KNN概念
k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。
k近邻法的输入为实例的特征向量对应于特征空间的点;输出为实例的类别,可以取多类。
k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。
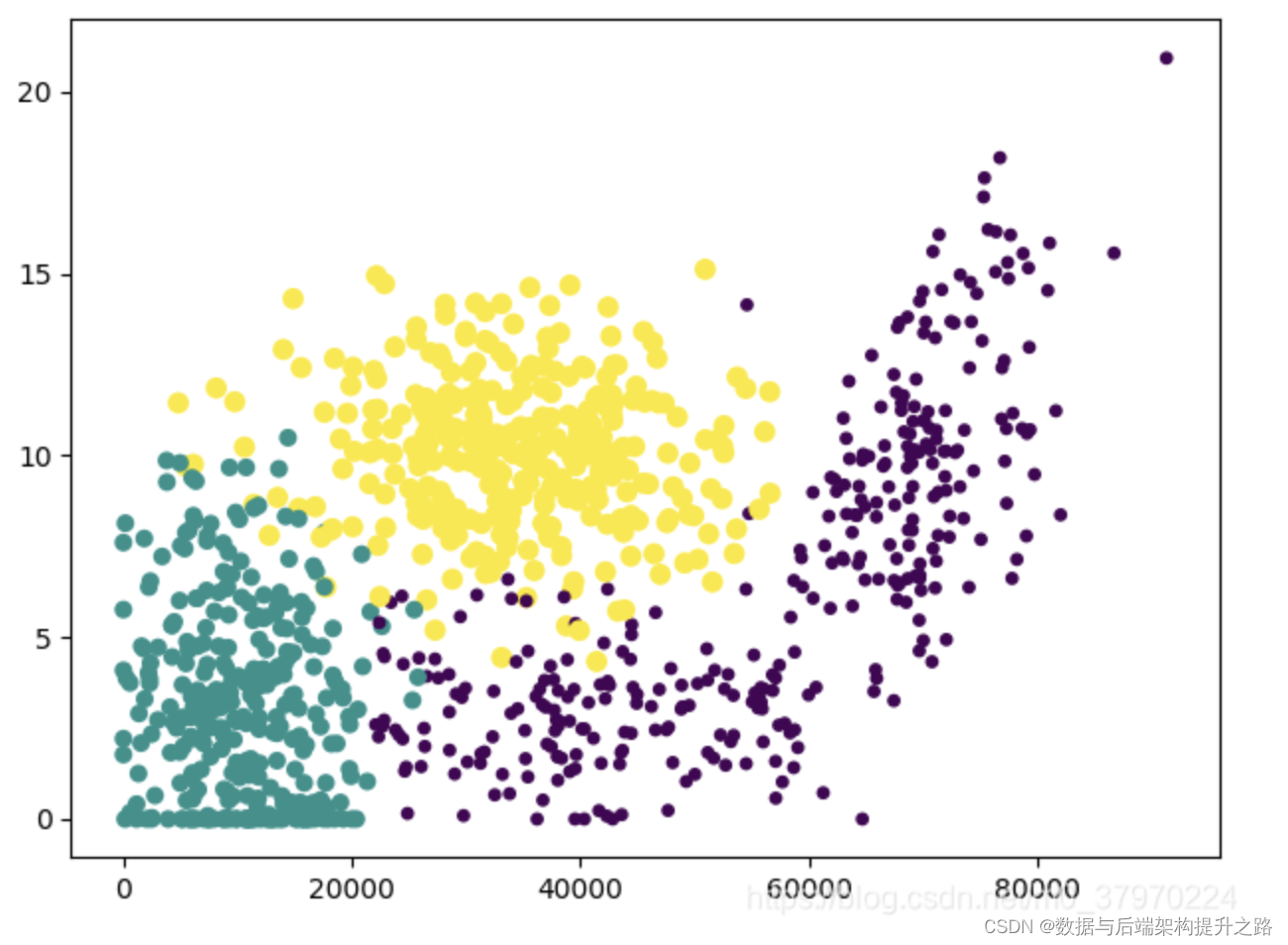
KNN过程
对未知类别属性的数据集中的每个点依次执行以下操作:
-
(1) 计算已知类别数据集中的点与当前点之间的距离;
-
(2) 按照距离递增次序排序;
-
(3) 选取与当前点距离最小的k个点;
-
(4) 确定前k个点所在类别的出现频率;
-
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类
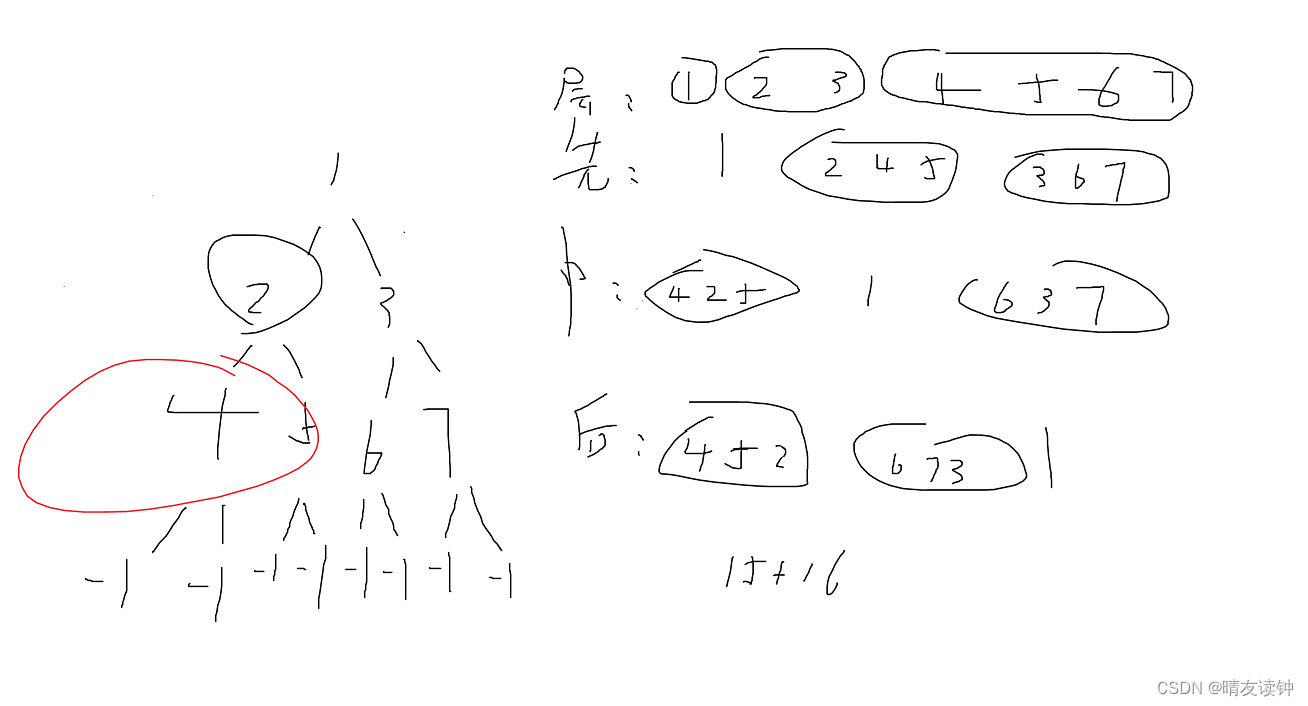
K 值如何选择
如果 K 值比较小,就相当于未分类物体与它的邻居非常接近才行。这样产生的一个问题就是,如果邻居点是个噪声点,那么未分类物体的分类也会产生误差,这样 KNN 分类就会产生
过拟合。
如果 K 值比较大,相当于距离过远的点也会对未知物体的分类产生影响,虽然这种情况的好处是鲁棒性强,但是不足也很明显,会产生欠拟合情况,也就是没有把未分类物体真正分类出来。
所以 K 值应该是个实践出来的结果,并不是我们事先而定的。在工程上,我们一般采用交叉验证的方式选取 K 值。
交叉验证的思路就是,把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在 KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。
KNN和K-Means的比较
K-Means是聚类算法,KNN 是分类算法。
这两个算法分别是两种不同的学习方式。
- KNN 是有监督学习数据集是带Label的数据,K-Means 是非监督学习,数据集是无Label,杂乱无章的数据
KNN没有明显的训练过程,基于Memory-based learning;K-Means有明显的训练过程。
- KNN 中的 K 值代表 K 个最接近的邻居;K-Means 中的 K 值代表 K 类。
参考文章
超详细:KNN与K-means从入门到实战!