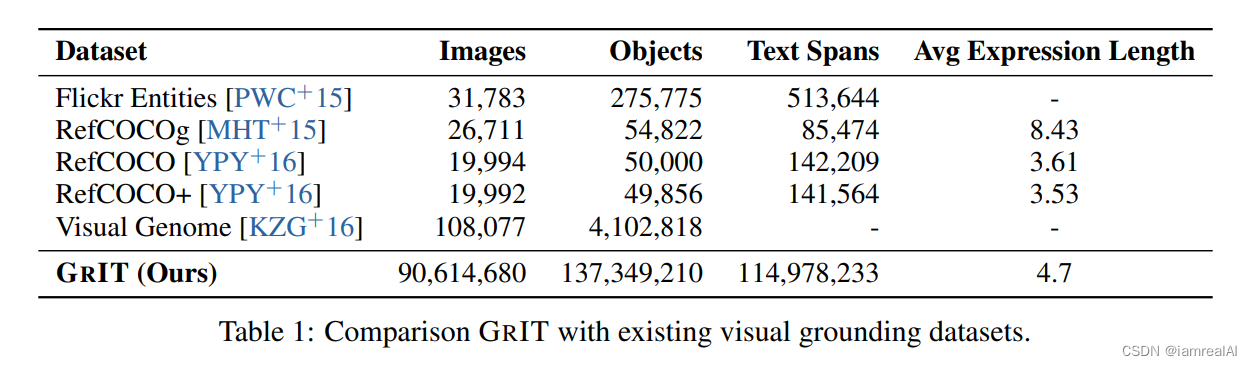
随着越来越多的企业将人工智能应用于其产品,AI芯片需求快速增长,市场规模增长显著。因此,本文主要针对目前市场上的AI芯片厂商及其产品进行简要概述。
简介
AI芯片也被称为AI加速器或计算卡,从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。
技术交流群
建了技术答疑、交流群!想要进交流群、资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

AI芯片分类
按技术架构分类
GPU(Graphics Processing Unit,图形处理单元):在传统的冯·诺依曼结构中, CPU 每执行一条指令都需要从存储器中读取数据, 根据指令对数据进行相应的操作。从这个特点可以看出, CPU 的主要职责并不只是数据运算, 还需要执行存储读取、 指令分析、 分支跳转等命令。深度学习算法通常需要进行海量的数据处理,用 CPU 执行算法时, CPU 将花费大量的时间在数据/指令的读取分析上, 而 CPU 的频率、 内存的带宽等条件又不可能无限制提高, 因此限制了处理器的性能。而 GPU 的控制相对简单,大部分的晶体管可以组成各类专用电路、多条流水线,使得 GPU 的计算速度远高于 CPU;同时,GPU 拥有了更加强大的浮点运算能力,可以缓解深度学习算法的训练难题,释放人工智能的潜能。但 GPU 无法单独工作,必须由 CPU 进行控制调用才能工作, 而且功耗比较高。
半定制化的 FPGA(Field Programmable Gate Array,现场可编程门阵列):其基本原理是在FPGA芯片内集成大量的基本门电路以及存储器,用户可以通过更新 FPGA 配置文件来定义这些门电路以及存储器之间的连线。与 GPU 不同, FPGA 同时拥有硬件流水线并行和数据并行处理能力, 适用于以硬件流水线方式处理一条数据,且整数运算性能更高,因此,常用于深度学习算法中的推理阶段。不过 FPGA 通过硬件的配置实现软件算法,因此,在实现复杂算法方面有一定的难度。将 FPGA 和 CPU 对比可以发现两个特点, 一是 FPGA 没有内存和控制所带来的存储和读取部分,速度更快, 二是 FPGA 没有读取指令操作,所以功耗更低。劣势是价格比较高、编程复杂、整体运算能力不是很高。目前,国内的 AI 芯片公司如深鉴科技就提供基于 FPGA 的解决方案。
全定制化 ASIC(Application-Specific Integrated Circuit,专用集成电路):是专用定制芯片,即为实现特定要求而定制的芯片。定制的特性有助于提高 ASIC 的性能功耗比,缺点是电路设计需要定制,相对开发周期长, 功能难以扩展。但在功耗、可靠性、 集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。谷歌的 TPU、寒武纪的 GPU,地平线的 BPU 都属于 ASIC 芯片。谷歌的 TPU 比 CPU 和 GPU 的方案快 30 至 80 倍,与 CPU 和 GPU 相比, TPU 把控制电路进行了简化,因此,减少了芯片的面积,降低了功耗。
神经拟态芯片:神经拟态计算是模拟生物神经网络的计算机制。神经拟态计算从结构层面去逼近大脑,其研究工作还可进一步分为两个层次,一是神经网络层面,与之相应的是神经拟态架构和处理器,如 IBM 的 TrueNorth 芯片,这种芯片把定制化的数字处理内核当作神经元,把内存作为突触。其逻辑结构与传统冯·诺依曼结构不同:它的内存、CPU 和通信部件完全集成在一起,因此信息的处理在本地进行,克服了传统计算机内存与 CPU 之间的速度瓶颈问题。同时,神经元之间可以方便快捷地相互沟通,只要接收到其他神经元发过来的脉冲(动作电位), 这些神经元就会同时做动作。二是神经元与神经突触层面,与之相应的是元器件层面的创新。如 IBM 苏黎世研究中心宣布制造出世界上首个人造纳米尺度的随机相变神经元,可实现高速无监督学习。
