RefCOCO、RefCOCO+、RefCOCOg

这三个是从MS-COCO中选取图像得到的数据集,数据集中对所有的 phrase 都有 bbox 的标注。
- RefCOCO 共有19,994幅图像,包含142,209个引用表达式,包含50,000个对象实例。
- RefCOCO+ 共有19,992幅图像,包含141,564个引用表达式,包含49,856个对象实例。
- Ref COCOg 共有26,711幅图像,包含85,474个引用表达式,包含54,822个对象实例。
在RefCOCO和RefCOCO +遵循train / validation / test A / test B的拆分,RefCOCOg只拆分了train / validation集合。
RefCOCO的表达式分别为120,624 / 10,834 / 5,657 / 5,095,RefCOCO+的表达式分别为120,191 / 10,758 / 5,726 / 4,889。
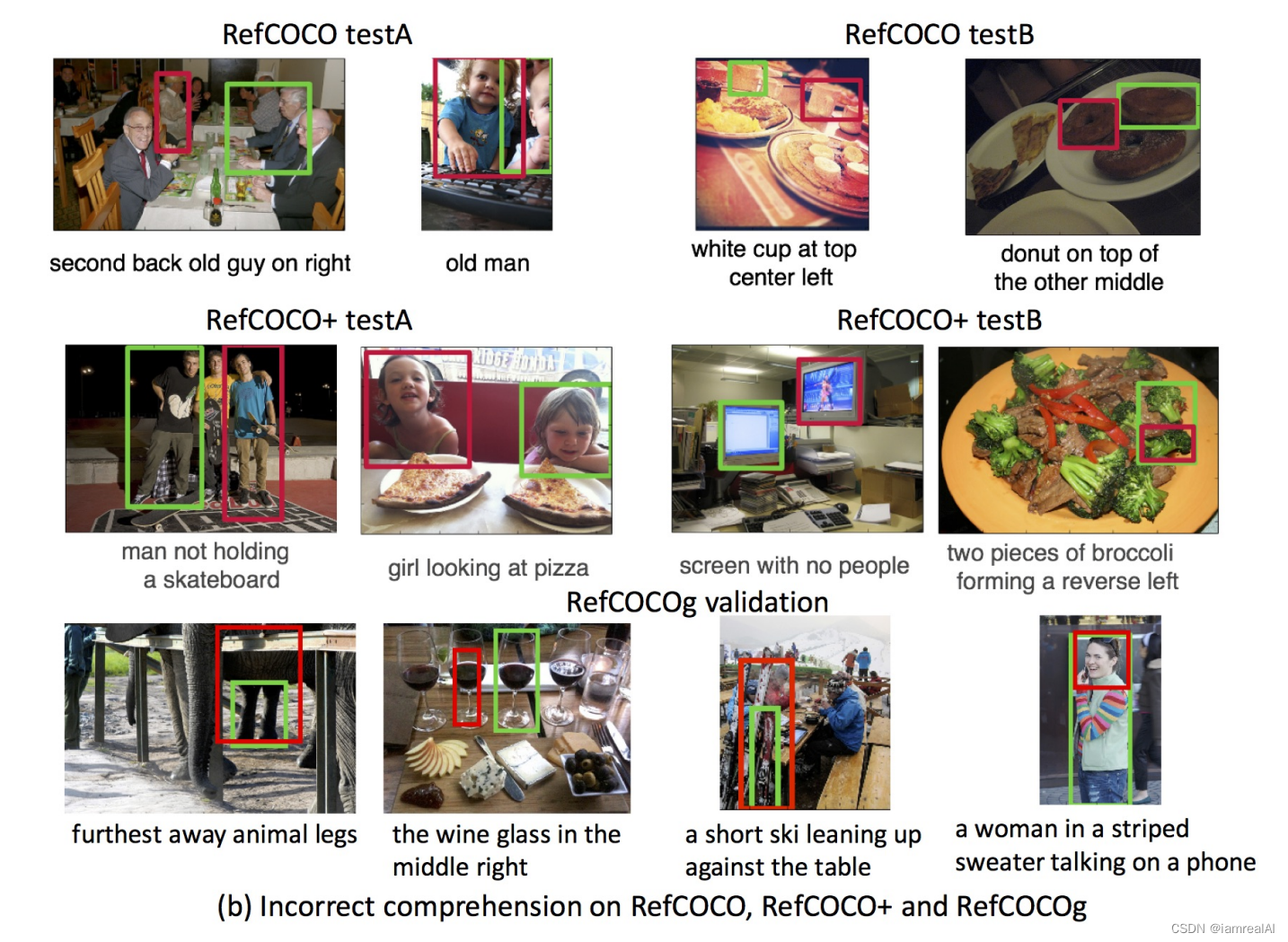
testA中的图像包含多人,testB中的图像包含所有其他对象。RefCOCO+中的查询不包含绝对的方位词,如描述对象在图像中位置的右边。RefCOCOg的查询长度普遍大于RefCOCO和RefCOCO +:RefCOCO、RefCOCO +、RefCOCOg的平均长度分别为3.61、3.53、8.43。
数据集示例如下图所示,每个图的 caption 描述在图片正下方,绿色是根据下面的 caption 标注的 gt,蓝色是预测正确的框,红色是预测错误的框。

OCR-VQA
OCR-VQA-200K是一个通过读取图像中的文本(OCR)进行视觉问答的大规模数据集,包含20多万张书籍封面图像及100多万个相关问答对,随机将80%、10%和10%的图像分别用于训练、验证和测试,因此分别产生了大约800K、100K和100K的训练、验证和测试QA对。

OK-VQA
OK-VQA是第一个大规模的需要外部知识才能回答视觉问答问题的基准测试集。它包含超过14000个开放域的问题,每个问题有5个标注答案。问题的构造保证单凭图像内容无法回答,需要利用外部知识库。

AOK-VQA
AOK-VQA是一个众包数据集,由大约 25000 个不同的问题组成,需要广泛的常识和世界知识来回答。与现有的基于知识的 VQA 数据集相比,这些问题通常不能通过简单地查询知识库来回答,而是需要对图像中描绘的场景进行某种形式的常识推理。

GRIT
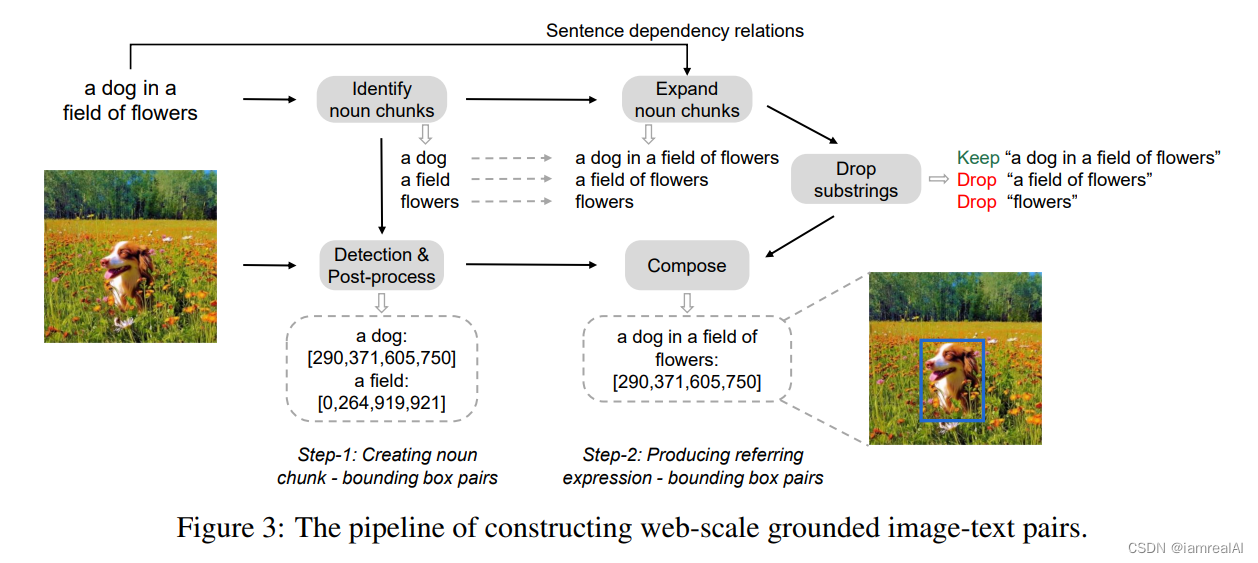
We introduce GRIT2 , a large-scale dataset of Grounded Image-Text pairs, which is created based on image-text pairs from a subset of COYO-700M [BPK+22] and LAION-2B [SBV+22]). We construct a pipeline to extract and link text spans (i.e., noun phrases and referring expressions) in the caption to their corresponding image regions. The pipeline mainly consists of two steps: generating nounchunk-bounding-box pairs and producing referring-expression-bounding-box pairs. We describe these steps in detail below:
Step-1: Generating noun-chunk-bounding-box pairs Given an image-text pair, we first extract noun chunks from the caption and associate them with image regions using a pretrained detector. As illustrated in Figure 3, we use spaCy [HMVLB20] to parse the caption (“a dog in a field of flowers") and extract all noun chunks (“a dog”, “a field” and “flowers”). We eliminate certain abstract noun phrases that are challenging to recognize in the image, such as “time”, “love”, and “freedom”, to reduce potential noise. Subsequently, we input the image and noun chunks extracted from the caption into a pretrained grounding model (e.g., GLIP [LZZ+22]) to obtain the associated bounding boxes. Non-maximum suppression algorithm is applied to remove bounding boxes that have a high overlap with others, even if they are not for the same noun chunk. We keep noun-chunk-bounding-box pairs with predicted confidence scores higher than 0.65. If no bounding boxes are retained, we discard the corresponding image-caption pair.