按功能分类
根据AI算法步骤,可分为训练(training)和推理(inference)两个环节。
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构, 运算量巨大,需要庞大的计算规模, 对于处理器的计算能力、精度、可扩展性等性能要求很高。目前市场上通常使用英伟达的 GPU 集群来完成, Google 的 TPU 系列 、华为昇腾 910 等 AI 芯片也支持训练环节的深度网络加速。
推理环节是指利用训练好的模型,使用新的数据去“推理”出各种结果。与训练阶段不同,推理阶段通常就不涉及参数的调整优化和反向传播了,它主要关注如何高效地将输入映射到输出。这个环节的计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。在推理环节中,除了使用 CPU 或 GPU 进行运算外, FPGA 以及 ASIC 均能发挥重大作用。典型的推理卡包括NVIDIA Tesla T4、NVIDIA Jetson Xavier NX、Intel Nervana NNP-T、AMD Radeon Instinct MI系列、Xilinx AI Engine系列等。
训练卡和推理卡的区别:
训练卡一般都可以作为推理卡使用,而推理卡努努力不在乎时间成本的情况下大部分也能作为训练卡使用,但通常不这么做。
主要原因在于二者在架构上就有很大的差别,推理芯片通常针对前向传播过程进行了高度优化,以实现高效的预测和分类任务。因此,它们的架构和指令集对于训练过程所需的大量参数更新和反向传播操作支持能力就弱了很多。
此外,训练芯片通常拥有更高的计算能力和内存带宽,以支持训练过程中的大量计算和数据处理。相比之下,推理芯片通常会在计算资源和内存带宽方面受到一定的限制。同时,二者支持的计算精度也通常不同,训练阶段需要高精度计算,因此常用高精度浮点数如:fp32,而推理阶段一般只需要int8就可以保证推理精度。
除了高带宽高并行度外,就片内片外的存储空间而言训练芯片通常比较“大”,这是训练过程中通常需要大量的内存来存储训练数据、中间计算结果以及模型参数。相较而言推理芯片可能无法提供足够的存储容量来支持训练过程。
按应用场景分类
主要分为用于服务器端(云端)和用于移动端(终端)两大类。
服务器端:在深度学习的训练阶段,由于数据量及运算量巨大,单一处理器几乎不可能独立完成一个模型的训练过程,因此, 负责 AI 算法的芯片采用的是高性能计算的技术路线,一方面要支持尽可能多的网络结构以保证算法的正确率和泛化能力;另一方面必须支持浮点数运算;而且为了能够提升性能必须支持阵列式结构(即可以把多块芯片组成一个计算阵列以加速运算)。在推断阶段,由于训练出来的深度神经网络模型仍非常复杂,推理过程仍然属于计算密集型和存储密集型,可以选择部署在服务器端。
移动端(手机、智能家居、无人车等):移动端 AI 芯片在设计思路上与服务器端 AI 芯 片有着本质的区别。首先,必须保证很高的计算能效;其次,在高级辅助驾驶 ADAS 等设 备对实时性要求很高的场合,推理过程必须在设备本身完成,因此要求移动端设备具备足够的推断能力。而某些场合还会有低功耗、低延迟、低成本的要求, 从而导致移动端的 AI 芯片多种多样。
下面,一起来看下国内外的AI芯片厂商发布的AI芯片产品。
国外 AI 芯片
英伟达 GPU
目前,主流的AI处理器无疑是NVIDIA的GPU,并且,英伟达针对不同的场景推出了不同的系列和型号。例如:L4用于AI视频,L40用于图像生成,H100系列则是大模型,GH200是图形推荐模型、矢量数据库和图神经网络。
目前NVIDIA的GPU产品主要有 GeForce、Data Center/Tesla 和 RTX/Quadro 三大系列,如下图所示,虽然,从硬件角度来看,它们都采用同样的架构设计,也都支持用作通用计算(GPGPU),但因为它们分别面向的目标市场以及产品定位的不同,这三个系列的GPU在软硬件的设计和支持上都存在许多差异。其中,GeForce为消费级显卡,而Tesla和Quadro归类为专业级显卡。GeForce主要应用于游戏娱乐领域,而Quadro主要用于专业可视化设计和创作,Tesla更偏重于深度学习、人工智能和高性能计算。
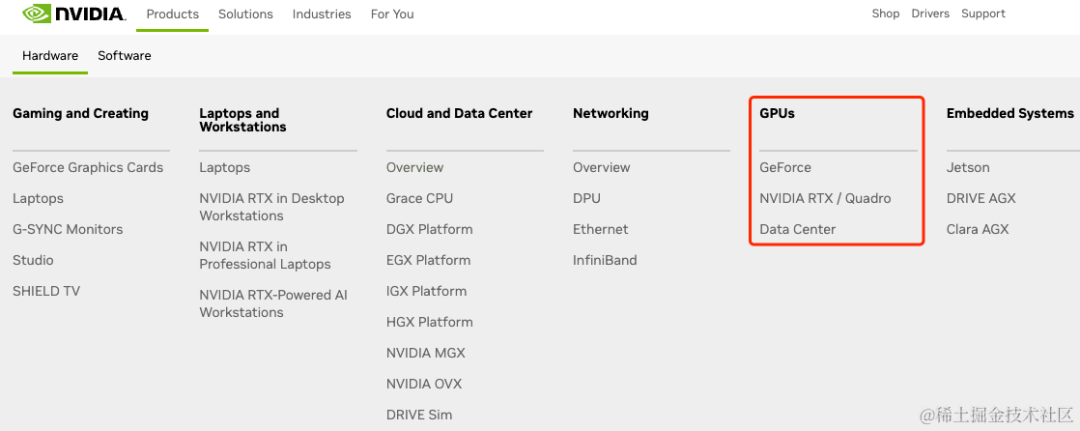
image.png
- Tesla:A100(A800)、H100(H800)、A30、A40、V100、P100…,下图为常见型号的参数对比:

image.png
-
GeForce:RTX 3090、RTX 4090 …
-
RTX/Quadro:RTX 6000、RTX 8000 …
其中,A800/H800是针对中国特供版(低配版),相对于A100/H100,主要区别:
-
A100的Nvlink最大总网络带宽为600GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
-
H100的Nvlink最大总网络带宽为900GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
随着美国新一轮的芯片制裁,最新针对中国特供版H20、L20和L2芯片也将推出。
近年来,NVIDIA GPU 的发展路线图如下所示:
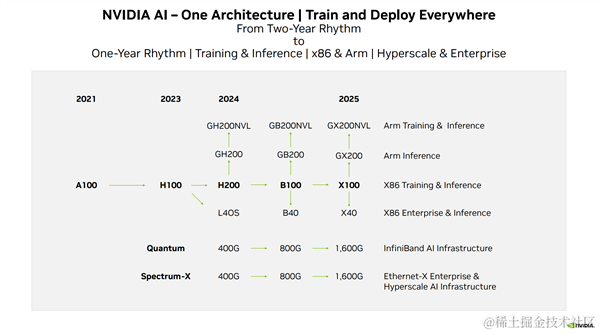
image.png
GPU架构:
NVIDIA GPU架构历经多次变革,从起初的Tesla,到Turing架构,再到Ampere、Hopper,发展史可分为以下时间节点:
-
2008 - Tesla
-
Tesla最初是给计算处理单元使用的,应用于早期的CUDA系列显卡芯片中,并不是真正意义上的普通图形处理芯片。
-
2010 - Fermi
-
Fermi是第一个完整的GPU计算架构。首款可支持与共享存储结合纯cache层次的GPU架构,支持ECC的GPU架构。
-
2012 - Kepler
-
Kepler相较于Fermi更快,效率更高,性能更好。
-
2014 - Maxwell
-
其全新的立体像素全局光照 (VXGI) 技术首次让游戏 GPU 能够提供实时的动态全局光照效果。基于 Maxwell 架构的 GTX 980 和 970 GPU 采用了包括多帧采样抗锯齿 (MFAA)、动态超级分辨率 (DSR)、VR Direct 以及超节能设计在内的一系列新技术。
-
2016 - Pascal
-
Pascal 架构将处理器和数据集成在同一个程序包内,以实现更高的计算效率。1080系列、1060系列基于Pascal架构
-
2017 - Volta
-
Volta 配备 640 个Tensor 核心,每秒可提供超过100 兆次浮点运算(TFLOPS) 的深度学习效能,比前一代的Pascal 架构快 5 倍以上。
-
2018 - Turing
-
Turing 架构配备了名为 RT Core 的专用光线追踪处理器,能够以高达每秒 10 Giga Rays 的速度对光线和声音在 3D 环境中的传播进行加速计算。Turing 架构将实时光线追踪运算加速至上一代 NVIDIA Pascal 架构的 25 倍,并能以高出 CPU 30 多倍的速度进行电影效果的最终帧渲染。2060系列、2080系列显卡也是跳过了Volta直接选择了Turing架构。
-
2020 - Ampere
-
Ampere 架构以 540 亿个晶体管打造,是有史以来最大的 7 纳米 (nm) 芯片。新的流式多处理器(SM)让 Ampere 架构的 A100 Tensor Core GPU 得到了显著的性能提升。
-
2022 - Hopper
-
Hopper 采用先进的台积电 4N 工艺制造,拥有超过 800 亿个晶体管,采用五项突破性创新技术为 NVIDIA H100 Tensor Core 提供动力支持。
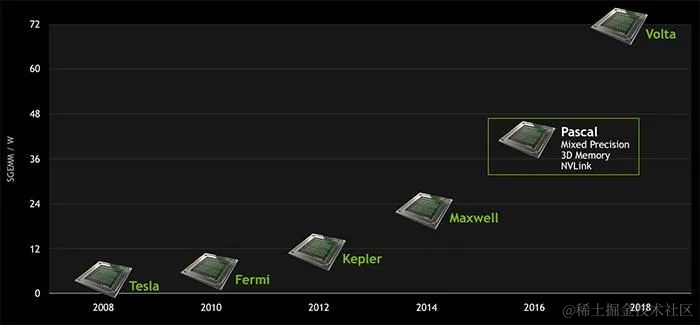
image.png
NVIDIA GPU 支持的数据类型:
NVIDIA GPU 从 Volta 架构开始支持 Tensor Core,专门用于矩阵乘法和累加计算,其和 CUDA Core 支持的数据类型也不相同。如下图所示为不同架构 GPU Tensor Core 和 CUDA Core 支持的数据类型。
可以看出,V100 是 Volta 架构,其 Tensor Core 只支持 FP16,而 Tensor Core 整体的算力一般是 CUDA Core 算力的几倍,因此如果在 V100 上使用 INT8,只能运行在 CUDA Core 上,其性能可能反而比使用 FP16 还差不少。同样,H100 的 Tensor Core 也不再支持 INT4 计算。
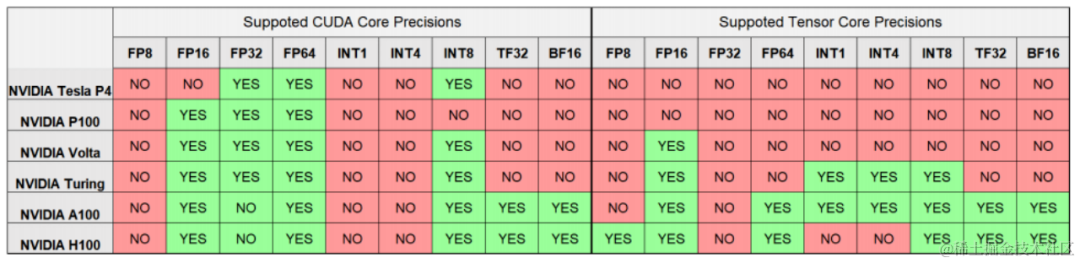
image.png
GPU 显存:
NVIDIA GPU 显存有两种类型,GDDR 和 HBM,每种也有不同的型号。针对显存我们通常会关注两个指标:显存大小和显存带宽。HBM 显存通常可以提供更高的显存带宽,但是价格也更贵,通常在训练卡上会使用,比如:H100、A100 等,而 GDDR 显存通常性价比更高,在推理 GPU 或游戏 GPU 更常见,比如:T4、RTX 4090 等。
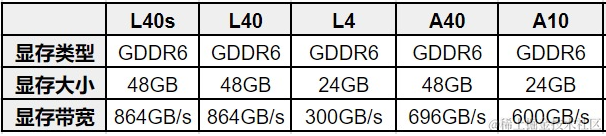
image.png
常见训练 GPU 的显存信息:

image.png
常见推理 GPU 的显存信息:
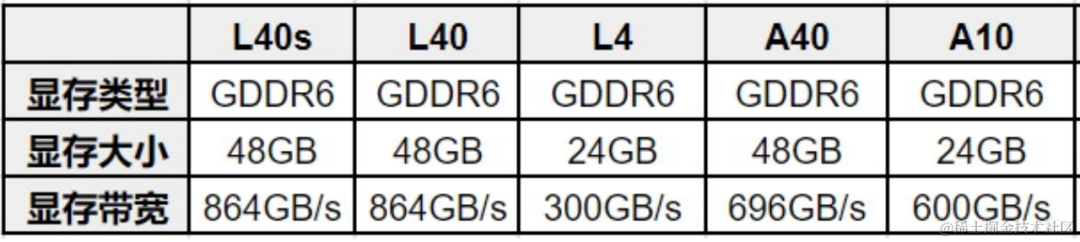
image.png
显存大小和带宽的影响:
传统的 CV、NLP 模型往往比较小,而且基本都是 Compute bound ,所以普遍对显存大小、带宽关注比较少;而现在 LLM 模型很大,推理除了是Compute bound,也是 IO bound;因此,越来越多人开始关注 GPU 显存大小和显存带宽。
最近 NVIDIA 正式推出 H200 GPU,相比 H100,其主要的变化就是 GPU 显存从 80GB 升级到 141GB,显存带宽从 3.5TB/s 增加到 4.8TB/s,也就是说算力和 NVLink 没有任何提升,这可能是为了进一步适配大模型推理的需求。
对于同一模型,在同样数量情况下,H200 相比 H100 的 LLM 推理性能对比:
-
LLaMA2 13B,性能提升为原来的 1.4 倍:
-
1 个 H100,batch size 为 64
-
1 个 H200,batch size 为 128
-
LLaMA2 70B,性能提升为原来的 1.9 倍:
-
1 个 H100,batch size 为 8
-
1 个 H200,batch size 为 32
-
GPT-3 175B,性能提升为原来的 1.6 倍:
-
8 个 H100,batch size 为 64
-
8 个 H200,batch size 为 128
GPU 间通信:
常见的 NVIDIA GPU 有两种常见的封装形式:PCIe GPU 和 SXM GPU。
NVIDA GPU-SXM主要是针对英伟达的高端GPU服务器,NVIDA GPU-SXM和NVIDA GPU-PCIe这两种卡都能实现服务器的通信,但是实现的方式是不一样的。SXM规格的一般用在英伟达的DGX服务器中,通过主板上集成的NVSwitch实现NVLink的连接,不需要通过主板上的PCIe进行通信,它能支持8块GPU卡的互联互通,实现了GPU之间的高带宽。
这里说的NVLink技术不仅能够实现CPU和GPU直连,能够提供高速带宽,还能够实现交互通信,大幅度提高交互效率,从而满足最大视觉计算工作负载的需求。
NVIDA GPU-PCIe就是把PCIe GPU卡插到PCIe插槽上,然后和CPU、同一个服务器上其他的GPU卡进行通信,也可以通过网卡与其他的服务器节点上的设备进行通信,这种就是PCIe的通信方式,但是这种传输速度不快。如果想要和SXM一样,有很快的传输速度,可以使用NVlink桥接器实现GPU和CPU之间的通信,但是和SXM不一样的地方就是它只能实现2块GPU卡之间的通信。也就是说,如果有 2 个 PCIe GPU,那么可以使用 NVLink 桥接器(Bridge)实现互联;如果超过 2 个 PCIe GPU,就无法实现 NVLink 的分组互联,此时只能考虑使用 SXM GPU。

image.png
一般来讲,单机内的多 GPU 之间通信分为:PCIe 桥接互联通信、NVLink 部分互联通信、NVSwitch 全互联通信三种。
谷歌 TPU
Google在高性能处理器与AI芯片主要有两个系列:
-
针对服务器端AI模型训练和推理的TPU系列,主要用于Goggle云计算和数据中心;
-
针对手机端AI模型推理的Tensor系列,主要用于Pixel智能手机。
TPU 是 Google 定制开发的应用专用集成电路 (ASIC),用于加速机器学习工作负载。TPU 使用专为执行机器学习算法中常见的大型矩阵运算而设计的硬件,更高效地训练模型。TPU 具有高带宽内存 (HBM),允许您使用更大的模型和批次大小。
TPU 芯片:
一个 TPU 芯片包含一个或多个 TensorCore。TensorCore 的数量取决于 TPU 芯片的版本。每个 TensorCore 由一个或多个矩阵乘法单元 (MXU)、一个向量计算单元和一个标量计算单位组成。
-
MXU 由脉动阵列中的 128 x 128 乘法累加器组成。MXU 在 TensorCore 中提供大部分计算能力。每个 MXU 在每个周期能够执行 16K 乘法累加操作。所有乘法都采用 bfloat16 输入,但所有累积都以 FP32 数字格式执行。
-
向量计算单元用于一般计算,例如:激活和 Softmax。
-
标量计算单位用于控制流、计算内存地址和其他维护操作。
TPU Pod:
TPU Pod 是通过专用网络组合在一起的一组连续的 TPU。TPU Pod 中的 TPU 芯片的数量取决于 TPU 版本。
TPU发展史:
-
TPUv1:Google第一代TPU芯片,服务器端推理芯片。
-
TPUv2:Google第二代TPU芯片,定位是服务端AI推理和训练芯片。TPUv2 平面图如下所示,紫色的ICI为卡之间的链接;绿色的HBM为高带宽内存。
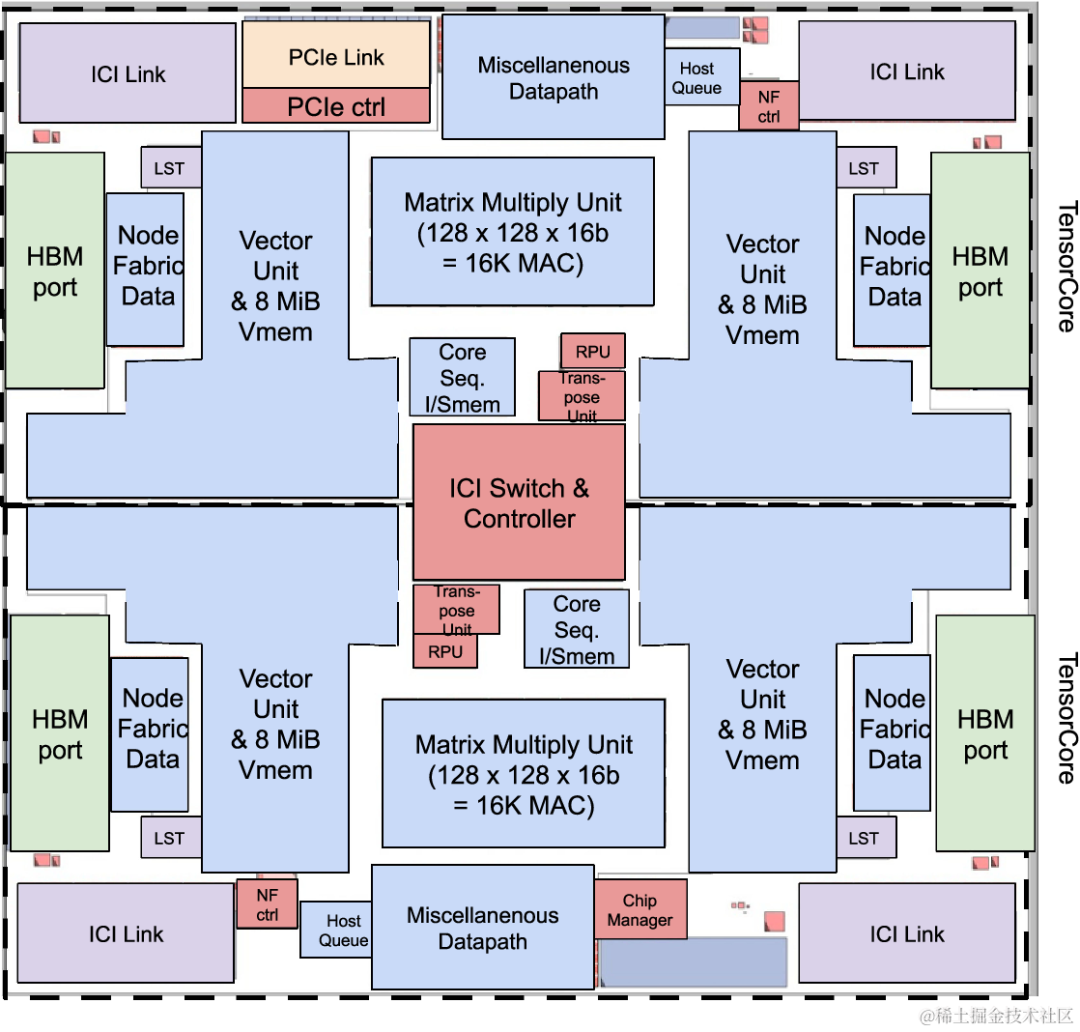
image.png
- TPUv3:TPUv3是对TPUv2的重新设计,采用相同的技术,MXU和HBM容量增加了两倍,时钟速率、内存带宽和ICI带宽增加了1.3倍。TPUv3超级计算机还可以扩展到1024个芯片。每个 v3 TPU 芯片包含两个 TensorCore。每个 TensorCore 有两个矩阵乘法计算单元(MXU)、一个向量计算单元和一个标量计算单元。
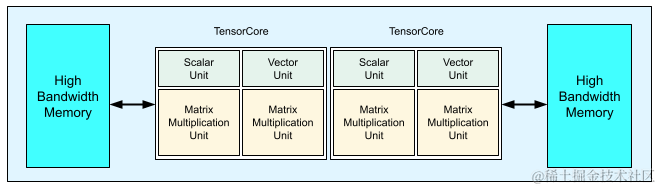
image.png
-
Edge TPU:Google发布的嵌入式TPU芯片,用于在边缘设备上运行推理。
-
TPUv4i:Google于2020年发布,定位是服务器端推理芯片。
-
TPUv4:Google于2020年发布,服务器推理和训练芯片,芯片数量是TPUv3的四倍。TPU v4 芯片如下图所示,每个 TPU v4 芯片包含两个 TensorCore。每个 TensorCore 都有四个矩阵乘法计算单元(MXU)、一个向量计算单元和一个标量计算单元。
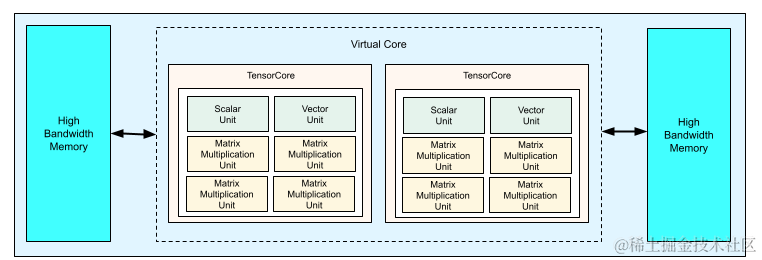
image.png
- TPU v5e:专为提升大中型模型的训练、推理性能以及成本效益所设计。与 2021 年发布的 TPU v4 相比,TPU v5e 的大型语言模型提供的训练性能提高了 2 倍、推理性能提高了2.5 倍。但是TPU v5e 的成本却不到上一代的一半,使企业能够以更低的成本,训练和部署更大、更复杂的 AI 模型。TPU v5e 芯片如下图所示,每个 v5e 芯片包含一个 TensorCore。每个 TensorCore 都有 4 个矩阵乘法计算单元 (MXU)、一个向量计算单元和一个标量计算单元。
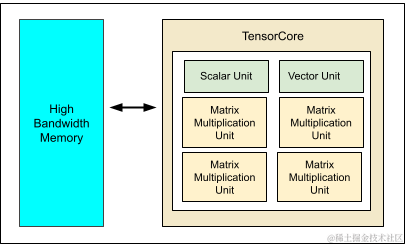
image.png
除此之外,国外还有英特尔和AMD的GPU,微软也计划推出代号为“雅典娜”的AI芯片。
国内 AI 芯片
华为昇腾
昇腾芯片是华为公司发布的两款 AI 处理器(NPU),昇腾910(用于训练)和昇腾310(用于推理)处理器,采用自家的达芬奇架构。昇腾在国际上对标的主要是英伟达的GPU,国内对标的包括寒武纪、海光等厂商生产的系列AI芯片产品(如:思元590、深算一号等)。
Atlas系列产品是基于昇腾910和昇腾310打造出来的、面向不同应用场景(端、边、云)的系列AI硬件产品。比如:
-
加速卡
-
Atlas 300T A2 训练卡,双槽位全高全长PCIe卡(PCIe x 16Gen5.0),32GB HBM,带宽800GB/s,支持ECC。
-
Atlas 300T Pro 训练卡 (型号:9000),昇腾910,单卡可提供最高 280 TFLOPS FP16 算力,32GB HBM,16GB DDR4。
-
Atlas 300I Pro 推理卡,140 TOPS INT8,70 TFLOPS FP16,LPDDR4X 24 GB,总带宽204.8 GB/s,PCIe x16 Gen4.0。
-
Atlas 300I Duo 推理卡,280 TOPS INT8,140 TFLOPS FP16,LPDDR4X 48GB,总带宽408GB/s,支持ECC。
-
加速模块
-
Atlas 200I A2(20 TOPS),20 TOPS INT8, 10 TFLOPS FP16,支持ECC。
-
Atlas 200I A2(8 TOPS),8 TOPS INT8, 4 TFLOPS FP16,支持ECC。
-
服务器
-
Atlas 800(型号:9000) 是训练服务器,包含8个训练卡(Atlas 300 T:采用昇腾910,300T有三种规格,分别为910A、910B、910 ProB;算力对应关系为910A–256、910B–256、910 ProB–280)。
-
Atlas 800(型号:3000) 是推理服务器,包含8个推理卡(Atlas 300 I:采用昇腾310)。
-
集群
-
Atlas 900 是训练集群(由128台 Atlas 800(型号:9000) 构成),相当于是由一批训练服务器组合而成。通过华为集群通信库和作业调度平台,整合HCCS、 PCIe 和 RoCE 三种高速接口,充分释放昇腾训练处理器的强大性能。

image.png
昇腾910性能强大,一般用于云上,关键参数如下所示:
-
640 TOPS @INT8, 320 TFLOPS @FP16
-
最大功耗300W
-
HBM 32GB
-
华为自研达芬奇架构
-
N7+工艺
-
PCIe x16 Gen4.0
-
散热方式:被动风冷
昇腾310主打高能效、灵活可编程,关键参数如下所示:
-
16TOPS@INT8, 8TOPS@FP16
-
最大功耗仅为 8W
-
华为自研达芬奇架构
-
12nm FFC工艺
百度昆仑芯
百度的造芯历史也相对比较悠久了,最早可以追溯到2015年,至今有接近十年的积累。
2018年,百度推出了第一代昆仑AI芯片,采用的是其自研XPU架构,关键指标如下所示:
-
采用14nm工艺
-
吞吐率可达256 TOPS@INT8,64 TFLOPS@FP16,功耗约150W
-
PCIe 4.0*8
-
HBM高速显存,512GB/s内存带宽
-
可用于云数据中心和智能边缘,支持全AI算法,已落地部署数万片
2021年,推出了第二代昆仑AI芯片,采用新一代XPU-R架构,关键指标如下所示:
-
采用7nm工艺
-
INT8性能不变,256 TOPS@INT8;浮点处理性能翻倍,128 TFLOPS@FP16
-
PCIe 4.0*16
-
GDDR6高性能显存
寒武纪思元
寒武纪作为国内最具代表性的AI芯片厂商之一,其发布的AI加速卡有思元270、思元290、思元370。
思元270系列面向高能效比云端AI推理。思元270采用寒武纪MLUv02架构,思元270集成了寒武纪在处理器架构领域的一系列创新性技术,处理非稀疏人工智能模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。其提供了两款产品:
思元270-S4,为高性能比AI推理设计的数据中心级加速卡,产品规格如下所示:
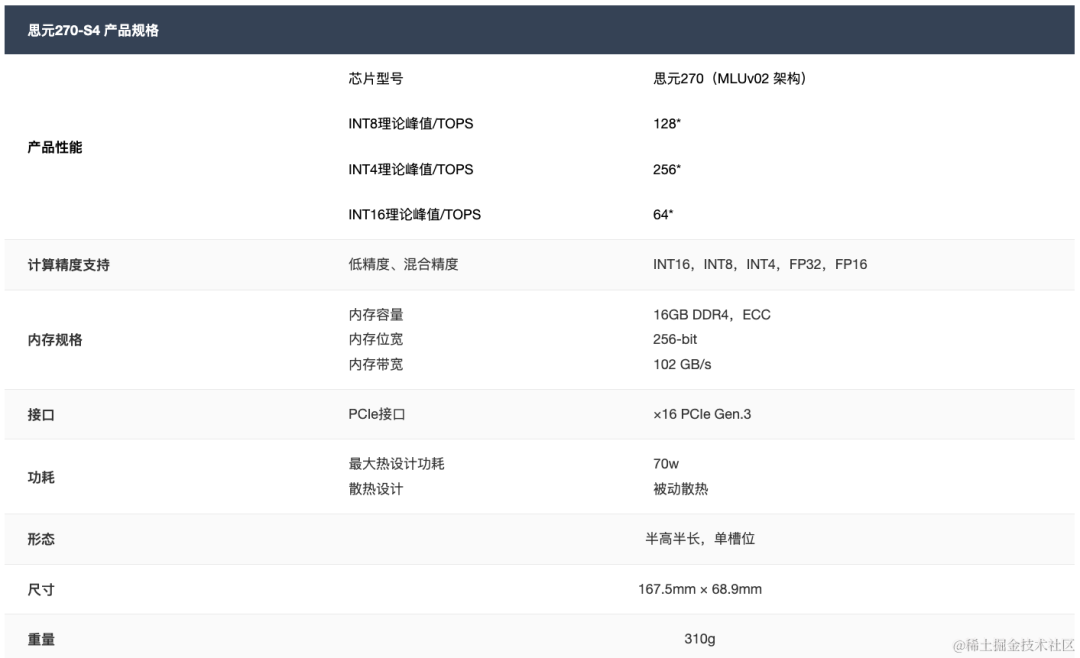
image.png
思元270-F4,面向非数据中心AI推理,产品规格如下所示: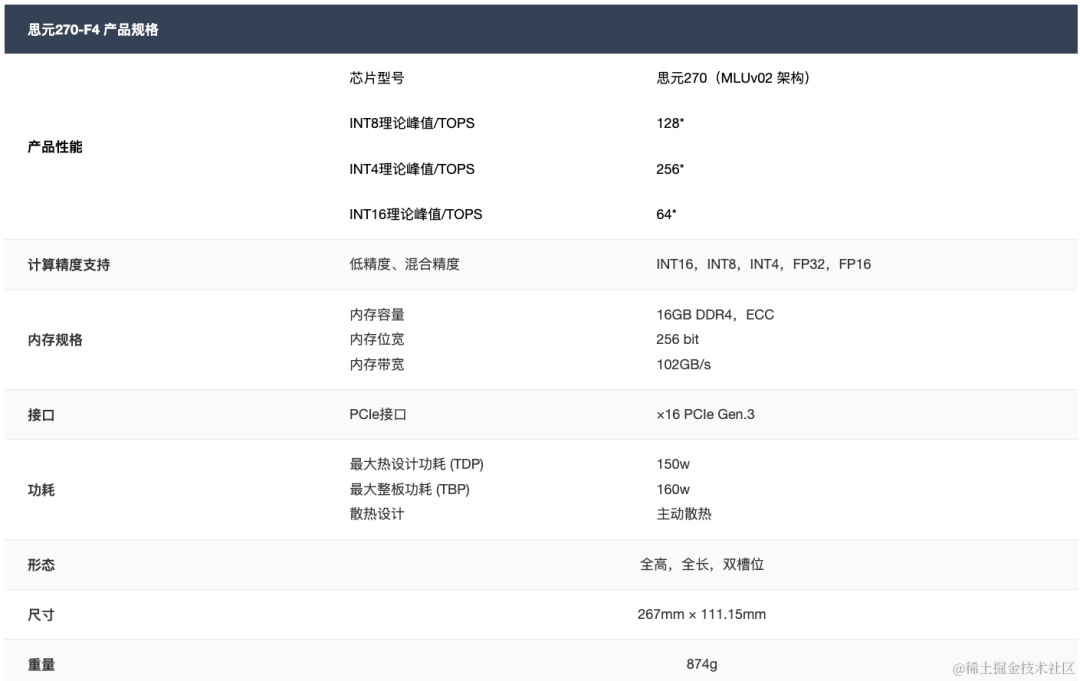
思元290是寒武纪首颗AI训练芯片,采用创新性的MLUv02扩展架构,使用台积电7nm先进制程工艺制造,在一颗芯片上集成了高达460亿的晶体管。芯片具备多项关键性技术创新, MLU-Link™多芯互联技术,提供高带宽多链接的互连解决方案;HBM2内存提供AI训练中所需的高内存带宽;vMLU帮助客户实现云端虚拟化及容器级的资源隔离。其提供了一款产品:
MLU290-M5智能加速卡搭载寒武纪首颗训练芯片思元290,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s内存带宽以及全新MLU-Link芯片间互联技术,同时支持单机八卡机内互联,多机多卡机间互联,全面支持AI训练、推理或混合型人工智能计算加速任务。
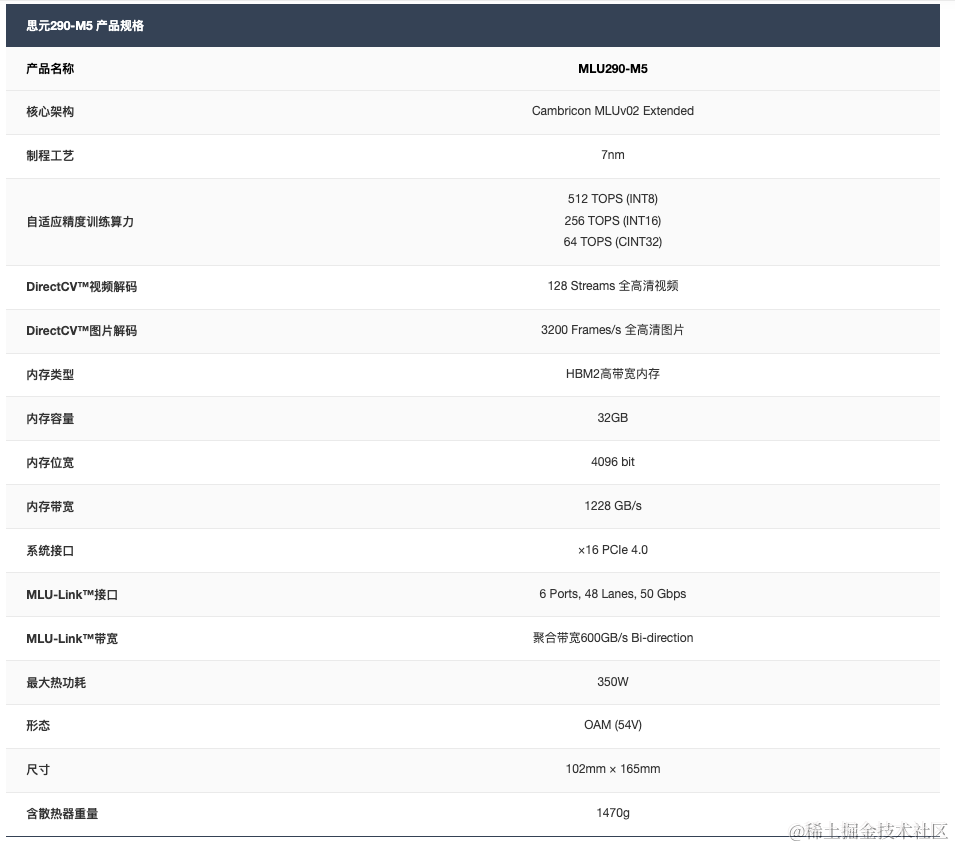
image.png
思元370芯片,基于7nm制程工艺,寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),是寒武纪第二代产品思元270算力的2倍。凭借寒武纪最新智能芯片架构MLUarch03,思元370实测性能表现更为优秀。思元370也是国内第一款公开发布支持LPDDR5内存的云端AI芯片,内存带宽是上一代产品的3倍,访存能效达GDDR6的1.5倍。搭载MLU-Link™多芯互联技术,在分布式训练或推理任务中为多颗思元370芯片提供高效协同能力。其提供了三款产品:
- MLU370-S4,面向高密度云端推理,支持PCIe Gen4,板载24GB低功耗高带宽LPDDR5内存,板卡功耗仅为75W。
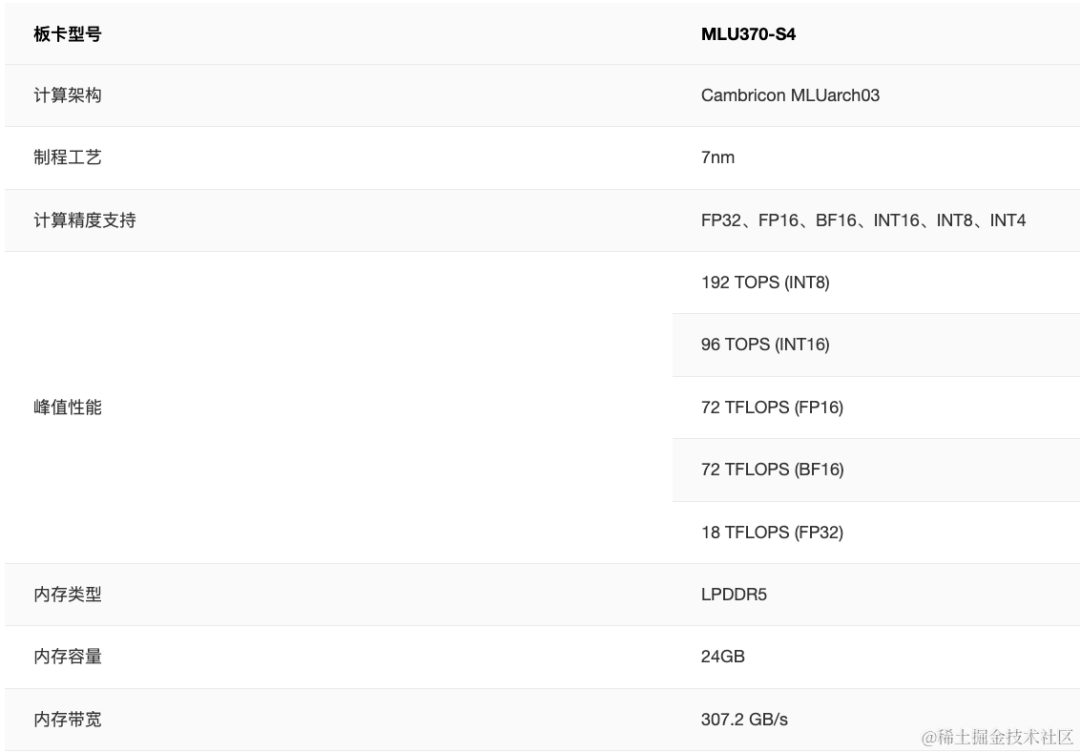
image.png
- MLU370-X4,云端人工智能加速卡,为单槽位150w全尺寸加速卡,可提供高达256TOPS(INT8)推理算力,和24TFLOPS(FP32)训练算力,同时提供丰富的FP16、BF16等多种训练精度。
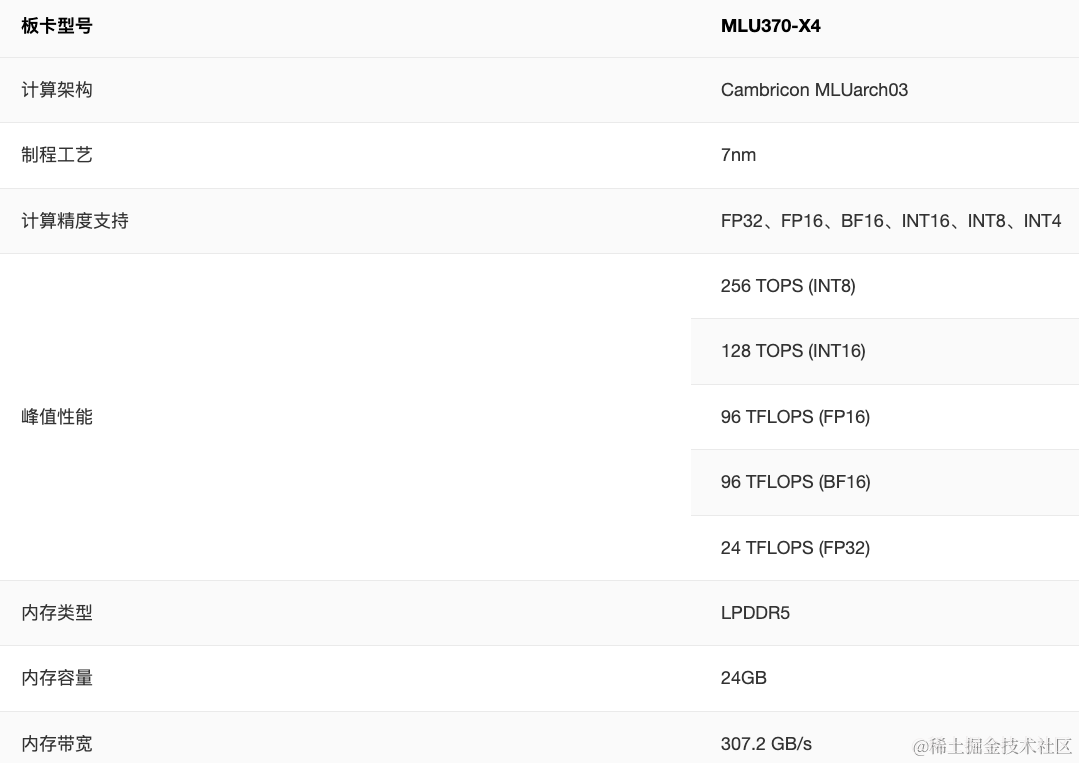
image.png
- MLU370-X8,训推一体人工智能加速卡,采用双芯思元370配置,为双槽位250w全尺寸智能加速卡,提供24TFLPOS(FP32)训练算力和256TOPS (INT8)推理算力,同时提供丰富的FP16、BF16等多种训练精度。基于双芯思元370打造的MLU370-X8整合了两倍于标准思元370加速卡的内存、编解码资源,同时MLU370-X8搭载MLU-Link多芯互联技术,每张加速卡可获得200GB/s的通讯吞吐性能,是PCIe 4.0带宽的3.1倍,支持单机八卡部署,可高效执行多芯多卡训练和分布式推理任务。
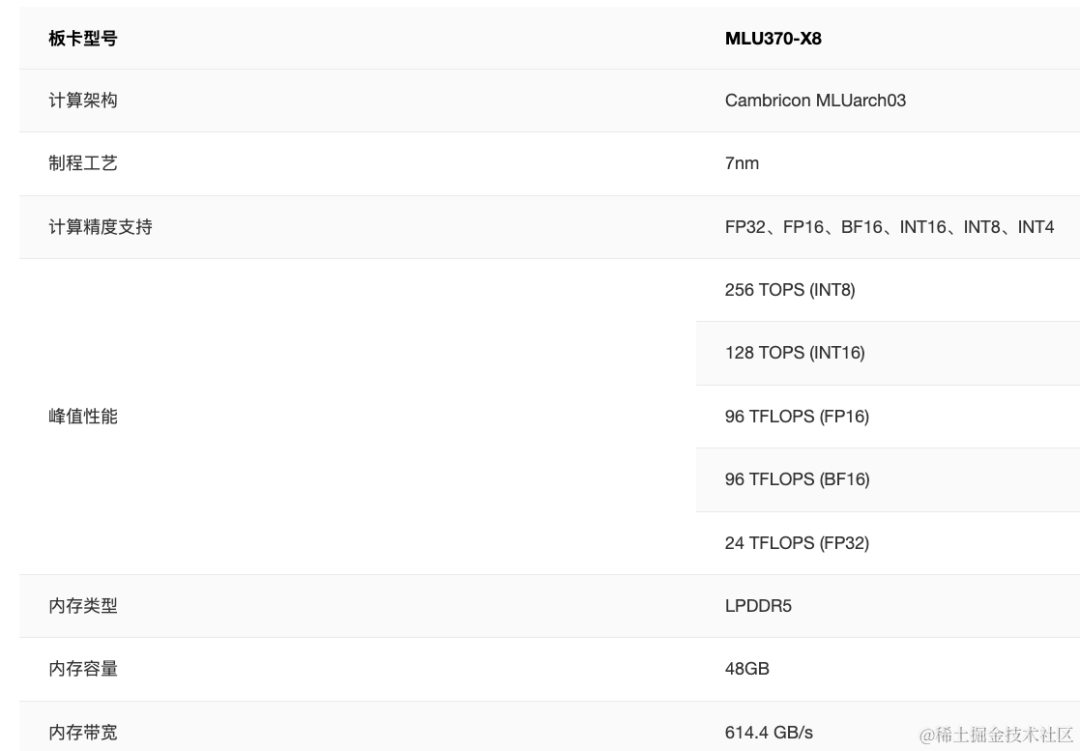
image.png
阿里平头哥含光
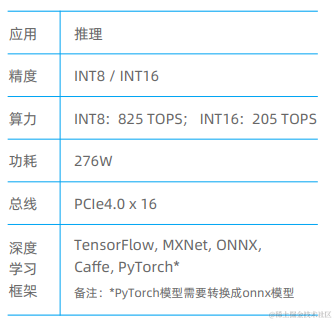
阿里巴巴集团的全资半导体芯片公司平头哥也发布过AI芯片含光800。一颗高性能人工智能推理芯片,基于12nm工艺, 集成170亿晶体管,性能峰值算力达820 TOPS。其自研神经网络处理器(NPU)架构为AI推理专门定制和创新,包括专有计算引擎和执行单元、192M本地存储(SRAM)以及便于快速存取数据的核间通信,从而实现了高算力、低延迟的性能体验。在业界标准的ResNet-50测试中,推理性能达到78563 IPS,能效比达500 IPS/W。
壁仞
壁仞科技也发布了壁仞BR100系列通用GPU芯片,其包含两款产品:
-
壁砺™100P产品形态为OAM模组,凭借强大的供电和散热能力,能够充分解放澎湃算力,驱动包括人工智能深度学习在内的通用计算领域高速发展。
-
壁砺™100 UBB:基于OCP UBB v1.0标准开发,搭载8张壁砺™100P通用GPU,支持单节点8卡全互连,能够为服务器提供强大的算力。
-
海玄服务器:性能强大的 OAM 服务器,首次实现单节点峰值浮点算力达到 8PFLOPS,搭载 8 个壁砺™100P OAM 模组,能够为广大应用场景提供超强的云端算力。
-
壁砺™104系列产品形态为PCIe板卡,其中壁砺™104P峰值功耗300W,壁砺™104S峰值功耗150W,能够为数据中心广泛应用的PCIe形态GPU服务器提供灵活部署的强大的通用算力。
燧原科技
燧原科技也发布了多款AI芯片,包括云燧T1x/T2x训练系列、云燧i1x/i2x推理系列。采用其自研的 GCU-CARA架构。

image.png
除此之外,还有像海光、摩尔线程、沐曦集成电路、天数智芯等发布的AI加速卡。随着美国对国内高端芯片的进一步封锁,希望国产芯片早日崛起。
结语
本文简要介绍了AI芯片的种类以及一些国内外AI芯片厂商发布的AI芯片。码字不易,如果觉得有帮助,欢迎点赞收藏加关注。
参考文档
-
TPU简介:https://cloud.google.com/tpu/docs/intro-to-tpu?hl=zh-cn
-
TPU架构:https://cloud.google.com/tpu/docs/system-architecture-tpu-vm
-
训练芯片和推理芯片,都是干嘛的:https://mp.weixin.qq.com/s/HX6-rVqRfy3n_PwQ0FWwrA
-
GPU 关键指标汇总:算力、显存、通信:https://mp.weixin.qq.com/s/KbYKAnZYQfLB2VkKQPhCVQ
-
浅析:NVIDA GPU卡SXM和PCIe之间的差异性:https://www.bilibili.com/read/cv24855760/
-
AI芯片第一极:GPU性能、技术全方位分析:https://www.ginpie.com/nd.jsp?id=56