Step-2: Producing referring-expression-bounding-box pairs In order to endow the model with the ability to ground complex linguistic descriptions, we expand noun chunks to referring expressions. Specifically, we use spaCy to obtain dependency relations of the sentence. We then expand a noun chunk into a referring expression by recursively traversing its children in the dependency tree and concatenating children tokens with the noun chunk. We do not expand noun chunks with conjuncts. For noun chunks without children tokens, we keep them for the next process. In the example shown in Figure 3, the noun chunk ‘a dog’ can be expanded to “a dog in a field of flowers”, and the noun chunk ‘a field’ can be expanded to “a field of flowers”.
Furthermore, we only retain referring expressions or noun chunks that are not contained by others. As shown in Figure 3, we keep the referring expression “a dog in a field of flowers” and drop “a field of flowers” (as it is entailed by “a dog in a field of flowers”) and ‘flowers’. We assign the bounding box of the noun chunk (‘a dog’) to the corresponding generated referring expression (“a dog in a field of flowers”).
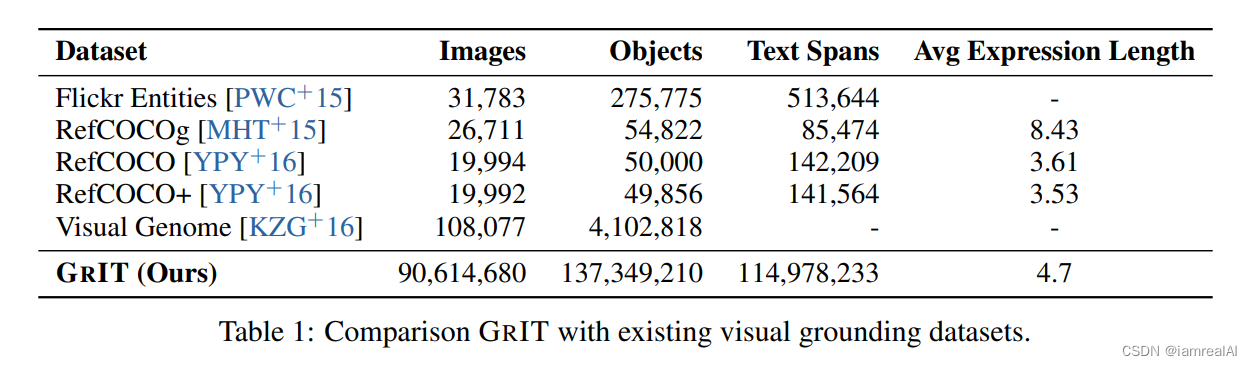
In the end, we obtain approximately 91M images, 115M text spans, and 137M associated bounding boxes. We compare GRIT with existing publicly accessible visual grounding datasets in Table 1.
LAION-400M
LAION-400M contains 400 million image-text pairs which is released for visionlanguage related pre-training. It is worthy to note that this dataset is filtered using CLIP which is a very popular pre-trained vision-language model.
CC3M
CC3M is a dataset annotated with conceptual captions proposed in 2018. The image-text samples are mainly collected from the web, then, about 3.3M image-description pairs remained after some necessary operations, such as extract, filter, and transform.
SBU
SBU Captions is originally collected by querying Flickr 1 using plentiful query terms. Then, they filter the obtained large-scale but noisy samples to get the dataset, which contains more than 1M images with high-quality captions.
COCO Captions
COCO Captions is developed based on MS-COCO dataset which contains 123,000 images. The authors recruit the Amazon Mechanical Turk to annotate each image with five sentences.
Text Captions
To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects.